Информационно-аналитические системы. Цель и задачи дисциплины. Целью
 Скачать 1.22 Mb. Скачать 1.22 Mb.
|

|
Тема 6. Интеллектуальный анализ данных (Data mining) Цель: cформировать представление об интеллектуальном анализе данных на предприятии. Задачи: · Изучить задачи интеллектуального анализа данных. · Ознакомиться со сферами применения интеллектуального анализа данных. · Освоить технологию проведения интеллектуального анализа данных. · Изучить программные средства интеллектуального анализа данных. Вопросы темы: 1. Назначение интеллектуального анализ данных и примеры его применение в бизнесе. 2. Технологические этапы проведения интеллектуального анализа данных. 3. Методы интеллектуального анализа данных. 4. Программные средства интеллектуального анализа данных. 5. Интеграция оперативного и интеллектуального анализа данных. Основные понятия: · Knowledge Discovery in Databases; · Data Mining; · интеллектуальный анализ данных; · ассоциация; · последовательность; · классификация; · кластеризация; · прогнозирование; · нейронные сети; · генетические алгоритмы; · дерево решений; · эволюционное моделирование. Вопрос 1. Назначение интеллектуального анализ данных и примеры его применение в бизнесе. Понятие «интеллектуальный анализ данных» (ИАД) соответствует англоязычному «Knowledge Discovery in Databases» (KDD), что буквально означает «обнаружение знаний в базах данных». Очень часто эти два понятия приравнивают к более популярному термину «Data Mining» (DM). Последнее принято переводить как «добыча (или раскопка) данных». Ряд авторов предлагают рассматривать эти три понятия как синонимы. Data Mining – это процесс обнаружения в «сырых» данных ранее неизвестных нетривиальных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности». Более кратко это можно сформулировать как «технологию выявления скрытых взаимосвязей внутри больших баз данных. В основе методов технологии data mining лежит «концепция шаблонов» (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. На основе подвыборок исходных данных выявляются закономерности (шаблоны), которые формулируются в понятной обычному человеку форме. Особенностью data mining является «нетривиальность разыскиваемых шаблонов». Под этим понимается то, что с помощью методов data mining должны выявляться неочевидные, неожиданные (unexpected) регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge). Связано это с идеей о том, что в сырых данных о конкретных фактах из деятельности компании при грамотной раскопке можно обнаружить некоторый глубинный пласт знаний (рис. 26). 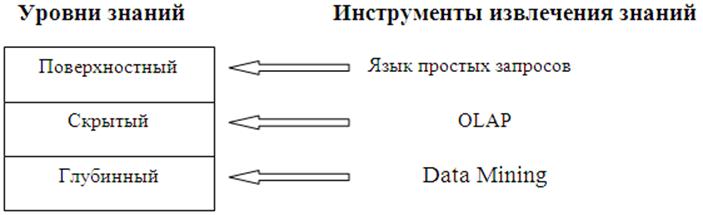 Рис. 26. Уровни знаний, извлекаемых из данных Выделяют пять стандартных типов закономерностей, которые можно выявить с помощью методов data mining: 1. Ассоциация означает, что несколько событий связаны друг с другом, т.е. определяется наличие высокой вероятности связи между событиями. 2. Последовательность означает существование цепочки событий, связанных между собой во времени. 3.Классификация помогает выявить признаки, характеризующие группу, к которой принадлежит тот или иной объект. 4. Кластеризация позволяет в отличие от классификации выделять различные однородные группы данных, когда классификационные группы заранее не известны (они выявляются автоматически в процессе обработки данных). 5.Прогнозирование позволяет находить в исторической информации, представленной в виде временных рядов, такие шаблоны, которые отражают динамику поведения целевых показателей. Информационные системы, реализующие методы data mining, в последние годыстановятся все более и более популярны как инструменты для проведения анализа экономической информации. Это становится особенно актуальным в случаях, когда из имеющихся больших объемов ретроспективных данных можно извлечь знания для принятия управленческих решений в условиях неопределенности. По сути, сфера применения ИАД не имеет ограничений. Методы data mining можно использовать в любой сфере, подразумевающей наличие каких-либо объемных массивов данных. Применение методов data mining имеет смысл, когда в компании накоплено очень большое количество данных. При этом крайне желательно, чтобы эти данные находились в грамотно спроектированном хранилище данных (DataWarehousing). В таблице 3 представлены наиболее популярные примеры практического применения методов data mining в бизнесе. Таблица 3. Примеры практических применений методов data mining в бизнесе
Вопрос 2. Технологические этапы проведения интеллектуального анализа данных. Процедура выполнения ИАД не зависит от предметной области и может считаться универсальной. Эта процедура выражается в определенной последовательности действий, которые требуется выполнить пользователю, чтобы извлечь из сырых данных значимую информацию (т.е. знания). При этом не имеет значения, какие именно методы будут применяться для обработки данных и получения результата. Процесс ИАД можно разбить на пять этапов (рис. 27). 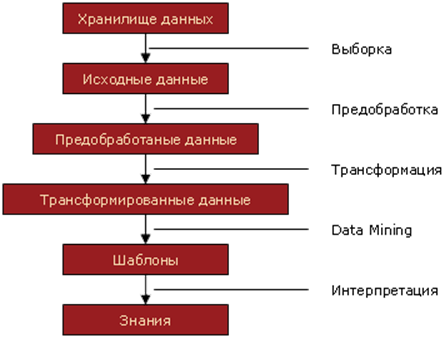 Рис. 27. Этапы процесса ИАД 1. Подготовка исходного набора данных. На этом этапе необходимо собрать исходные данные (в том числе из разных источников) и сформировать из них выборку, на основе которой будет происходить применение какого-либо метода data mining. Объем этой выборки зависит от того метода, который планируется применять для получения нужного результата. Эту выборку из данных также называют «обучающей». Однако следует учесть, что помимо обучающей выборки, т.е. по которой строится модель, потребуется еще и выборка «тестовая», чтобы проверить качество полученной модели. Сбор данных из разных источников – задача непростая, она требует наличия программных средств доступа к различным источникам данных. Эта задача существенно упрощается при наличии в компании централизованного хранилища данных (data warehouse). 2. Предобработка данных. Собранные на первом этапе данные являются «сырыми» и нуждаются в специальной обработке прежде, чем к ним будут применены какие-либо методы. Связано это с тем, что в данных могут оказаться пропуски значений, аномальные значения, ошибочно введенные значения и т.д. В некоторых случаях исходные данные следует дополнить какими-либо показателями. При подготовке данных следует учитывать требования конкретного метода, с помощью которого будет проходить их обработка. 3. Трансформация, нормализация данных. На этом этапе отобранные ранее данные нужно привести к виду, пригодному для последующего анализа. Содержание этого этапа зависит от применяемого метода анализа. Так, например, метод нейронных сетей требует, чтобы все данные были числовыми и нормализованными. Для выполнения трансформации данных существуют такие алгоритмы, как приведение типов, квантование, приведение к «скользящему окну» и др. 4. Data Mining. На этом этапе происходит применение метода анализа к исходным данным и получение «знаний» в виде некоторой модели. Этот этап является ключевым в процедуре ИАД. 5. Постобработка данных. На этом этапе выполняется интерпретация результатов, полученных на предыдущем этапе, и разработка механизмов применения результатов в бизнесе (например, разработка программных приложений). Вопрос 3. Методы интеллектуального анализа данных. Рассмотрим теперь методы анализа, которые могут применяться на этапе «data mining». Специалисты компании BaseGroup подразделяют методы ИАД на три группы (рис. 28): 1) методы математической статистики; 2) методы эволюционного моделирования; 3) методы машинного обучения. 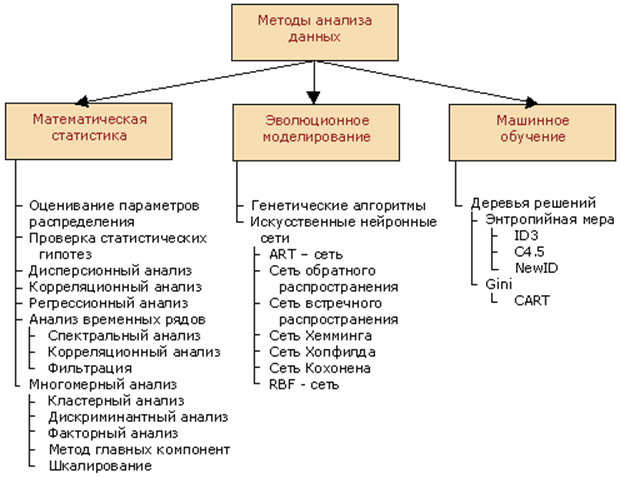 Рис. 28. Классификация методов ИАД Методы математической статистки уже долгое время успешно применяются в различных сферах человеческой деятельности, позволяя при этом получать оптимальные решения задач анализа данных в условиях случайных и непредсказуемых воздействий на исследуемый объект. Наиболее популярные из этих методов: регрессионный, дисперсионный и корреляционный анализ. Под методамиэволюционного моделированиясегодня подразумевают искусственные нейронные сети и генетические алгоритмы. Нейронные сети работают по аналогии с нервной системой живых существ: в зависимости от набора исходных сигналов на входных рецепторах нейроны формируют некоторый результирующий сигнал. Нейронная сеть подвергается обучению, в результате которого происходит запоминание эмпирической зависимости между значениями входных факторов и результирующим. Значения входных факторов играют роль исходных сигналов, а для получения результата в нейронной сети в процессе обучения происходит выработка определенных связей (весов) между отдельными нейронами. Для этого при обучении необходима выборка данных большого объема, содержащая как исходные данные, так и правильные ответы результирующего показателя. В основе генетических алгоритмов лежат принципы генетической эволюции, т.е. если особь определенного вида обладает в высокой мере каким-то свойством приспособленности, то велика вероятность, что у потомков этой особи данное свойство приспособленности закрепится и проявится еще сильнее. При помощи методов эволюционного моделирования решают такие аналитические задачи, как классификация и кластеризация объектов, прогнозирование, управление динамическими объектами. По сравнению с методами математической статистики нейронные сети способны выполнить указанные задачи даже в том случае, когда формализовать исходную задачу сложно. Методы машинного обучения основаны на алгоритмах построения «деревьев решений» и зарекомендовали себя при выполнении несложных классифицирующих задачах. При этом результаты выполненной ими классификации представляют собой набор выражений, доступных для понимания человеком. Дерево решений представляет собой иерархическую структуру, в которой переход с одного уровня на другой основан на ответе на некоторый вопрос (обычно это логический вопрос, подразумевающий ответ «да» или «нет»). По сравнению с методами нейронных сетей деревья решений строятся заметно быстрее. В отличие от методов математической статистики, которые применимы только для числовых данных, деревья решений позволяют анализировать как числовые, так и символьные данные. Вопрос 4. Программные средства интеллектуального анализа данных. Программные средства ИАД условно можно разделить на два вида: 1. Универсальные системы ИАД – программные средства, которые поддерживают практически всю процедуру ИАД и автоматизируют большой набор методов анализа данных. 2. Специализированные – средства, созданные для применения в узкой предметной области или поддерживающие только определенный метод или набор методов анализа. Универсальные программные средства.На рынке универсальных программных средств ИАД представлены следующие зарубежные разработки: · IBM SPPS Modeler. · SAS Interprise Miner. · Qlik Analytics Platform. · Knowledge Studio (Angoss Software). · Oracle Advanced Analytics. Конкуренцию им составляют такие российские разработки, как: · PolyAnalyst (Megaputer Intelligence). · Deductor (BaseGroup Labs). · Prognoz Platform (Прогноз). Практически все эти продукты имеют удобный графический интерфейс, широкие возможности в визуализации и манипулировании с данными, а также организуют доступ к различным источникам данных. Однако стоимость таких систем довольно высока и требует от покупателя серьезных работ по интеграции их в существующую корпоративную информационную систему. Специализированные программные средства. Среди специализированных программных средств ИАД выделяют различные классы: · предметно-ориентированные аналитические системы; · статистические пакеты; · нейросетевые пакеты; · деревья решений; · системы рассуждений на основе аналогичных случаев; · генетические алгоритмы; · алгоритмы ограниченного перебора; · системы для визуализации многомерных данных. Как правило, стоимость таких специализированных систем заметно меньше по сравнению с универсальными. Предметно-ориентированные аналитические системы решают узкий класс специализированных задач. Они не требует от пользователя каких-либо серьезных настроек после установки и практически сразу же готовы к использованию. Эти системы, как правило, реализуют несложные статистические методы, но при этом максимально учитывают специфику своей предметной области. Популярным примером таких систем могут служить программные средства «технического анализа» исследования фондовых рынков или средства анализа финансового состояния предприятия. Статистические пакеты изначально не позиционировались разработчиками как средства для проведения ИАД: это мощные математические системы, предназначенные для статистической обработки данных любой природы. Они включают многочисленные инструменты статистического анализа, имеют развитые графические средства. Однако сейчас почти все серьезные статистические пакеты помимо обычных функций реализуют еще и некоторые методы data mining. Ограничением широкого распространения этих систем является их немалая цена, а также необходимость пользователям обладать глубокими знаниями в области статистики (иначе они не смогут эффективно проводить анализ данных). Примеры статистических систем: SAS/STAT (SAS), SPSS (SAP), Statgraphics Centurion 18 (StatPoint, Inc). Нейросетевые пакеты – это класс разнообразных программных средств, реализующих алгоритм построения нейронных сетей, т.е. иерархических сетевых структур, в узлах которых находятся так называемые нейроны. Как уже отмечалось при описании метода нейронных сетей, для создания такой сети ее необходимо «обучить» на примере большого объема обучающей выборки из исходных данных. При этом сети демонстрируют очень хорошие результаты при прогнозировании и классифицировании, однако невозможно интерпретировать полученные с ее помощью результаты. Поскольку тренированная нейронная сеть представляет собой «умный черный ящик», работу которого невозможно понять и контролировать. Примеры нейронносетевых пакетов: · BrainMaker (CSS). · NeuroShell (Ward Systems Group). · OWL (Hyperlogic). · Statistica Neural Networks (StatSoft). Программные средства, реализующие методы деревьев решений (decision trees), представляют собой специализированные продукты для решения только задач классификации. Примерами таких систем являются: · See5/С5.0 (RuleQuest). · SIPINA (University of Lyon). · IDIS (Information Discovery). · KnowledgeSeeker (Angoss). Системы рассуждений на основе аналогичных случаев (case based reasoning, CBR) так же, как и предыдущий класс, реализуют только один метод, который еще называют методом «ближайшего соседа» (nearest neighbour). У этого метода есть свои недостатки, однако в ряде задач он способен выдавать неплохие результаты. Примеры таких систем: · KATE tools (Acknosoft). · Pattern Recognition Workbench (Unica). Другими примерами систем, реализующим только одну группу методов анализа, можно назвать системы генетических алгоритмов (программный продукт GeneHunter компании Ward Systems Group) и системы алгоритмов ограниченного перебора (система WizWhy от компании WizSoft). Отдельный класс специализированных средств ИАД представляют собой системы для визуализации многомерных данных. Несмотря на то, что средствами графического отображения данных оснащены сегодня почти все продукты ИАД, на рынке присутствуют продукты, специализирующиеся только на этой функции, например, DataMiner от разработчика Skyline Communications. Системы визуализации предлагают пользователю дружелюбный пользовательский интерфейс, с помощью которого можно ассоциировать анализируемые показатели с такими параметрами диаграмм, как цвет, форма, ориентация относительно осей, размеры и другие свойства графических элементов изображения. Вопрос 5. Интеграция оперативного и интеллектуального анализа данных. Технологии ИАД тесно связаны с технологиями построения хранилищ данных (Data Warehouse), а также с технологиями оперативной аналитической обработки (OLAP). По своей сути и OLAP, и ИАД являются составными частями процесса поддержки принятия решений. На сегодняшний день большинство программных OLAP-средств акцентированы в основном на обеспечение доступа к многомерным данным (кубам), в то время как средства ИАД для поиска закономерностей оперируют одномерными массивами данных. Чтобы объединить эти два вида анализа, нужно сфокусировать OLAP-средства не только на способах доступа к данным, но и на выявлении закономерностей в них. Перспективным направлением интеграции OLAP и ИАД считается объединение этих технологий в рамках корпоративной информационной системы на основе единого хранилища данных. На рис. 29 изображен подход к подобной интеграции OLAP и ИАД. 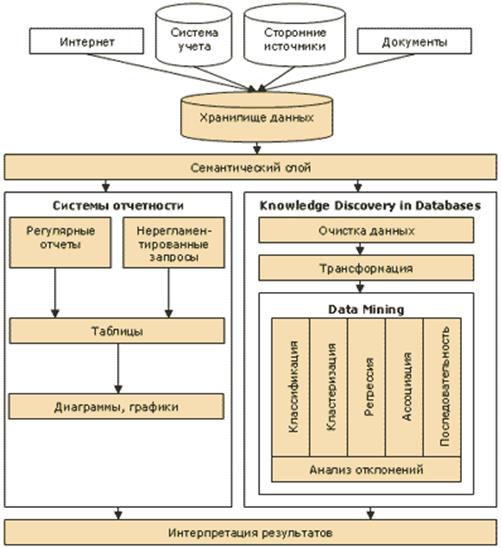 Рис. 29. Схема интеграции OLAP и ИАД в корпоративной информационной системе В идеальном случае корпоративная система должна содержать в себе одновременно и средства отчетности, и средства ИАД. В этом случае такая информационная система покроет практически все потребности бизнес-пользователей в проведении анализа данных. Рассмотрим подробнее элементы схемы интеграции OLAP и ИАД, представленной на рис. 29. Источником исходным данных для любого вида анализа выступают различные учетные базы данных организации, документы. В качестве дополнительного источника можно использовать данные, публикуемые в сети Интернет. Для решения стратегических задач управления организацией важно иметь не только внутреннюю информацию, но и внешнюю (например, макроэкономические показатели, демографические данные, сведения о конкурентной среде и т.п.). Базой для построения аналитической системы является хранилище данных, которое само по себе никаких функций анализа не реализует. Исходные данные собираются из различных источников (как внутри, так и вне организации) и загружаются в хранилище. Семантический слой обеспечивает лицо, принимающее решение (ЛПР) «понятным» ему механизмом доступа к данным, т.к. он трансформирует термины экономической предметной области в процедуры вызова запросов к БД. Таким образом, ЛПР может запрашивать необходимые ему данные на почти естественном для него языке. Назначение систем отчетности – обеспечить ЛПР ответом на вопрос «что происходит». Самый очевидный способ реализации этого – формирование регулярных отчетов для контроля текущий ситуации и выявления отклонений от нормы. Обычно элементы такого вида анализа реализованы в каждой организации. Системы отчетности в таком случае значительно ускоряют процесс получения отчета, но как единственный механизм анализа в организации этот подход недостаточен. Другим способом использования систем отчетности является обработка нерегламентированных запросов пользователя. Периодически перед ЛПР возникает необходимость проверить правильность какой-либо идеи (гипотезы), но для этого ему необходимо иметь фактические данные, подтверждающие или опровергающие его идею. Поскольку такие идеи-гипотезы могут возникать неожиданно, и ЛПР заранее не знает, какого рода фактическая информация ему понадобится, то реализовать все возможные запросы к данным в системах регулярных отчетов невозможно. Поэтому необходимо обеспечить ЛПР инструментом для оперативного сбора данных и представления их в удобной для восприятия форме. Обычно результаты нерегламентированных запросов оформляются в виде таблиц или графиков и диаграмм (хотя возможны и другие формы визуализации). Для создания систем отчетности разработчики информационных систем могут применять различные подходы, но самой популярной и доказавшей свою эффективность на сегодняшний день является технология OLAP. Программные OLAP-средства позволяют легко извлекать запрашиваемые пользователем данные и визуализировать их в виде таблиц и диаграмм, но проводить более глубокий анализ (прогнозирование, кластеризация и др.) они, как правило, не могут, так как не позволяют пользователю строить математические и иные модели. Для проведения более глубоко анализа данных, подразумевающего выбор адекватной модели и ее пошаговое улучшение от более грубой к приемлемо точной, пользователю необходимо обратиться к программным средствам, поддерживающим технологии ИАД. Результаты обработки данных, как системами отчетности, так и системами ИАД всего лишь обеспечивают ЛПР информацией для принятия решений: в первом случае это данные в форме таблиц и диаграмм, а во втором – в виде моделей и правил. Информационные технологии ИАД позволяют современной организации осуществлять так называемое «тиражирование знаний», когда один сотрудник на основе анализа получает определенные выводы и формулирует их в виде набора правил или математической модели. Эта модель (или правила) могут быть оформлены организацией как рабочие инструкции для других сотрудников, но могут быть заложены в бизнес-логику программных средств. В любом случае, остальные сотрудники компании могут уже не проводить самостоятельный анализ, а воспользоваться ранее полученными выводами. Это сокращает время на выполнение различных бизнес-процессов, а также позволяет организациям снизить требования к уровню профессиональной компетенции отдельных сотрудников без риска потери качества выполнения бизнес-процессов. Вопросы для самопроверки: 1. Что такое «интеллектуальный анализ данных» (ИАД)? Как этот термин соотносится с понятиями Knowledge Discovery in Databases (KDD) и Data Mining (DM)? 2. В чем отличие ИАД от оперативной аналитической обработки данных (OLAP)? 3. Какие стандартные типы закономерностей (взаимосвязей) можно выявить с помощью методов ИАД? 4. В каких сферах человеческой деятельности можно применять ИАД? 5. Опишите этапы технологического процесса ИАД. 6. Какие группы методов применяются в ИАД? 7. Охарактеризуйте схему интеграции программных средств ИАД и OLAP в рамках одной корпоративной информационной системы 8. Чем отличается классификация от кластеризации? 9. Опишите процесс предобработки данных. 10. Охарактеризуйте методы эволюционного моделирования. Литература по теме: 1. Информационные аналитические системы: учеб. / Т.В. Алексеева, Ю.В. Амириди, В.В. Дик. – М.: Московский финансово-промышленный ун-т «Синергия», 2013. 2. Белов В.С. Информационно-аналитические системы: основы проектирования и применения: учеб.-прак. пособие / В.С. Белов. – 2-е изд., перераб. и доп. – М.: Евразийский открытый институт, 2010. – Режим доступа: http://biblioclub.ru – Тема 4. 3. Нестеров С.А. Интеллектуальный анализ данных средствами MS SQLServer. – 2-е изд., испр. – М.: Национальный Открытый Университет «ИНТУИТ», 2016. – Режим доступа: http://biblioclub.ru –Лекции 1–3. 4. Дюк В. Data mining – интеллектуальный анализ данных. – [электронный ресурс] – Режим доступа: http://www.interface.ru/fset.asp?Url=/oracle/dmiad.htm 5. StatSoft. Методы добычи данных: глава из электронного учебника по статистике компании StatSoft. – [электронный ресурс] – Режим доступа: http://www.olap.ru/basic/data_mining.asp 6. Knowledge Discovery in Databases – обнаружение знаний в базах данных. – [электронный ресурс] – Режим доступа: http://www.basegroup.ru/library/methodology/kdd/ |