информатика. Глава 1, часть 2_р. 1 Кодирование текстовых и символьных данных
 Скачать 5.84 Mb. Скачать 5.84 Mb.
|

1.8. Кодирование звуковой информацииМетоды работы со звуковой информацией пришли в вычислительную технику наиболее поздно. В итоге они далеки от стандартизации. Отдельные компании разработали свои корпоративные стандарты, однако можно выделить два основных подхода. Метод частотной модуляции (метод FM — Frequency Modulation) основан на разложении сигнала в виде суперпозиции элементарных гармоник с разными фазами, частотами и амплитудами. В природе звуковые сигналы имеют непрерывный спектр. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналого-цифровые преобразователи (АЦП). При воспроизведении происходит обратное преобразование — цифро-аналоговое (ЦАП). Конструктивно АЦП и ЦАП находятся в звуковой карте компьютера. При таких преобразованиях неизбежны потери информации, связанные с методом кодирования. Метод компактен, но качество звучания не очень высокое и соответствует качеству звучания простейших электромузыкальных инструментов. Метод таблично-волнового синтеза (Wave-Table) заключается в том, что образцы звуков для множества различных музыкальных инструментов (сэмплы) хранятся в особых таблицах. Числовые коды выражают тип инструмента, высоту тона, продолжительность и интенсивность звука, динамику его изменения и другие особенности. Затем при моделировании звуковой информации эти образцы смешиваются. Качество звука, полученное в результате синтеза, приближается к качеству звучания реальных музыкальных инструментов. 1.9. Структуры данныхВ современных ЭВМ данные всегда велики по объему. Работать с ними проще, если данные упорядочены, т. е. образуют заданную структуру. Существует три основные типа структур: линейная, табличная и иерархическая. Самая простая структура данных — линейная (список) — это упорядоченная структура, в которой адрес элемента однозначно определяется его номером. В качестве примера можно взять обычную книгу. При создании любой структуры данных надо решить, как разделять элементы данных между собой и как разыскивать нужные элементы. В качестве разделителя обычно используется какой-нибудь специальный символ. Табличные структуры отличаются от списочных лишь тем, что элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списке, а из нескольких. В двумерных таблицах разделителей должно быть два. Таблица может быть и трехмерная, тогда три числа характеризуют положение элемента и требуются три типа разделителей, а может быть и Нерегулярные данные, которые трудно представить в виде списка или таблицы, представляются иерархически. Иерархическую структуру имеет система почтовых адресов. В такой структуре адрес каждого элемента данных определяется путем доступа к нему (маршрута), ведущим от вершины структуры к данному элементу. Каждый из описанных видов структур данных имеет свои преимущества и недостатки. Например, списочные и табличные структуры являются простыми. Ими легко пользоваться, они легко упорядочиваются, однако их трудно обновлять. При обновлении нарушается вся списочная или табличная структура. Иерархические структуры данных сложнее, чем списочные или табличные, но они не создают проблем с обновление данных. Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочивания. 1.10. Файлы и файловая структураВ компьютерных технологиях единицей хранения данных является объект переменной длины, называемый файлом. Файл — это последовательность произвольного числа байтов, обладающая уникальным именем. Файловые системы создают для пользователей некоторое виртуальное представление внешних запоминающих устройств ЭВМ, позволяя работать с ними не на низком уровне команд управления физическими устройствами, а на высоком уровне наборов и структур данных. Таким образом, файловая система — это система управления данными. Имя файла имеет особое значение — оно фактически несет в себе адресные функции в иерархических структурах. Кроме того, имя может иметь расширение, в котором хранятся сведения о типе данных. Если имена создаваемых файлов пользователь может задавать произвольно, то в использовании расширений следует придерживаться некоторой традиции. Например, в операционной системе MS DOS файлы с расширениями: com, exe, bat — исполняемые; bat, txt, doc — текстовые; pas, bas, c, for — тексты программ на известных языках программирования (Паскале, Бейсике, Си, Фортране соответственно); dbf — файл базы данных. В различных операционных системах существуют ограничения на длину имени и расширения имени файла. Так, в MS DOS длина имени файла не должна превышать восьми символов, а расширение — трех, т. е. используется стандарт 8.3. В операционной системе Windows ограничения значительно менее жесткие. Для пользователя файл является основным и неделимым элементом хранения данных, который можно найти, изменить, удалить, сохранить либо переслать на устройство или на другой компьютер, но только целиком. Файловая система — это часть операционной системы компьютера и поэтому всегда несет на себе отпечаток свойств конкретной операционной системы. Файловая система скрывает от пользователя картину реального расположения информации во внешней памяти, обеспечивает независимость программ от особенностей конкретной конфигурации ЭВМ, т. е. логический уровень работы с файлами. При работе с файлами пользователю предоставляются средства для создания новых файлов, операции по считыванию и записи информации и т. п., не затрагивающие конкретные вопросы программирования работы канала по пересылке данных, по управлению внешними устройствами. Наиболее распространенным видом файлов, внутренняя структура которых обеспечивается файловыми системами различных операционных систем, являются файлы с последовательной структурой. Файлы в этом случае представляются в виде набора составных элементов, называемых логическими записями произвольной длины и с последовательным доступом. В ряде операционных систем предусматривается использование более сложных логических структур файлов, например, древовидной структуры. На физическом уровне блоки файла могут размещаться в памяти непрерывной областью или храниться несмежно. Вся учетная информация о расположении файлов на магнитном диске сводится в одно место — каталог или директорию диска. Каталог представляет собой список элементов, каждый из которых описывает характеристики конкретного файла, используемые для организации доступа к нему — имя файла, его тип, местоположение на диске, размер. Каталогов может быть большое число, и они связываются в информационные структуры, например, в иерархическую (древовидную) систему каталогов. Каждый каталог рассматривается как файл и имеет собственное имя. Полное имя каталога или файла в такой структуре задает путь переходов между каталогами и файлами в логической структуре каталогов (рис. 1.5). Рис. 1.5. Иерархическая система каталогов Структура самых файлов может быть тривиальной. Например, текст может сохраняться в виде последовательности байтов, соответствующих кодировке таблицы ASCII. Однако в большинстве случаев вместе с данными приходится хранить и некоторую дополнит 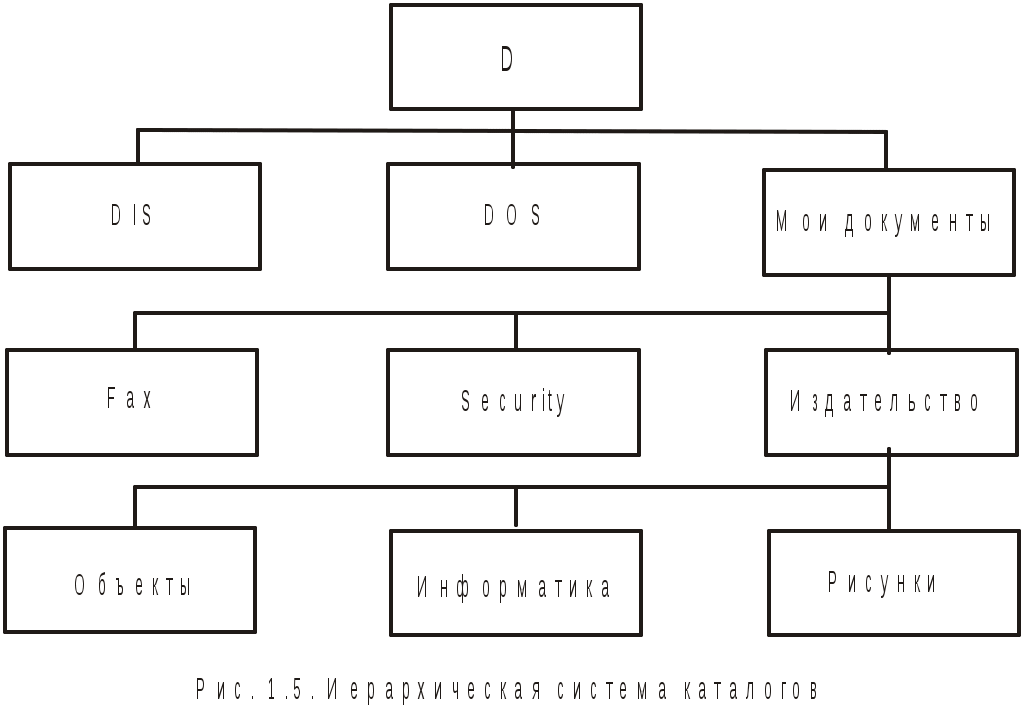 ельную информацию. Способ организации данных в файле, т. е. структура файла, называется форматом. Формат файла определяет способ правильной интерпретации хранимых данных. Существует довольно много различных форматов файлов. Некоторые из них стандартизированы и поддерживаются любой операционной системой, некоторые специфичны только для данных операционных систем. Часто заголовок файла включает идентификатор формата файла. Современные программные системы позволяют одновременно включать в файл данные разных видов, т. е. файл может иметь очень сложный формат. Например, в документ MS Word можно включать текст, картинки, таблицы, формулы и многое другое. В большинстве случаев пользователю ничего не нужно знать о внутреннем устройстве файлов. Это уровень абстракции интерфейса операционных систем. |