шпора. 34. генеральная совокупность и выборка сущность выборочного метода. Выборочный метод позволяет оценить совокупность изучаемых объектов на основе их части или выборки
 Скачать 38.12 Kb. Скачать 38.12 Kb.
|

Zn-X2 "22-19" ' 34. 6.2. ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ И ВЫБОРКА Сущность выборочного метода. Выборочный метод позволяет оценить совокупность изучаемых объектов на основе их части или выборки. В статистике различают всю или генеральную совокупность, подлежащую изучению, и выборочную совокупность объектов, фактически измеряемых. На практике их обозначают кратко: совокупность и выборка. Генеральная совокупность (Г. с.) может быть конечной, т. е. известного объема (/V). Однако, как правило, ее объем слишком велик или неизвестен, и она понимается гипотетически, или абстрактно. Например, Г. с. могут составлять 200 семян новой, интересной с точки зрения селекционера линии или 1 т семян нового сорта, делянка, а также целые поля региона или страны, засеянные этим сортом. Для оценки длины льносоломы можно взять на поле (делянке) от 5 до 500 растений. Совокупность цифр (статистическую совокупность), полученную в результате проведенного обследования, подвергают «уплотнению» (математической обработке) и получают несколько показателей, называемых оценками совокупности, или характеристиками выборки, или «статистиками»*. На их основе составляют доверительные интервалы (ДИ или Ь) параметров генеральной совокупности. Ошибка выборки. Суть статистической оценки сводится к установлению величины ошибки выборки, называемой случайной ошибкой, статистической погрешностью, или ошибкой эксперимента: е = 54п, абсолютная и Е — Л|—'•••-=гт> или е,% = е-100/у, относиV и У тельная ошибка. В этих формулах 52 — дисперсия; 5 — стандартное отклонение; п — число всех значений, или объем выборки; у — среднее значение выборки, или выборочная средняя. Ошибку чаще обозначают буквой 5" с индексом среднего значения признака х или У $у). Ошибка позволяет характеризовать точность исследования и достоверность выводов до определенного уровня вероятности (но не до 100 %!). Ошибка — закономерна, ибо часть (выборка) в условиях изменчивой среды никогда не отражает полностью целое (совокупность). Случайную ошибку нельзя связывать с несовершенством метода или инструмента, с отсутствием навыка или неаккуратностью исполнителя. Каждый метод, инструмент, как и человеческий фактор, имеют свою погрешность. Все это — источники ошибок систематического или грубого характера. Они не поддаются учету, поскольку в отличие от случайной ошибки не имеют математических формул и, как следствие, лишь завышают величину последней. Таким образом, следует различать три вида ошибок выборки (в опыте): случайные (статистические), систематические (смещения) и грубые (ошибки в прямом смысле). Систематические ошибки в полевом опыте обусловлены неучетом закономерного (направленного), или смещенного варьирования плодородия почвы; сбоями (отсутствие регулировки) в работе инструментов, приборов и орудий; ориентацией исследователя на типичные растения (точки делянки) и т. д. Эти ошибки-смещения можно контролировать с помощью элементов методики опыта (повторность, повторения, блоки, делянки, их размеры и ориентация), а также соответствующей математической модели. Кроме того, необходимо использовать исправные (отрегулированные) приборы и орудия. Грубые ошибки носят субъективный характер и связаны с неаккуратностью (небрежностью) исполнителей, их незнанием или невыполнением базовых требований научного исследования. Составление выборки. Для отбора объектов (проб) необходимо хорошо знать совокупность, иметь соответствующую подготовку и соблюдать следующие два требования. {.Рандомизация (случайность, или принцип жребия). Каждое растение и точка на делянке должны иметь равный шанс быть отобранными. Случайность при отборе может быть ограничена сегментами (частями) поля или делянки. 2. 35. Методы вторичной статистической обработки результатов эксперимента. Способы вторичной статистической обработки результатов исследования. Регрессионное исчисление. Сравнение средних величин разных выборок. Сравнение частотных распределений данных. Сравнение дисперсий двух выборок. Установление корреляционных зависимостей и их интерпретация. Понятие о факторном анализе как методе статистической обработки. пособы табличного и графического представления результатов эксперимента. Виды таблиц и их построение. Графическое представление экспериментальных данных. Гистограммы и их применение на практике. Методами статистической обработки результатов эксперимента называются математические приемы, формулы, способы количественных расчетов, с помощью которых показатели, получаемые в ходе эксперимента, можно обобщать, приводить в систему, выявляя скрытые в них закономерности. Первичными называют методы, с помощью которых можно получить показатели, непосредственно отражающие результаты производимых в эксперименте измерений. Соответственно под первичными статистическими показателями имеются в виду те, которые применяются в самих психодиагностических методиках и являются итогом начальной статистической обработки результатов психодиагностики. Вторичными называются методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности. 37 Разработка программы эксперимента Степень риска эксперимента в значительной степени может быть снижена, а вероятность выхода на эффективные решения повышена, если тщательно разработать программу эксперимента. Объект исследования – это то педагогическое пространство, та область, в рамках которой и находится (содержится) то, что будет изучаться. Чаще всего – это определенный процесс (обучения, воспитания, социализации, становления личности, управления). Объектами исследования могут быть развитие педагогического или ученического коллектива, система воспитательной работы школы, учебно-воспитательный (образовательный, педагогический) процесс, преподавание какого-то предмета, система управления в школе и т.п. Предмет исследования – это конкретная часть объекта или процесс, в нем происходящий, или аспект проблемы, своего рода «угол зрения», который, собственно, и исследуется. Рассмотрим примеры. Если объектом будет учебно-воспитательный процесс в лицее, то предметом может быть, например, механизм отбора детей (разработка диагностических методик) для обучения в школе этого типа или формирование оптимальных вариантов учебного плана, или механизм интенсификации обучения в этих условиях. Если объект – процесс обучения иностранному языку, то предметом может служить, например, механизм применения суггестивных методов обучения. Предмет всегда изучается в рамках какого-то объекта. Как правило, предмет в большой степени совпадает с темой эксперимента (исследования), однако предмет должен не повторять, а раскрывать, конкретизировать тему. Формулирование цели эксперимента – следующий необходимый элемент разработки программы. Чтобы успешно и с минимальными затратами времени справиться с формулированием цели, нужно ответить себе на вопрос: «Что ты хочешь создать в итоге организуемого эксперимента?» Этим итогом могут быть: новая методика, классификация, новая программа или учебный план, алгоритм, структура, новый вариант известной технологии, методическая разработка и т.д. Очевидно, что цель любого эксперимента, как правило, начинается с глаголов: выяснить, выявить и тд. 36 Стандартные методы характеризуются более частым, обычно через 1—2 опытных варианта, расположением контроля, стандарта. Стандартные методы основаны на том, что плодородие опытного участка изменяется постепенно, и между урожаями ближайших делянок наблюдается корреляционная связь. В стандартных методах каждый изучаемый вариант сравнивают со своим контролем, урожай которого вычисляют способом линейной интерполяции, находя промежуточные значения функции на основании предположения о постепенном изменении плодородия почвы земельного участка. Стандартные методы размещения полевого опыта иногда подкупают простотой и предполагаемой возможностью устранить влияние пестроты плодородия почвы и тем самым свести к минимуму ошибки эксперимента. Кажется, что стандарт, расположенный возле каждого изучаемого варианта, даст наиболее точную оценку эффетивности сорта или агротехнического приема. Однако практика применения и сравнительной оценки стандартных методов вьрявила их существенные недостатки. Во-первых, не всегда наблюдается тесная корреляционная зависимость между урожаями рядом расположенных делянок. Во-вторых, очень трудно сравнивать опытные варианты, далеко расположенные друг от друга, что бывает при большом числе (свыше 10—12) изучаемых вариантов. В-третьих, стандартные методы характеризуются большой громоздкостью и нерациональным использованием земельной площади, особенно при большом числе изучаемых вариантов. Действительно, при размещении стандарта через два опытных варианта около 40%, а через один — более 50% всей площади опыта занято стандартными делянками. Отмеченные недостатки не способствовали широкому распространению стандартных методов в опытной, работе. 38 Первичная обработка экспериментальных данных Первичная обработка результатов исследования химического равновесия основана на рекомендациях [38, 101-104] и включала в себя следующее. Расчет отношений концентраций компонентов, характеризующих константы равновесия изучаемых реакций. Анализ изученных отношений с целью установления момента достижения равновесия и включения в обработку только равновесных данных. Исключение грубых ошибок внутри серии определений константы равновесия. Для каждой температуры исследования сериями считали опыты, различающиеся между собой либо составом исходной смеси, либо количеством катализатора. Отбраковку промахов в сериях проводили с использованием критерия - наибольшего по абсолютной величине нормированного выборочного отклонения: 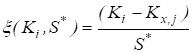 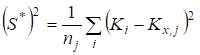 ,где - значение константы равновесия; - среднее арифметическое значение константы равновесия в серии j; - смещенная дисперсия ; - число результативных определений константы равновесия в серии j. Процентные точки наибольшего по абсолютной величине нормированного выборочного отклонения заимствованы из работы [102]. Расчет среднего арифметического значения константы равновесия и дисперсии воспроизводимости в сериях после исключения грубых ошибок: 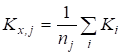 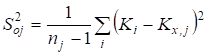 Сопоставление дисперсий воспроизводимости констант равновесия в сериях при одной температуре. Эта стадия дисперсионного анализа является весьма полезной, так как позволяет контролировать ошибки воспроизводимости, возникающие на всех этапах получения экспериментальной информации. Проверку равенства дисперсий воспроизводимости в сериях выполняли по двум критериям: Фишера - если число серий равнялось двум и Бартлетта - когда количество серий превышало два [38, 102]. Если нуль-гипотеза выполнялась, то дисперсию воспроизводимости вычисляли по следующей формуле: 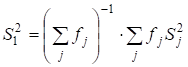 где . Для всех изученных в данной работе превращений дисперсии воспроизводимости констант равновесия в сериях были однородны. Расчет среднего значения константы равновесия для каждой температуры исследования: 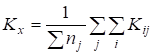 Проверку значимости расхождения средних значений констант равновесия в сериях. Для этого вычисляли дисперсию : 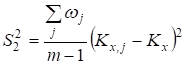 где m - число серий, j - вес серии j, равный числу определений nj. Величина характеризовала рассеяние значений относительно . Число степеней свободы дисперсии равнялось . Проверку гипотезы равенства средних значений констант равновесия в сериях проводили с помощью распределения Фишера. Если нуль-гипотеза выполнялась, то вычисляли сводную дисперсию 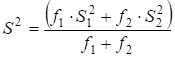 с числом степеней свободы . На этом обработка заканчивалась. Для всех исследованных реакций расхождения между серийными константами равновесия не превышали дисперсии воспроизводимости, что указывало на отсутствие систематических отклонений. 40. Ранжируют вариационный ряд в возрастающем порядке: 10,1; 19,0; 19,9; 20,8; 21,0; 22,0. Двум первым и двум последним данным присваивают обозначения Х\, X2, Хп—\, Xn. Наиболее 273 сомнительными будут крайние, т. е. 10,1 и 22,0. Их сомнительность проверяют путем расчета критерия х для Х\ и Xn по формулам X2-Xi = 19,0- 10,1 1 Xn-I-Xi 21,0-10,1 |