АВМ. 1. Вычислительный процесс в эвм 4 Команды эвм 6
 Скачать 1.54 Mb. Скачать 1.54 Mb.
|

|
Мультикомпьютеры уже не обеспечивают общий доступ ко всей имеющейся в системах памяти (no-remote memory access или NORMA). Данный подход используется при построении двух важных типов многопроцессорных вычислительных систем – массивно-параллельных систем (massively parallel processor или MPP) и кластеров (clusters). Среди представителей первого типа систем – IBM RS/6000 SP2, Intel PARAGON/ASCI Red, транспьютерные системы Parsytec и др.; примерами кластеров являются, например, системы AC3 Velocity, NCSA/NT Supercluster и др. Следует отметить чрезвычайно быстрое развитие кластерного типа многопроцессорных вычислительных систем. Далее приводятся базовые характеристики основных классов современных компьютеров. Массивно-параллельные системы (MPP) 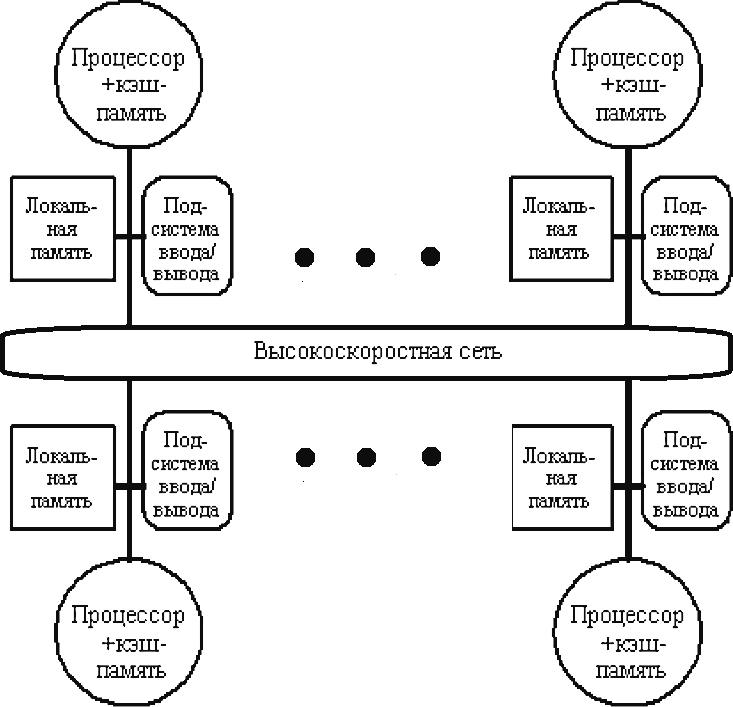 На рис.8.7 представлена типовая архитектура вычислительных систем с распределенной памятью. На рис.8.7 представлена типовая архитектура вычислительных систем с распределенной памятью.Рис. 8.7 Типовая архитектура машины с распределенной памятью Архитектура: Система состоит из однородных вычислительных узлов, включающих: один или несколько центральных процессоров (обычно RISC), локальную память (прямой доступ к памяти других узлов невозможен), коммуникационный процессор или сетевой адаптер, иногда – жесткие диски (как в SP) и/или другие устройства Вв/Выв. К системе могут быть добавлены специальные узлы ввода-вывода и управляющие узлы. Узлы связаны через некоторую коммуникационную среду (высокоскоростная сеть, коммутатор и т.п.) Примеры: IBM RS/6000 SP2, Intel PARAGON/ASCI Red, SGI/CRAY T3E, Hitachi SR8000, транспьютерные системы Parsytec и др. Масштабируемость: Общее число процессоров в реальных системах достигает нескольких тысяч (ASCI Red, Blue Mountain). Операционная система: Существуют два основных варианта реализации: Полноценная ОС работает только на управляющей машине (front- end), на каждом узле работает сильно урезанный вариант ОС, обеспечивающий только работу расположенной в нем ветви параллельного приложения. Пример: Cray T3E. На каждом узле работает полноценная UNIX-подобная ОС (вариант, близкий к кластерному подходу). Пример: IBM RS/6000 SP + операционная система AIX, которая устанавливается отдельно на каждом узле. Модель программирования: Программирование в рамках модели передачи сообщений (MPI, PVM, BSPlib) Распределенность памяти означает, что каждый процессор имеет непосредственный доступ только к своей локальной памяти, а доступ к данным, расположенным в памяти других процессоров, выполняется другими способами. Чтобы переслать информацию от процессора к процессору, необходим механизм передачи сообщений по сети, связывающей вычислительные узлы. Для абстрагирования от подробностей функционирования коммуникационной аппаратуры и программирования на высоком уровне, используются библиотеки передачи сообщений. Несмотря на существенные различия средств межпроцессорного взаимодействия в разных системах по скоростным параметрам и по способу аппаратной реализации, библиотеки обмена сообщениями выполняют приблизительно одни и те же функции. Выбор топологии машины часто определяет способ решения прикладной задачи. Надо заметить, что оптимизация алгоритмов для параллельных архитектур существенно отличается от той же работы для последовательных систем. Если переход с одного скалярного процессора на другой практически никогда не требует пересмотра алгоритма, то алгоритм, идеально приспособленный для одной параллельной архитектуры, на другой машине (с тем же числом процессоров того же типа) может работать неприемлемо медленно. Для оценки производительности распределенной системы, кроме топологии связей, необходимо знать скорость выполнения арифметических операций, время инициализации канала связи и время передачи единицы объема информации. Если топология системы не тривиальна, то в состав операционной системы или пакета передачи сообщений приходится включать процедуры маршрутизации сообщений, работающие на каждом узле и обеспечивающие пересылку транзитных сообщений. Они также вызывают задержку при передаче информации между узлами, не имеющими прямого канала связи. Таким образом, применение дешевых процессоров позволяет сделать относительно недорогой суперкомпьютер. Широкому распространению подобных архитектур препятствует в основном отсутствие эффективных параллельных программ, полностью использующих их возможности. Симметричные мультипроцессорные системы (SMP) 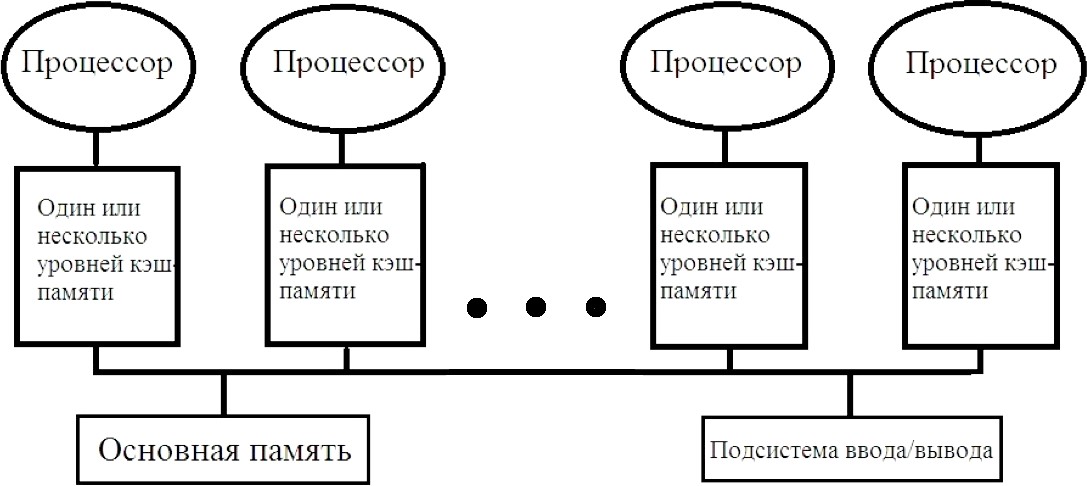 На рис. 8.8 приведена типовая архитектура мультипроцессорных вычислительных систем с общей памятью. На рис. 8.8 приведена типовая архитектура мультипроцессорных вычислительных систем с общей памятью.Рис. 8.8. Типовая архитектура мультипроцессорной системы с общей памятью Архитектура: Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины (базовые 2–4 процессорные SMP-сервера), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей. Примеры: HP 9000 V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.). Масштабируемость: Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число – не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA- архитектуры. Операционная система: Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка. Модель программирования: Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания. SMP - это один компьютер с несколькими равноправными процессорами, но с одной памятью, подсистемой ввода/вывода и одной ОС. Каждый процессор имеет доступ ко всей памяти, может выполнять любую операцию ввода/вывода, прерывать другие процессоры и т.д., но это представление справедливо только на уровне программного обеспечения. На самом же деле в SMP имеется несколько устройств памяти. Каждый процессор имеет, по крайней мере, одну собственную кэш-память, что необходимо для достижения хорошей производительности, поскольку основная память работает слишком медленно по сравнению со скоростью процессоров (и это соотношение все больше ухудшается), а кэш работает со скоростью процессора, но дорог, и поэтому устройства кэш-памяти обладают относительно небольшой емкостью. Из-за этого в кэш помещается лишь оперативная информация, остальное же хранится в основной памяти. тсюда возникает проблема когерентности кэшей – получение процессором значения, находящегося в кэш-память другого процессора. Это решается при помощи отправки широковещательного запроса всем устройствам кэш-памяти, основной памяти и даже подсистеме ввода/вывода, если она работает с основной памятью напрямую, с целью получения актуальной информации. Имеется еще одно следствие, связанное с параллелизмом. Неявно производимая аппаратурой SMP пересылка данных между кэшами является наиболее быстрым и самым дешевым средством коммуникации в любой параллельной архитектуре общего назначения. Поэтому при наличии большого числа коротких транзакций (свойственных, например, банковским приложениям), когда приходится часто синхронизовать доступ к общим данным, архитектура SMP является наилучшим выбором; любая другая архитектура работает хуже. Тем не менее, архитектуры с разделяемой общей памятью не считаются перспективными. Основная причина довольно проста. Рост производительности в параллельных системах обеспечивается наращиванием числа процессоров, что приводит к тому, что узким местом становится доступ к памяти. Увеличение локальной кэш-памяти не способно полностью решить проблему: задача поддержания согласованного состояния нескольких банков кэш-памяти столь же трудна. Как правило, на основе общей памяти не создают систем с числом процессоров более 32, при необходимости объединяя их в кластерные или NUMA- архитектуры. Системы с неоднородным доступом к памяти (NUMA) На рис. 8.9 изображена типовая архитектура мультипроцессорных вычислительных систем с неоднородным доступом к памяти. 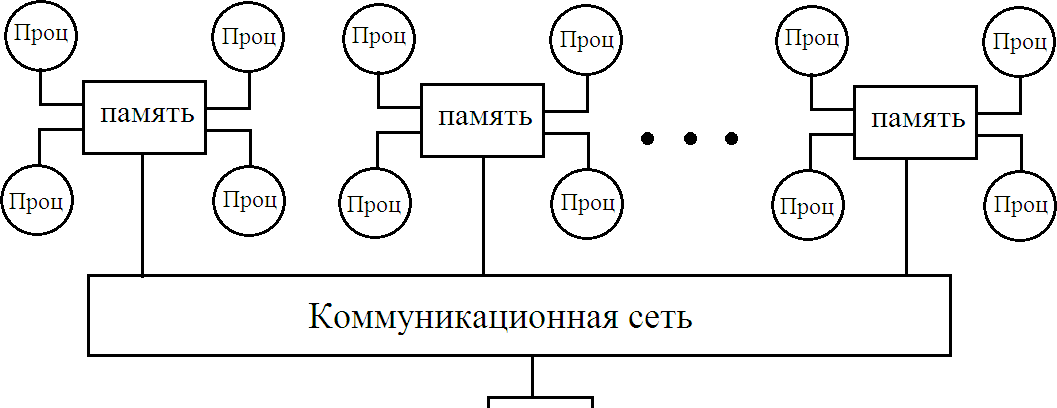 Рис. 8.9. Типовая архитектура мультипроцессорной системы с неоднородным доступом к памяти Архитектура: Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. Доступ к локальной памяти узла осуществляется в несколько раз быстрее, чем к удаленной. В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре CC-NUMA (cache-coherent NUMA). Примеры: HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600 и др. Масштабируемость: Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддержки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000). Операционная система: Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000). Модель программирования: Аналогично SMP. По сути своей NUMA представляет собой большую SMP-систему, разбитую на набор более мелких и простых SMP. Аппаратура позволяет работать со всеми отдельными устройствами основной памяти составных частей системы (называемых обычно узлами) как с единой гигантской памятью. Этот подход порождает ряд следствий. Во-первых, в системе имеется одно адресное пространство, распространяемое на все узлы. Реальный (не виртуальный) адрес 0 для каждого процессора в любом узле соответствует адресу 0 в частной памяти узла 0; реальный адрес 1 для всей машины – это адрес 1 в узле 0 и т.д., пока не будет использована вся память узла 0. Затем происходит переход к памяти узла 1, затем узла 2 и т.д. Для реализации этого единого адресного пространства каждый узел NUMA включает специальную аппаратуру (Dir), которая решает проблему когерентности кэшей, обеспечивая получение актуальной информации от других узлов. Понятно, что этот процесс длится несколько дольше, чем если бы требуемое значение находилось в частной памяти того же узла. Отсюда и происходит словосочетание "неоднородный доступ к памяти". В отличие от SMP, время выборки значения зависит от адреса и от того, от какого процессора исходит запрос (если, конечно, требуемое значение не содержится в кэше). Поэтому ключевым вопросом является степень "неоднородности" NUMA. Например, если для взятия значения из другого узла требуется только на 10% большее время, то это никого не задевает. В этом случае все будут относиться к системе как к SMP, и разработанные для SMP программы будут выполняться достаточно хорошо. Однако в текущем поколении NUMA-систем для соединения узлов используется сеть. Это позволяет включать в систему большее число узлов, до 64 узлов с общим числом процессоров 128 в некоторых системах. В результате, современные NUMA-системы не выдерживают правила 10% – лучшие образцы замедление 200–300% и даже более. При такой разнице в скорости доступа к памяти для обеспечения должной эффективности следует позаботиться о правильном расположении требуемых данных. Чтобы этого добиться, можно соответствующим образом модифицировать операционную систему (и это сделали поставщики систем в архитектуре NUMA). Например, такая операционная система при запросе из программы блока памяти выделяет память в узле, в котором выполняется эта программа, так что когда процессор ищет соответствующие данные, то находит их в своем собственном узле. Аналогичным образом должны быть изменены подсистемы (включая СУБД), осуществляющие собственное планирование и распределение памяти (что и сделали Oracle и Informix). Как утверждает компания Silicon Graphics, такие изменения позволяют эффективно выполнять в системах с архитектурой NUMA приложения, разработанные для SMP, без потребности изменения кода. Параллельные векторные системы (PVP) Архитектура: Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1–16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP). Примеры: NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY SV1, серия Fujitsu VPP и др. Модель программирования: Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением). Кластерные системы Архитектура: Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого варианта массивно-параллельного компьютера. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet и др.) на базе шинной архитектуры или коммутатора. При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах. Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. В случае, когда это не нужно, узлы могут быть существенно облегчены и/или установлены в стойку. Примеры: NT-кластер в NCSA, Beowulf-кластеры, кластеры МГУ и СПбГУ, кластер МЭИ (см.рис. 8.10 и 8.11) и др. Операционная система: Используются стандартные для рабочих станций ОС, чаще всего, свободно распространяемые – Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и распределения нагрузки. Модель программирования: Программирование, как правило, в рамках модели передачи сообщений (чаще всего - MPI). Организация схем коммутации Важнейшим аспектом создания высокопроизводительных архитектур является построение средств коммутации. Структура линий коммутации между процессорами вычислительной системы (топология сети передачи данных) определяется, как правило, с учетом возможностей технической реализации. Немаловажную роль при выборе структуры сети играет и анализ интенсивности информационных потоков при параллельном решении наиболее распространенных вычислительных задач. Рассмотрим основные схемы коммутации в МВС разной системы организации памяти. Организация схем коммутации в МВС с общей памятью На рис. 8.10 представлена типовая архитектура МВС с общей памятью. Замечание. В реальных вычислительных системах (ВС) с общей памятью количество процессоров n не превосходит 32. Число модулей памяти m, осуществляющих хранение данных, не превосходит n, то есть m ≤ n ≤ 32. 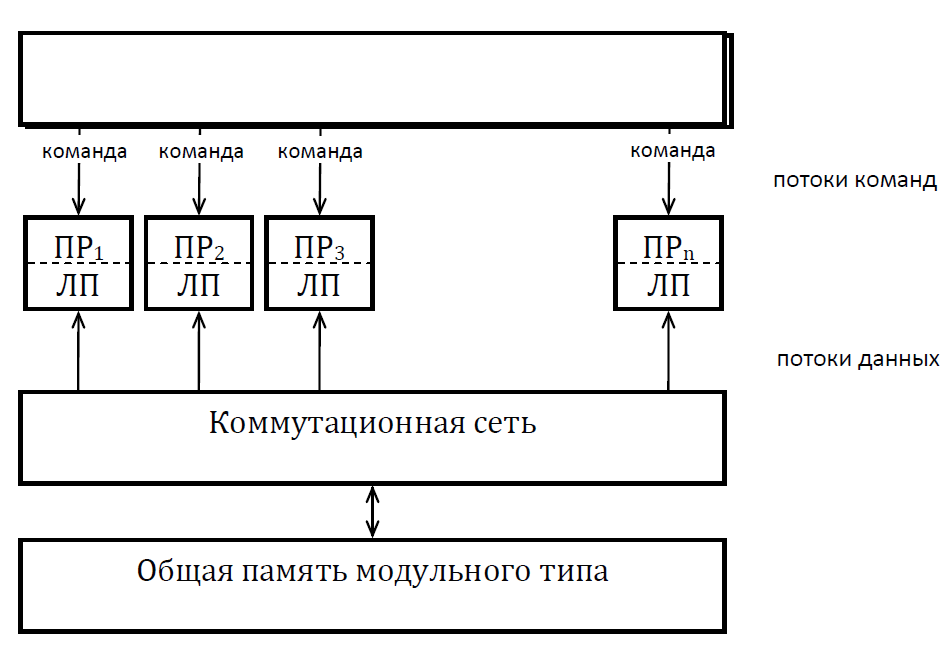 Рис. 8.10. Типовая архитектура МВС с общей памятью Возможно несколько вариантов построения ВС с общей памятью: ВС с единственным модулем памяти (m ≥ 1), или многовходовой памятью; ВС с несколькими модулями памяти (1 ≤ m ≤ n ), или несколькими многовходовыми памятями; ВС с количеством модулей памяти равным количеству процессоров (m≤ n) и коммутацией в виде коммутационной сети. На рис. 8.11, 8.12 и 8.13 представлены варианты реализации. 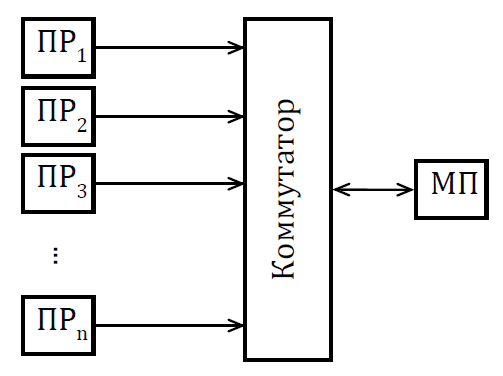  ... Рис. 8.11. Единый модуль памяти m = 1 ... ... 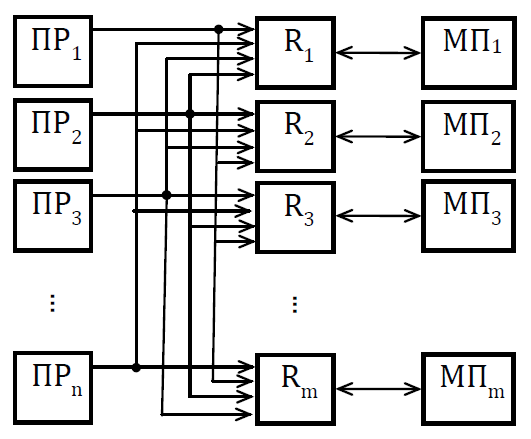 Рис. 8.12. Несколько модулей памяти 1 < m < n 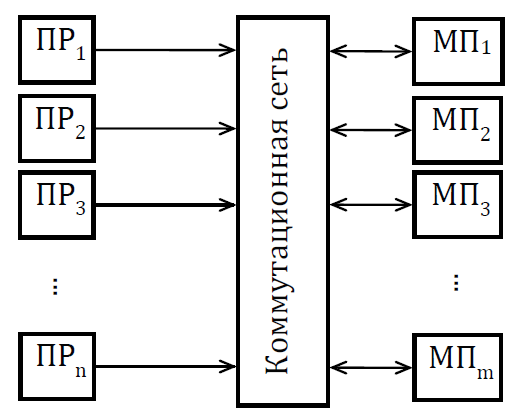 Рис. 8.13. Число модулей памяти равно числу процессоров m ≤ n Организация средств коммутации в архитектуре “Butterfly” Для архитектуры “Butterfly” - n = m = 256 . Коммутационный узел (КУ), как изображено на рис. 8.14, имеет 4 входа и 4 выхода, причем каждый вход соединён с каждым выходом. 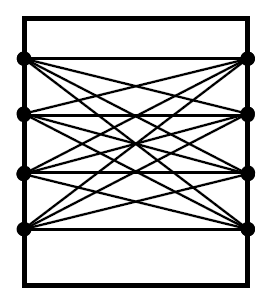 Рис. 8.14. Коммутационный узел «4 х 4» Коммутационный блок (КБ) представляет собой аналогичную КУ структуру, «атомарными» в которой являются КУ (рис. 8.15). 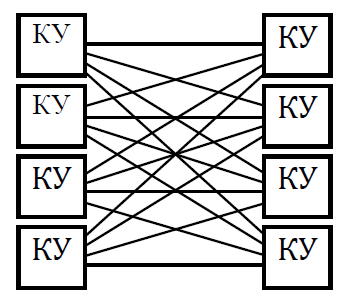 Рис. 8.15. Коммутационный блок «16 х 16» Коммутационная сеть по типу Butterfly изображена на рис. 8.16. 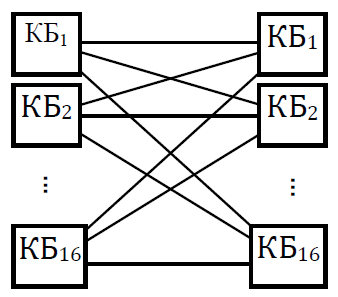 ... ... Рис. 8.16. Коммутационная сеть по типу Butterfly «256 х 256» В МВС с общей памятью в качестве средства передачи информации часто используют шины. Каждый модуль памяти имеет свою шину, к которой подключаются все процессорные узлы. Схематически это показано на рис. 8.17. 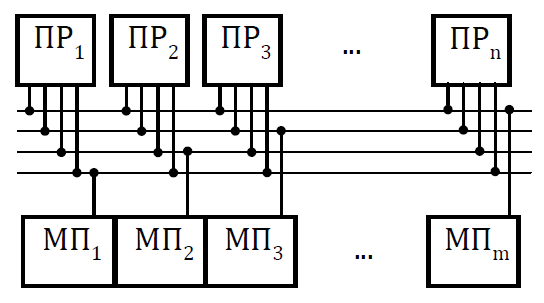 Рис. 8.17. МВС с общей памятью Организация схем коммутации в МВС с распределенной памятью На рис. 8.18 представлена типовая архитектура МВС с распределенной памятью. 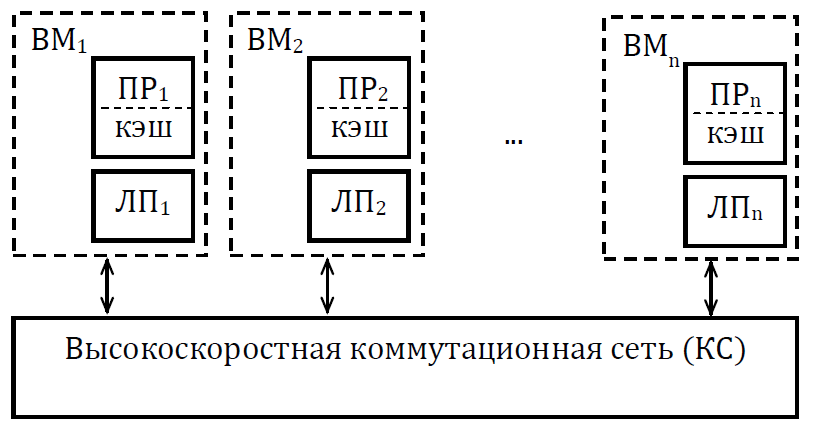 Рис. 8.18. Типовая архитектура схем коммутации в МВС с распределенной памятью При обсуждении этого типа архитектур будем использовать следующие обозначения: число шин – m, число процессоров – n. Также будем учитывать ограничение m n/2. Средства коммутации для этого типа архитектуры представляют важнейший структурный элемент ВС. Наиболее распространенные решения при построении КС для МВС с распределенной памятью можно разбить на три группы. ВС со связями через общую шину (см. рис. 8.19). Такая схема является, с одной стороны, дешевой и просто реализуемой, а также соответствует структуре передачи данных при решении многих вычислительных задач. Легко наращивается число подключаемых вычислительных модулей (ВМ). С другой стороны, для обеспечения эффективной работы шины требуется тщательное планирование использования шины (арбитр шины), работающей в режиме разделения времени, от которой зависит производительность всей системы. 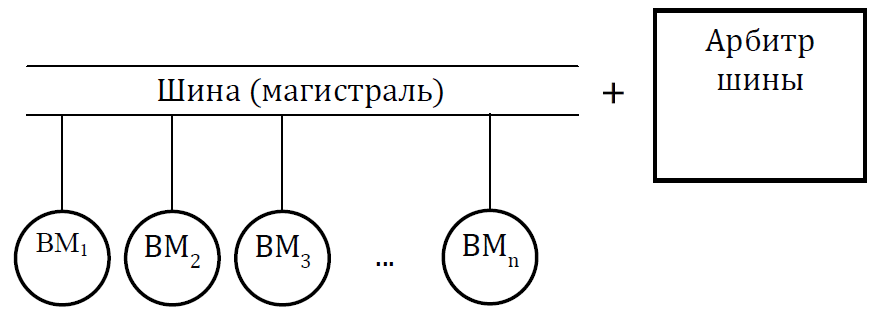 Рис. 8.19. Архитектура схем коммутации в МВС с распределенной памятью со связями через общую шину Более дорогой вариант – архитектура со связями через несколько шин – представлена на рис. 8.20. При таком способе связи поддерживается режим прямого доступа к памяти, причем передача производится обычно блоками из фиксированного набора слов. 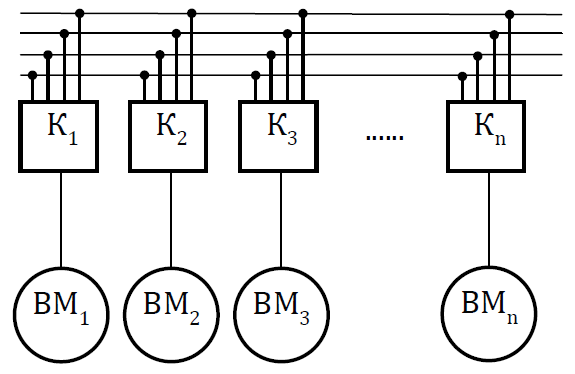 Рис. 8.20. Архитектура схем коммутации в МВС с распределенной памятью со связями через несколько шин  Достоинством архитектур МВС, использующих при коммутации несколько шин, является бо'льшая производительность и надежность, чем у аналогов с одной шиной. Однако для организации эффективных вычислений необходимы n коммутаторов шин, а это высокие аппаратные затраты. Достоинством архитектур МВС, использующих при коммутации несколько шин, является бо'льшая производительность и надежность, чем у аналогов с одной шиной. Однако для организации эффективных вычислений необходимы n коммутаторов шин, а это высокие аппаратные затраты.На рис. 8.21 представлена архитектура со связями через многоступенчатый переключатель. 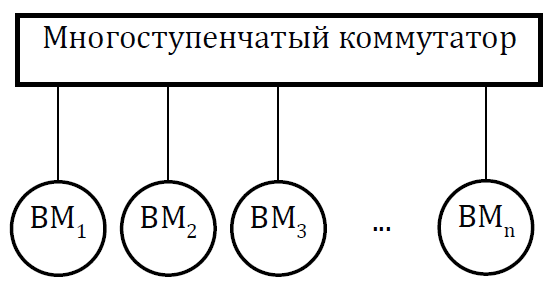 Рис. 8.21. МВС с распределенной памятью со связями через многоступенчатый переключатель Существует большое разнообразие в организации коммутации такого вида. При соединении первого и последнего процессоров линейки через коммутатор получается топология, называемая кольцом (рис. 8.22). 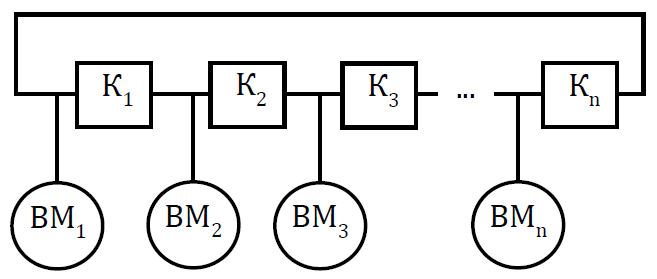 Рис. 8.22. Многоступенчатый коммутатор кольцевого типа Система, в которой каждый ВМ связан с каждым другим ВМ прямой линией связи, построена на основе КС с полным набором связей (рис. 8.23). Такая топология обеспечивает высокую надежность и минимальные затраты при передаче данных, однако является сложно реализуемой при большом количестве процессов. Каждый узел – это ВМ со своим многовходовым коммутатором. 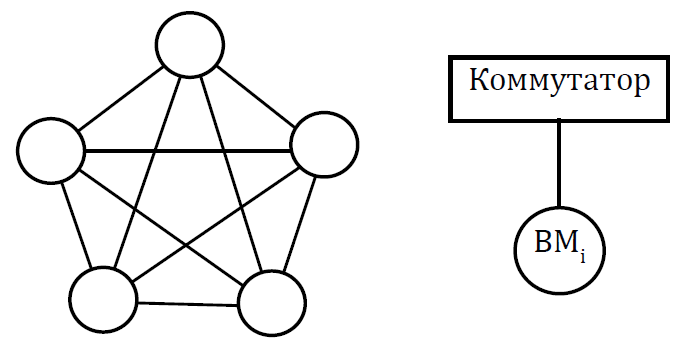 Рис. 8.23. Схема КС с полным набором связей Система, в которой все ВМ с помощью своих коммутаторов имеют линии связи с некоторым центральным коммутатором или центральным коммутационным узлом (ЦКУ) или управляющим процессором, называется ВС с топологией типа «звезда». 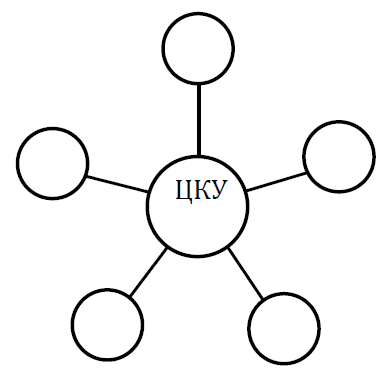 Рис. 8.24. Коммутатор по типу «звезды» ВС, в которой топология линий связи образует прямоугольную сетку (обычно двух- или трехмерную), называется системой с топологией решетки. Подобная топология может быть достаточно просто реализована и, кроме того, эффективно использована при параллельном выполнении многих численных алгоритмов (например, при реализации методов анализа математических моделей, описываемых дифференциальными уравнениями в частных производных). На рис. 8.25 представлена топология связей по типу «двумерной решетки». Каждый ВМ связан с 4-мя соседями и через них с любыми другими ВМ. 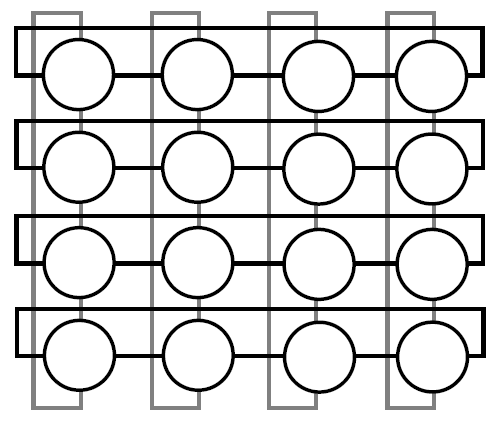 Рис. 8.25. Структура ВС по типу «решетки» Топология ВС по типу «гиперкуб» – частный случай решетки, когда по каждой размерности сетки имеется только два процессора. Примеры гиперкуб- коммутаторов представлены на рис. 8.26. Гиперкуб содержит 2N процессоров при размерности гиперкуба N. 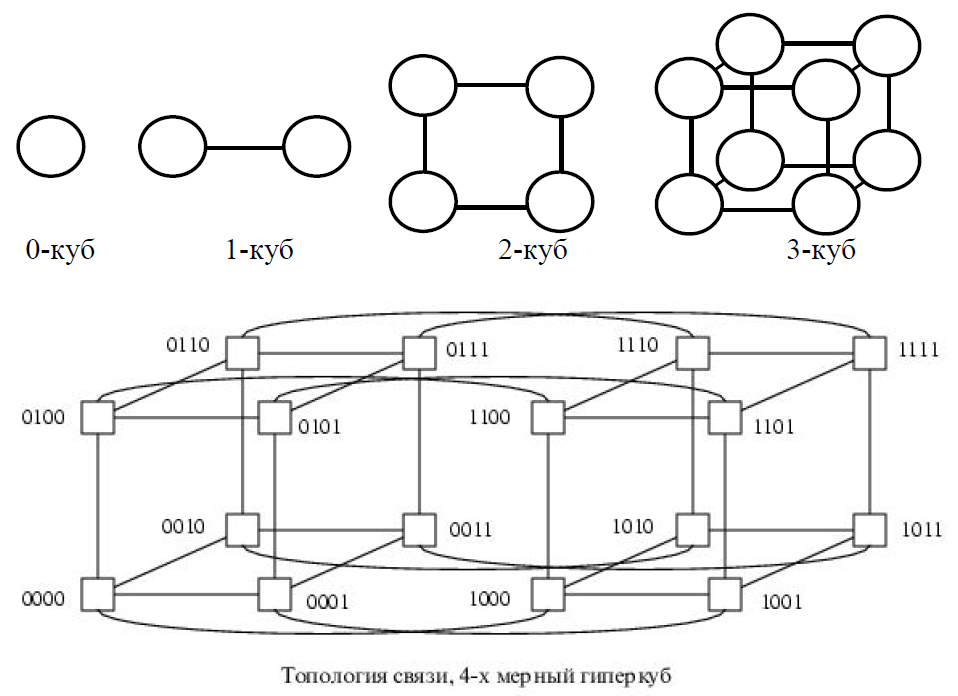 Рис. 8.26. Коммутатор по типу «гиперкуба» Такой вариант организации сети передачи данных достаточно широко распространен на практике, достаточно прост в построении, и характеризуется следующими свойствами: Два процессора имеют соединение, если двоичные представления их номеров имеют только одну различающуюся позицию. В N-мерном гиперкубе каждый процессор связан ровно с N соседями. Кратчайший путь между двумя любыми процессорами имеет длину, совпадающую с количеством различающихся битовых значений в номерах процессов. Отсюда следует, что максимальная длина пути в N-мерном гиперкубе равна N. N-мерный гиперкуб может быть разделен на два (N–1)-мерных гиперкуба (всего возможно N таких разбиений). Очевидные преимущества такой топологии: ВМ, располагаясь в вершине N куба, не отстоит более чем на N-ребер ни от какого другого ВМ, что значительно облегчает создание эффективных коммуникаций в системе (например, для N=12 допустимое число ВМ 212 =4096!); Т.к. структура соединений в N-кубе хорошо согласуется с двоичной логикой, то достаточно легко реализуется алгоритм маршрутизации для передачи сообщений между узлами; Между любой парой ВМ существует несколько альтернативных путей коммуникаций, что позволяет в целом снизить задержки при передачах. Архитектура систем со смешанной организацией памяти Для решения практических задач часто используют вычислительные системы со смешанной организацией памяти. На рис. 8.27 схематично представлен пример такой архитектуры. 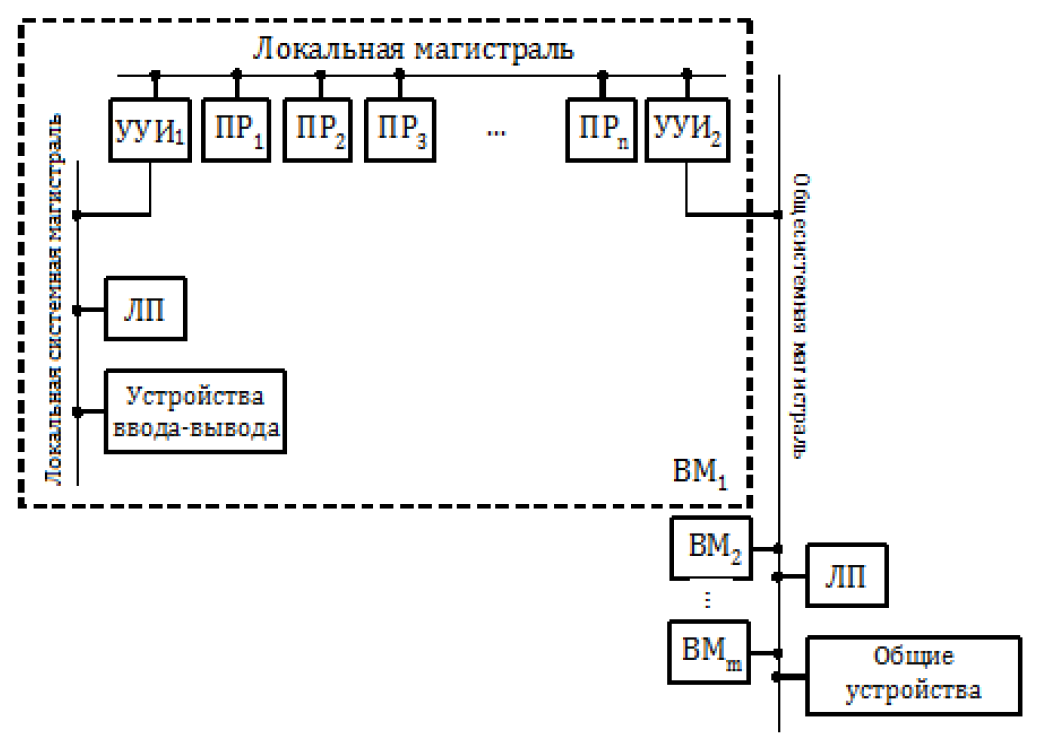 Рис. 8.27. Типовая архитектура систем со смешанной организацией памяти Здесь: УУИ1, УУИ2 – устройства управления интерфейсами; ПР – процессор; ЛП – локальная память; ВМ – вычислительный модуль. Литература 1. Современные операционные системы : Пер. с англ. / Э. Таненбаум. — СПб.: Питер, 2006. — 1038 с. 2. Сетевые операционные системы : Учебник для вузов / В. Г. Олифер, Н. А. Олифер. — СПб.: Питер, 2009. — 668 с. 3. Основы современных операционных систем : Учеб. пособие для вузов / В. О. Сафонов. — М.: ИНТУИТ, 2011. — 583 с. 4. Архитектура ЭВМ и систем : учебное пособие для бакалавров / О. П. Новожилов. — М.: Юрайт, 2015. — 528 с. 5. Архитектура ЭВМ и операционные среды : Учебник для вузов / В. Г. Баула, А. Н. Томилин, Д. Ю. Волканов. — М.: Академия, 2012. — 336 с. 6. Организация ЭВМ и систем : Учебник для вузов / С.А.Орлов, Б.Я. Цилькер — СПб.: Питер, 2015. — 668 с. Сведения об авторах Мусихин Александр Григорьевич, кандидат технических наук, доцент кафедры вычислительной техники института информационных технологий Российского технологического университета – МИРЭА. Смирнов Николай Алексеевич, кандидат технических наук, доцент, профессор кафедры вычислительной техники института информационных технологий Российского технологического университета – МИРЭА. |