практич.задание. Задача Произвести кластеризацию документов на web ресурсе
 Скачать 0.78 Mb. Скачать 0.78 Mb.
|

|
ОГЛАВЛЕНИЕ 1. Установка RapidMiner 3 2. Установка компонентов textMining и WebMining 5 3. Использование CrawlWeb для сохранения документов 7 4. Использование Process Dociment from files 10 5. Проведение кластеризации 13 Цель работы: научиться пользоваться инструментальными средствами анализа данных RapidMiner Задача: Произвести кластеризацию документов на web ресурсе 1. Установка RapidMiner Зайдем на веб-сайт программного продукта и скачаем установочный файл (рис.1). Окно запуска установленной версии приведено на рис.2.  Рис.1 Установка RapidMiner  Рис.2 Запуск RapidMiner  Рис.3 Интерфейс RapidMiner 2. Установка компонентов textMining и WebMining Зайдем в меню установки плагинов и выберем соответствующие компоненты для установки (рис.4). 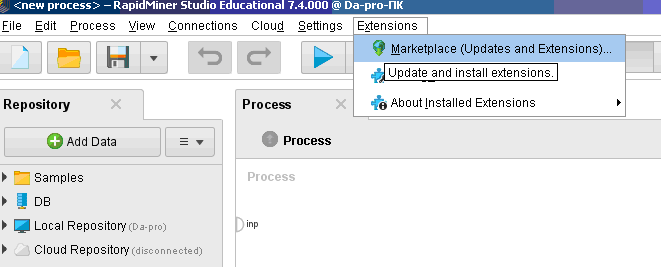 Рис.4 Переход в интерфейс управления компонентами RapidMiner Studio 7.4 Установив необходимые компоненты, они будут отображаться в перечне (package is up to date). Результаты приведены на рис.5 и рис.6. 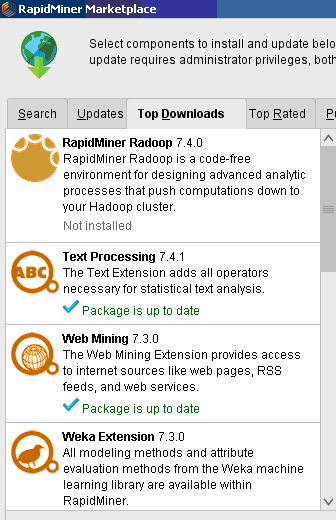 Рис.5 Результат установки компонентов в RapidMiner Studio 7.4  Рис.6 Окно просмотра установленных компонентов в RapidMiner 3. Использование CrawlWeb для сохранения документов В окне Operations выберем каталог Extensions-Web Mining и перетащим компонент Crawl Web в поле Process (рис.7). Установим ограничение анализа и скачивания не более 50 страниц (рис.8). В соответствующее поле введем выбранный сайт для сохранения.  Рис.7 Выбор компонента Crawl Web 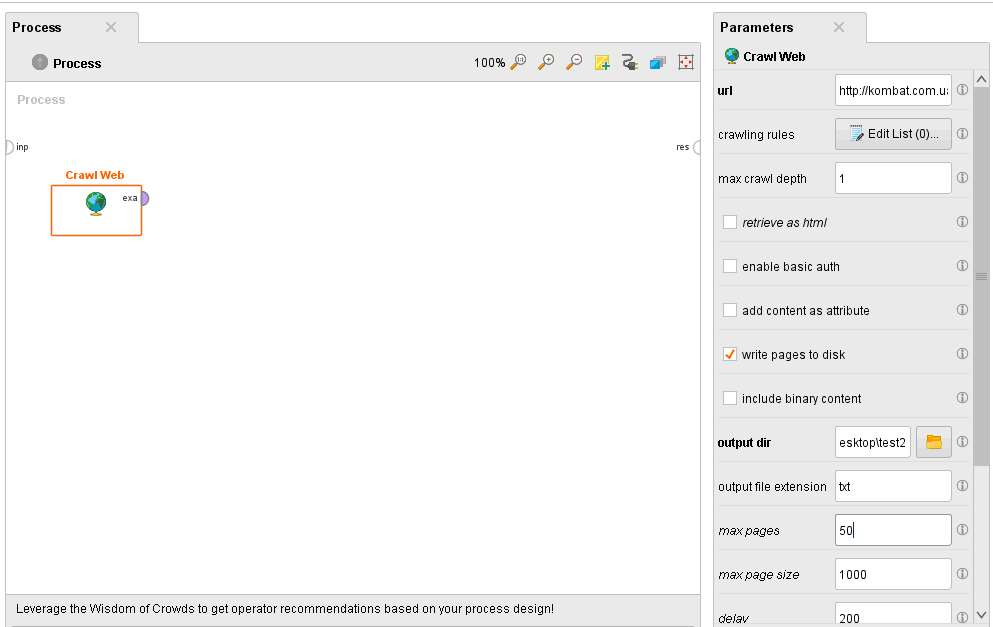 Рис.8 Конфигурация компонента Crawl Web Подадим выходной сигнал компонента на результирующий вход и запустим процесс (рис.9,10). 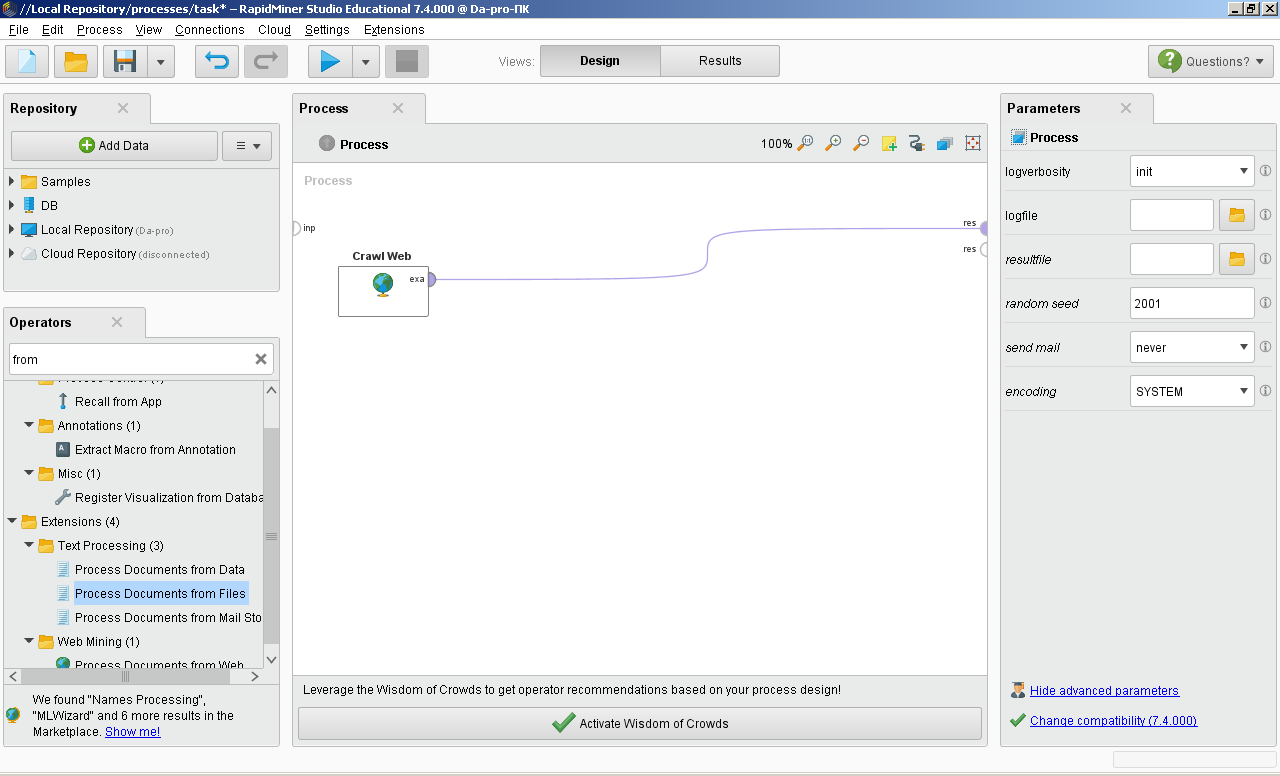 Рис.9 Соединение компонента Crawl Web с выходом для обработки 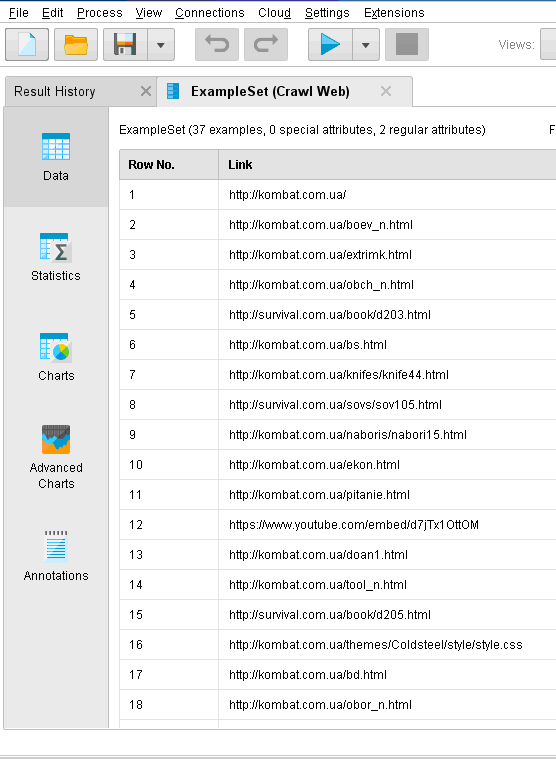 Рис.10 Результат анализа заданного сайта с помощью компонента Crawl Web 4. Использование Process Dociment from files Выберем из палитры компонентов с помощью поиска Process Documents from Files (рис.11). Зададим каталог, куда были сохранены результаты работы компонента Crawl Web (рис.12) для обработки.  Рис.11 Окно выбора компонента Process Documents from Files 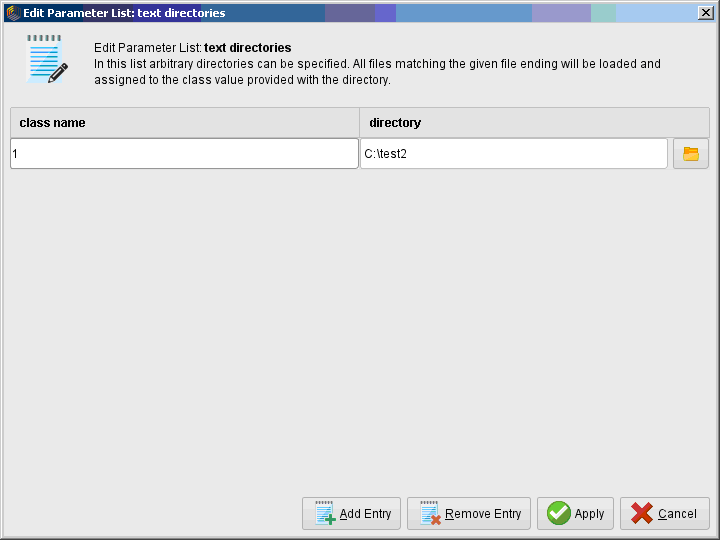 Рис.12 Окно задания пути к данным для работы компонента Process Documents from Files Применим компонент Tokenize в составе Process Documents from Files для анализа текста (рис.13) в режиме «non letters». Добавим компонент фильтрации по длине символов (от 4 до 15), результат приведен на рис.14. 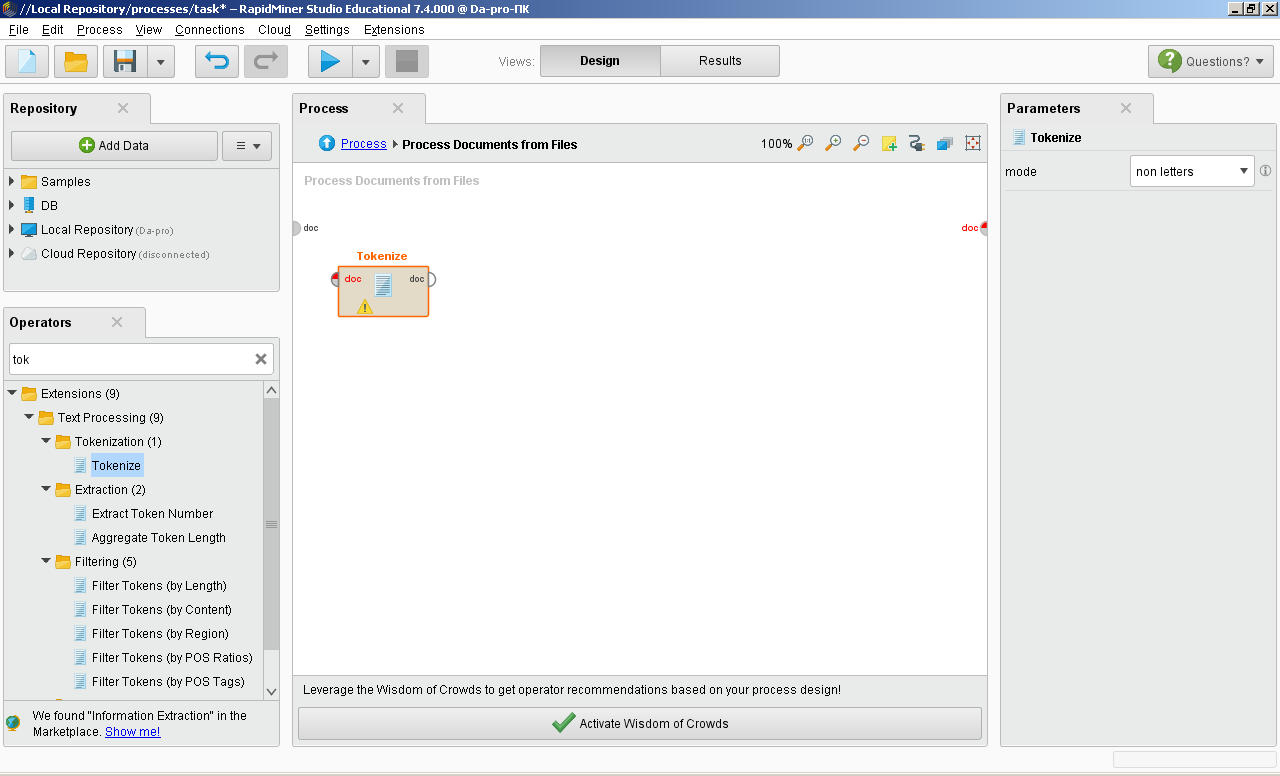 Рис.13 Применение компонента Tokenize в составе Process Documents from Files для анализа текста 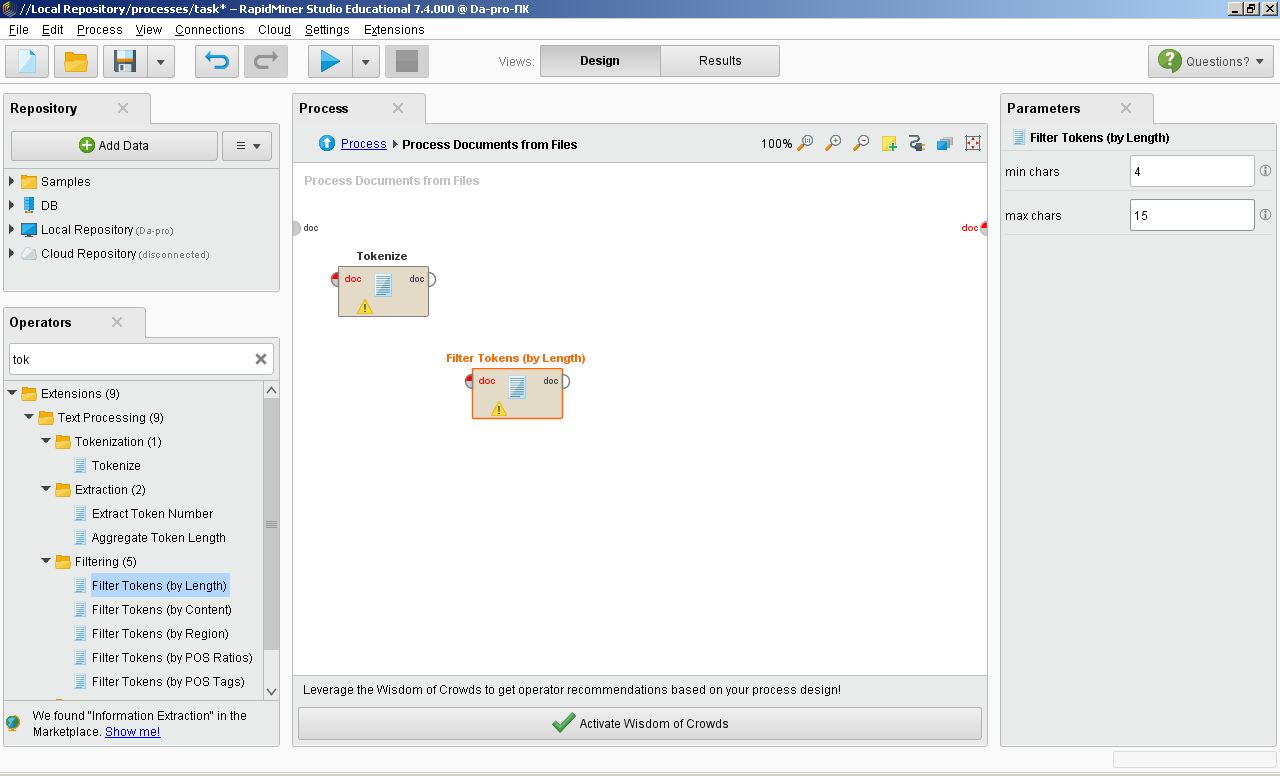 Рис.14 Применение компонента фильтрации Filter Tokens (by Length) в составе Process Documents from Files для анализа текста Итоговый состав сконфигурированных компонентов фильтрации в Process Documents from Files для анализа текста (фильтр по количеству символов, стоп-слов и преобразования регистра символов) приведен на рис.15. 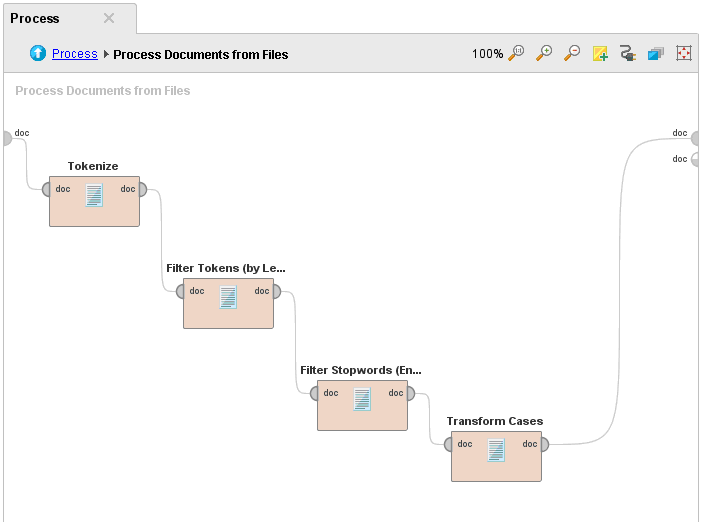 Рис.15 Итоговый состав компонентов фильтрации в Process Documents from Files для анализа текста 5. Проведение кластеризации На базе работы компонента Process Documents from Files необходимо обеспечить кластеризацию документов. Для этого найдем и подключим компонент K-means (каталог Modelling-Segmentation) (рис.16 и 17). 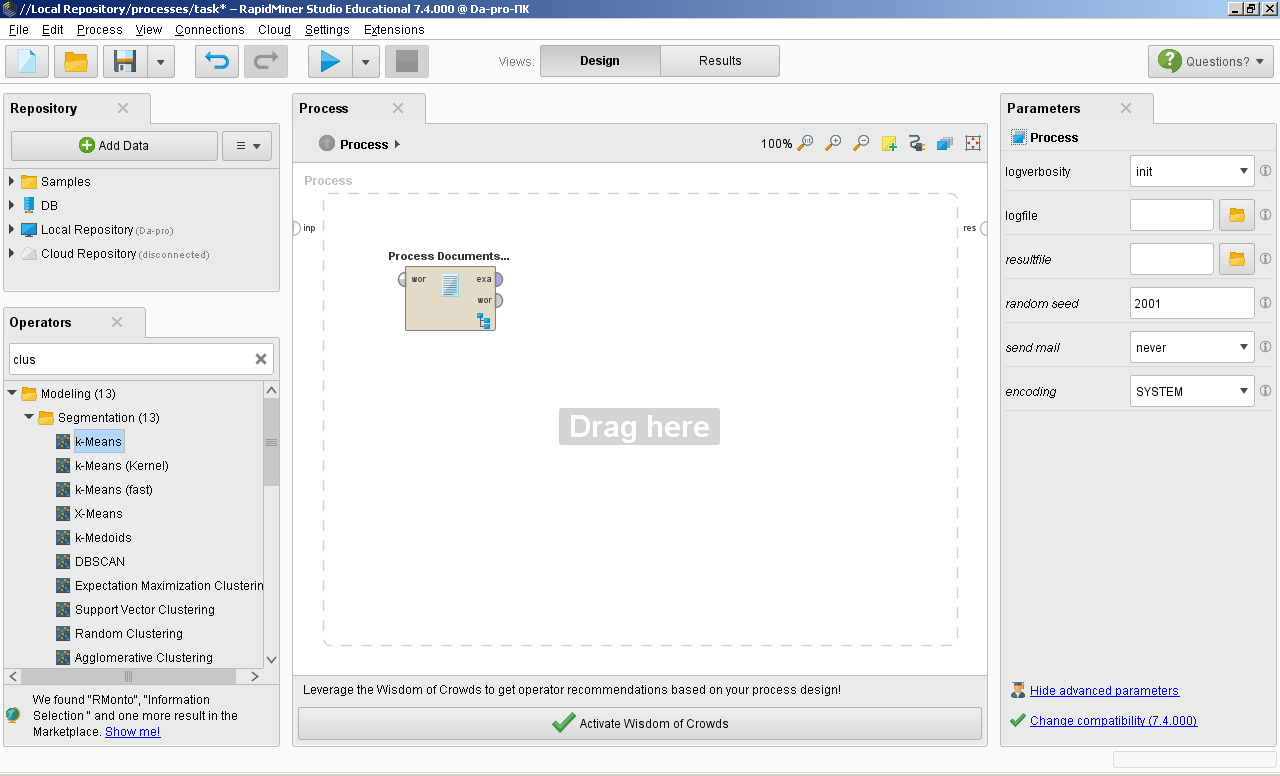 Рис.16 Поиск компонента кластеризации K-means 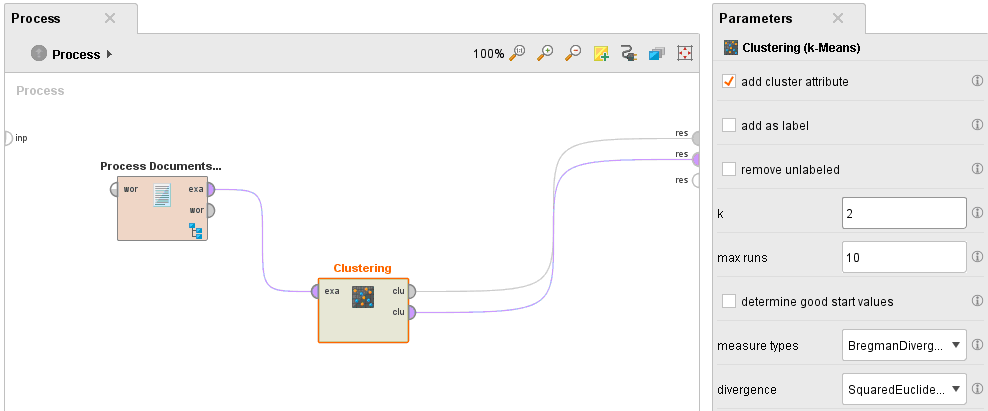 Рис.17 Результат размещение компонента кластеризации K-means После подключения компонента запустим созданную модель, результаты отображаются в окне результатов во вкладках ExampleSet и Cluster Model (рис.18-20). 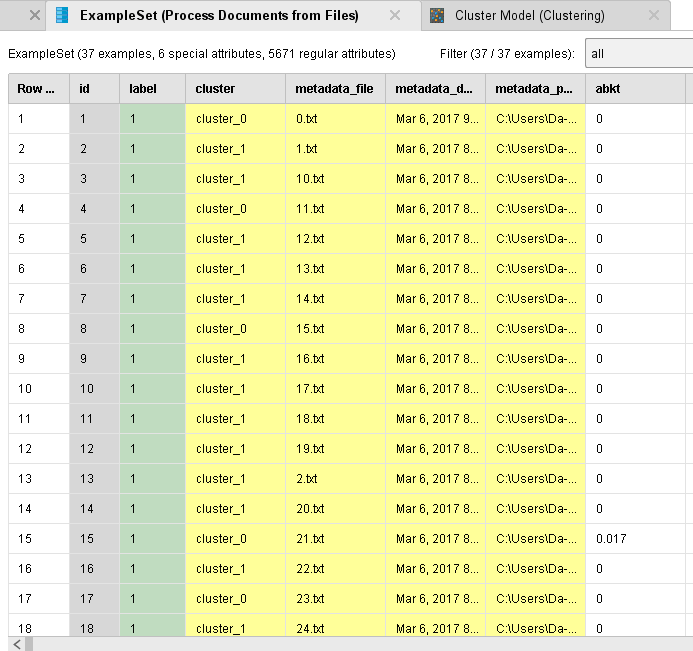 Рис.18 Вкладка просмотра информации о результатах обработки данных 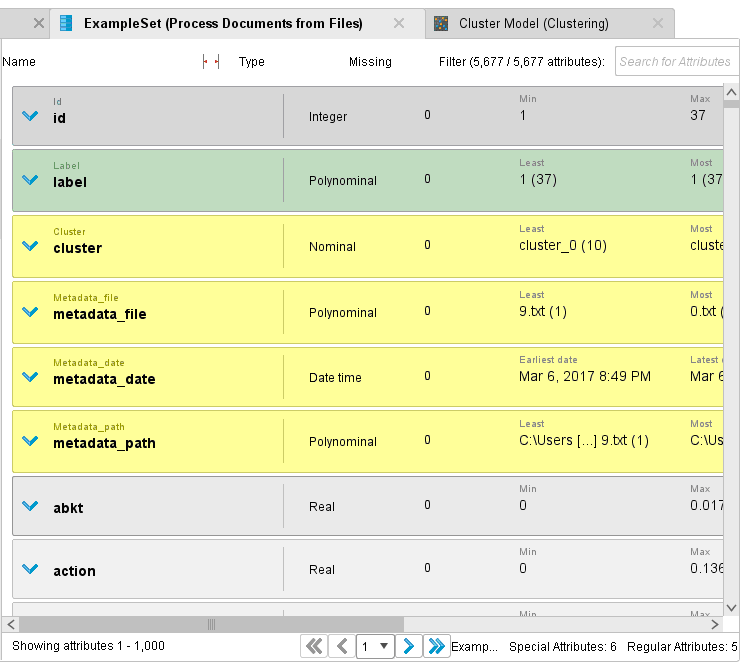 Рис.19 Вкладка просмотра результатов по статистике полученной модели (часть 1) 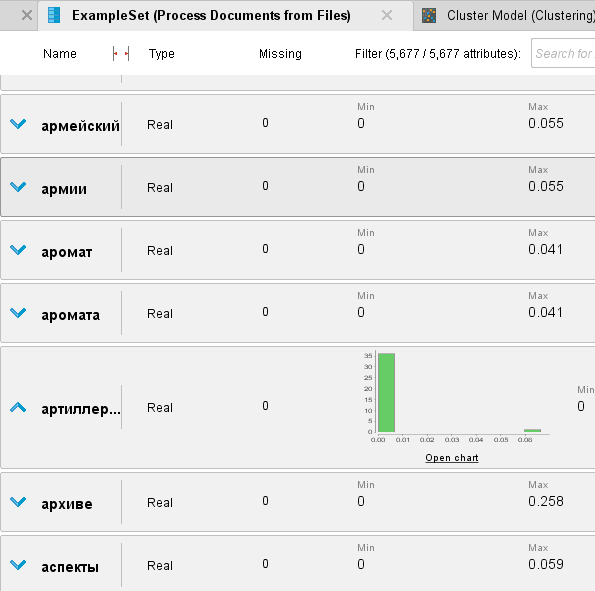 Рис.20 Вкладка просмотра результатов по статистике полученной модели (часть 2) Описание результатов модели кластеризации (количества документов по каждому кластеру и общего количество проанализированных материалов и другие статистические данные) приведено на рис.21-24. 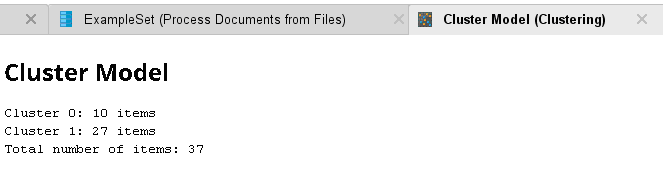 Рис.21 Вкладка описания результатов модели кластеризации 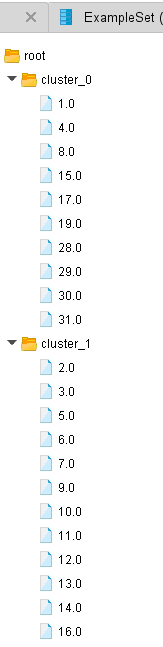 Рис.22 Вкладка просмотра результатов кластеризации текстовых файлов по 2-м категориям cluster_0 и cluster_1 (часть 1) 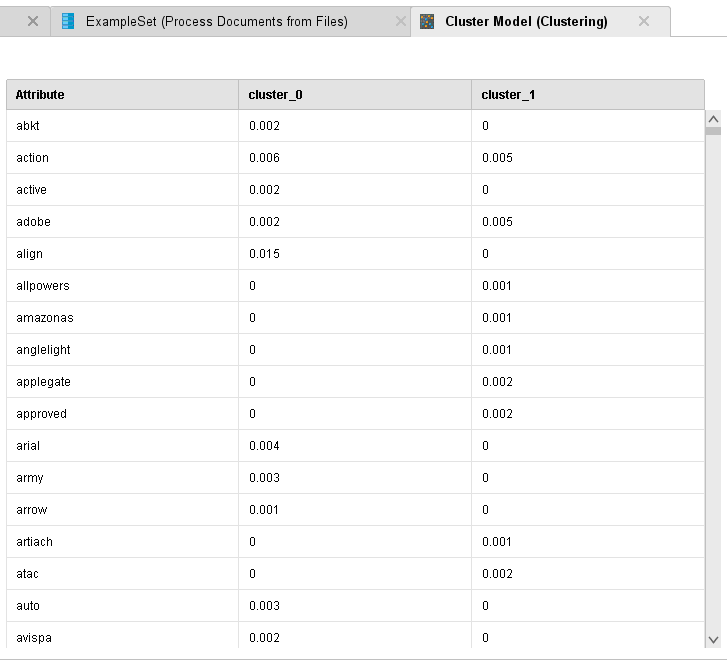 Рис.23 Вкладка просмотра результатов кластеризации текстовых файлов по 2-м категориям cluster_0 и cluster_1 (часть 2) 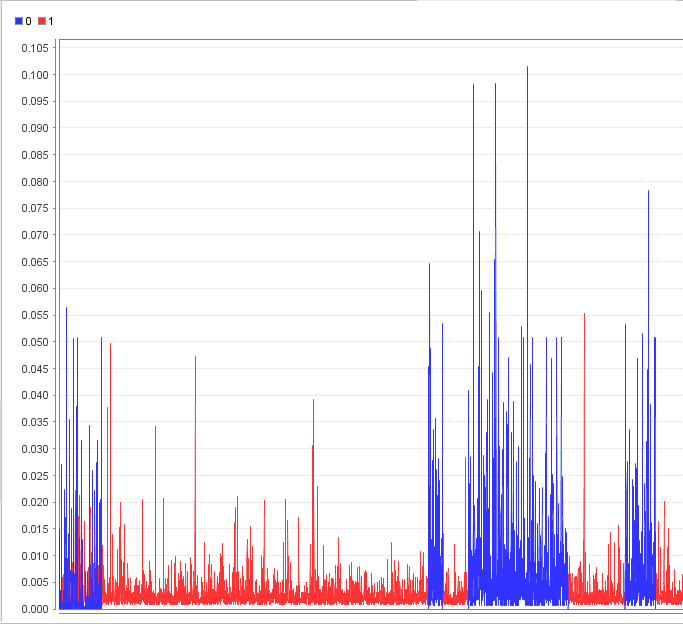 Рис.24 Графическая визуализация результатов кластеризации по обработанным словам в текстовых документах Как можно заметить, количество текста, отнесенного к 1-му кластеру (красный цвет), превышает значение 2-го кластера (синий цвет), что свидетельствует о большей степени корреляции проанализированных данных в 1-м кластере. Это свидетельствует о том, что на анализируемом веб-ресурсе информация не является в полной степени однородной и узко-тематичной, семантика разнообразна, в чем можно удостовериться умозрительно изучив данный веб-сайт. На основании этого можно утверждать, что поставленная задача и цель работы выполнены, проведена кластеризация данных веб-сайта на базе использования программного продукта Rapid Miner. |