АВМ. 1. Вычислительный процесс в эвм 4 Команды эвм 6
 Скачать 1.54 Mb. Скачать 1.54 Mb.
|

|
Внутренние прерывания. К прерываниям этого типа относят: группу программных прерываний (деление на нуль, переполнение, неверная адресация и т. п.), прерывания от схем контроля машины, сбоев системы питания и др. Обработка прерываний этого типа состоит в выдаче сообщений о причине прерывания, прекращении выполнения текущей программы и перехода к реализации другой программы либо, если дальнейшее функционирование системы невозможно, только в выдаче диагностического сообщения, локализующего причину отказа. В любом случае, при наступлении события, вызвавшего аварию, процессор не останавливается. Внешние прерывания. Эту группу прерываний представляют прерывания от внешних устройств. Обработка событий, связанных с выполнением операций обмена данными между внешними устройствами и ОЗУ, в конечном счете, сводится к запуску драйвера - программы, реализующей обмен с устройством конкретного типа (драйвер клавиатуры, драйвер монитора и т. п.). Внепроцессорные прерывания. Прерывания, обработка которых приводит к передаче управления общей шиной от процессора к контроллеру внешнего устройства с реализацией дальнейшего обмена между устройством и основной памятью по Общей шине напрямую без посредничества процессора, то есть без запуска какого-либо драйвера (см. п. 10.4.). Общая организация прерываний Механизм прерывания обеспечивается соответствующими аппаратно-программными средствами компьютера. Задачей аппаратных средств обработки прерывания в процессоре ЭВМ является приостановка выполнения одной программы (иногда называемой основной) и передача управления подпрограмме обработки прерывания. Поскольку для выполнения подпрограммы обработки прерывания используются различные регистры процессора (РОНы, счетчик команд, регистр флагов и т.д.), то информацию, содержащуюся в них в момент прерывания, необходимо сохранить для последующего возврата в прерванную программу. Обычно задача сохранения содержимого счетчика команд и регистра флагов, содержащего вектор состояния процессора возлагается на аппаратные средства обработки прерывания. Сохранение содержимого других регистров процессора, используемых в подпрограмме обработки прерывания, производится непосредственно в подпрограмме (рис. 7.1). Организация системы прерываний с использованием векторов прерываний Рассмотрим подробнее процесс обработки внешних прерываний. Действия, выполняемые при этом процессором, как правило, те же, что и при обращении к обычной подпрограмме; различие в том, что при обращении к подпрограмме эти действия инициируются командой, а при обработке прерывания - управляющим сигналом от контроллера внешнего устройства, называемым Запрос (или Требование) прерывания.  Рис.7.1. Структура подпрограммы обработки прерывания и ее связь с основной программой Эта важная особенность обмена с прерыванием программы позволяет организовать обмен данными с внешними устройствами в произвольные моменты времени, не зависящие от программы, выполняемой в ЭВМ. Таким образом, появляется возможность обмена данными с внешними устройствами в реальном масштабе времени, определяемом внешней по отношению к ЭВМ средой (например, с датчиками, следящими за состоянием технологического процесса). Прерывание программы по требованию внешнего устройства не должно оказывать на прерванную программу никакого влияния, кроме увеличения времени ее выполнения за счет приостановки на время выполнения подпрограммы обработки прерывания. Формирование сигналов прерываний – запросов внешних устройств на обслуживание, происходит в их контроллерах – электронных схемах, обеспечивающих связь с внешним устройством. Еще есть драйвер – программа, обеспечивающая обслуживание прерывания. В серийных ЭВМ обычно используется одноуровневая система прерываний, то есть сигналы Запрос прерывания от всех внешних устройств поступают на один вход процессора. Поэтому возникает проблема идентификации внешнего устройства, запросившего обслуживание. Основным способом, решающим проблему идентификации в большинстве современных ЭВМ в настоящее время, является использование векторов прерываний. Внешнее устройство, запросившее обслуживание, само идентифицирует себя с помощью адреса своего вектора прерывания - ячейки основной памяти, в которой хранится адрес начала программы обработки прерывания данного типа. Векторы всех обработчиков прерываний собраны в единую таблицу векторов прерываний, располагающуюся в самых младших адресах оперативной памяти, имеющую объем 1 Кбайт и содержащую 4-х байтные элементы (векторы прерываний) для 256 обработчиков прерываний. Так как таблица всегда имеет нулевой начальный адрес и длину вектора в 4 байта, чтобы определить адрес вектора для прерывания типа i, достаточно просто умножить это значение на 4. Вектор прерывания выдается контроллером не одновременно с запросом на прерывание, а только по разрешению процессора (рис.7.2). Регистр прерываний составлен триггерами внешних устройств, устанавливаемыми в единичное состояние требованиями прерывания соответствующих контроллеров. Выходы триггеров поступают на входы приоритетного шифратора через элементы совпадения, вторые входы которых соединены с выходами регистра маски. Разряды этого регистра управляются ОС и устанавливаются в 0 при запрете прерывания соответствующего устройства и в 1, если прерывание разрешено. 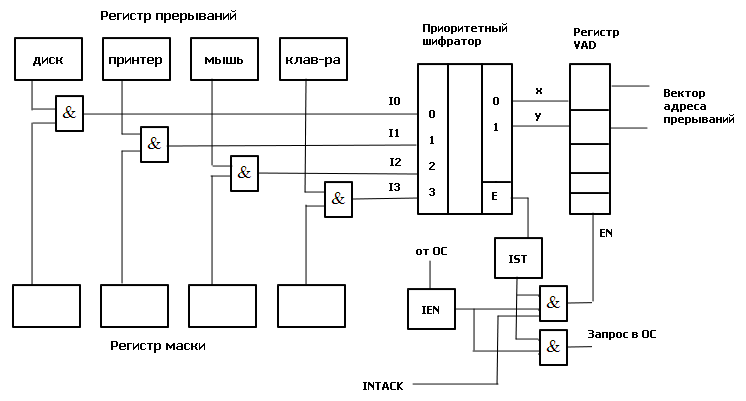 Рис.7.2. Схема обработки требования прерывания от внешнего устройства. IEN – Interrupt Enable – прерывание разрешено; IST – Interrupt Status – статус прерывания; INTACK – подтверждение прерывания; VAD – вектор адреса прерывания. При поступлении хотя бы одного требования прерывания на входы приоритетного шифратора он устанавливает в единичное состояние свой выход Е и устанавливает код приоритета прерывания на других своих выходах в соответствии с таблицей соответствия
В регистре прерываний устройства подключены в соответствии с их приоритетами. Чем выше приоритет, тем на меньший по значению вход приоритетного шифратора он поступает. Поэтому при одновременном поступлении требований прерывания от нескольких внешних устройств будет обрабатываться требование от устройства с высшим приоритетом. В начале оперативной памяти расположена таблица векторов прерываний. В каждой ячейке этой таблицы расположена команда безусловного перехода на начальный адрес соответствующей устройству программы обслуживания прерывания (ПОП). Рассмотрим пример вычислительного процесса при обработке прерываний от внешних устройств. Пусть программы обслуживания прерываний находятся по адресам 101-200 для диска (нулевой приоритет), 201-300 для принтера (1-й приоритет), 301-400 для мыши (2-й приоритет) и 401-500 для клавиатуры (3-й приоритет). Исполняемый код программы находится в области памяти 701-1500. Для сохранения адресов возврата предусмотрен стек. Пусть при выполнении команды основной программы по адресу 809 пришло прерывание от клавиатуры. Затем, при выполнении команды по адресу 441 ПОП клавиатуры, пришло прерывание от принтера. Надо изобразить ход вычислительного процесса в этих условиях. Цикл прерывания Управлением циклов в УУ ЦП занимаются триггеры F и R. Рассмотрим, как происходит управление при поступлении требований прерывания. В такте c2t3 цикла выполнения команды вырабатывается сигнал Если 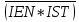 c2t3: c2t3: 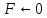 Если 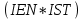 c2t3: c2t3: 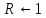 То есть, если имеется требование прерывания и разрешено прерывание от ОС, то выполняется установка в 1 триггера R, означающая переход к циклу прерывания. В этом цикле выполняются следующие действия: C3t0: M[SP] ← PC / запомнить адрес возврата в стеке. C3t1: INTACK ← 1, VAD ← CD / подтвердить обработку прерывания, занести в VAD вектор прерывания. C3t2: PC ← VAD / передать в счетчик команд адрес ПОП. C3t3: IEN ← 0, C ← C0 / Запретить прерывания. Перейти к выборке команды, адрес которой находится в PC. Запрет прерывания необходим для того, чтобы обеспечить правильное выполнение прерывания, которое начал обслуживать процессор. В начале и в конце каждой ПОП имеются команды, которые нельзя прерывать. В начале каждого драйвера имеются следующие стандартные команды: Сбросить маски всех устройств, которые имеют приоритет ниже приоритета того устройства, прерывание которого обслуживается; Сбросить регистры прерывания; Запомнить содержание тех регистров процессора основной (прерванной) программы, которые используются в драйвере; IEN ← 1 разрешить прерывания устройствам с более высоким приоритетом; Перейти к выполнению основной части драйвера УВВ. В конце драйвера: IEN ← 0 запретить прерывания; Восстановить содержание всех регистров процессора основной (прерванной) программы; Сбросить требование прерывания того устройства, которое обслуживалось; Восстановить регистр маски и шифратор приоритетный; Восстановить адрес возврата в прерванную программу из стека PC ← M[SP]; Разрешить прерывания IEN ← 1. Таким образом, мы рассмотрели мероприятия по обслуживанию прерываний. Классификация и тенденции развития архитектур современных компьютеров Классификации ЭВМ и ВС Самой ранней и наиболее известной считается классификация архитектур вычислительных систем, предложенная в 1966 году М. Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных М. Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD и MIMD. 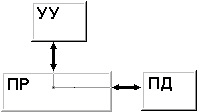 Рис. 8.1. Структура архитектуры класса SISD SISD (single instruction stream/single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть только один поток команд, все команды обрабатываются последовательно и каждая команда инициирует одну операцию с одним потоком данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. Поэтому в этот класс попадают ВМ со скалярными и с конвейерными функциональными устройствами. 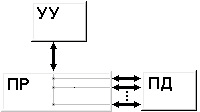 Рис. 8.2. Структура архитектуры класса SIMD. SIMD (single instruction stream/multiple data stream) – одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными – элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производиться либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1. 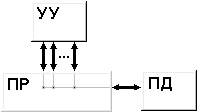 Рис. 8.3. Структура архитектуры класса MISD. MISD (multiple instruction stream/single data stream) – множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни М.Флинн, ни другие специалисты в области архитектуры компьютеров до некоторого времени не могли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей относят конвейерные машины к данному классу. К данному классу, по-видимому, можно отнести появившиеся многоядерные компьютеры. 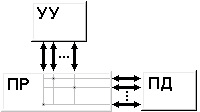 Рис. 8.4. Структура архитектуры класса MIМD. MIMD (multiple instruction stream/multiple data stream) – множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. Можно отметить два недостатка в классификации М. Флинна. Во-первых, некоторые заслуживающие внимания архитектуры, например, dataflow и векторно-конвейерные машины, четко не вписываются в данную классификацию. Во-вторых, класс MIMD чрезвычайно заполнен. Поэтому необходимо средство, более избирательно систематизирующее архитектуры, которые по М.Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования. 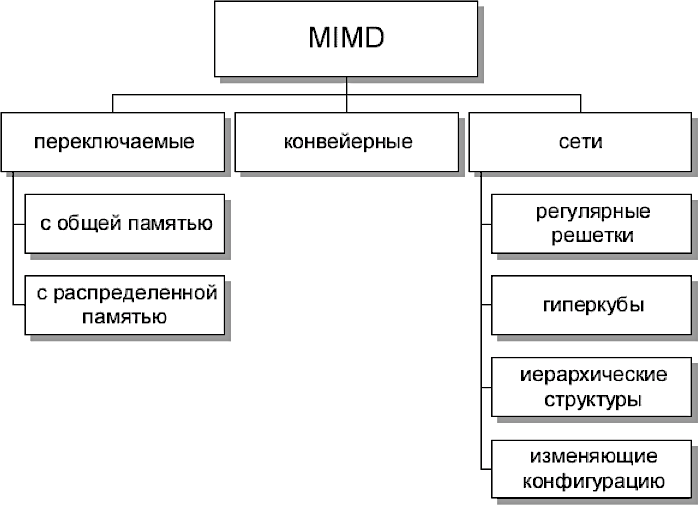 Роджер Хокни разработал свой подход к классификации для более детальной систематизации компьютеров, попадающих в класс MIMD по систематике М. Флинна. Пытаясь систематизировать архитектуры внутри этого класса, Р. Хокни получил иерархическую структуру, представленную на рис. 8.5. Основная идея классификации состоит в следующем. Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD-компьютерах, получивших название конвейерных. Роджер Хокни разработал свой подход к классификации для более детальной систематизации компьютеров, попадающих в класс MIMD по систематике М. Флинна. Пытаясь систематизировать архитектуры внутри этого класса, Р. Хокни получил иерархическую структуру, представленную на рис. 8.5. Основная идея классификации состоит в следующем. Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD-компьютерах, получивших название конвейерных.Рис. 8.5. Иерархическая структура архитектуры класса MIMD Архитектуры, использующие вторую возможность, в свою очередь, делятся на два класса. В первый класс попадают MIMD-компьютеры, в которых возможна прямая связь каждого процессора с каждым, реализуемая с помощью переключателя. Во втором классе находятся MIMD-компьютеры, в которых прямая связь каждого процессора возможна только с ближайшими соседями по сети, а взаимодействие удаленных процессоров поддерживается специальной системой маршрутизации. Среди MIMD-машин с переключателем Р. Хокни выделяет те, в которых вся память распределена среди процессов как их локальная память, например, PASM, PRINGLE, IBM SP2 без SMP-узлов. В этом случае общение самих процессоров реализуется с помощью сложного переключателя, составляющего значительную часть компьютера. Такие машины носят название MIMD-машин с распределенной памятью. Если память – разделяемый ресурс, доступный всем процессорам через переключатель, то MIMD-машины являются системами с общей памятью (BBN Butterfly, Cray C90). В соответствии с типом переключателей можно проводить классификацию и далее: простой переключатель, многокаскадный переключатель, общая шина и т. п. Многие современные вычислительные системы имеют как общую разделяемую память, так и распределенную локальную. Такие системы принято называть гибридными MIMD с переключателем. Особенности организации и функционирования архитектур с общей, распределенной и смешанной памятью Классифицируя современные компьютеры, которые практически все относятся к классу MIMD, будем основываться на анализе используемых в системах способах организации оперативной памяти. На рис. 8.6 приведена классификация систем MIMD, основанная на разных способах организации памяти. Данный поход позволяет различать два важных типа многопроцессорных систем – мультипроцессоры (multiprocessors или системы с общей разделяемой памятью) и мультикомпьютеры (multicomputers или системы с распределенной памятью). Для мультипроцессоров учитывается способ построения общей памяти. Возможный подход – использование единой (централизованной) общей памяти. Такой подход обеспечивает однородный доступ к памяти (uniform memory access или UMA) и служит основой для построения векторных суперкомпьютеров (parallel vector processor, PVP) и симметричных мультипроцессоров (symmetric multiprocessor или SMP). Среди примеров первой группы суперкомпьютер Cray T90, ко второй группе относятся IBM eServer p690 и др. 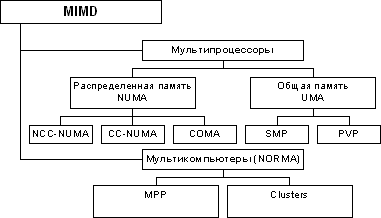 Рис. 8.6. Классификация систем MIMD Общий доступ к данным может быть обеспечен и при физически распределенной памяти (при этом, естественно, длительность доступа уже не будет одинаковой для всех элементов памяти). Такой подход именуется как неоднородный доступ к памяти (non-uniform memory access или NUMA). Среди систем с таким типом памяти выделяют: Системы, в которых для представления данных используется только локальная кэш память имеющихся процессоров (cache-only memory architecture или COMA); примерами таких систем являются, например, KSR-1 и DDM; Системы, в которых обеспечивается однозначность (когерентность) локальных кэш памяти разных процессоров (cache-coherent NUMA или CC-NUMA); среди систем данного типа SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000; Системы, в которых обеспечивается общий доступ к локальной памяти разных процессоров без поддержки на аппаратном уровне когерентности кэша (non-cache coherent NUMA или NCC-NUMA); к данному типу относится, например, система Cray T3E. |