Статья на нир. Статья-ИТИС-5. А. В. Мельников применение тематического моделирования (topic modeling) в задачах автоматической генерации рабочей программы дисциплины (рпд) на основе модели предметной области дисциплины (мпод) Статья
 Скачать 104.71 Kb. Скачать 104.71 Kb.
|

|
О.Ю. Матковская, А.В. Мельников ПРИМЕНЕНИЕ ТЕМАТИЧЕСКОГО МОДЕЛИРОВАНИЯ (TOPIC MODELING) В ЗАДАЧАХ АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ РАБОЧЕЙ ПРОГРАММЫ ДИСЦИПЛИНЫ (РПД) НА ОСНОВЕ МОДЕЛИ ПРЕДМЕТНОЙ ОБЛАСТИ ДИСЦИПЛИНЫ (МПОД) Статья посвящена тематическому моделированию: основным концепция, терминологиям, вероятностному латентному семантическому анализу и латентному размещению Дирихле (LDA). Кроме того, в статье приведен краткий обзор существующих ПО для автоматической разработки рабочие программы дисциплин (РПД). А также рассмотрено применение тематического моделирование в задаче автоматической генерации рабочей программы дисциплины (РПД). The article is devoted to the topic model: basic concepts, terminology, probabilistic latent semantic analysis and latent Dirichlet allocation (LDA). In addition, the article provides an overview of existing software for automatic design course programme. And also considered the use of thematic modeling in the problem of automatic generation of the course programme. 1 Введение В настоящее время практически каждый год Министерство Образования выпускает новые образовательные стандарты. В связи с этим университеты ежегодно создают новые учебные планы и новые рабочие программы дисциплин (РПД). Качественно разработанные и грамотно составленные РПД являются очень важной составляющей престижного учебного заведения. Когда на протяжении нескольких лет РПД по конкретной дисциплине составляет один и тот же преподаватель, то данный процесс не вызывает затруднений. А как начинающему преподавателю грамотно и качественно разработать РПД? В таком случае, Интернет выступает в качестве главного помощника: преподаватель ищет или уже готовую РПД и редактирует ее под свои особенности, если конечно в Интернете есть готовая РПД, или составляет свою РПД из отдельных источников информации по частям. В любом случае, полученная РПД может получиться не грамотно составленной по разным причинам: необходимо производить сравнение структур разных РПД; необходимо производить анализ множества результатов по поиску критериев; необходимо компоновать из разных источников множество информации, если нет готовой РПД; необходимо искать и пересматривать огромное количество отзывов для составления качественной РПД. На данный момент существуют различные решения данных проблем: Конструктор СОНАТА-ПРО, который представляет собой интерактивную среду для быстрой разработки рабочих программ учебных курсов и дисциплин. Недостатком данного продукта является то, что он платный и нет никакой демо-версии. Киберос - Кибернетическая образовательная система, которая предназначена для организации и управления учебным процессом в вузе или среднем учебном заведении на основе подхода "двойная спираль". Этот подход предполагает дополнить каждый элемент традиционного аудиторного учебного процесса электронным информационным наполнением. Автор и разработчик Киберос - Пак Эдуард Дмитриевич. Преподаватель КГПУ. Данная система разработана для преподавателей данного ВУЗа и на данный момент не предоставляет возможности покупки доступа в систему или регистрации в системе. В 2012 г. Королева И. Ю. в журнале «Молодой ученый» опубликовала статью «Автоматизация процесса разработки УМКД кафедры вуза», в которой она предлагает разработать модуль автоматизации УМКД кафедры ВУЗа, но при этом на тот момент она еще не выбрала средство разработки [1]. Существует достаточно большое количество как зарубежных, так и отечественных программ электронного документооборота. Все зарубежные программы достаточно дорогостоящие, имеют избыточные функциональные возможности, сложны в обслуживании и их невозможно настроить на работу кафедры российского ВУЗа и тем более для конкретной задачи по разработке РПД. А также существуют несколько систем для автоматизированной разработки РПД, но все они не подходят для разработки любых РПД, т.к. у каждого ВУЗа своя утвержденная структура РПД. Целью диссертационного исследования является разработка системы автоматической генерации РПД на основе модели предметной области дисциплины (МПОД). Для реализации поставленной цели необходимо в первую очередь создать МПОД с использованием методов анализа текста (статистические метода и тематическое моделирование). 2 Тематическое моделирование В настоящее время графические модели являются основным инструментом для построения вероятностных тематических моделей (probabilistic topic model). Тематическое моделирование (topic modeling) — одно из современных приложений машинного обучения к анализу текстов, активно развивающееся с конца 90-х годов. Тематическая модель (topic model) коллекции текстовых документов определяет, к каким темам относится каждый документ и какие слова (термины) образуют каждую тему[2]. Вероятностная тематическая модель (ВТМ) описывает каждую тему дискретным распределением на множестве терминов, каждый документ — дискретным распределением на множестве тем. Предполагается, что коллекция документов — это последовательность терминов, выбранных случайно и независимо из смеси таких распределений, и ставится задача восстановления компонент смеси по выборке. Поскольку документ или термин может относиться одновременно ко многим темам с различными вероятностями, говорят, что ВТМ осуществляет «мягкую» кластеризацию документов и терминов по кластерам-темам. Тем самым решаются проблемы синонимии и омонимии терминов, возникающие при обычной «жёсткой» кластеризации. Синонимы, часто употребляющиеся в схожих контекстах, с большой вероятностью попадают в одну тему. Омонимы, употребляющиеся в разных контекстах, распределяются между несколькими темами соответственно частоте употребления. Тематические модели применяются для выявления трендов в научных публикациях или новостных потоках [3, 4], для классификации и категоризации документов [5] изображений и видеопотоков [6-8], для информационного поиска [9], в том числе многоязычного [10], для тегирования веб-страниц [11], для обнаружения текстового спама [12], для рекомендательных систем [13] и других приложений. Графические модели могут быть разделены на две основные категории: ориентированные и неориентированные графические модели, каждая из которых может быть параметрической и непараметрической (рисунок 1). 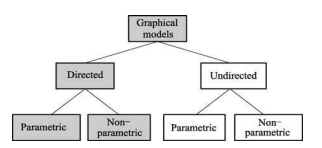 Рисунок 1. Классификация графических моделей Если ориентированная тематическая модель является вероятностной (DPTM - directed probabilistic topic model), то оценка соответствия документа теме считается как доля содержимого документа, которая относится к данной конкретной теме, то есть имеет вероятностный смысл. Данная модель не является достаточно исследованной в теории самообучения (обучения без учителя, unsupervised learning). Самый первый предложенный метод - это вероятностный латентный семантический анализ (PLSA - probabilistic latent semantic analysis), который основан на принципе максимума правдоподобия. Следующий метод, который был предложен – это метод латентного размещения Дирихле (LDA - latent Dirichlet allocation). Предполагается, что использование тематического моделирования дает возможность получить ответ на большое количество нестандартных вопросов, например таких: каким образом узнать смысл или тему документа по их содержанию? Каким образом производить классификацию документов на основе тематических закономерностей? Каким образом узнавать научные интересы авторов и находить экспертов в специальных областях знания? Каким образом выявлять скрытые ассоциативные связи между отдельными исследователями или группами людей? И многие другие. Известны вводные обзоры [14,15] по вероятностным тематическим моделям и методам оценивания их параметров. Концепции и терминология 2.1 Документ Обычно документ включает в себя множества слов, терминов (словосочетаний), специальных символов, таблиц, графиков, и т.д. В литературе по тематическому моделированию в качестве стандартных видов документов выступают научные статьи и новостные сообщения. Обычно документ представляется d вектором (конкатенацией) слов wd= {wd1+….+ wdn}, где wdi— i-е слово в документе d, а коллекция из D документов представляется совокупностью векторов слов D = {w1,….,wD }, где wd— вектор слов документа d. 2.2 Тема В исследованиях по тематическому моделированию нет четко сформулированного определения темы (topic). Различные научные школы по-разному определяют понятие темы: «скрытый паттерн», «компактное описание смысла документов», «вероятностный (нечёткий) кластер семантически связанных терминов», «связующее звено между терминами и другими объектами (документами, авторами, организациями, конференциями, и т.д.), которое позволяет находить скрытые ассоциативные связи между ними». Формально тема определяется как дискретное (мультиномиальное) вероятностное распределение в пространстве слов заданного словаря. Документ может состоять из огромного числа слов, однако эти слова могут порождаться небольшим числом тем, как смесью мультиномиальных распределений [16]. 2.3 Вероятностный латентный семантический анализ (PLSA) PLSA [17] — это первая вероятностная тематическая модель с латентными переменными, имеющая строгие статистические обоснования. В [18] она также называется моделью аспектов (aspect model). Эта модель основана на предположении, что совместное появление пар (документ, слово) обусловлено латентными переменными z T {z1,…., zt}. Совместное распределение на парах d w определяется как смесь распределений: p(d,w) p(d) p(w| d), где p(w| d)= 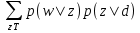 (1) (1)Предполагается, что каждая пара (d,w) появляется независимо, в соответствии с предположением о том, что документ — это «мешок слов». Слова w появляются в документе в зависимости от тем z, но независимо друг от друга. Можно сделать вывод о том, что модель PLSA описывает порождение слов в документе, но не описывает порождение самих документов. Вероятностная модель PLSA представлена на рисунке 2. 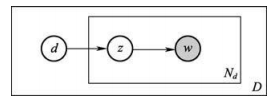 Рисунок 2. Вероятностная модель PLSA 2.4 Латентное размещение Дирихле (LDA) В отличие от PLSA, модель LDA описывает и порождение слов в документе, и порождение самих документов. Это возможно благодаря тому, что в модели LDA документы выступают в качестве смеси распределений латентных тем, где каждая тема определяется вероятностным распределением на множестве слов. Модель LDA выявляет скрытые связи между словами при помощи тем. Кроме того, она позволяет присваивать вероятности новым документам, не входившим в обучающую выборку. Для этого модель LDA использует алгоритм вариационного вывода. На рисунке 3 графически представлена данная модель. 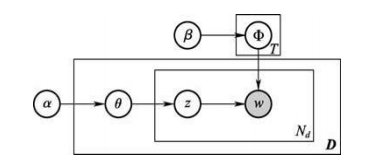 Рисунок 3. Вероятностная модель LDA Фактически LDA является трехуровневой байесовской сетью, которая порождает документ из смеси тем. На первом шаге для каждого документа d выбирается случайный вектор d из распределения Дирихле с параметром α (обычно α принимается равным 50/T). На втором шаге выбирается тема zdi из мультиномиального распределения с параметром d . Наконец, согласно выбранной теме zdi выбирается слово wdi из распределения zdi , которое является распределением Дирихле с параметром β (обычно параметр 0.1 , увеличение β ведёт к более разреженным тематикам) [19]. Таким образом, порождающая модель слова w из документа d представляется в виде: p(w|d, ,) = 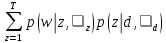 (2) (2)Для оценки параметров LDA используются простой вариационный EM-алгоритм и семплирование Гиббса [19,20]. Применение тематического моделирование в задаче автоматической генерации рабочей программы дисциплины (РПД) Изучив теоретические аспекты тематического моделирования, можно поставленную цель в диссертационном исследовании реализовать разбив ее решение на два этапа. На первом этапе реализации системы необходимо на основе имеющейся документации (книги по конкретной области наук, разработанные РПД конкретной дисциплины) сформировать множество всех разделов (топиков, тем), которые только могут быть в данной конкретной дисциплине (рисунок 4). 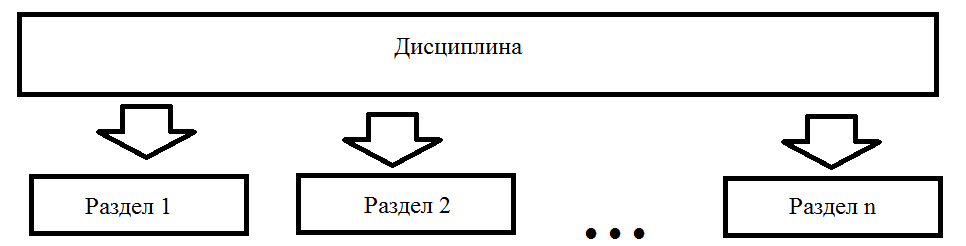 Рисунок 4. Множество всех разделов На втором этапе реализации системы необходимо по полученным требованиям к РПД (например, список компетенций) с применением тематического моделирования выбрать только те темы дисциплины, которые удовлетворяют данным требованиям. Общая схема работы системы представлена на рисунке 5. 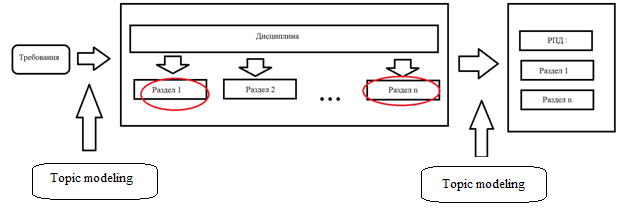 Рисунок 1. Общая схема Заключение В данной работе было исследовано тематическое моделирование и построена общая схема работы системы построения модели предметной области дисциплины. В дальнейшем планируется проведение эксперимента решения проблемы. Библиографический список Чичиль В. О. Разработка автоматизированной системы для организации документооборота невыпускающей кафедры вуза [Текст] / В. О. Чичиль, И. Ю. Королева // Молодой ученый. — 2015. — №23. — С. 74-78 Сайт «Вероятностное тематическое моделирование К. В. Воронцов» (конспект лекций) [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/images/2/22/Voron-2013-ptm.pdf, свободный. Zhang J., Song Y., Zhang C., Liu S. Evolutionary hierarchical Dirichlet processes for multiple correlated time-varying corpora // Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. — 2010. — Pp. 1079–1088. TextFlow: Towards better understanding of evolving topics in text. / W. Cui, S. Liu, L. Tan, C. Shi, Y. Song, Z. Gao, H. Qu, X. Tong // IEEE transactions on visualization and computer graphics. — 2011. — Vol. 17, no. 12. — Pp. 2412–2421. Rubin T. N., Chambers A., Smyth P., Steyvers M. Statistical topic models for multilabel document classification // Machine Learning. — 2012. — Vol. 88, no. 1-2. — Pp. 157–208. Li X.-X., Sun C.-B., Lu P., Wang X.-J., Zhong Y.-X. Simultaneous image classification and annotation based on probabilistic model // The Journal of China Universities of Posts and Telecommunications. — 2012. — Vol. 19, no. 2. — Pp. 107– 115. Feng Y., Lapata M. Topic models for image annotation and text illustration // Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. — Association for Computational Linguistics, 2010. — Pp. 831–839. Varadarajan J., Emonet R., Odobez J.-M. A sparsity constraint for topic models — application to temporal activity mining // NIPS-2010 Workshop on Practical Applications of Sparse Modeling: Open Issues and New Directions. — 2010. Yi X., Allan J. A comparative study of utilizing topic models for information retrieval // Advances in Information Retrieval. — Springer Berlin Heidelberg, 2009. — Vol. 5478 of Lecture Notes in Computer Science. — Pp. 29–41. Vuli´c I., Smet W., Moens M.-F. Cross-language information retrieval models based on latent topic models trained with document-aligned comparable corpora // Information Retrieval. — 2012. — Pp. 1–38. Krestel R., Fankhauser P., Nejdl W. Latent dirichlet allocation for tag recommendation // Proceedings of the third ACM conference on Recommender systems. — ACM, 2009. — Pp. 61–68. Павлов А. С., Добров Б. В. Метод обнаружения массово порожденных неестественных текстов на основе анализа тематической структуры // Вычислительные методы и программирование: новые вычислительные технологии. — 2011. — Т. 12. — С. 58–72. Yeh J.-h., Wu M.-l. Recommendation based on latent topics and social network analysis // Proceedings of the 2010 Second International Conference on Computer Engineering and Applications. — Vol. 1. — IEEE Computer Society, 2010. — Pp. 209– 213. Steyvers M, Griffiths T. Probabilistic topic models. In: Landauer T, Mcnamara D, Dennis S, Kintsch W (Eds), Latent Semantic Analysis: A Road to Meaning. Laurence Erlbaum, 2007. Heinrich G. Parameter Estimation for Text Analysis. Technical report, Version 2, February 2008. Blei D M, McAuliffe J. Supervised topic models. In: Advances in Neural Information Processing Systems (NIPS) 21. Cambridge, MA, MIT Press, 2007, 121–128 Hofmann T. Probabilistic latent semantic analysis. In: Proceedings of the 15th Annual Conference on Uncertainty in Artificial Intelligence (UAI), Stockholm, Sweden, July 30- August 1, 1999 Hofmann T, Puzicha J, Jordan M I. Learning from dyadic data. In: Advances in Neural Information Processing Systems (NIPS) 11. Cambridge, MA, MIT Press, 1999 Griffiths T L, Steyvers M. Finding scientific topics. In: Proceedings of the National Academy of Sciences. USA, 2004, 101: 5228–5235 Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation. Journal of Machine Learning Research, 2003, 3: 993–1022 Матковская Оксана Юрьевна – аспирант, преподаватель кафедры информационных технологий и экономической информатики Челябинского государственного университета (ИИТ). Е-mail: oxsa91@gmail.com, mou@csu.ru Мельников Андрей Витальевич – Доктор технических наук, профессор института информационных технологий (ИИТ) Челябинского государственного университета, директор ИИТ Челябинского государственного университета. Е -mail: mav@csu.ru |