1. Жйелер теориясыны негізгі элементтерін натылап крсетііз. Жйені асиеттерін атаыз жне р асиетіне сипаттама берііз
 Скачать 2.19 Mb. Скачать 2.19 Mb.
|

|
Өзара ақпараттың қасиеттері: 1. Симметриялық: I (x; y) = I ( y; x) . 2. Егер x және y тәуелсіз болса, онда I (x, y) = 0 X және Y ансамбльдері арасындағы орташа өзара ақпарат деп I (X;Y) = M[I (x; y)] өлшемі айтылады. Орташа өзара ақпаратты ортақ үлестірім ықтималдығы арқылы өрнектейтін формула  Орташа өзара ақпараттың қасиеттері 1 қасиет. Симметриялық I (X;Y) = I (Y; X ) . 2 қасиет. Теріс болмаушылық: I (X;Y) ≥ 0. 3 қасиет. X және Y ансамбльдері тәуелсіз болған кезде, тек сол кезде ғана I(X;Y)=0 тепе-теңдігі орын алады. 4 қасиет. I (X;Y) = H(X ) − H(X | Y) = = H(Y) − H(Y | X ) = = H(X ) + H(Y) − H(XY) . 5 қасиет. I (X;Y) ≤ min{H(X ),H(Y)}. 6 қасиет. I (X;Y) ≤ min{log | X |, log | Y |}. 7 қасиет. Өзара ақпарат I (X;Y) – p(x) үлестірім ықтималдығының дөңес ∩ функциясы. 8 қасиет. Өзара ақпарат I (X;Y) – p(у|x) шартты үлестірімінің ойыс ∪ функциясы. 30.ЦИФРЛЫҚ АҚПАРАТТЫ СЫҒУ ӘДІСТЕРІ. Анықтама. Ақпаратты кодтау артықтық болып табылады, егер алғашқы ақпаратты декодтауға қарағанда, алынған кодта бит саны артық болса. Ақпаратты сақтау және беру нақты ресурстар шығынын қажет етеді. Деректерді сығу (сақтау немесе байланыс каналы арқылы беру алдында) осы шығындарды азайтуға мүмкіндік береді. Ақпараттарды сығудың теориялық негізі 1940 жылдардың соңында қалана бастады. К.Шеннонның мақаласы жарияланды: «Коммуникацияның математикалық теориясы». Сығу әдістерін екі үлкен топқа бөлуге болады: 1. Қайтарылатын 2. қайтарылмайтын Қайтарылатын алгоритмдеркіріс деректерін ең ықшам кодталатын формаға келтіре отырып, тек кіріс деректерінің берілу тәсілін өзгертеді. Мұндай алгоритмдер үшін кері алгоритм бар, олар сығылған жиымнан алғашқы деректерді қалпына клтіре алады. Қайтарылатын алгоритмдерді кез-келген типті деректерді сығу үшін қолдануға болады. Ақпаратты жоғалтпай сығылатын файлдар форматтары: • GIF, TIF, PCX, PNG — графиктік деректер үшін; • AVI — кезектесетін видео- және дыбыс деректері үшін; • ZIP, ARJ, RAR, LZH, LH, CAB — деректердің кез-келген типі үшін Анықтама: Сығу әдісі қайтарылатын деп аталады, егер сығу кезінде деректер жоғалмайтын болса. Қайтарылатын әдістердің негізгілері: Қаттау (упаковка) әдісі Хаффман алгоритмі RLE алгоритмі Лемпель—Зив алгоритмі RLE (ағ. Run-Length Encoding — қайталану санын есепке ала отырып кодтау) алгоритмінің негізі қайталанатын тізбектерді табу қағидасына сүйенеді: қайталанатын фрагменттер мен қайталану коэффициенттері. RLE кодтау әдісімен ақпаратты кодтау: тізбек басқару байттарынан тұрады. Егер сандар тізбегі бірнеше рет қатарынан қайталанса, онда басқарушы байт 1-ден басталады да, одан кейін қайталанатын сан жазылады. Егер сандар тізбегі қайталанбаса, онда басқарушы байт 0-ден басталады да, сандар өзгертілмейді. RLE кодтау әдісімен ақпаратты қалпына келтіру: тізбек басқару байттарынан тұрады, егер басқару байтының басы 1 –ге тең болса, онда басқару байтынан кейінгі деректерді сонша рет қайталау керек. Ал егер 0-ге тең болса, онда одан кейін байттарды өзгертпеу керек. Егер басқару байты 10000111 болса, онда одан кейінгі байтты 7 рет қайталау керек, ал басқару байты 00000100 болса, онда одан кейінгі 4 байтты өзгеріссіз қалдыру керек. Сығу дәрежесін жақсарту үшін жиі қайталанатын символдарды қысқа кодпен, ал сирек кездесетіндерді ұзын кодпен алмастыру керек. Бүл әдіс идеясын ұсынған - Д. Хаффман (1952 жыл). Хаффман алгоритмінің көмегімен деректерді сығу: кездесетін символдар жиілігі есептелінеді, содан кейін Хаффман кодтау ағашы тұрғызылады. Кодтау ағашы бойынша символар коды жасалынады. Хаффман ағашын тұрғызу алгоритмі: Алғашқы символдар бос түйіндер тізімін құрайды. Әр түйіннің алғашқы хабарламадағы символдар санына тең салмағы бар. Тізімнен ең кіші салмағы бар екі бос түйін таңдалады. Олардың салмақтарының қосындысына тең салмағы бар «ата-ана» түйіні құрылады, ол «ұрпақтарымен» доға арқылы байланысады. «Ата-анадан» шығатын бір доғаға 1, екіншісіне 0 қойылады. «Ата-ана» бос түйінді тізімге қосылады, ал оның «ұрпақтары» тізімнен жойылады. Тізімдегі қадам тек бір бос түйін қалғанша қайталана береді. Ол ағаштың басы (тамыры) болып есептелінеді. Мысалы. «КОЛ_ОКОЛО_КОЛОКОЛА» мәтіні үшін Хаффман ағашын тұрғызу және префикстік кодты алу:  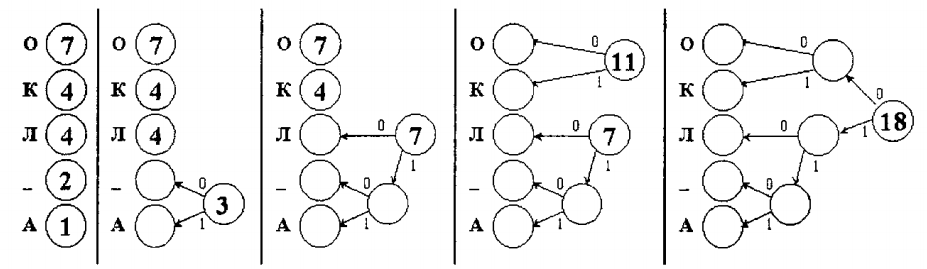 Лемпель—Зив алгоритмдері (LZ77, LZ78) Хаффман алгоритмінде символдар кодталса, ал L Z77, LZ78 алгоритмдерінде сөздер кодталады. LZ77 алгоритмі : • КОЛОКОЛ_ОКОЛО_КОЛОКОЛЬНИ КОЛО(-4,3)_0(-8,4)_(-14,7)ЬНИ. |