Шпоры ОС. Шпоры OS_34-44. 34. Формальные модели для изучения проблемы взаимных блокировок. Обнаружение блокировок при наличии нескольких экземпляров ресурсов каждого типа
 Скачать 87.1 Kb. Скачать 87.1 Kb.
|

1 2 34. Формальные модели для изучения проблемы взаимных блокировок. Обнаружение блокировок при наличии нескольких экземпляров ресурсов каждого типа. Взаимная блокировка - ситуация, когда каждый из группы процессов ожидает событие, которое может вызвать только другой процесс из этой группы. Существует четыре стратегии избегания взаимоблокировок: 1. Пренебрежением проблемой в целом. 2. Обнаружение и устранение (взаимоблокировка происходит, но оперативно ликвидируется). 3. Динамическое избежание тупиков. 4. Предотвращение условий, необходимых для взаимоблокировок. Если вероятность взаимоблокировки очень мала, то ею легче пренебречь, т.к. код исключения может очень усложнить ОС и привести к большим ошибкам. Также многие взаимоблокировки тяжело обнаружить. Этот алгоритм используется как в UNIX, так и в Windows. Система не пытается предотвратить взаимоблокировку, а пытается обнаружить ее и устранить. Обнаружение взаимоблокировки при наличии нескольких ресурсов каждого типа Рассмотрим систему. m - число классов ресурсов (например: принтеры это один класс) n - количество процессов P(n) - процессы E- вектор существующих ресурсов E(i)- количество ресурсов класса i A- вектор доступных (свободных) ресурсов A(i) - количество доступных ресурсов класса i С- матрица текущего распределения (какому процессу, какие ресурсы принадлежат) R- матрица запросов (какой процесс, какой ресурс запросил) 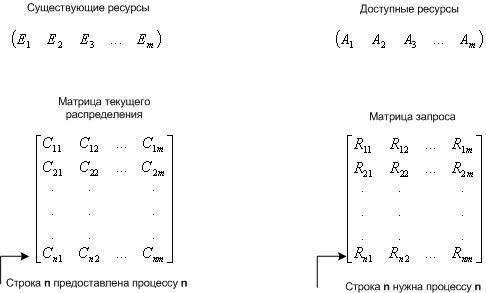 C(ij) - количество экземпляров ресурса j, которое занимает процесс P(i). R(ij) - количество экземпляров ресурса j, которое хочет получить процесс P(i). 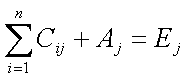 Общее количество ресурсов равно сумме занятых и свободных ресурсов Рассмотрим алгоритм поиска тупиков. 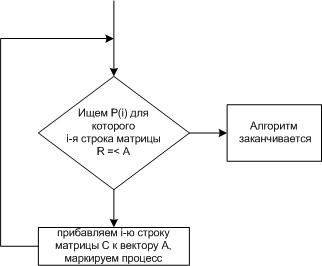 Алгоритм поиска тупиков при наличии нескольких ресурсов каждого типа Если остаются не маркированные процессы, значит, есть тупик. Р 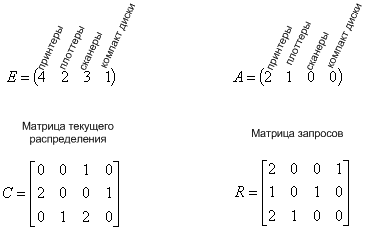 ассмотрим работу алгоритма на реальном примере. ассмотрим работу алгоритма на реальном примере.Используем алгоритм: 1. Третий процесс может получить желаемые ресурсы, т.к. R (2 1 0 0) = A (2 1 0 0) 2. Третий процесс освобождает ресурсы. Прибавляем их к A. А = (2 1 0 0) + (0 1 2 0) =(2 2 2 0). Маркируем процесс. 3. Может выполняться процесс 2. По окончании А=(4 2 2 1). 4. Теперь может работать первый процесс. Тупиков не обнаружено. Если рассмотреть пример, когда второму процессу требуются ресурсы (1 0 3 0), то два процесса окажутся в тупике. Когда можно искать тупики: · Когда запрашивается очередной ресурс (очень загружает систему) · Через какой-то промежуток времени (в интерактивных системах пользователь это ощутит) · Когда загрузка процессора слишком велика 35. Безопасное распределение ресурсов на примере алгоритма банкира. Алгоритм банкира (Э. Дейкстра) – алгоритм распределения ресурсов операционной системой, обеспечивающий избежание тупиков. Его условия и принципы: возможны множественные экземпляры ресурсов; каждый процесс должен априорно обозначить свои максимальные потребности в ресурсах; при запросе ресурса возможно ожидание процесса; после получения ресурсов процесс должен вернуть их за ограниченный период времени. Для работы алгоритма используются вектор доступности ресурсов каждого вида, матрица максимальных потребностей процессов, матрица фактического выделения системой ресурсов процессам, матрица оставшихся потребностей процессов в ресурсах. Структуры данных для алгоритма банкира Пусть в системе имеется n процессов и m типов ресурсов. Вектор Available длины m содержит информацию о доступныхресурсах. Если Avaliable[j] = k, то в системе в данный момент доступно k единиц ресурса j. Матрица Max (n * m) отображает максимальныепотребности процессов в ресурсах. Если Max [i, j] = k, то процесс i может запросить, самое большее, k единиц ресурса j. Матрица Allocation ( n * m ) отображает фактическоевыделение системой ресурсов. Если Allocation [i, j] = k, то процессу i в данный момент выделено системой k единиц ресурса j. Матрица Need ( n * m ) отображает оставшиеся потребности процессов в ресурсах. Если Need [i, j] = k, то процессу i могут потребоваться еще k единиц ресурса j для завершения работы. Имеет место следующее соотношение между элементами матриц: Need [i, j] = Max [i, j] – Allocation [i, j]. 36. Управление памятью. Сегментная организация памяти компьютера. Совместное использование памяти. Защита памяти и защищенный режим работы процессора. 1)При сегментной организации виртуальный адрес является двумерным как для программиста, так и для операционной системы, и состоит из двух полей – номера сегмента и смещения внутри сегмента. Подчеркнем, что в отличие от страничной организации, где линейный адрес преобразован в двумерный операционной системой для удобства отображения, здесь двумерность адреса является следствием представления пользователя о процессе не в виде линейного массива байтов, а как набор сегментов переменного размера (данные, код, стек...). Логическое адресное пространство – набор сегментов. Каждый сегмент имеет имя, размер и другие параметры (уровень привилегий, разрешенные виды обращений, флаги присутствия). В сегментной схеме пользователь специфицирует каждый адрес двумя величинами: именем сегмента и смещением. Каждый сегмент – линейная последовательность адресов, начинающаяся с 0. Максимальный размер сегмента определяется разрядностью процессора (при 32-разрядной адресации это 232 байт или 4 Гбайт). Размер сегмента может меняться динамически (например, сегмент стека). В элементе таблицы сегментов помимо физического адреса начала сегмента обычно содержится и длина сегмента. Если размер смещения в виртуальном адресе выходит за пределы размера сегмента, возникает исключительная ситуация. Логический адрес – упорядоченная пара v=(s,d), номер сегмента и смещение внутри сегмента. В системах, где сегменты поддерживаются аппаратно, эти параметры обычно хранятся в таблице дескрипторов сегментов, а программа обращается к этим дескрипторам по номерам-селекторам. При этом в контекст каждого процесса входит набор сегментных регистров, содержащих селекторы текущих сегментов кода, стека, данных и т. д. и определяющих, какие сегменты будут использоваться при разных видах обращений к памяти. Это позволяет процессору уже на аппаратном уровне определять допустимость обращений к памяти, упрощая реализацию защиты информации от повреждения и несанкционированного доступа. Рис. 8.8. Преобразование логического адреса при сегментной организации памяти Аппаратная поддержка сегментов распространена мало (главным образом на процессорах Intel). В большинстве ОС сегментация реализуется на уровне, не зависящем от аппаратуры. Хранить в памяти сегменты большого размера целиком так же неудобно, как и хранить процесс непрерывным блоком. Напрашивается идея разбиения сегментов на страницы. При сегментно-страничной организации памяти происходит двухуровневая трансляция виртуального адреса в физический. 2) В основном совместное использование памяти обеспечивается следующими средствами: файлами, отображаемыми в памяти и обеспечивающими следующие механизмы: открытие дескриптора файла; свободные чтение и запись, как если бы это был блок памяти. 2.специальными API, управляющие страницами, обозначенными как разделяемые, доступ к которым процессы получают через механизмы имен. механизмами экспорта/импорта на этапах компиляции и загрузки. На этапе компиляции и компоновки программа определяет статическую область памяти как допустимую для экспорта. Другие программы во время компиляции и компоновки могут импортировать данные из этой области. 3) Защита памяти — это способ управления правами доступа к отдельным регионам памяти. Используется большинством многозадачных операционных систем. Основной целью защиты памяти является запрет доступа процессу к той памяти, которая не выделена для этого процесса. Такие запреты повышают надежность работы как программ так и операционных систем, так как ошибка в одной программе не может повлиять непосредственно на память других приложений. Методы защиты базируются на некоторых классических подходах, которые получили свое развитие в архитектуре современных ЭВМ. К таким методам можно отнести защиту отдельных ячеек, метод граничных регистров, метод ключей защиты. Защита отдельных ячеек памяти - выделение в каждой ячейке памяти специального "разряда защиты". Установка этого разряда в "1" запрещает производить запись в данную ячейку, что обеспечивает сохранение рабочих программ. Недостаток такого подхода - большая избыточность в кодировании информации из-за излишне мелкого уровня защищаемого объекта (ячейка). Метод граничных регистров заключается во введении двух граничных регистров, указывающих верхнюю и нижнюю границы области памяти, куда программа имеет право доступа. При каждом обращении к памяти проверяется, находится ли используемый адрес в установленных границах. При выходе за границы обращение к памяти не производится, а формируется запрос прерывания, передающий управление операционной системе. Содержание граничных регистров устанавливается операционной системой при загрузке программы в память. Основной недостаток-метод поддерживает работу лишь с непрерывными областями памяти. Метод ключей защиты - память в логическом отношении делится на одинаковые блоки, например, страницы. Каждому блоку памяти ставится в соответствие код - ключ защиты памяти, а каждой программе, принимающей участие в мультипрограммной обработке, присваивается код ключа программы. Доступ программы к данному блоку памяти для чтения и записи разрешен, если ключи совпадают или один из них имеет код 0 .Коды ключей защиты блоков памяти и ключей программ устанавливаются операционной системой. В ключе защиты памяти предусматривается дополнительный разряд режима защиты. Защита действует только при попытке записи в блок, если в этом разряде стоит 0, и при любом обращении к блоку, если стоит 1. Коды ключей защиты памяти хранятся в специальной памяти ключей защиты, более быстродействующей, чем оперативная память. При обращении к памяти группа старших разрядов адреса ОЗУ, соответствующая номеру блока, к которому производится обращение, используется как адрес для выборки из памяти ключей защиты кода ключа защиты, присвоенного операционной системой данному блоку. Схема анализа сравнивает ключ защиты блока памяти и ключ программы, находящийся в регистре слова состояния программы (ССП), и вырабатывает сигнал "Обращение разрешено" или сигнал "Прерывание по защите памяти". При этом учитываются значения режима обращения к ОЗУ (запись или считывание), указываемого триггером режима обращения ТгРО, и режима защиты, установленного в разряде режима обращения (РРО) ключа защиты памяти. Защищенный режим (режим защищенного виртуального адреса) - режим работы процессора. Разработанный фирмой Digital Equipment (DEC) для 32-разрядных компьютеров VAX-11, а также фирмой Intel для своих процессоров, начиная с 32-разрядных процессоров 80386. Суть защищенного режима заключается в следующем. Программист и разрабатываемые им программы используют логическое адресное пространство (виртуальное адресное пространство), размер которого может составлять 1024 МБ. Логическая адрес превращается в физический адрес автоматически с помощью схемы управления памятью (MMU). Благодаря защищенному режиму в памяти можно хранить только ту часть программы, которая необходима в определенный момент, остальные могут храниться во внешней памяти (например, на жестком диске). В случае обращения к той части программы, которой нет в памяти в данный момент, операционная система может приостановить программу, загрузить нужную секцию кода из внешней памяти и возобновить выполнение программы. Соответственно, становятся доступными программы, размер которых превышает объем доступной памяти. Другими словами, пользователю кажется, что он работает с большим объемом памяти, чем в действительности. Для использования защищенного режима необходима многозадачная операционная система, например Microsoft Windows 3.0, IBM OS / 2 или UNIX. Физический адрес формируется следующим образом. В сегментных регистрах хранится селектор, содержащий индекс дескриптора в таблице дескрипторов (13 бит), 1 бит, определяющий, к какой таблице дескрипторов будет осуществляться обращение (к локальной или к глобальной) и 2 бита запрашиваемого уровня привилегий. Далее происходит обращение к соответствующей таблице дескрипторов и соответствующему дескриптору, который содержал начальную, 24-битную адрес сегмента, размер сегмента и права доступа. После чего рассчитывается необходимый физический адрес, посредством составления адреса сегмента и смещения, который хранится в 16-разрядном указательном регистре. Дескриптор сегмента — служебная структура в памяти, которая определяет сегмент. Длина дескриптора равна 8 байт. 37. Управление памятью. Страничная организация памяти компьютера. В самом простом и наиболее распространенном случае страничной организации памяти как логическое адресное пространство, так и физическое представляются состоящими из наборов блоков или страниц одинакового размера. При этом образуются логические страницы, а соответствующие единицы в физической памяти называют физическими страницами или страничными кадрами. Страницы (и страничные кадры) имеют фиксированную длину, обычно являющуюся степенью числа 2, и не могут перекрываться. Каждый кадр содержит одну страницу данных. При такой организации внешняя фрагментация отсутствует, а потери из-за внутренней фрагментации, поскольку процесс занимает целое число страниц, ограничены частью последней страницы процесса. Логический адрес в страничной системе – упорядоченная пара (p, d), где p – номер страницы в виртуальной памяти, а d – смещение в рамках страницы p, на которой размещается адресуемый элемент. Разбиение адресного пространства на страницы осуществляется вычислительной системой незаметно для программиста. Поэтому адрес является двумерным лишь с точки зрения операционной системы, а с точки зрения программиста адресное пространство процесса остается линейным. Описываемая схема позволяет загрузить процесс, даже если нет непрерывной области кадров, достаточной для размещения процесса целиком. Но одного базового регистра для осуществления трансляции адреса в данной схеме недостаточно. Система отображения логических адресов в физические сводится к системе отображения логических страниц в физические и представляет собой таблицу страниц, которая хранится в оперативной памяти. Иногда говорят, что таблица страниц – это кусочно-линейная функция отображения, заданная в табличном виде. И 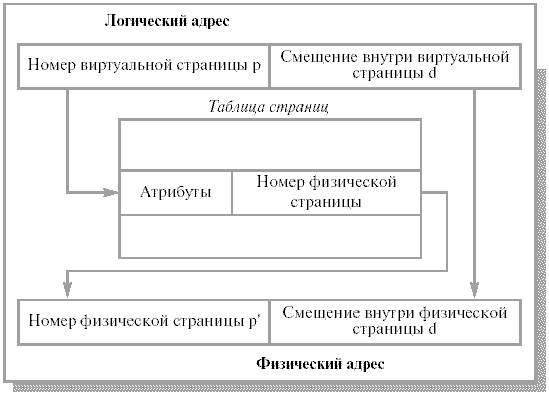 нтерпретация логического адреса показана на рис. 8.7. Если выполняемый процесс обращается к логическому адресу v = (p,d), механизм отображения ищет номер страницы p в таблице страниц и определяет, что эта страница находится в страничном кадре p', формируя реальный адрес из p' и d. нтерпретация логического адреса показана на рис. 8.7. Если выполняемый процесс обращается к логическому адресу v = (p,d), механизм отображения ищет номер страницы p в таблице страниц и определяет, что эта страница находится в страничном кадре p', формируя реальный адрес из p' и d.Рис. 8.7. Связь логического и физического адресов при страничной организации памяти Таблица страниц адресуется при помощи специального регистра процессора и позволяет определить номер кадра по логическому адресу. Помимо этой основной задачи, при помощи атрибутов, записанных в строке таблицы страниц, можно организовать контроль доступа к конкретной странице и ее защиту. 38. Управление памятью. Сегментно-страничная организация памяти компьютера. При сегментно-страничной организации памяти происходит двухуровневая трансляция виртуального адреса в физический. В этом случае логический адрес состоит из трех полей: номера сегмента логической памяти, номера страницы внутри сегмента и смещения внутри страницы. Соответственно, используются две таблицы отображения – таблица сегментов, связывающая номер сегмента с таблицей страниц, и отдельная таблица страниц для каждого сегмента. Рис. 8.9. Упрощенная схема формирования физического адреса при сегментно-страничной организации памяти Сегментно-страничная и страничная организация памяти позволяет легко организовать совместное использование одних и тех же данных и программного кода разными задачами. Для этого различные логические блоки памяти разных процессов отображают в один и тот же блок физической памяти, где размещается разделяемый фрагмент кода или данных. Сегмент памяти — одна из единиц адресации в некоторых моделях памяти. Физический адрес — это адрес, по которому производится реальное обращение к памяти. Обычно программисты не имеют напрямую дело с физическими адресами. Вместо этого они работают с виртуальными адресами (с логическими адресами), которые затем преобразуются процессором в физические. .. 39. Виртуальная память. Механизм реализации виртуальной памяти. Стратегия подкачки страниц. Программная поддержка сегментной модели памяти компьютера. Основы функционирования менеджера памяти. 1)Виртуальная память - это совокупность программно-аппаратных средств, позволяющих пользователям писать программы, размер которых превосходит имеющуюся оперативную память; для этого виртуальная память решает следующие задачи: размещает данные в запоминающих устройствах разного типа, например, часть программы в оперативной памяти, а часть на диске; перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы с диска в оперативную память; преобразует виртуальные адреса в физические. Все эти действия выполняются автоматически, без участия программиста, то есть механизм виртуальной памяти является прозрачным по отношению к пользователю. Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и странично-сегментное распределение памяти, а также свопинг. При страничной организации виртуальное адресное пространство процесса делится механически на равные части. Это не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а это свойство часто бывает очень полезным. Например, можно запретить обращаться с операциями записи и чтения в кодовый сегмент программы, а для сегмента данных разрешить только чтение. Странично-сегментное распределение памяти представляет собой комбинацию страничного и сегментного распределения памяти. Виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента. Оперативная память делится на физические страницы. При свопинге процесс перемещается между памятью и диском целиком, то есть в течение некоторого времени процесс может полностью отсутствовать в оперативной памяти. 2)Стратегия подкачки страниц. Стратегия считывания определяет, когда надо перемещать страницу с диска в память. Можно пытаться загрузить страницы, которые потребуются процессу, до того как он их запросит (заранее). А можно использовать стратегию подкачки по запросу, в этом случае страница загружается в память только тогда, происходит страничная ошибка. Диспетчер виртуальной памяти Windows использует алгоритм подкачки по запросу с кластаризацией. Когда возникает страничная ошибка, диспетчер виртуальной памяти загружает страницу, вызвавшую ошибку, вместе с небольшим количеством окружающих ее страниц. Это позволяет минимизировать количество страничных ошибок. При возникновении страничной ошибки система виртуальной памяти должна определить, в какое место физической памяти следует загрузить эту виртуальную страницу. Здесь начинает действовать стратегия размещения . В ОС Windows используется линейная архитектура памяти, поэтому если память не заполнена, диспетчер виртуальной памяти просто выбирает первый страничный фрейм из списка свободных страничных фреймов. Если этот список пуст, то диспетчер просматривает другие списки в заданном порядке. Если страничная ошибка происходит, когда вся физическая память заполнена, то применяется стратегия замещения. Она определяет, какую страницу нужно извлечь из памяти, чтобы освободить место для новой страницы. 3) Программная поддержка сегментной модели памяти компьютера. Реализация функций операционной системы, связанных с поддержкой памяти, - ведение таблиц страниц, трансляция адреса, обработка страничных ошибок, управление ассоциативной памятью и др. - тесно связана со структурами данных, обеспечивающими удобное представление адресного пространства процесса. Формат этих структур сильно зависит от аппаратуры и особенностей конкретной ОС. Чаще всего виртуальная память процесса ОС разбивается на сегменты пяти типов: кода программы, данных, стека, разделяемый и сегмент файлов, отображаемых в память (см. рис. 10.5). Сегмент программного кода содержит только команды. Обычно страницы данного сегмента имеют атрибут read-only. Следствием этого является возможность использования одного экземпляра кода для разных процессов. Сегмент данных, содержащий переменные программы и сегмент стека, содержащий автоматические переменные, могут динамически менять свой размер и содержимое, должны быть доступны по чтению и записи и являются приватными сегментами процесса. Рис. 10.5. Образ процесса в памяти С целью обобществления памяти между несколькими процессами создаются разделяемые сегменты, допускающие доступ по чтению и записи. Вариантом разделяемого сегмента может быть сегмент файла, отображаемого в память. Реализация разделяемых сегментов основана на том, что логические страницы различных процессов связываются с одними и теми же страничными кадрами. Сегменты представляют собой непрерывные области в виртуальном адресном пространстве процесса, выровненные по границам страниц. Каждая область состоит из набора страниц с одним и тем же режимом защиты. Два процесса могут общаться через разделяемую область памяти при условии, что им известно ее имя (пароль). Обычно это делается при помощи специальных вызовов (например, map и unmap), входящих в состав интерфейса виртуальной памяти. Загрузка исполняемого файла (системный вызов exec) осуществляется обычно через отображение (mapping) его частей (кода, данных) в соответствующие сегменты адресного пространства процесса. 4)Основы функционирования менеджера памяти. Корректная работа менеджера памяти помимо принципиальных вопросов, связанных с выбором абстрактной модели виртуальной памяти и ее аппаратной поддержкой, обеспечивается также множеством нюансов. В качестве примера такого рода компонента рассмотрим более подробно локализацию страниц в памяти, которая применяется в тех случаях, когда поддержка страничной системы приводит к необходимости разрешить определенным страницам, хранящим буферы ввода-вывода, другие важные данные и код, быть блокированными в памяти. Рассмотрим случай, когда система виртуальной памяти может вступить в конфликт с подсистемой ввода-вывода. Например, процесс может запросить ввод в буфер и ожидать его завершения. Управление передастся другому процессу, который может вызвать page fault и, с отличной от нуля вероятностью, спровоцировать выгрузку той страницы, куда должен быть осуществлен ввод первым процессом. Подобные ситуации нуждаются в дополнительном контроле. Одно из решений данной проблемы - вводить данные в не вытесняемый буфер в пространстве ядра, а затем копировать их в пользовательское пространство. Второе решение - локализовать страницы в памяти, используя специальный бит локализации, входящий в состав атрибутов страницы. Локализованная страница замещению не подлежит. Другим важным применением локализации является ее использование в системах мягкого реального времени. Вообщем говоря, виртуальная память - антитеза вычислений реального времени, так как дает непредсказуемые задержки при подкачке страниц. Поэтому системы реального времени почти не используют виртуальную память. Для решения проблемы page faults, Solaris разрешает процессам сообщать системе, какие страницы важны для процесса, и локализовать их в памяти. В результате возможно выполнение процесса, реализующего задачу реального времени, содержащего локализованные страницы, где временные задержки страничной системы будут минимизированы. 40. Файловые системы. Функции файловых систем и иерархия данных. Общая структура файловой системы управления внешней памятью. Кооперация процессов при работе с файлами. Файловые системы FAT,FAT32,NTFS. Под файлом обычно понимают именованный набор данных, организованных в виде совокупности записей одинаковой структуры. Для управления этими данными создаются соответствующие файловые системы. Файловая система предоставляет возможность иметь дело с логическим уровнем структуры данных и операций, выполняемых над данными в процессе их обработки. Именно файловая система определяет способ организации данных на диске или на каком-нибудь ином носителе. Специальное системное программное обеспечение, реализующее работу с файлами по принятым спецификациям файловой системы, часто называют системой управления файлами. Именно системы управления файлами отвечают за создание, уничтожение, организацию, чтение, запись, модификацию и перемещение файловой информации и т.д. Благодаря системам управления файлами пользователям предоставляются следующие возможности: 1. Создание, удаление, переименование (и другие операции) именованных наборов данных (файлов) из своих программ или посредством специальных управляющих программ, реализующих функции интерфейса пользователя с его данными и активно использующих систему управления файлами; 2. Работа с недисковыми периферийными устройствами как с файлами; 3. Обмен данными между файлами, между устройствами, между файлом и устройством (и наоборот); 4. Работа с файлами путем обращений к программным модулям системы управления файлами (часть api ориентирована именно на работу с файлами); 5. Защита файлов от несанкционированного доступа. Очевидно, что система управления файлами, будучи компонентом операционной системы, не является независимой от нее, поскольку активно использует соответствующие вызовы api. - При работе с файлами желательно ввести механизмы структурирования. Проще всего организовать иерархические отношения. Для этого достаточно ввести понятие каталога. Каталог содержит информацию о данных, организованных в виде файлов. Другими словами, в каталоге должны содержаться дескрипторы файлов. Файл-каталог должен иметь специальное системное значение; система управления файлами должна его выделять на фоне обычных файлов. Файл-каталог часто называют подкаталогом (subdirectory). Если файл-каталог содержит информацию о других файлах, то поскольку среди них также могут быть файлы-каталоги, мы получаем возможность строить почти ничем не ограниченную иерархию. Общая структура файловой системыСистема хранения данных на дисках может быть структурирована следующим образом (см. рис. 12.1). Нижний уровень - оборудование. Это в первую очередь магнитные диски с подвижными головками - основные устройства внешней памяти, представляющие собой пакеты магнитных пластин (поверхностей), между которыми на одном рычаге двигается пакет магнитных головок. Диски могут быть разбиты на блоки фиксированного размера и можно непосредственно получить доступ к любому блоку (организовать прямой доступ к файлам). Непосредственно с устройствами (дисками) взаимодействует часть ОС, называемая системой ввода-вывода. Система ввода-вывода предоставляет в распоряжение более высокоуровневого компонента ОС - файловой системы - используемое дисковое пространство в виде непрерывной последовательности блоков фиксированного размера. В структуре системы управления файлами можно выделить базисную подсистему, которая отвечает за выделение дискового пространства конкретным файлам, и более высокоуровневую логическую подсистему, которая использует структуру дерева директорий для предоставления модулю базисной подсистемы необходимой ей информации, исходя из символического имени файла. Она также ответственна за авторизацию доступа к файлам. Стандартный запрос на открытие (open) или создание (create) файла поступает от прикладной программы к логической подсистеме. Логическая подсистема, используя структуру директорий, проверяет права доступа и вызывает базовую подсистему для получения доступа к блокам файла. Когда различные пользователи работают вместе над проектом, они часто нуждаются в разделении файлов. Разделяемый файл - разделяемый ресурс. Как и в случае любого совместно используемого ресурса, процессы должны синхронизировать доступ к совместно используемым файлам, каталогам, чтобы избежать тупиковых ситуаций, дискриминации отдельных процессов и снижения производительности системы. Рассмотрим вначале грубый подход, то есть временный захват пользовательским процессом файла или записи (части файла между указанными позициями). Системный вызов, позволяющий установить и проверить блокировки на файл, является неотъемлемым атрибутом современных многопользовательских ОС. Допускается два варианта синхронизации: с ожиданием, когда требование блокировки может привести к откладыванию процесса до того момента, когда это требование может быть удовлетворено, и без ожидания, когда процесс немедленно оповещается об удовлетворении требования блокировки или о невозможности ее удовлетворения в данный момент. Более тонкий подход заключается в прозрачной для пользователя блокировке отдельных структур ядра, отвечающих за работу с файлами части пользовательских данных. Например, в ОС Unix во время системного вызова, осуществляющего ту или иную операцию с файлом, как правило, происходит блокирование индексного узла, содержащего адреса блоков данных файла. FAT,FAT32 — классическая архитектура файловой системы, которая из-за своей простоты всё ещё широко используется для флеш-накопителей. Используется в дискетах и некоторых других носителях информации. В файловой системе FAT смежные секторы диска объединяются в единицы, называемые кластерами. Количество секторов в кластере равно степени двойки (см. далее). Для хранения данных файла отводится целое число кластеров (минимум один), так что, например, если размер файла составляет 40 байт, а размер кластера 4 кбайт, реально занят информацией файла будет лишь 1 % отведенного для него места. Пространство тома FAT32 логически разделено на три смежные области: Зарезервированная область. Содержит служебные структуры, которые принадлежат загрузочной записи раздела и используются при инициализации тома; Область таблицы FAT, содержащая массив индексных указателей («ячеек»), соответствующих кластерам области данных. Обычно на диске представлено две копии таблицы FAT. Область данных, где записано собственно содержимое файлов — то есть текст текстовых файлов, кодированное изображение для файлов рисунков, оцифрованный звук для аудиофайлов и т. д. В настоящее время NTFS рассматривается в качестве предпочтительной файловой системы, как для серверных, так и для клиентских версий Windows. Текущие реализации в Windows поддерживают 32 разрядную адресацию кластеров, что при размере кластера максимум 64 КБ (216 байт) позволяет NTFS тому достигать размера до 256 Тб. Некоторые возможности NTFS: восстанавливаемость– способность файловой системы возвращаться к работоспособному состоянию после возникновения сбоя. Реализуется такая возможность, во первых, за счет поддержки атомарных транзакций, во вторых, за счет избыточности хранения информации. Атомарная транзакция– операция с файловой системой, приводящая к её изменению, которая либо полностью успешно выполняется, либо не выполняется вообще. безопасность– защищенность файлов от несанкционированного доступа. Реализуется при помощи модели безопасности Windows. шифрование– преобразование файла в зашифрованный код, который невозможно прочесть без ключа. Обычные механизмы безопасности, такие как назначение прав доступа пользователей к файлам, не обеспечивают полной защиты информации, например, в случае перемещения диска на другой компьютер. Администратор операционной системы всегда может получить доступ к файлам других пользователей, даже на томе NTFS. Поэтому в NTFS включена поддержка шифрующей файловой системы EFS (Encrypting File System), которая позволяет легко зашифровывать и расшифровывать файлы; поддержка RAID (массив недорогих (независимых) дисков с избыточностью) – возможность использования для хранения информации нескольких дисков; данные с одного диска автоматически копируются на другие, обеспечивая тем самым повышенную надежность; дисковые квоты для пользователей (Per-User Volume Quotas) – возможность выделения для каждого пользователя определенного пространства на диске (квоты); NTFS не позволяет пользователю записывать данные на диск сверх выделенной квоты. 41. Управление вводом-выводом в ОС. Основные принципы организации ввода-вывода в ОС. Режимы управления вводом-выводом в ОС. Основные системные таблицы ввода-вывода. Главный принцип ввода/вывода – любые операции по управлению вводом/выводом объявляются привилегированными и могут выполняться только самой ОС. Для обеспечения этого принципа в большинстве процессоров вводятся два режима: - режим пользователя, выполнение команд ввода/вывода запрещено; - режим супервизора, выполнение команд ввода/вывода разрешено. Использование команд ввода/вывода в пользовательском режиме вызывает прерывание обработки программы, и управление передается ОС. Для ОС одним из основных видов ресурсов являются устройства ввода/вывода и обслуживающие их программы. ОС должны управлять устройствами и позволять параллельно выполняющимися задачам использовать различные устройства ввода/вывода. Непосредственное обращение к внешним устройствам из пользовательских программ не разрешено по трем причинам: - возможные конфликты при доступе к устройствам ввода/вывода; - повышение эффективности использование этих ресурсов; - ошибки в программах ввода/вывода могут привести к разрушению системы. Компонента ОС, выполняющая ввод/вывод называется супервизором ввода/вывода. Основные задачи супервизора следующие: - получение, проверка на корректность и выполнение запросов на ввод/вывод от прикладных задач и от модулей самой системы; - планирование ввода/вывода: выполнение или постановка в очередь; - передача управления драйверам; - - передача сообщений об ошибках, если они появляются; - передача сигнала о завершении операции ввода/вывода. В случае, если устройство ввода-вывода является инициативным (устройство ввода-вывода, по сигналу прерывания от которого запускается соответствующая ему программа),управление со стороны супервизора ввода-вывода будет заключаться в активизации соответствующего вычислительного процесса (перевод его в состояние готовности к выполнению). Таким образом, прикладные программы (а в общем случае - все обрабатывающие программы) не могут непосредственно связываться с устройствами ввода-вывода независимо от того, в каком режиме используются эти устройства (монопольно или совместно), но, установив соответствующие значения параметров в запросе на ввод-вывод,определяющие требуемую операцию и количество потребляемых ресурсов, обращаются к супервизору задач. Последний передает управление супервизору ввода-вывода, который и запускает необходимые логические и физические операции. Как известно, имеется два основных режима ввода-вывода: режим обмена с опросом готовностиустройства ввода-вывода и режим обмена с прерываниями. Пусть центральный процессор посылает команду устройству управления, требующую, чтобы устройство ввода-вывода выполнило некоторое действие. Устройство управления исполняет команду, транслируя сигналы, понятные ему и центральному устройству, в сигналы, понятные устройству ввода-вывода. После выполнения команды устройство ввода-вывода выдает сигнал готовности,который сообщает процессору о том, что можно выдать новую команду для продолжения обмена данными. Однако поскольку быстродействие устройства ввода-вывода намного меньше быстродействия центрального процессора, то сигнал готовности приходится очень долго ожидать, постоянно опрашивая соответствующую линию интерфейса на наличие или отсутствие нужного сигнала. Посылать новую команду, не дождавшись сигнала готовности, сообщающего об исполнении предыдущей команды, бессмысленно. В режиме опроса готовности драйвер, управляющий процессом обмена данными с внешним устройством, как раз и выполняет в цикле команду «проверить наличие сигнала готовности». При этом нерационально используется время центрального процессора. Гораздо выгоднее, выдав команду ввода-вывода, на время забыть об устройстве ввода-вывода и перейти на выполнение другой программы. А появление сигнала готовности трактовать как запрос на прерывание от устройства ввода-вывода. Именно эти сигналы готовности и являются сигналами запроса на прерывание. Режим обмена с прерываниями по своей сути является режимом асинхронного управления. Для того чтобы не потерять связь с устройством (после выдачи процессором очередной команды по управлению обменом данными и переключения его на выполнение других программ), может быть запущен отсчет времени, в течение которого устройство обязательно должно выполнить команду и выдать-таки сигнал запроса на прерывание. Максимальный интервал времени, в течение которого устройство ввода-вывода или его контроллер должны выдать сигнал запроса на прерывание, часто называют установкой тайм-аута.Если это время истекло после выдачи устройству очередной команды, а устройство так и не ответило, то делается вывод о том, что связь с устройством потеряна и управлять им больше нет возможности. Пользователь и/или задача получают соответствующее диагностическое сообщение. Драйверы, работающие в режиме прерываний, представляют собой сложный комплекс программных модулей и могут иметь несколько секций: секцию запуска,одну или несколько секций продолженияи секцию завершения. Секция запуска инициирует операцию ввода-вывода. Эта секция запускается для включения устройства ввода-вывода или просто для инициализации очередной операции ввода-вывода. Секция продолжения (их может быть несколько, если алгоритм управления обменом данными сложный, и требуется несколько прерываний для выполнения одной логической операции) осуществляет основную работу по передаче данных. Секция продолжения, собственно говоря, и является основным обработчиком прерывания. Секция завершения обычно выключает устройство ввода-вывода или просто завершает операцию. Для управления всеми операциями ввода-вывода и отслеживания состояния всех ресурсов, занятых в обмене данными, операционная система должна иметь соответствующие информационные структуры. Эти информационные структуры, прежде всего, призваны отображать следующую информацию: состав устройств ввода-вывода и способы их подключения; аппаратные ресурсы, закрепленные за имеющимися в системе устройствами ввода-вывода; логические (символьные) имена устройств ввода-вывода, используя которые вычислительные процессы могут запрашивать те или иные операции ввода-вывода; адреса размещения драйверов устройств ввода-вывода и области памяти для хранения текущих значений переменных, определяющих работу с этими устройствами; области памяти для хранения информации о текущем состоянии устройства ввода-вывода и параметрах, определяющих режимы работы устройства; данные о текущем процессе, который работает с данным устройством; адреса тех областей памяти, которые содержат данные, собственно и участвующие в операциях ввода-вывода (получаемые при операциях ввода данных и выводимые на устройство при операциях вывода данных). Эти информационные структуры часто называют таблицами ввода-вывода, хотя они, в принципе, могут быть организованы и в виде списков. Каждая операционная система ведет свои таблицы ввода-вывода, их состав (и количество, и назначение каждой таблицы) может сильно отличаться. Исходя из принципа управления вводом-выводом ,можно сделать вывод о необходимости создания, по крайней мере, трех системных таблиц: 1) таблица оборудования (содержит информацию обо всех устройствах ввода-вывода, подключенных к вычислительной системе) 2) Вторая таблица предназначена для реализации еще одного принципа виртуализации устройств ввода-вывода — принципа независимости от устройства. 3)таблица прерываний —необходима для организации обратной связи между центральной частью и устройствами ввода-вывода. Эта таблица указывает для каждого сигнала запроса на прерывание тот элемент UCB, который сопоставлен данному устройству. 42. Проблемы надежности и безопасности ОС. Защитные механизмы ОС (принципы построения, защита от сбоев и несанкционированного доступа). Идентификация и аутентификация. Основными задачами защиты операционных систем являются идентификация, аутентификация, разграничение доступа пользователей к ресурсам, протоколирование и аудит самой системы Идентификация и аутентификацияНаиболее распространенным способом контроля доступа является процедура регистрации. Обычно каждый пользователь в системе имеет уникальный идентификатор. Идентификаторы пользователей применяются с той же целью, что и идентификаторы любых других объектов, файлов, процессов. Идентификация заключается в сообщении пользователем своего идентификатора. Для того чтобы установить, что пользователь именно тот, за кого себя выдает, то есть что именно ему принадлежит введенный идентификатор, в информационных системах предусмотрена процедура аутентификации ("установление подлинности"), задача которой - предотвращение доступа к системе нежелательных лиц. Обычно аутентификация базируется на одном или более из трех пунктов: то, чем пользователь владеет (ключ или магнитная карта); то, что пользователь знает (пароль); атрибуты пользователя (отпечатки пальцев, подпись, голос). Шифрование паролей в операционных системахДля хранения секретного списка паролей на диске во многих ОС используется криптография. Система задействует одностороннюю функцию, которую просто вычислить, но для которой чрезвычайно трудно (разработчики надеются, что невозможно) подобрать обратную функцию. Например, в ряде версий Unix в качестве односторонней функции используется модифицированный вариант алгоритма DES. Введенный пароль длиной до 8 знаков преобразуется в 56–битовое значение, которое служит входным параметром для процедуры crypt(), основанной на этом алгоритме. Результат шифрования зависит не только от введенного пароля, но и от псевдослучайной последовательности битов, называемой привязкой (переменная salt). Это сделано для того, чтобы решить проблему совпадающих паролей. Очевидно, что саму привязку после шифрования необходимо сохранять, иначе процесс не удастся повторить. Модифицированный алгоритм DES выполняется, имея входное значение в виде 64–битового блока нулей, с использованием пароля в качестве ключа, а на каждой следующей итерации входным параметром служит результат предыдущей итерации. Всего процедура повторяется 25 раз. Полученное 64–битовое значение преобразуется в 11 символов и хранится рядом с открытой переменной salt. В ОС Windows NT преобразование исходного пароля также осуществляется многократным применением алгоритма DES и алгоритма MD4. Хранятся только кодированные пароли. При удаленном доступе к ОС нежелательна передача пароля по сети в открытом виде. Одним из типовых решений является использование криптографических протоколов. Авторизация.После успешной регистрации система должна осуществлять авторизацию (authorization) – предоставление субъекту прав на доступ к объекту. Средства авторизации контролируют доступ легальных пользователей к ресурсам системы, предоставляя каждому из них именно те права, которые были определены администратором, а также осуществляют контроль возможности выполнения пользователем различных системных функций. Выявление вторжений. Аудит системы защитыОбнаружение попыток вторжения является важнейшей задачей системы защиты, поскольку ее решение позволяет минимизировать ущерб от взлома и собирать информацию о методах вторжения. Основным инструментом выявления вторжений является запись данных аудита. Отдельные действия пользователей протоколируются, а полученный протокол используется для выявления вторжений. Аудит, таким образом, заключается в регистрации специальных данных о различных типах событий, происходящих в системе и так или иначе влияющих на состояние безопасности компьютерной системы. К числу таких событий обычно причисляют следующие: · вход или выход из системы; · операции с файлами (открыть, закрыть, переименовать, удалить); · обращение к удаленной системе; · смена привилегий или иных атрибутов безопасности 1 2 |