1. специфікація мови програмування
 Скачать 166.09 Kb. Скачать 166.09 Kb.
|

|
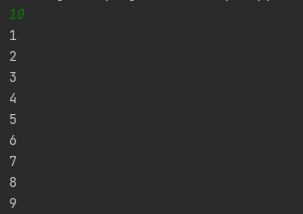
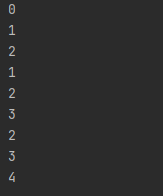
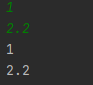
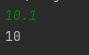
ВСТУП Мова програмування - це інтерфейс, за допомогою якого програміст може створювати алгоритми та транслювати ці алгоритми в код, зрозумілий процессору. З роками мови програмування поліпшилися. Таким чином, було розроблено assembler, що допомагав легче створювати програми. З часом з’явилися мови програмування високого рівня, такі як C, C++ з ООП. Надалі еволюцією мов програмування стали скриптові мови. Більшість з них підтримує динамічну типізацію и полегшує роботу, але за це приходиться платити часом виконання. Завдання цієї роботи - розробити транслятор і інтерпретатор для заданої граматики мови. Також розробити інтерфейс користувача і протестувати мову. Цільова мова надає користувачу механізми для виконання базових операцій, таких як: створення змінних, присвоєння значень, операції порівняння, операції множення, додавання, віднімання і ділення. Також мова надає доступ до операторів розгалуження, циклу, виведення до консолі. Алгоритм трансляції: На вході приймається файл з текстом програми. Текст програми передається в лексичний аналізатор, який розбиває програму на так звані лексеми - розпізнані частини тексту. Лексер оперує такими лексемами: ідентифікатор, число, строковий літерал, оператор, ключове слово. Массив лексем передається в синтаксичний аналізатор, який будує абстрактне синтаксичне дерево за допомогою методу рекурсивного спуску. Побудоване абстрактне синтаксичне дерево перевіряється на логічні помилки, наприклад, спроба доступу до неоголошеної змінної, тощо. Перевірене абстрактне синтаксичне дерево компілюється в інструкції для віртуальної машини. Після трансляції, код віртуальної машини можна виконати за допомогою ARE (Ape Runtime Environment). 1. СПЕЦИФІКАЦІЯ МОВИ ПРОГРАМУВАННЯ 1.2 Опис мови Цільова мова підтримує змінні трьох типів: int, float та bool. Цілі та дійсні числа можуть мати від’ємне значення. Тип змінної вказується при ініціалізації. Під час ініціалізації змінній можна присвоїти значення. Синтаксис мови С-подібний. 1.3 Синтаксис Літерали Синтаксис Const = IntegerConstant | FloatConstant | BooleanConstant IntegerConstant = [Sign] UnsignedInteger FloatConst = [Sign] UnsignedFloat | UnsignedDoubleExpForm Sign = ‘+’ | ’-’ UnsignedInteger = Digit {Digit} UnsignedDoubleExpForm = UnsignedDouble ’e’ [Sign] IntegerNumber UnsignedFloat = UnsignedInteger ’.’ UnsignedInteger BooleanConstant = true | false Обмеження Кожен з представлених літералів має тип даних. Значення літералу обмежується допустимими значеннями. Під час лексичного аналізу знаходяться літерали типів BoolConstant, IntegerConstant, FloatConstant. Літерали можуть бути знаковими та беззнаковими. Семантика Кожен літерал відноситься до типу даних, що визначається його синтаксисом. Приклади 18, -239, 1.54, 34.5167, 2e+243 , true, false Інструкції Синтаксис DoSection = ’{’ Statements ’}’ Statements = Statement { Statement } Statement = (Assign | Input | Output | Declaration) ‘;’ | ForStatement | IfStatement | DopStatement | DoWhileStatement Опис Інструкції та директиви (statements) визначають алгоритм программи. Семантика Інструкції та директиви виконуються послідовно у їх слідування, допоки не зустрінуться розгалуження або цикл. Приклад if(true) { int foo = 12; foo = 13; int bar = 10; bar = 21 ^2; float baz = 10.2; baz = baz + baz; } Вирази Синтаксис BooleanExpr = BooleanTerm | BooleanExpr ‘||’ BooleanTerm BooleanTerm = BooleanFactor | BooleanTerm ‘&&’ BooleanFactor BooleanFactor = BooleanRelation | ‘(‘ BooleanTerm ‘)’ BooleanRelation = Expression [RelationOperator Expression] Expression = Term | Expression AddOperator Term Term = Factor | Term MultiplyOperator Factor Factor = FirstExpression | Factor PowerOperator FirstExpression FirstExpression = ‘(’ Expression ‘)’ | Identifier | Const Опис Вираз - це оператори і операнди, записані у деякій осмисленій послідовності. Вирази бувають логічними та арифметичними. Результатом арифметичного виразу буде тип real або int. Результатом логічного виразу буде тип bool. Всі представлені бінарні оператори ліво ассоциативні окрім степені. Пріоритети операторів: (), || ,&&, <, >, <=, >=, ==, !=, ^, *, /, -, + Послідовність операторів з однаковим значенням пріоритету асоціативна. Обмеження Кожна змінна повинна бути проініціалізована та типізована. Повторна декларація змінної викличе помилку компіляції на стадії валідації абстрактного синтаксичного дерева. Використання неоголошеної змінної, викликає помилку на етапі трансляції. Використання змінної, що не буза задекларована, викликає помилку. Семантика Кожен літерал містить інформацію про тип даних, визначений його синтаксисом. Змінна набуває значення в інструкції присвоювання Assign або в інструкції введення даних Input з потоку stdin. Приклади FirstExpression: 11, x, (a + 2 * 4) BooleanExpression: b == 2, 2 < 100 || a <= 2, (x * x + a / b) >= l Оголошення змінної Синтаксис Initialization = Type IdentDeclaration IdentDeclaration = Ident [‘=’ Expression] Type = int | float | bool Опис Оголошення декларує набір iдентифiкаторiв змінних, що можуть бути використані у подальшому в програмі. Обмеження Кожен ідентифікатор має бути оголошений. В області видимості можна переоголошувати змінні з зовнішньої області видимості. Семантика Оголошення змінної призводить до виділення динамічної пам’яті для зберігання значення змінної. Значення оголошеної змінної визначається за допомогою інструкцій присвоювання при ініціалізації або надається за замовчування. Приклад int foo; float bar; bool baz; Інструкція присвоєння Синтаксис Assign = Identifier ’=’ Expression Опис Значення, які можуть використовуватись у лівій та правій частинах інструкції присвоювання називають l-значенням та r-значенням (або lvalue та rvalue, або left-value та right-value). Тип змінної з ідентифікатором Identifier не обов’язково повинен збігатись з типом r-значення. Працює автоматичне приведення типу даних. Семантика l-значення вказує на місце зберігання значення змінної з потрібними ідентифікатором та індексом. r-значення має тип значення, обчисленого за виразом BooleanExpression. Приклад a = 2*2+2, b = 2+2 < 5 Оператор розгалуження Синтаксис if <відношення> { <оператор> } else { <оператор> } IfStatement = if ‘(‘ BooleanExpression ‘)’ DoBlock1 else DoBlock2 DoBlock1 = DoBlock DoBlock2 = DoBlock DoBlock = ’{’ Statements ’}’ Опис Тіло оператора циклу DoBlock1 виконується один раз, якщо виконується умова BooleanExpression. Тіло оператора циклу DoBlock2 виконується один раз, якщо НЕ виконується умова BooleanExpression. Семантика Якщо виконується умова BoolExpr, тобто умова є true, то виконується DoBlock1, якщо ні то DoBlock2. Приклад if (true) { print(true); } else { print(false); } Оператор циклу Синтаксис ForStatement = for ‘(’ Statement1 ‘;’ BooleanExpression ‘;’ Statement2 ‘)’ DoBlock IndExpr = Type Ident ’=’ BoolExpression Statement1 = Statement Statemtn2 = Statement DoBlock = ’{’ Statements ’}’ Опис Інструкції в тілі оператора циклу DoBlock виконуються один або декілька разів, в залежності від умов. Семантика Перед першою ітерацією виконується Expression1 один раз. Якщо значення BooleanExpression дорівнює true, то виконується Statement2. DoBlock виконується до тих пір,доки значення BooleanExpression = true. Приклад for (int i = 0; i < 100; i = i + 1) { print(i); } Оператор введення Синтаксис Input = read ’(’ Identifier ’)’. Опис Значення вводяться з потоку stdin. Значення перевіряються у відповідності до типу даних змінної. Приклад read(a); . Оператор виведення Синтаксис Output = print ’(’ BooleanExpression ’)’. Опис Значення виводиться до потоку stdout. Параметром може бути вираз, що буде виконано. Приклад print(2 + 2 + a); 1.4 Формат таблиць Таблиця символiв програми (таблиця розбору) Розбір реалізовано за допомогою методу nextToken классу Lexer. Метод повертає екземпляр классу Token, який містить в собі наступну інформацію: type - Тип лексеми. payload - Значення лексеми. line - строка в якій знаходиться лексема в тексті програми. column - колонка початку лексеми в тексті програми. Лексеми бувають наступних типів: NUMBER IDENTIFIER KEYWORD SYMBOL LINEBREAK EOFILE STRING UNSUPPORTED EMPTY При розборі літералів, операторів, ключових слів і констант використовуються класси, що розширюють Token. Наприклад, NumberToken, OperatorToken, KeywordToken. Висновок В наведеному вище розділі було представлено специфікацію мови програмування ApeLang, яка дає змогу зрозуміти особливості написання коду і використання операцій цієї мови. Було наведено структуру, сементику, обмеження , синтаксис і список операторів. 2. АРХІТЕКТУРА, МЕТОДИ ТА АЛГОРИТМИ Архітектура розробленого компілятора складається з лексичного аналізатора, що розбирає вхідний текст на набір лексем. Далі, семантичний аналізатор створює абстрактне синтаксичне дерево за допомогою методу рекурсивного спуску. Суть методу в аналізі токенів за допомогою рекурсивного викликуу або циклічно рекурсивного виклику методів аналізу різних синтаксичний структур мови. Це дерево перевіряється на логічні помилки і передається в транслятор, який перетвор.є абстрактне синтаксичне дерево у набір інструкцій у ПОЛІЗ-подібному вигляді інструкцій для віртуальної машини.  Рис. Архітектура системи. 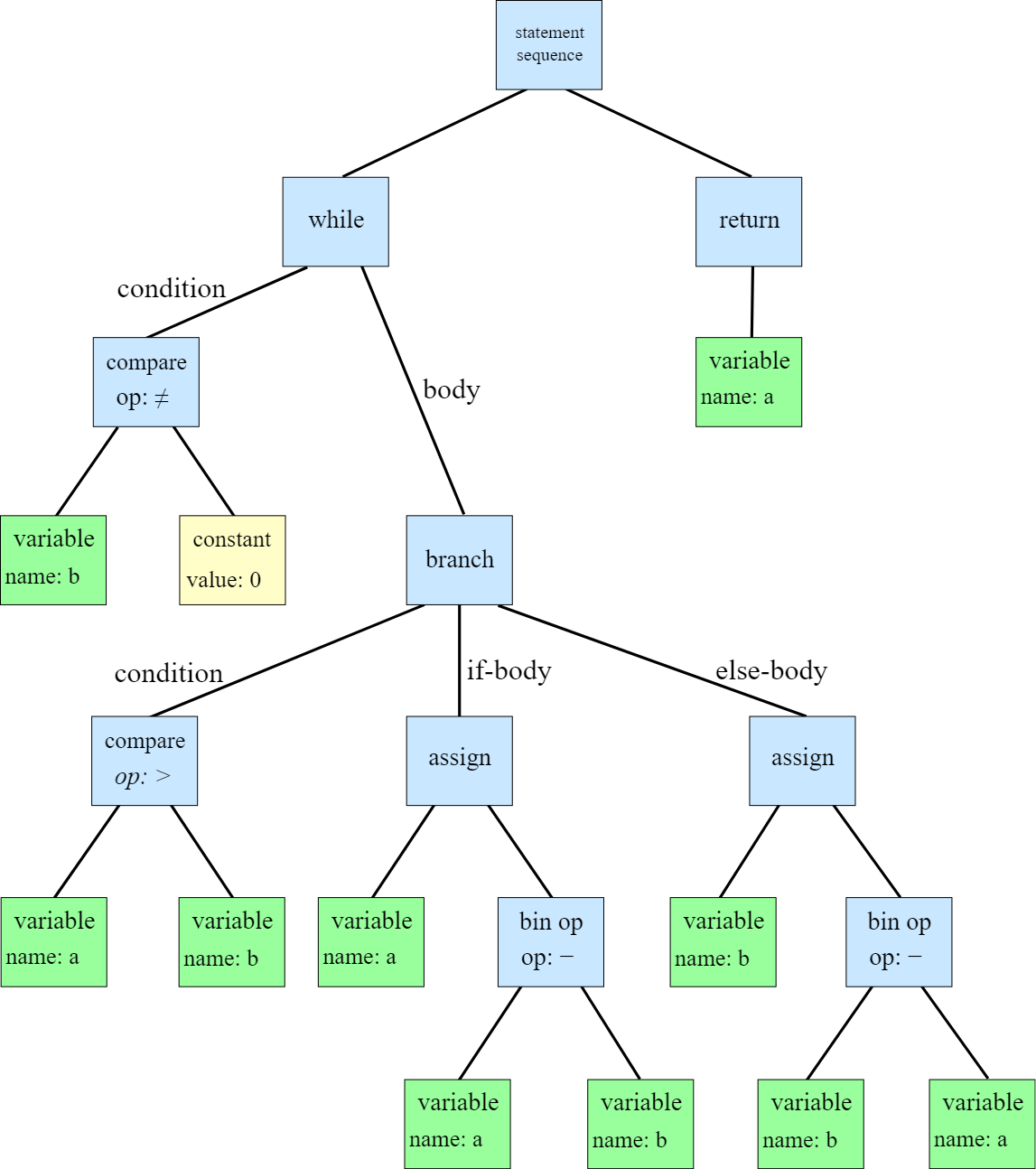 Рис. Абстрактне синтаксичне дерево. Для оптимізації роботи з пам'яттю лексичний аналізатор являється модулем, реалізуючим метод nextToken(). Таким чином, він не генерує массив токенів а завжди повертає наступний. Цей підхід використовується у класі Tokenizer. Після трансляції у набір ПОЛІЗ-подібних команд вони виконуються в віртуальній машині(інтерпретаторі). Команди для віртуальної машини представляють собою команди низького рівня, серед яких елементарні арифметичні операції між двома значеннями на вершині стеку, запис значень до стеку, видалення значень зі стеку, директива переходу(jump) та її розширення. Висновок В даному розділі представлено подробиці будови проекту та його архітектури. Описано метод рекурсивного спуску та особливості трансляції в ПОЛІЗ. Наведено взаємозв’язки між підсистемами. 3. ПРОГРАМНА РЕАЛІЗАЦІЯ 3.1 Опис програмної реалізації лексичного аналізатора Лексичний аналізатор працює за допомогою таблиці допустимих лексем, а саме: Переліку ключових слів. Переліку операторів. Перелік символів, що потрібно ігнорувати при розборі. Загальних правил розбору. Таким чином, лексичний аналізатор переміщується по тексту програми вперед і коли знаходить символ, що не потрібно ігнорувати - починає інтерпретувати наступні символи за пріоритетом: Цифра Оператор. Літерал. Ключове слово. Ідентифікатор. Метод Lexer::nextToken() з кожним викликом зміщується по тексту програми у напрямку від початку до кінця тексту і повертає наступну знайдену лексему. Для перевірки закінчення розбору тексту використовується метод Lexer::isEof(). Для розбору лексем на позиції курсора в тексті використовуються методи: Lexer::readNumber() Lexer::readIdentifier() Lexer::readSymbol() Lexer::readString() Якщо лексичний аналізатор знайшов заборонений символ - буде створено екземпляр виключної ситуації ApeLangException. 3.2 Опис програмної реалізації транслятора Трансляція виконується в три етапи: Створення абстрактного синтаксичного дерева. Перевірка абстрактного синтаксичного дерева на помилки. Трансляція у команди для інтерпретатора. Для створення абстрактного синтаксичного дерева використовується метод Tokenizer::parse(). Створення абстрактного синтаксичного дерева виконується за допомогою методу рекурсивного спуску. Реалізують цей механізм наступні методи классу: Tokenizer::statement() - операція. Tokenizer::parenExpr() - вираз в дужках. Tokenizer::argumentsDeclaration() - декларація аргументів функції. Tokenizer::arguments() - аргументи. Tokenizer::expression() - вираз. Tokenizer::declaration() - Декларація змінної. Tokenizer::test() - Логічний вираз. Tokenizer::summa() - Арифметичний вираз. Tokenizer::term() - Терм. Під час створення абстрактного синтаксичного дерева перевіряються синтаксичні помилки, такі як неправильний порядок слідування токенів. Базовим классом вузла дерева є класс Node. Його розширюють: DeclarationNode - вузол з інформацією про декларацію змінної. FloatNode - вузол з інформацією про занчення з плаваючою точкою. IntegerNode - вузол з інформацією про ціле число. LiteralNode - вузол з інформацією про строковий літерал. StringNode - вузол з інформацією про строку. VariableNode - вузол з інформацією про змінну. Кожен вузол має три посилання на операнди від 1 до 3. За замовчуванням всі посилання дорівнюють nullptr. 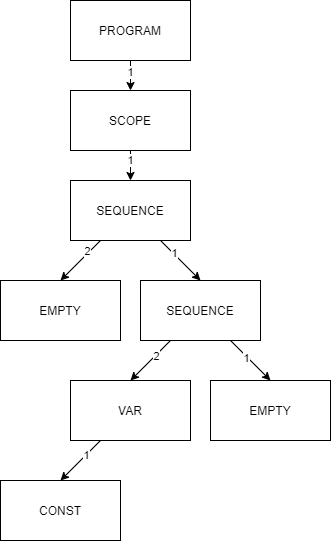 Рис. Схема абстрактного синтаксичного дерева. Після створення абстрактного синтаксичного дерева виконується перевірка останнього на логічні помилки, такі як: Використання незадекларованої змінної. Присвоєння неправильних типів даних. Перевірка здійснюється за допомогою метода Tokenizer::validateTree(). Метод перевіряє типи даних і області видимості. Після перевірки абстрактного синтаксичного дерева метод Compiler::compile() транслює інформацію з абстрактного синтаксичного дерева у набір команд для інтерпретатора. 3.3 Опис програмної реалізації інтерпретатора Для демонстрації незалежності інтерпретатора від транслятора інтерпретатор було реалізовано за допомогою мови python. Інтерпретатор реалізовано у вигляді стекової віртуальної машини для наглядності. Інтерпретатор йде послідовно по командах і виконує задані операції. Інтерпретатор розуміє наступні команди: FETCH x - покласти на стек значення змінної х. STORE х - зберегти в змінній х значення з вершини стеку. PUSH n - покласти число n на вершину стеку. POP - Видалити число з вершини стеку. ADD - скласти два числа на вершині стеку. SUBTRACT - Відняти від числа на вершині стеку число під вершиною стеку. MULTIPLY - Помножити два числа на вершині стеку. DIVIDE - Розділити число на вершині стеку на число під вершиною стеку. LT - Порівняти два числа на вершині стеку a < b. LTE - порівняти два числа на вершині стеку a ≤ b. EQ - Порівняти два числа на вершині стеку a = b. NEQ - Порівняти два числа на вершині стеку a ≠ b JZ a - Перейти до адреси a якщо на вершині стеку 0. JNZ a - Перейти до адреси a якщо на вершині стеку не 0. JMP a - Перейти до адреси a. HALT - Завершити роботу. Команди виконуються за правилами обробки виразів в ПОЛІЗ. Висновок У наведеному розділі показана програмна реалізація ключових механізмів компілятора. Трансляція виконується за допомогою побудови абстрактного синтаксичного дерева. Інтерпретація виконується за допомогою стеку. 4. ТЕСТУВАННЯ СИСТЕМИ В наступних таблицях наведено стратегію тестування. У лівій колонці - зміст тесту, в правій - очікуваний результат. Тести покривають основні допустимі помилки, а саме - помилки лексичного, синтаксичного, семантичного аналізаторів. Також тестуються помилки виконання скомпільованої програми. Таблиця 1 – Стратегія тестування
Таблиця 2 – Результат тестування
Висновок В стратегії тестування наведено приклади правильних і неправильних програм та реакцію системи на них. У випадку неправильних програм - вивід помилки, у випадку правильної - результат роботи. Програмну реалізацію проекту було протестовано за допомогою цих прикладів. ВИСНОВКИ В наведеній роботі було створено опис і специфікацію мови програмування ApeLang, створено програмну реалізацію наступних модулів: Лексичного аналізатора. Синтаксичного аналізатора. Семантичного аналізатора. Транслятора. Інтерпретатора. Після створення програмної реалізації біло наведено стратегію тестування і самі тести. В наведеній мові було реалізовано базові операції, такі як: додавання, віднімання, множення, ділення, степінь, робота з потоками вводу. Також було створено систему інформування користувача про помилку та її семантику. Трансляція відбувається у ПОЛІз-подібні інструкції для віртуальної машини Ape. Це забезпечує кросплатформеність мови і надає змогу програмісту не перейматись за розмірність змінних на операційних системах різної архітектури. |