ГИС в лесном деле. гис2. Базовые модели данных, используемые в гис. Инфологическая, иерархическая модели
 Скачать 272.24 Kb. Скачать 272.24 Kb.
|

|
Содержание Базовые модели данных, используемые в ГИС. Инфологическая, иерархическая модели……………………………………………………..3 Квадратомическая модель данных………………………………………12 Реляционная модель данных……………………………………………..16 Модель «сущность-связь»………………………………………………..21 Сетевые, семантические и бинарные модели……………...……………24 Особенности организации данных в ГИС………………………………26 Список используемых источников…………………………………………..…28 Базовые модели данных, используемые в ГИС. Инфологическая, иерархические модели. Модели данных в ГИС. Объектом информационного моделирования в ГИС является пространственный объект. Это цифровое представление объектов местности, содержащее информацию о местоположении и свойствах (атрибутах). Пространственные объекты реализуются в различных моделях. Современные ГИС используют следующие основные модели представления данных: • растровую; • матричную; • квадротомическую; • векторную. Рассмотрим наиболее распространенные и простые модели, которые могут быть реализованы в настольных ГИС: растровые и векторные. Растровый метод основан на разбиении поверхности на множество равных по размеру элементов (ячеек, пикселей). Геометрические формы элементарных составляющих растра могут быть различными, но обычно они представлены прямоугольниками или квадратами. Таким образом, растр представляет собой прямоугольную таблицу, состоящую из множества строк и колонок, образованных пикселями, имеющими определенный цвет. При обычном отображении элементарные частицы растра (ячейки, пиксели) не видны, но при значительном увеличении их легко обнаружить. В соответствии с этим, растровая модель может быть обозначена как цифровое представление пространственных объектов в виде совокупности элементов растра (пикселов) с присвоенными им значениями класса объекта. Растровые атрибуты не содержат точной координатной информации для объектов географического пространства, поскольку оно поделено на дискретные ячейки конечного размера. Для покрытия всей области частицы растра должны примыкать друг к другу, а это значит, что, придав каждому из них определенные номера по вертикали и горизонтали, их можно использовать в качестве координатной сетки. Каждому пикселу присваивается цифровое значение, определяющее имя или атрибут объекта. Таким образом, элемент получает значение, соответствующее принадлежности или непринадлежности к определенному типу пространственных объектов. Растровая модель дает информацию о том, что расположено на территории, и чем больше размер ячейки (ниже разрешения растра), тем меньше точность изображения объектов, заключенных в нем (рис. 1).  Рис. 1. Растровая модель данных Для характеристики растровой модели используются следующие термины. Разрешение — способность измерительной системы обеспечивать различение деталей изображения, а также мера, используемая для оценки объекта как размера наименьшего из различаемых объектов. Обычно выражается в числе точек на дюйм (dpi — dots per inch). Площадная зона — набор соседствующих местоположений одинакового свойства. Термин класс (или район) часто используют в отношении всех самобытных зон, которые имеют одинаковые параметры. Главными компонентами зоны являются ее значение и местоположение. Значение — это единица информации, хранящаяся в теме (слое) для каждой точки или пикселя объекта. Ячейки одной зоны (или района) имеют одинаковое значение. Местоположение — это наименьшая единица картографического пространства, для которого могут быть определены какие-либо характеристики или свойства (пиксель, ячейка). Такая единица картографического плана однозначно идентифицируется упорядоченной парой координат — номерами строки и столбца. Растровые модели наиболее удобно использовать для выявления различных взаимосвязей между элементами сплошного распространения. Картографические проекции, в которых могут быть представлены растры, просты и точны, и любой отображаемый объект может быть описан с точностью до одной ячейки растра. Однако работа с растровыми моделями требует значительных машинных ресурсов, прежде всего компьютерной памяти, требуемой для хранения и обработки растра. 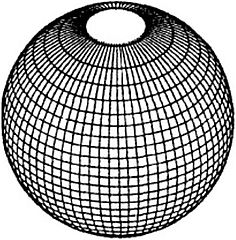 Рис. 2. Матричная (регулярно-ячеистая) модель данных на примере разделения сферы на равновеликие трапеции. В отличие от растровой модели модель матричная (регулярно-ячеистая) представляет собой цифровые фотоизображения, снятые непосредственно фотокамерой или полученные со сканера. Каждому из элементарных единиц такого изображения присваивается цветовое значение (рис. 2). Особенностью квадротомической модели является разбиение территории на вложенные друг в друга пикселы с образованием иерархической древовидной структуры, основанной на декомпозиции пространства на квадратные участки, каждый из которых делится на четыре вложенных до достижения некоторого уровня детальности представления (рис. 3). Векторная модель имеет объектную ориентацию. Конфигурация всех объектов задается координатами точек и соединяющих их векторов. Причем каждая группа объектов, характеризуемых одинаковыми свойствами, формирует отдельный слой. И любой географический объект может быть представлен набором графических примитивов: точек, линий, полигонов, выраженных соответствующими картографическими символами. Таким образом, векторная модель представляет собой коллаж графических объектов, физически присутствующих в изображении. Пространственные данные обычно хранятся в виде взаимосвязанных объектов, атрибутивная информация о которых позволяет составить целостную картину картографируемого пространства (рис. 4).  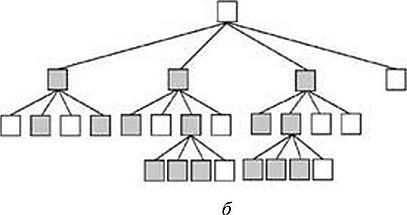 Рис. 3. Квадротомическая модель данных Дискретные объекты, каждый из которых может занимать в любой момент времени только одну определенную точку в пространстве, представляются в виде точек. Считается, что такие объекты не имеют пространственной протяженности и ширины (внемасштабные, 0-мерные пространственные объекты) и каждый из них может быть обозначен парой координат: X и У (широта и долгота). Примерами могут служить мысы, отдельно стоящие деревья, маяки, отметки высот и т. д. Совокупность точечных объектов образует точечный слой. Объекты, внемасштабные по ширине, но имеющие протяженность, отображаются в виде линий (1-мерный пространственный объект). Это могут быть дороги, линии электропередач, реки, тектонические разломы и другие. В ГИС они представлены последовательно стью пар координат. Сложные наборы линий называются сетями. Они содержат дополнительную информацию о пространственных взаимоотношениях этих линий. Например, линии, отражающие транспортные магистрали, могут содержать сведения об особенностях передвижения по ним (направления, скорость и т. д.), при этом информация присваивается каждому отрезку до изменения атрибутов. Точки, в которых отрезки связываются, называются узлами, также кодируются, каждый узел свидетельствует о смене ситуации. Все эти атрибуты определяются по всей сети без пропусков, что необходимо для обеспечения связанности и пространственных отношений. Совокупность линий образует линейный слой. Точка (х, у) 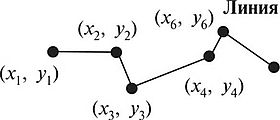 (*з> Уз) 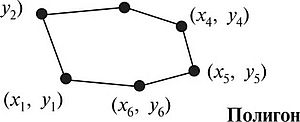 Рис. 4. Векторная модель данных Полигоны используются для тех объектов, которые на карте сохраняют свои очертания (имеют длину и ширину) (2-мерный пространственный объект). Отображаются в виде замкнутой последовательности пар координат, где начальная и конечная точки имеют одинаковое значение. Совокупность полигонов образует полигональный слой. Современные ГИС поддерживают одновременно множество моделей, однако векторные получили большую популярность, поскольку обеспечивают хорошую визуализацию картографируемых объектов, возможность детально представлять реальные объекты и более оперативную обработку информации в процессе анализа и геообработки. Инфологическая модель. Инфологическая модель строится на основе естественного понимания человеком окружающего мира и дает формальное описание предметной области и отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Основными конструктивными элементами инфологических моделей являются сущности (объекты), связи между ними и их свойства (атрибуты). Инфологическая модель носит описательный характер и включает в себя ряд компонентов (рис.5): 1)описание предметной области; 2)описание методов обработки; 3)описание информационных потребностей пользователей. 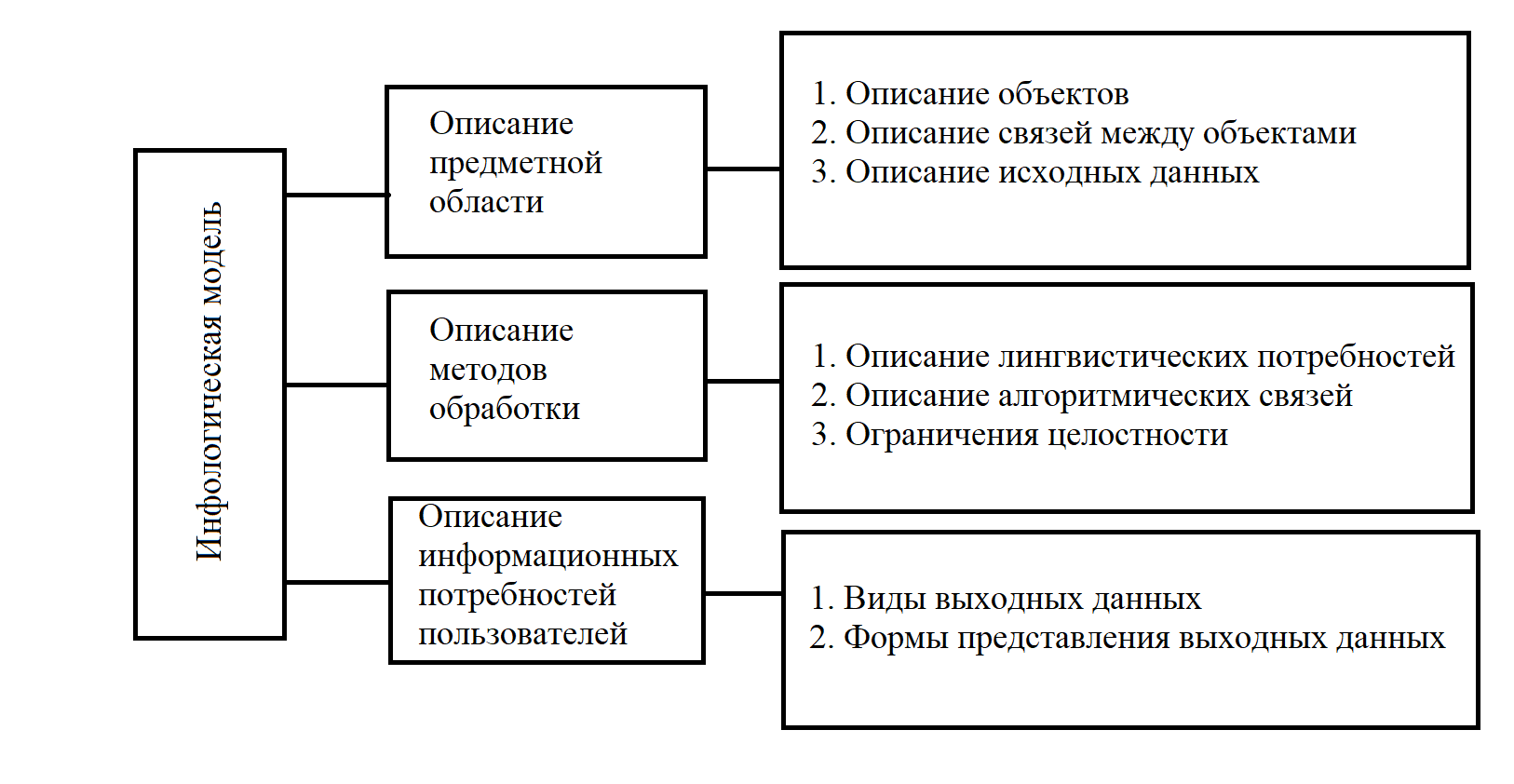 Рис.5 Основные компоненты инфологической модели Логические модели данных. Инфологическая модель должна быть отображена в компьютерноориентированную даталогическую модель, «понятную» СУБД. Наиболее близка к концептуальной модели, модель «Сущность-связь». Иерархическая модель. К наиболее простым структурно определенным относится иерархическая модель. В этой модели данных связи между ее частями являются жесткими, а ее структурная диаграмма должна быть упорядоченным деревом. Одно из важных понятий для этой модели - уровень. Для описания разных уровней применяют понятия: корень, ствол, ветви, листья и лес, что подчеркивает сходство структуры модели со структурой дерева. Граф иерархической модели (ее схемное представление) включает AM типа элементов: дуги и узлы (или записи). Дуги соединяют разные узлы между собой. Дуги, соответствующие функциональным связям, должны быть всегда направлены от корня в листья дерева, т.е. они являются ориентированным графом. Такая структурная схема называется иерархическим деревом определения или деревом определения. Дуга дерева определения, соответствующая функциональному типу связи, называется связью исходный - порожденный. Между двумя типами записей в иерархической модели может быть не более одной такой связи. Дуга исходит из типа родительской (порождающей) записи и заходит в тип дочерней (порожденной ) записи. В простейшем случае иерархическая модель представляет собой описание процесса или системы, состоящей из совокупности уровней, связанных одной дугой (рис. 6).  Рассматривая последовательность связей "исходный - порожденный", можно естественным образом идентифицировать типы родительской и порожденной записей. Первую порождающую запись называют корневой (реже стволом), промежуточные записи - ветвями, записи самого нижнего уровня иерархической модели - листьями. Понятия корневой, ствол, ветви, листья определяют тип записи в иерархической модели. Иерархический путь, или маршрутизация, - это последовательность типов записей, начинающаяся с типа корневой записи, в которой типы записей выступают переменно в ролях исходного и порожденного. Известная программистам последовательность "диск- корневой каталог - подкаталог - программа" - характерный пример иерархической модели. Уровень типа записи относительно типа корневой записи определяется как длина пути от корневой записи, выраженная в числе дуг. Так, тип корневой записи "диск" находится на нулевом уровне, ”корневой каталог” - на первом, ”подкаталог” - на втором, имя файла - на третьем и т.д. Расширение дерева определения иерархической модели может быть отражено в виде таблиц для записей, а расширение каждой связи "исходный - порожденный" - множеством соединений между таблицами. Альтернативным способом представления расширения дерева определения является "лес", или совокупность отдельных деревьев, состоящих из одной корневой записи и всех ее зависимых записей. Такое дерево называется деревом базы данных. Оно конструируется в соответствии с деревом определения. Иногда структуру иерархической модели называют Е-деревом (см. рис. 8). Иерархическим моделям данных присущи два внутренних ограничения. Первое ограничение - все типы связей должны быть функциональными, второе - структура связей должна быть древовидной. Следствием этих ограничений является необходимость соответствующей Структуризации данных. В силу функциональности связей запись может иметь не более одной исходной записи любого типа, т.е. связь должна иметь жесткий вид -1 : п (один ко многим). Очевидный недостаток иерархических моделей - снижение времени доступа при большом числе уровней, поэтому в ГИС не используют модели при большом числе уровней (более 10). В то же время иерархические модели довольно устойчиво применяются для составления различного рода классификаторов. Квадратомическая модель данных. Иерархическая структура данных, известная как квадратомическое дерево, используется для накопления и хранения географической информации. В этой структуре двухмерная геометрическая область рекурсивно подразделяется на квадраты, что определило название данной модели. На рис. 7 показан фрагмент двухмерной области QT, состоящей из 16 пикселей. Каждый пиксель обозначен цифрой. Вся область разбивается на четыре квадранта: А, В, С, D. Каждый из четырех квадрантов является узлом квадратомического дерева. Большой квадрант QT становится узлом более высокого иерархического уровня квадратомического дерева, а меньшие квадранты появляются на более низких уровнях. Технология построения квадратомического дерева основана на ре-курсивном разделении квадрата на квадранты и подквадранты до тех пор, пока все подквадранты не станут однородными по отношению к значению изображения (цвета) или пока не будет достигнут предопределенный заранее наименьший уровень разрешения. Если регион состоит из 2n х 2n пикселей, то он полностью представлен на уровне n, а единичные пиксели находятся на нулевом уровне. Квадрант уровня 1 (0<1 На рис. 8 показано квадратомическое дерево, построенное по данным рис. 7. Как видно, эта структура являет собой классический пример Е-дерева. Преимущество такой структуры состоит в том, что регулярное разделение обеспечивает накопление, восстановление иобработку данных простым и эффективным способом. Простота проистекает из геометрической регулярности разбиения, а эффективность достигается за счет хранения только узлов с данными, которые представляют интерес. 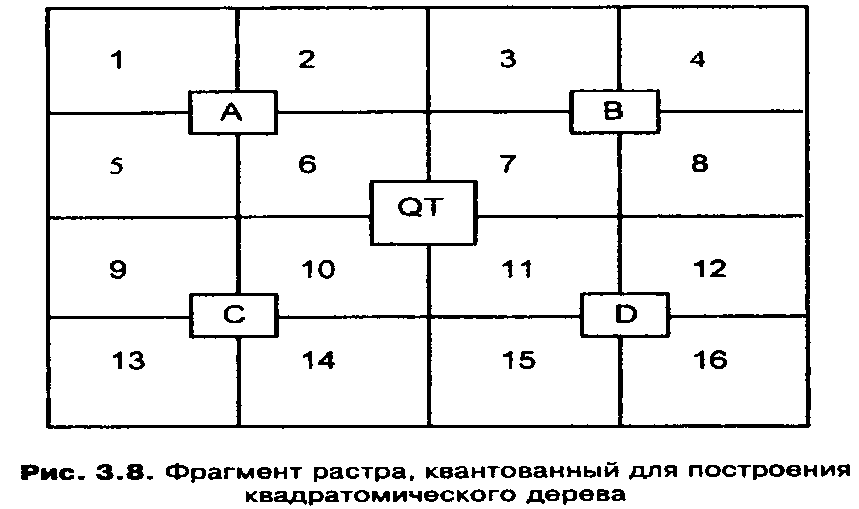 Рис. 7. Фрагмент растра, квантованный для построения квадратомического дерева. 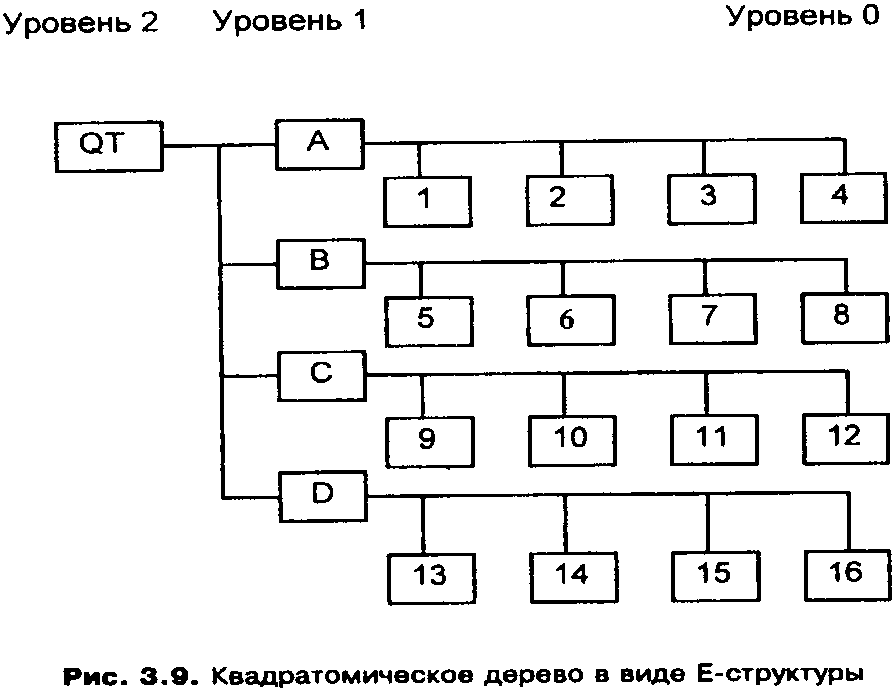 Рис. 8. Квадратомическое дерево в виде Е-структуры. Поскольку квадратомическое дерево известно как пространственно-рациональный способ представления сгруппированных однородных ми сопряженных изображений, их преимущество над векторной репрезентацией многих (но не всех) пространственных алгоритмов относительно затрат машинного времени весьма существенно. Первоначально большинство приложений моделей квадратомических деревьев было сделано для обработки изображений. Из этой области данная модель была перенесена в ГИС. Модели, основанные на квадратомических деревьях, обеспечивают расчеты площадей, центроидные определения, распознавание образов, выявление связанных компонентов, определение соседства, преобразование расстояний, разделение изображений, сглаживание данных и усиление краевых эффектов. Вследствие этого появилась возможность использовать квадратомические деревья для хранения географических данных. Однако при этом требуется развитие процедур для превращения растровых данных в формат квадратомического дерева и усовершенствование техники линейного кодирования. В первых работах по квадратомическим деревьям связи между квадрантом и подквадрантом давались в виде дерева со степенью ветвления, равной четырем. В такой структуре связи между родительским и дочерним уровнем определяются системой внешних указателей. Все узловые точки дерева, за исключением корневой, имеют одного родителя. В то же время все они, за исключением листьев, связаны с четырьмя дочерними узловыми точками. Преимущество представления, основанного на указателях, заключается в том, что оно выражает только значимую часть полного квадратомического дерева. Последние исследования показали, что для больших квадратомических деревьев наиболее подходящей структурой является линейное квадродерево. В нем каждый листовой узел представлен линейным числовым кодом, который базируется на упорядоченном списке узловых точек прародителей. Последующее преобразование дерева в код достигается использованием битового уровня или модулярной арифметики. Система линейных кодов обеспечивает эффективную связь между структурами пространственных данных и алгоритмами, применяемыми в вычислительной геометрии для решения проблем восстановления прямоугольников и определения ближайшего "соседа". Рядом исследователей была рассмотрена возможность использования искусственного интеллекта для совершенствования очень больших географических информационных систем, основанных на квадратомических деревьях. Иерархические модели, как и прочие, могут описывать системы, данные и схемы процессов обработки данных. Следует, однако, подчеркнуть, что правильно составленная иерархическая схема должна содержать в качестве записей ( вершин) атрибуты или агрегаты атрибутов либо типы сущностей. Атрибуты или агрегаты атрибутов соответствуют множествам или расширенным множествам. Дуги могут использоваться для представления агрегации двух атрибутов в тип сущности или двух типов сущности в тип связи. На практике часто в запись вставляют не только сущности базы данных, но и связи. Такая схема описывается моделью "сущность-связь" и будет рассмотрена ниже. Анализ иерархических моделей (связей между их частями) с "неправильным" описанием необходимо проводить, выделяя типы сущностей. Реляционная модель данных. В современных информационных системах и базах данных наиболее широко представлены реляционные модели (РМ). Реляционная модель данных, разработанная Коддом еще в 1969-1970 гг. на основе математической теории отношений, опирается на систему понятий, важнейшие из которых - таблица, отношение, строка, столбец, первичный ключ, внешний ключ, домен (domain). Доменом называется совокупность значений, не повторяющихся в одном столбце. Такая модель положена в основу так называемых электронных таблиц специализированных баз данных. Сущности, атрибуты и связи хранятся в таблицах как данные определенной структуры. Структура данных обусловливается используемыми моделями данных. Таблица состоит из строк и столбцов и имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка - конкретный объект. Основным средством структурирования данных в реляционной модели является отношение (relation). Понятия отношения в реляционной модели и математике близки, хотя и не совпадают. Можно определить отношение как декартово произведение доменов. Поясним связь перечисленных выше понятий между собой. Таблица имеет столбцы и записи (строки). Каждая запись имеет набор атрибутов. Записи каждого типа образуют таблицу или отношение. Каждая строка - это запись или кортеж. Каждый столбец - это атрибут. Диапазон допустимых значений (домен) определяется для каждого атрибута. Степень отношения - число атрибутов в таблице: один атрибут - унарное отношение, два атрибута - бинарное отношение, n атрибутов — n-арное отношение. Ключ отношения - это подмножество атрибутов, имеющее следующие свойства: уникальную идентификацию; неизбыточность; ни один из атрибутов ключа нельзя удалить, не нарушив его уникальности. Первичный атрибут отношения - это атрибут, присутствующий по крайней мере в одном ключе, все другие атрибуты непервичные. В реляционной модели данных схема отношения может быть использована для представления типа сущности. Реляционная модель является табличной моделью, некоторые типы связей между отношениями могут представляться в схеме неявно. В этих моделях не предусматривается поддержание логической упорядоченности, однако кортежи помещаются в физическую память в соответствии с некоторым порядком. Физическая упорядоченность используется для выборки. Рассмотренная выше иерархическая модель данных может быть сведена к реляционной с помощью "нормализации" - пошагового процесса приведения к табличной форме с полным сохранением информации. Рассмотрим пример реляционной модели. Таблица "Сотрудник" (рис. 9, а) содержит сведения о сотрудниках, работающих в организации, а ее строки являются наборами значений атрибутов. Каждый столбец таблицы - это совокупность значений конкретного атрибута объекта. Например, столбец "Специальность" содержит множество значений специальностей, столбец "Стаж" - целые неотрицательные числа.
а – «Сотрудник»
б – «Отдел» Рис. 9. Реляционная модель: а - "Сотрудник" ; б - "Отдел" Значения в столбце "Специальность" выбираются из множества имен всех возможных специальностей данной организации. В нем принципиально невозможно появление значения, которого нет в соответствующем домене, например "15" или "с.н.с". Каждый столбец имеет имя, которое обычно записывается в верхней части таблицы. Оно должно быть уникальным в таблице, однако различные таблицы могут иметь столбцы с одинаковыми именами. Любая таблица должна иметь по крайней мере один столбец. Столбцы расположены в таблице в соответствии с порядком следования их имен при се создании. В отличие от столбцов строки не имеют имен, порядок их следования в таблице не определен, а количество логически не ограничено. Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции - среди них не существует "первой", "второй", "последней". Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключам (primary key). В таблице "Сотрудник" первичный ключ - это столбец "код". В нашем примере каждый сотрудник имеет единственный номер (код), по которому из таблицы извлекается необходимая информация. Следовательно, в этой таблице первичный ключ - это столбец "код". В нем значения не могут дублироваться - в таблице "Сотрудник" не должно быть строк, имеющих одно и то же значение в столбце "код". Взаимосвязь таблиц - важнейший элемент реляционной модели данных. Она поддерживается внешними ключами (foreign key). Рассмотрим пример, в котором база данных хранит информацию о сотрудниках (таблица "Сотрудник") и отделах (таблица "Отдел") в некоторой организации. Первичный ключ таблицы "Отдел" (рис. 3.10,6)-столбец "Название отдела". Столбец "Численность" не может выполнять роль первичного ключа, так как в одной организации могут существовать несколько отделов с одинаковой численностью. Любой сотрудник работает в одном отделе, что должно быть отражено в базе данных. Таблица "Сотрудник" содержит столбец "Название отдела" и значения в этом столбце выбираются из столбца "Название отдела" таблицы "Отдел". Столбец "Название отдела" является внешним ключом в таблице "Сотрудник". Для обработки данных, размещенных в таблицах, нужны дополнительные данные о данных, например описатели таблиц, столбцов и т.д. Их называют обычно метаданными. Метаданные также представлены в табличной форме и хранятся в словаре данных (data dictionary). Помимо таблиц в ГИС могут храниться и другие объекты, такие, как экранные формы, отчеты (reports), представления (views) и даже прикладные программы, работающие с информацией, размещенной в реляционной модели. Данные информационной системы должны быть однозначными и непротиворечивыми. В таком случае говорят, что реляционная модель удовлетворяет условию целостности (integrity). При этом на реляционную модель накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints). Существует несколько типов ограничений целостности. Например, требуется, чтобы значения в столбце таблицы выбирались только из соответствующего домена. На практике учитывают и более сложные ограничения целостности, в частности, целостность по ссылкам (reference integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице. Модель "сущность-связь" Модель данных "сущность-связь" или ER-модель (Entity Relationship Model) дает представление о предметной области в виде объектов, называемых сущностями, между которыми фиксируются связи. Для каждой связи определено число связываемых ею объектов. На схеме сущности изображаются прямоугольниками, связи - ромбами. Число связываемых объектов указывается цифрой на линии соединения объекта и связи. Появление моделей данных типа "сущность-связь" было обусловлено практическими потребностями проектирования баз данных для коммерческих СУБД. Такие модели имеют много общего с иерархическими и сетевыми моделями данных. Теоретической основой этого подхода является известная модель, введенная М. Ченом в 1976 г. и получившая широкое распространение в качестве средств концептуального проектирования баз данных. В основе модели Чена лежит представление о том, что предметная область состоит из отдельных объектов, находящихся друг с другом в определенных связях. Объекты описываются различными параметрами или атрибутами; однотипные объекты описываются одним и тем же набором параметров и объединяются во множества или классы (сущности). Конкретные объекты, составляющие класс, называют экземплярами соответствующей сущности. Между сущностями идентифицируются взаимосвязи различного вида: один к одному, один ко многим и др. На рис. 10 приведена схема проектирования геоинформационной системы, построенная на основе модели "сущность-связь". В силу своей ориентации на процесс проектирования ER-модели могут рассматриваться как обобщение и развитие иерархических и сетевых моделей. Это, в частности, означает, что допускаются явная спецификация ограничений целостности и непосредственное представление связей типа "один к одному" (1:1), "один ко многим" (1: М) , "многие к одному" (М : 1) "многие ко многим" (М : N). 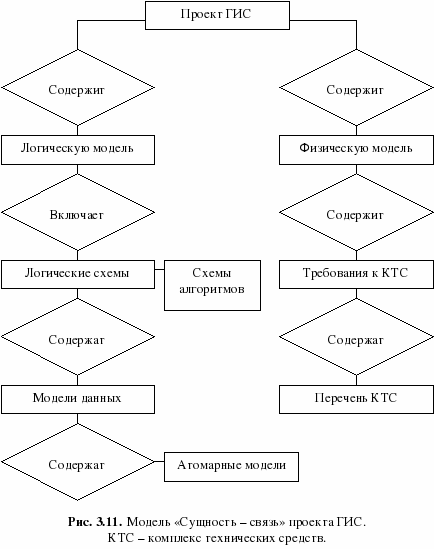 Рис. 10. Модель «Сущность – связь» проекта ГИС. КТС – комплекс технологических средств При построении ER-моделей важно учитывать разновидность объектов. Прежде всего это простые и сложные объекты. Объект модели рассматривается как простой, если он имеет свойства атомарного объекта или модели. Сложными называют объекты, которые могут быть представлены в виде совокупности более простых объектов. На схеме это соответствует тому, что блок, отображающий такой объект, может быть заменен несколькими взаимосвязанными подблоками, определяющими другие объекты или наборы данных. Такое разделение условно, так как в одних случаях объект может считаться простым, в других - сложным. Сложные объекты подразделяют на составные, обобщенные и агрегированные. Составной объект структурирован на основе связей "целое-часть". Он строится аналогично классификации. Обобщенный объект построен на основе обобщения, т.е. на основе связей "тип-тип", "род-вид" и т.д. Выделение родовых-видовых связей позволяет осуществлять классификацию, т.е. выделение классов и подклассов, с использованием признаков и свойств объектов. Агрегированным объектом, строго говоря, следует считать объект, спроектированный (смоделированный) на основе агрегации. Однако в разных приложениях допускают введение дополнительных условий. В частности, агрегированными обозначают объекты, участвующие в каком-либо процессе. Это соответствует описанию динамических свойств, и такие агрегированные объекты называют "отглагольными существительными", например, поставлять - "поставка", производить - "производство" и т.п. Большинство ограничений в ER-моделях относится к классу явных. Однако в них существует ограничение для случая, когда сущность может быть идентифицирована по связям, а не по значениям своих атрибутов. Такое ограничение называется зависимостью по идентификации и обозначается как ID-зависимость. Сетевые, семантические и бинарные модели. Сетевые модели. Сетевые модели дают представление о проблемной области в виде объектов, связанных бинарными отношениями "многие ко многим". В отличие от иерархических моделей в сетевой модели каждый объект может иметь несколько "подчиненных" и несколько "старших" объектов. Сетевые модели используют табличные и значительно чаще графовые представления. Вершинам графа сопоставляют некоторые типы сущности, представляемые таблицами, а дугам - типы связей. Многие типы сетевых моделей данных используют для описания экономических и организационных систем. Наиболее развитой сетевой моделью данных является модель, разработанная Рабочей группой по базам данных Ассоциации по языкам систем обработки данных КОДАСИЛ. Ее спецификации впоследствии неоднократно пересматривались. Дискуссия по поводу сравнительных достоинств реляционной и сетевой моделей данных окончательно не закончилась. Пока признано, что нет модели, наилучшей в любых условиях, и что различным задачам адекватны различные модели. 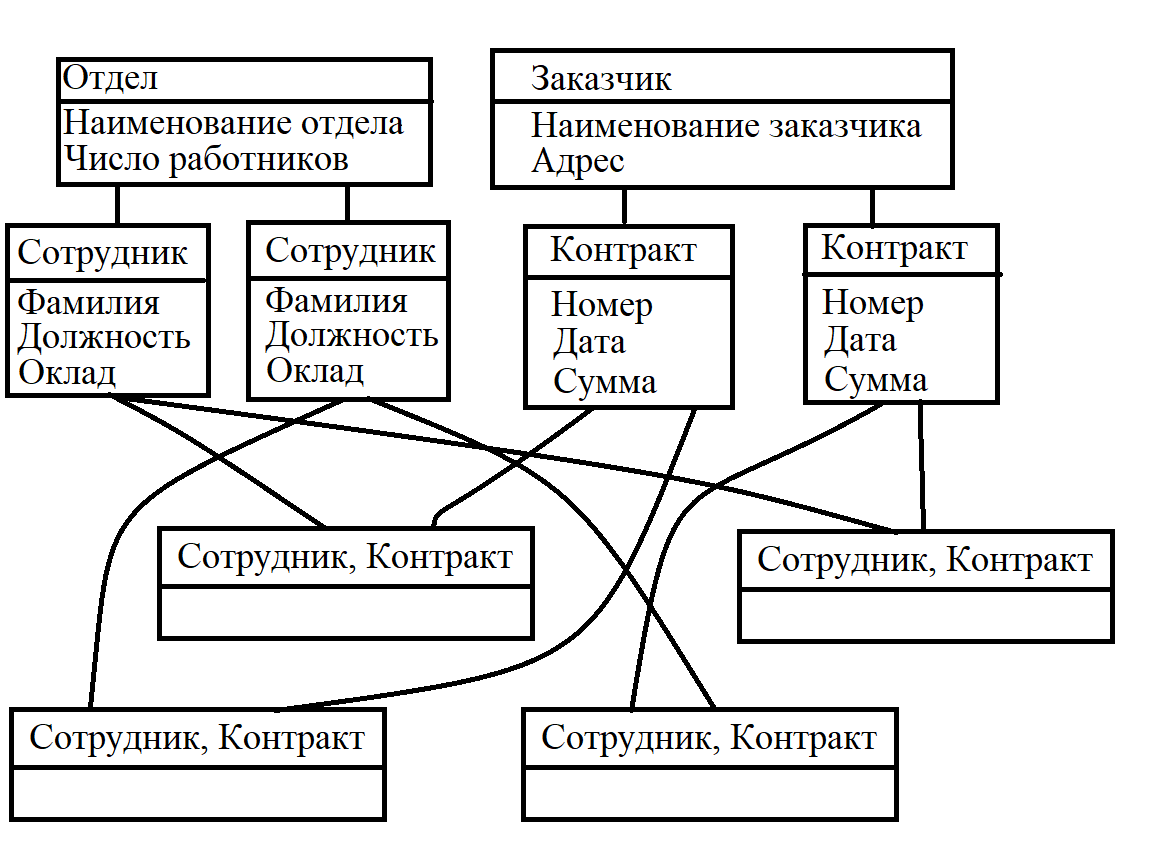 Рис. 11. Пример сетевой модели. Бинарная модель. Дает представление о предметной области в виде бинарных отношений, характеризуемых триадами «объект, атрибут, значение атрибута». Графическое представление такой модели называется В-деревом (в отличие от Е-дерева). Особенности организации данных в ГИС. ГИС как системы обработки пространственно-временной информации относятся к классу информационных систем. Они имеют общие, присущие всему классу, и индивидуальные, присущие только ГИС, свойства. К особенностям ГИС следует отнести наличие больших объемов хранимой в них информации. Кроме того, они отличаются специфичностью организации и структурирования моделей данных. ГИС характеризуются разнообразием графических данных со специфическими их частями и связями. В частности, карта может быть рассмотрена как двухмерная аналоговая модель, отображающая трехмерную поверхность. Используя процедуры абстракции, определим более общую модель геоинформационных данных как абстракцию данных, которые содержатся на земной поверхности. Такой подход требует выделения основных типов данных и их многочисленных связей. В качестве основного критерия анализа взаимосвязи частей и построения базовых моделей данных использовалась структура. Этот же подход приемлем для построения моделей геоинформационных данных. Напомним, что одной из основных моделей в первых ГИС был набор имен и характеристик в сочетании со множеством именованных данных, местонахождение которых задается координатами. Эта простая модель не содержала каких-либо семантических данных, помогающих пользователю при работе с базами данных. Дальнейшие исследования привели к необходимости развития и усложнения такой модели. Другими словами, возникла потребность создания общей модели данных ГИС и ее основных частей для оптимальной обработки в базах данных и эффективного описания объектов. Данные реального мира, отображаемые в ГИС, можно рассматривать с учетом трех аспектов: пространственного, временного и тематического. Пространственный аспект связан с определением местоположения, временной - с изменениями объекта или процесса с течением времени, в частности от одного временного среза до другого. Примером временных данных служат результаты переписи населения. Тематический аспект обусловлен выделением одних признаков объекта и исключением из рассмотрения других. Все измеримые параметры моделей геоинформационных данных подпадают под одну из этих характеристик: место, время, предмет. Затруднительно исчерпывающим образом описать сразу все три эти характеристики. Поэтому при построении моделей данных на основе наблюдений явлений реального мира один параметр считают "неизменным", изменения другого "задаются" и при этом "измеряют" изменения третьего параметра. Зафиксировав географическое положение и изменяя время, можно получить временные ряды данных. Зафиксировав время и изменяя географическое положение, получаем данные по профилям. В большинстве технологий ГИС для определения места используют один класс данных - координаты, для определения параметров времени и тематической направленности - другой класс данных -атрибуты. Однако прежде чем рассмотреть два основных класса данных в ГИС, необходимо рассмотреть методы определения местоположения точек объектов на поверхности Земли. Список используемых источников Берлянт А.М. Картография: Учебник для вузов. – М.: Аспект Пресс, 2001. – 336 с. Введение в ГИС. Учебное пособие/Коновалова Н.П., Кондратов Е.Г. — Петрозаводск: 2003. - 148 с. Интернет ресурс: [https://studfile.net/preview/3190827/page:10/], дата обращения 10.08.2022. Интернет ресурс: [http://rudocs.exdat.com/docs/index-35582.html?page=8], дата обращения 10.08.2022. Интернет ресурс: [https://studfile.net/preview/9269541/page:19/], дата обращения 11.08.2022. Интернет ресурс: [https://studref.com/316408/geografiya/modeli_dannyh], дата обращения 11.08.2022. |