Экзаменационные вопросы по ос (80120) 80. Диспетчеризация потоков. Очереди потоков. Состав и организация контекста потока
 Скачать 486.52 Kb. Скачать 486.52 Kb.
|

1 2 Ответы на экзаменационные вопросы по ОС (80-120) 80.Диспетчеризация потоков. Очереди потоков. Состав и организация контекста потока. Диспетчеризация заключается в реализации найденного в результате планирования (динамического или статистического) решения, то есть в переключении процессора с одного потока на другой. Прежде чем прервать выполнение потока, ОС запоминает его контекст, с тем чтобы впоследствии использовать эту информацию для последующего возобновления выполнения данного потока. Диспетчеризация сводится к следующему: сохранение контекста текущего потока, который требуется сменить; загрузка контекста нового потока, выбранного в результате планирования; запуск нового потока на выполнение. 81.Вытесняющие и не вытесняющие алгоритмы планирования. Невытесняющие алгоритмы основаны на том, что активному потоку позволяется выполняться, пока он самт не отдаст управление ОС для того, чтобы та выбрала из очереди другой готовый к выполнению поток. Вытесняющие алгоритмы — это такие способы планирования потоков, в которых решение о переключении процессора с выполнения одного потока на выполнение другого потока принимается ОС, а не активной задачей. Основным различием степень централизации механизма планирования потоков. При применении вытесняющих алгоритмов планирования ОС получает полный контроль над вычислительным процессом, а при применении невытесняющих алгоритмов решения принимаются децентрализованно: активный поток определяет момент смены потоков, а ОС выбирает новый поток для выполнения. При невытесняющем мультипрограммировании механизм планирования распределен между ОС и прикладными программами. Это проблемно. Для пользователей это означает, что управление системой теряется. Поэтому разработчики приложений для операционной среды с невытесняющей многозадачностью вынуждены, возлагая на себя часть функций планировщика, создавать приложения так, чтобы они выполняли свои задачи небольшими частями. Подобный метод затрудняет разработку программ и предъявляет повышенные требования к квалификации программиста. Преимуществом невытесняющего планирования является высокая скорость переключения с потока на поток. Пример: файлсерверы NetWare 3.x и 4.x, в которыхдостигнута высокая скорость выполнения файловых операций. Почти во всех современных ОС реализованы вытесняющие алгоритмы планирования потоков (процессов). При вытесняющем мультипрограммировании функции планирования потоков целиком сосредоточены в ОС, и программист пишет свое приложение, не заботясь о том, что оно будет выполняться одновременно с другими задачами. При этом ОС выполняет следующие функции: определяет момент снятия с выполнения активного потока, запоминает его контекст, выбирает из очереди готовых потоков следующий, запускает новый поток на выполнение, загружая его контекст. 82. Алгоритмы планирования, основанные на квантовании. Квантование — это когда каждому потоку для выполнения поочередно предоставляется ограниченный непрерывный интервал процессорного времени – квант. Смена активного потока происходит, если: 1)поток завершился и покинул систему; 2)произошла ошибка; 3)поток перешел в состояние ожидания; 4)исчерпан квант, отведенный данному потоку. Потокам могут выделяться одинаковые или разные кванты, величина кванта данного потока может быть постоянной (фиксированной) или переменой по мере его развития. Переменная величина кванта может возрастать или убывать. Учет отмеченных факторов увеличивает число возможных вариантов алгоритмов планирования. При переменной величине кванта ее убывание выгодно коротким задачам, а возрастание позволяет уменьшить накладные расходы на переключение задач, если сразу несколько задач выполняют длительные вычисления. При интенсивном вводе-выводе поток не использует квант полностью. В алгоритмах планирования на основе квантования не используется никакой предварительной информации об особенностях решаемых задач (длительность, потребность в обмене, важность), она может накапливаться уже в ходе решения. 83. Схема назначения приоритетов в ОС Windows NT. Обычные пользователи, как правило, не имеют права повышать приоритеты своим потокам. Это могут делать в определенных пределах только администраторы. 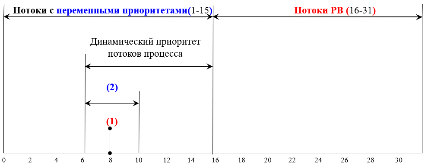 Рисунок 4.2 Схема назначения приоритетов в ОС Windows Рисунок 4.2 Схема назначения приоритетов в ОС Windows В системе определено 32 уровня приоритетов (с диапазоном значений 0-31) и два класса потоков – потоки с переменными приоритетами (с диапазоном значений 1-15) и потоки РВ (с диапазоном значений 16-31). Приоритет 0 зарезервирован для системных целей. При порождении процесса он в зависимости от класса получает по умолчанию базовый приоритет K в верхней или нижней части диапазона (0-31). На рис.4.2 он обозначен (1). Базовый приоритет процесса позднее может быть повышен или понижен ОС. А все потоки данного процесса первоначально получают базовый приоритет (2) из того же диапазона в интервале [K-2, K+2]. Значит, изменяя базовый приоритет процесса, можно влиять на базовые приоритеты его потоков. В ОС Windows NT с течением времени приоритет потока с переменными приоритетами может отклоняться от своего базового значения (2). ОС может повышать приоритет потока (называемый в этом случае динамическим), если поток не полностью использовал свой квант, или понижать его в противном случае. Начальной точкой отсчета для динамического приоритета является значение базового приоритета потока (2). Значение динамического приоритета потока ограничено снизу минимумом его базового приоритета (2), а сверху максимумом приоритета своего класса (рис.4.2). 84.Смешанный алгоритм планирования в ОС Windows Во многих ОС алгоритмы планирования могут учитывать обе рассмотренные выше концепции. Например, в основе планирования лежит квантование, но величина кванта и/или порядок выбора потока из очереди готовых определяется приоритетами потоков. Именно так организовано планирование в ОС Windows NT, где квантование сочетается с динамическими абсолютными приоритетами. На выполнение выбирается поток с наивысшим приоритетом и получает квант. Появившийся более приоритетный поток вытесняет выполняемый. Вытесненный поток возвращается в очередь готовых, причем там становится впереди всех остальных, имеющих равный приоритет. 85.Алгоритм планирования в ОС UNIX System V Release В алгоритме планирования в ОС UNIX System V Release 4.2 вообще отсутствуют потоки и поддерживается вытесняющая многозадачность, основанная приоритетах и квантовании. Процесс может относиться к одному из 2 классов: РВ (диапазон значений приоритетов 100-159) или РДВ (0-99), причем процессы РДВ делятся на пользовательские (0-59) и системные (60-99). Назначение и обработка приоритетов выполняются для процессов разных классов по-разному. Процессы системные РДВ, зарезервированные для ядра ОС, используют стратегию фиксированных приоритетов. Их значения задаются ядром и никогда не изменяются. Процессы РВ также имеют фиксированные приоритеты, но пользователь может изменять их значения. Процессы РВ могут надолго захватывать процессор. Их характеризуют две величины: уровень глобального приоритета и квант. Для каждого уровня приоритета по умолчанию имеется своя величина кванта, что задается специальной внутренней таблицей ОС. 86.Смешанный алгоритм планирования в OS/2 Планирование в OS/2 основано на использовании квантования и абсолютных динамических приоритетов. Все потоки разделены на 4 класса (по убыванию приоритета): * критический (time critical). Например, системные потоки, решающие важнейшие задачи управления сетью; * серверный (server) – потоки, обслуживающие серверные приложения; * стандартный (regular) – потоки обычных приложений; * остаточный (idle) – наименее важные. Например, это поток, выводящий на экран заставку, когда в системе не выполняется никакой работы. В каждом классе имеется 32 уровня (значения) приоритета, что дает в сумме 128 уровней. Поток из менее приоритетного класса не может быть активизирован, пока в очереди более приоритетного класса имеется хотя бы один поток. Внутри каждого класса потоки выбираются также по приоритетам. Потоки с равными приоритетами обслуживаются в циклическом порядке (по карусельной схеме). 87.Схема изменения приоритетов потоков и величины квантов при планировании в OS/2. Планирование в ОС OS/2 также основано на использовании квантования и абсолютных динамических приоритетов. Все потоки разделены на 4 класса (по убыванию приоритета): - критический. Это системные потоки, решающие задачи управления сетью; -серверный. Это потоки, обслуживающие серверные приложения; -стандартный. Это потоки обычных приложений; -остаточный. Это наименее важные. В каждом классе имеется 32 уровня (значения) приоритета, что дает в сумме 128 уровней. Поток из менее приоритетного класса не может быть активизирован, пока в очереди более приоритетного класса имеется хотя бы один поток. Внутри каждого класса потоки выбираются также по приоритетам. Потоки с равными приоритетами обслуживаются в циклическом порядке. Приоритеты потоков могут изменяться планировщиком OS/2 в следующих случаях: - если поток находится в состоянии готовности дольше, чем это задано 60 системной переменной MAXWAIT, то OS/2 увеличит уровень его приоритета. При этом результирующее значение приоритета не должно переводить данный поток в критический класс; - если поток начинает операцию ввода-вывода, то после ее завершения он получит наивысшее значение приоритета своего класса; - при активизации потока его приоритет автоматически повышается. OS/2 динамически устанавливает и величину кванта потока в зависимости от степени загрузки системы и интенсивности подкачки. Средства настройки параметров OS/2 позволяют пользователю самостоятельно явно задать границы изменения величины кванта командой TIMESLICE=a, b (где a-b – задаваемый диапазон в пределах 32-65536 мс, по умолчанию 32-246 мс). Если поток был прерван до истечения кванта, то следующий квант его выполнения будет увеличен на 32 мс (один период таймера) и так много раз до тех пор, пока не будет достигнуто установленное значение b. 88.События, требующие перераспределения процессорного времени, и действия планировщика ОС в каждом случае. Когда дальнейшее выполнение потока невозможно, например из-за его завершения или перехода в ждущее состояние, ядро напрямую обращается к диспетчеру, чтобы вызвать немедленное переключение контекста. Однако иногда ядро обнаруживает, что перераспределение процессорного времени должно произойти при выполнении глубоко вложенных уровней кода. B этой ситуации ядро запрашивает диспетчеризацию, но саму операцию откладывает до выполнения текущих действий. Такую задержку удобно организовать с помощью программного прерывания DPC (deferred procedure call). При необходимости синхронизации доступа к разделяемым структурам ядра последнее всегда повышает IRQL процессора до уровня «DPC/dispatch» или выше. При этом дополнительные программные прерывания и диспетчеризация потоков запрещаются. Обнаружив необходимость в диспетчеризации, ядро генерирует прерывание уровня «DPC/dispatch». Ho поскольку IRQL уже находится на этом уровне или выше, процессор откладывает обработку этого прерывания. Когда ядро завершает свои операции, оно определяет, что должно последовать снижение IRQL ниже уровня "DPC/dispatch", и проверяет, не ожидают ли выполнения отложенные прерывания диспетчеризации. Если да, IRQL понижается до уровня «DPC/dispatch», и эти отложенные прерывания обрабатываются.. 89.Моменты перепланировки в среде ОС РВ. Для реализации своего алгоритма планирования ОС должна получать управление всякий раз, когда в системе происходит событие, требующее перераспределения процессорного времени: 1) прерывание от таймера – конец кванта. Планировщик ОС переводит задачу (поток) в состояние готовности и выполняет перепланировку; 2) активная задача выполнила системный вызов – запрос на ввод-вывод или на доступ к ресурсу, который в настоящий момент времени занят. Планировщик переводит задачу в состояние ожидания и выполняет перепланировку; 3) активная задача 1 выполнила системный вызов, связанный с освобождением ресурса. Планировщик проверяет, не ожидает ли этот ресурс задача 2. 4) внешнее аппаратное прерывание, сигнализирующее о завершении УВВ операции ввода-вывода. Планировщик переводит соответствующую задачу в очередь готовых и выполняет перепланировку; 5) внутреннее прерывание, сигнализирующее об ошибке в результате выполнения активной задачи. Планировщик снимает задачу и выполняет перепланировку. При возникновении каждого из этих событий планировщик ОС просматривает очереди задач и решает, какая задача будет выполняться следующей. 90.Диспетчеризация и учет приоритетов прерываний в ОС. Диспетчер прерываний. Для упорядочения работы обработчиков прерываний в ОС применяется тот же механизм, что и для пользовательских процессов – механизм приоритетных очередей. Все источники прерываний обычно делятся на несколько классов, причем каждому классу присваивается приоритет. В ОС выделяется программный модуль, который занимается диспетчеризацией обработчиков прерываний – диспетчер прерываний, обеспечивающий обслуживание с абсолютными приоритетами. При возникновении прерывания диспетчер прерываний вызывается первым, запрещает ненадолго все прерывания, выясняет причину (и источник) прерывания. Затем диспетчер прерываний сравнивает назначенный данному источнику прерывания приоритет с текущим приоритетом потока команд, выполняемого процессором, и если новый приоритет выше текущего, запускает соответствующий обработчик. В этот момент времени процессор уже может выполнять инструкции другого обработчика прерываний, также имеющего некоторый приоритет. И если приоритет нового запроса выше текущего, то выполнение текущего обработчика приостанавливается, и он помещается в соответствующую очередь обработчиков прерываний. Иначе в очередь помещается обработчик нового запроса. Приоритет обработчиков прерываний в общем случае всегда выше приоритета потоков, выполняемых в обычной последовательности, определяемой планировщиком потоков. Поэтому любой запрос на прерывание всегда может прервать выполнение обычного потока. Так как процедуры, вызываемые по запросам прерываний, обычно выполняют работу, не связанную с текущим процессом, то для них вводятся ограничения: они не имеют права использовать ресурсы процесса или от его имени запрашивать выделение дополнительных ресурсов. Диспетчеризация прерываний является важной функцией, 64 реализованной практически во всех мультипрограммных ОС. 91.Диспетчеризация системных вызовов. Системный вызов позволяет приложению обратиться к ОС с просьбой выполнить то или иное действие, оформленное как процедура (или набор процедур) кодового сегмента ОС. Реализация системных вызовов должна: -обеспечивать переключение в привилегированный режим (часто только с помощью механизма программных прерываний); -обладать высокой скоростью вызова процедур ОС; -обеспечивать по возможности единообразное обращение к системным вызовам; -допускать легкое расширение набора системных вызовов; -обеспечивать контроль со стороны ОС за корректным использованием системных вызовов. Здесь при любом системном вызове приложение выполняет программное прерывание (INT) с определенным и единственным номером вектора. Перед выполнением программного прерывания приложение некоторым образом передает ОС номер системного вызова, который является индексом в специально организованной дополнительной таблице sysent адресов процедур ОС, реализующих системные вызовы. Кроме номера передаются аргументы системного вызова. После завершения обработки системного вызова управление возвращается диспетчеру системных вызовов вместе с кодом завершения этого вызова. Диспетчер системных вызовов восстанавливает регистры процессора, помещает в определенный регистр код возврата и выполняет инструкцию возврата из прерывания, которая восстанавливает непривилегированный режим работы процессора 92.Схема организации системных вызовов с диспетчером системных вызовов. Диспетчер системных вызовов обычно представляет собой простую программу, которая сохраняет содержимое регистров процессора в системном стеке (в связи со сменой режима процессора), проверяет, попадает ли запрошенный номер вызова в поддерживаемый ОС диапазон (в таблицу sysent адресов системных вызовов) и передает управление адресованной процедуре ОС. Искомая процедура обработки системного вызов извлекает из системного стека аргументы и выполняет заданное действие. После завершения обработки системного вызова управление возвращается диспетчеру системных вызовов вместе с кодом завершения этого вызова. Диспетчер системных вызовов восстанавливает регистры процессора, помещает в определенный регистр код возврата и выполняет инструкцию возврата из прерывания, которая восстанавливает непривилегированный режим работы процессора.  93.Особенности и различия организации синхронных и асинхронных системных вызовов. ОС может выполнять системные вызовы в синхронном или асинхронном режиме. Поток (процесс), сделавший синхронный (блокирующий) системный вызов, переводится планировщиком ОС в состояние ожидания, а после завершения обработки вызова – в состояние готовности. Тогда при следующей активизации этот поток уже сможет воспользоваться результатами своего системного вызова. В свою очередь, асинхронный системный вызов не приводит к переходу потока в состояние ожидания результатов вызова. Вместо этого поток переводится в состояние готовности, пока активизируются короткие начальные системные действия (например, запуск операции ввода-вывода), но неясно, когда поток сможет воспользоваться результатами данного системного вызова (это становится заботой самого потока). Большинство системных вызовов в ОС являются синхронными, так как это избавляет приложение от работы по выяснению момента появления результатов вызова. Вместе с тем в новых версиях ОС число асинхронных системных вызовов постепенно растет, что дает больше свободы разработчикам сложных приложений. Особенно нужны асинхронные системные вызовы в ОС на основе микроядра, так как при этом в пользовательском режиме работает часть модулей ОС, которым необходимо иметь полную свободу в организации своей работы, а такую свободу дает только асинхронный режим обслуживания вызовов микроядром. 93.Особенности и различия организации синхронных и асинхронных системных вызовов. ОС может выполнять системные вызовы в синхронном или асинхронном режиме. Поток (процесс), сделавший синхронный (блокирующий) системный вызов, переводится планировщиком ОС в состояние ожидания, а после завершения обработки вызова – в состояние готовности. Тогда при следующей активизации этот поток уже сможет воспользоваться результатами своего системного вызова. В свою очередь, асинхронный системный вызов не приводит к переходу потока в состояние ожидания результатов вызова. Вместо этого поток переводится в состояние готовности, пока активизируются короткие начальные системные действия (например, запуск операции ввода-вывода), но неясно, когда поток сможет воспользоваться результатами данного системного вызова (это становится заботой самого потока). Большинство системных вызовов в ОС являются синхронными, так как это избавляет приложение от работы по выяснению момента появления результатов вызова. Вместе с тем в новых версиях ОС число асинхронных системных вызовов постепенно растет, что дает больше свободы разработчикам сложных приложений. Особенно нужны асинхронные системные вызовы в ОС на основе микроядра, так как при этом в пользовательском режиме работает часть модулей ОС, которым необходимо иметь полную свободу в организации своей работы, а такую свободу дает только асинхронный режим обслуживания вызовов микроядром.94.Цели взаимодействия, синхронизация процессов и потоков. Гонки, критическая секция, взаимное исключение потоков. В мультипрограммной ОС процессы (потоки) также могут и взаимодействовать друг с другом, причем с такими двумя целями как обмен данными и взаимная синхронизация исполнения. Организация осложняется тем, что оно происходит в условиях разделения (совместного использования) взаимодействующими процессами и потоками аппаратных и информационных ресурсов ВС. Синхронизация необходима для исключения дефектов (гонок и тупиков) при обмене данными между потоками, разделении данных, при доступе к процессору и к УВВ. Любое взаимодействие процессов или потоков связано с их синхронизацией, которая заключается в согласовании их скоростей путем приостановки отдельного потока до наступления некоторого события с последующей активизацией данного потока при наступлении этого события. Синхронизация требуется независимо от того, с чем связано взаимодействие (с разделением ресурсов или с обменом данными), так как процессы или потоки связаны отношением «производитель-потребитель». Ситуации, когда два или более потоков обрабатывают разделяемые данные, и конечный результат зависит от соотношения скоростей потоков, называются гонками. Критическая секция – это часть программы, результат выполнения которой может непредсказуемо меняться, если переменные, относящиеся к ней, изменяются другими потоками в то время, когда ее выполнение еще не завершено. Критическая секция всегда определяется по отношению к определенным критическим данным, при несогласованном изменении которых могут возникнуть нежелательные эффекты. Для исключения эффекта гонок по отношению к критическим данным необходимо обеспечить взаимное исключение, чтобы в каждый момент времени в критической секции находился только один поток, неважно в каком состоянии. При этом обычно ОС использует разные способы реализации взаимного исключения, пригодные для потоков одного и/или разных процессов. 95.Блокирующие переменные и семафоры. Примеры. Блокирующие переменные. Для синхронизации потоков одного процесса прикладной программист может использовать глобальные блокирующие переменные, доступные всем его потокам. Каждому набору критических данных D ставится в соответствие двоичная переменная F, которой поток присваивает значение F(D)=0 при вхождении в критическую секцию или F(D)=1 – при выходе из нее. Пока F(D)=0, другой поток, циклически проверяя это, не может войти в критическую секцию  96.Пример использования семафоров при работе с буферным пулом записи чтения.  Пусть пул включает N буферов, каждый буфер может содержать одну запись. В общем случае поток-писатель и поток-читатель могут обращаться к пулу с переменной интенсивностью. При этом скорость заполнения пула может превышать скорость освобождения и наоборот. Тогда для правильной совместной работы поток-писатель должен приостанавливаться при заполнении пула (в состоянии, когда некуда писать), а поток-читатель – при освобождении пула (в состоянии, когда нечего читать). Введем два семафора: e – число пустых (empty) буферов, f – число заполненных (filled) буферов. N=e + f. В исходном состоянии e = N, f = 0. Поток-писатель выполняет операцию P(e): если e>0, то записывает данные в пустой буфер, делает уменьшение e:=e–1 и выполняет операцию V(f): f:=f+1; иначе ожидание. Поток-читатель выполняет операцию P(f): если f>0, то читает данные из непустого буфера, делает уменьшение f:=f–1 и выполняет операцию V(e): e:=e+1; иначе ожидание. Заметим, что буферный пул здесь является критическим ресурсом. А использование блокирующей переменной вместо семафора не позволяет 72 организовать доступ к критическому ресурсу более чем одному потоку. Последнее актуально, если требуется сделать запись и чтение данных критическими секциями и обеспечить взаимное исключение. Семафор же решает задачу более гибко, допуская к разделяемому пулу ресурсов заданное число потоков. В нашем примере с пулом могут работать до N потоков, часть из которых – «писатели», остальные – «читатели». 97.Тупики, идеи и средства их выявления и устранения. Взаимные блокировки (дедлоки, клинчи или тупики) – ситуации, когда два и более потоков из-за занятости, запретов или ограничений доступа к ресурсам (памяти, УВВ) могут взаимно и неразрешимо мешать развитию друг друга. На случаи, когда тупики все же возникают, администратору нужны средства их своевременного выявления, снятия и восстановления нормальной работы ВС. Тупики должны предотвращаться при написании приложений. Другой подход заключается в том, что ОС при каждом запуске задач анализирует состав мультипрограммной смеси (требования задач к ресурсам). Запуск задачи, которая может вызывать тупик, временно откладывается. ОС может также использовать особые правила выделения ресурсов процессам, например, строго последовательно и полностью. Тупиковую ситуацию важно быстро и точно распознать. Если тупик образован множеством потоков, занимающих массу ресурсов, распознавание его становится нетривиальной задачей. Существуют формальные, программно реализованные методы распознавания тупиков, основанные на ведении таблиц распределения ресурсов и таблиц запросов к занятым ресурсам. Анализ этих таблиц позволяет обнаруживать взаимные блокировки алгоритмически. Если же тупиковая ситуация все же возникла, не обязательно снимать с решения все задачи или заблокированные потоки. Достаточно начать снимать некоторые из них, освобождая ожидаемые ресурсы. Можно вернуть некоторые потоки в область подкачки. Можно совершить откат некоторых потоков до так называемой контрольной точки, специально созданной программистом, где запоминается вся информация для восстановления выполнения программы с данного места и т.п. 98. Виды синхронизирующих объектов ОС, их сигнальное состояние, примеры. Использование для синхронизации потоков глобальных переменных процесса не подходит для синхронизации потоков разных процессов (чужих). В таких случаях ОС должна предоставлять потокам свои собственные, так называемые системные объекты синхронизации, которые были бы доступны всем потокам, даже если они принадлежат разным процессам и работают в разных адресных пространствах. Примерами таких синхронизирующих объектов ОС являются системные семафоры, мьютексы, события, таймеры и др. Их набор зависит от конкретной ОС, которая создает эти объекты по запросам от процессов. Кроме того, для синхронизации могут быть использованы обычные объекты ОС: файлы, процессы, потоки. Все они могут находиться в двух состояниях: сигнальном (оповещающем) и несигнальном (свободном). А конкретный смысл сигнального состояния зависит от типа объекта. Например, поток переходит в сигнальное состояние, когда он завершается, процесс – когда завершаются все его потоки, файл – когда завершается операция его ввода-вывода (остальные объекты ОС – в результате выполнения специальных системных вызовов). Тогда приостановка и активизация потоков осуществляется в зависимости от состояния этих синхронизирующих объектов ОС. Потоки с помощью специального системного вызова сообщают ОС, что они хотят синхронизировать свое выполнение с состоянием некоторого объекта. 99.Мьютекс, объект-событие. Сигналы. Мьютекс или взаимоисключение, как и семафор, обычно используется для управления доступом к данным. Мьютекс устанавливается в особое сигнальное состояние, когда он не занят каким-либо потоком. Только один поток может владеть мьютексом. В отличие от обычных объектов (потоков, процессов, файлов), которые при переходе в сигнальное состояние переводят в состояние готовности все потоки, ожидающие этого события, объект-мьютекс «освобождает» из очереди ожидающих только один поток. Работу мьютекса легко пояснить в терминах «владения переходящим пропуском». Пусть поток, который, пытаясь получить доступ к критическим данным, выполнил системный вызов Wait(X), где X – указатель на мьютекс. Объект-событие обычно используется для того, чтобы оповестить другие потоки о том, что некоторые действия завершены. Пусть, например, в некотором приложении работа организована так, что первый поток читает данные из файла в буфер памяти, а другие потоки обрабатывают эти данные, затем первый поток считывает новую порцию данных для обработки другими потоками и так далее. В начале работы первый поток устанавливает объект-событие в несигнальное состояние. Все остальные потоки выполнили вызов Wait(X), где X – указатель на это событие, и находятся в приостановленном состоянии, ожидая его наступления. Как только буфер заполняется, первый поток сообщает об этом ОС, выполняя вызов Set(X). ОС просматривает очередь ожидающих потоков и активизирует все потоки, ожидающие наступления этого события. Сигнал дает возможность задаче реагировать на событие, источником которого может быть ОС или другая задача. Сигналы вызывают прерывание задачи и выполнение заранее предусмотренных действий. Сигналы могут вырабатываться синхронно (в результате работы самого процесса) или асинхронно (направляться процессу от другого процесса). Синхронные сигналы чаще всего приходят от системы прерываний процессора и свидетельствуют о действиях процесса, блокируемых аппаратурой, например, деление на 0, ошибка адресации, нарушение защиты памяти. 100.Виды адресов команд и данных. ВАП и образ процесса. 1) виртуальные (математические, логические) условные адреса, вырабатываемые транслятором, переводящим программу и все ее авторские символьные имена на машинный язык. Во время трансляции в общем случае неизвестно, в какое место ОП будет загружена программа. Поэтому транслятор может присвоить переменным и командам только виртуальные (условные) адреса, по умолчанию начиная программу с нулевого адреса; 2) физические адреса, соответствующие реальным номерам ячеек ОП, где могут быть расположены переменные и команды. Совокупность виртуальных адресов процесса называется его виртуальным адресным пространством (ВАП). Содержимое назначенного процессу ВАП (коды команд, исходные и промежуточные данные, результаты вычислений) представляет собой образ процесса. 101.Способы структурирования ВАП процесса. В разных ОС используются различные способы структурирования ВАП: плоская (flat) структура – в виде непрерывной линейной последовательности виртуальных адресов. Здесь адрес определяется как число m, задающее смещение относительно начала ВАП. ВАП делится на части одного вида – сегменты (области и т.п.). Виртуальный адрес в этом случае представляет собой пару чисел вида (номер сегмента, смещение внутри сегмента). ВАП делится на части нескольких видов, что усложняет адрес до нескольких чисел [1-2,11]. 102.Классы алгоритмов распределения ОП, состав классов. Все алгоритмы распределения ОП делятся на два класса, работающие без использования внешней памяти: - распределение фиксированными разделами. ОП на сеанс работы разбивается на несколько разделов фиксированной величины каждый. К разделам организуется одна или несколько очередей процессов, - распределение динамическими разделами, по мере порождения процессов. Алгоритм связан с различными вариантами поиска свободной области ОП для раздела, отличается большей гибкостью, но подвержен эффекту фрагментации, - распределение перемещаемыми разделами. Используется как метод борьбы с фрагментацией на основе ликвидации «дыр» в ОП; с использованием внешней памяти: - страничное распределение, когда частями ОП и ВАП являются страницы фиксированного и сравнительно небольшого размера, - сегментное распределение, когда частями ОП и ВАП являются сегменты произвольного размера (какой получится у программиста), организованные с учетом смыслового значения данных, - сегментно-страничное распределение – комбинация двух предыдущих алгоритмов, когда ВАП делится на сегменты, которые затем делятся на страницы. 103.Свопинг, его достоинства и недостатки. Виртуализация памяти может быть осуществлена на основе двух различных подходов: 1)свопинг (swapping – подкачка) – образы процессов выгружаются на диск и возвращаются в ОП целиком. Подкачке свойственна избыточность, так как часто достаточно было бы загрузить/выгрузить лишь часть образа процесса. Кроме того, перемещение избыточной информации замедляет работу системы, приводит к неэффективному использованию ОП. Нельзя загрузить для выполнения процесс, ВАП которого превышает размер свободной ОП 2) виртуальная память – между ОП и диском перемещаются части образов процессов (страницы, сегменты). Для временного хранения сегментов и страниц на диске отводится либо специальная область, либо специальный файл, который по традиции продолжают называть областью или файлом свопинга (swap-файлом), хотя перемещение между ОП и диском осуществляется уже не процессами целиком, а их частями. Используется и другое название – страничный файл (page file, paging file). Текущий размер страничного файла является важным параметром: чем он больше, тем больше приложений может одновременно выполнять ОС при фиксированном размере ОП. Но при этом их работа замедляется, так как значительная часть времени тратится на перекачку кодов и данных из ОП на диск и обратно. Из-за своих недостатков свопинг как основной механизм управления памятью почти не используется в современных ОС. Например, в версиях UNIX, основанных на System V Release 4, свопинг служит дополнением виртуальной памяти и включается лишь при серьезных перегрузках системы. 104.Страничное распределение ОП. Страничное распределение памяти — это отображение виртуального адресного пространства, которое исключает внешнюю фрагментацию путем разбиения ОП на единицы одинаковой длины (в отличие от сегментации). Обращение к памяти имеет вид: ( p, i ), где р - номер страницы, i - индекс. Виртуальный адрес - число, в котором старшие биты определяют р, а младшие биты -определяют i. Отображение, осуществляемое системой во время исполнения, сводится к отображению р в f, где f - номер физической страницы. Отличие от сегментации: •разбиение программы на сегменты осуществляется пользователем; •разбиение на страницы выполняется транслятором. Перечень положений при распределении страниц ОП по запросам: •ОП разбивается на блоки фиксированной длины; •адресное пространство разбивается на страницы, такого же размера; •для каждой задачи пользователя организуется таблица страниц; существует регистр адреса таблицы страниц, содержание регистров меняется при переключении от одной задаче к другой. 105.Известные стратегии замещения страниц. Обычно рассматривают три стратегии: Стратегия выборки (fetch policy) - в какой момент следует переписать страницу из вторичной памяти в первичную. Выборка бывает по запросу и с упреждением. Алгоритм выборки вступает в действие в тот момент, когда процесс обращается к не присутствующей странице, содержимое которой в данный момент находится на диске (в своп файле или отображенном файле), и потому является ключевым алгоритмом свопинга. Он обычно заключается в загрузке страницы с диска в свободную физическую страницу и отображении этой физической страницы в то место, куда было произведено обращение, вызвавшее исключительную ситуацию. Существует модификация алгоритма выборки, которая применяет еще и опережающее чтение (с упреждением), т.е. кроме страницы, вызвавшей исключительную ситуацию, в память также загружается несколько страниц, окружающих ее (так называемый кластер). Такой алгоритм призван уменьшить накладные расходы, связанные с большим количеством исключительных ситуаций, возникающих при работе с большими объемами данных или кода, кроме того, оптимизируется и работа с диском, поскольку появляется возможность загрузки нескольких страниц за одно обращение к диску. Стратегия размещения (placement policy) - определить в какое место первичной памяти поместить поступающую страницу. В системах со страничной организацией в любой свободный страничный кадр (в системах с сегментной организацией - нужна стратегия, аналогичная стратегии с переменными разделами). Стратегия замещения (replacement policy) - какую страницу нужно вытолкнуть во внешнюю память, чтобы освободить место. Разумная стратегия замещения позволяет оптимизировать хранение в памяти самой необходимой информации и тем самым снизить частоту страничных нарушений. 106.Поддержка разделов при страничном распределении ОП. Основные положения схемы страничного распределения: память разбивается на блоки фиксированной длины; адресное пространство любой задачи разбивается на страницы такой же длины; страницы одной задачи должны быть все одновременно в ОП, но могут занимать различные участки памяти; страницы не перемещаются; для каждой задачи организуется таблица страниц; структура адреса (исполнительного): 2). Обычно размер страницы 1К, 2К, 4К; используется "регистр адреса таблицы страниц" - для указания адреса таблицы страниц текущей задачи. Таблица страниц устанавливает взаимосвязь между логическим страницами, с которыми работает процесс пользователя, и физическими страницами, с которыми работает центральный процессор. С одной физической страницей могут быть связаны несколько логических (например: когда несколько процессов разделяют некоторую повторно входимую программу). Логическое адресное пространство страницы — это источник информации для передачи данных (чему-либо - в наше случае - физической памяти). Достоинства распределения: отсутствует внешняя фрагментация (а есть, например, внутри страницы); нет затрат на сжатие. Недостатки распределения: двойное обращение к ОП - быстродействие понижается в, меры исключения этого недостатка: ассоциативная память, специальные регистры для всех таблиц страниц. накладные расходы на таблицы; внутренняя фрагментация ("усеченные страницы"); задачи, занимающие ОП, не все используются; возможны отказы. 107.Сегментное распределение ОП. При сегментной организации памяти ВАП(Это метод доступа к информации в Интернете с цифрового беспроводного телефона, пейджера или другого устройства. WAP — аббревиатура английского термина, что означает «протокол беспроводного доступа».) процесса делится на части – сегменты, размер которых определяется с учетом смыслового значения содержащейся в них информации (подпрограмма, массив данных и т.п.). Деление ВАП на сегменты производится компилятором на основе указаний программиста или по умолчанию, в соответствии с принятыми в системе соглашениями. Размер сегмента ограничивается лишь разрядностью виртуального адреса, например, при 32-разрядной адресации сегмент может занимать до 4 Гбайт. В каждом сегменте виртуальные адреса находятся в диапазоне от 0000000016 до FFFFFFFF16. А ВАП процесса представляет собой набор N виртуальных сегментов, не упорядоченных друг относительно друга. Полная копия ВАП хранится в дисковой памяти. Для каждого загружаемого сегмента ОС подыскивает непрерывный участок ОП достаточного размера, что, конечно, вызывает большие проблемы по сравнению с поиском свободной страницы . Смежные сегменты ВАП процесса могут в ОП занимать несмежные участки. Если во время выполнения процесса происходит обращение по виртуальному адресу, относящемуся к сегменту, который в настоящий момент отсутствует в ОП, то происходит прерывание. ОС переводит активный процесс в состояние ожидания, активизирует очередной процесс, а параллельно организует загрузку нужного сегмента с диска. А при отсутствии в ОП свободного места для загрузки данного сегмента, ОС выбирает «ненужный» сегмент для выгрузки по критериям, аналогичным критериям выгрузки страниц. При порождении процесса во время загрузки его образа в ОП ОС создает таблицу сегментов процесса, подобную таблице страниц и содержащую в дескрипторе каждого сегмента: базовый физический адрес сегмента в ОП; размер сегмента; правила доступа к сегменту; признаки: модификации, присутствия и обращения к сегменту, а также некоторую дополнительную информацию. 108.Сегментно-страничное распределение ОП. Это комбинация страничного и сегментного механизмов управления памятью с реализацией достоинств обоих подходов: ВАП процесса разделено на сегменты, что обеспечивает поддержку разных прав доступа; перемещение данных между ОП и диском осуществляется страницами. Для этого каждый виртуальный сегмент и вся физическая память делятся на страницы равного (фиксированного) размера, что позволяет более эффективно использовать ОП, до минимума сокращая фрагментацию. Но в отличие от ВАП в виде набора отдельных виртуальных диапазонов адресов (0000000016 – FFFFFFFF16) каждого сегмента при сегментной организации (рис.5.9), при сегментно-страничной организации все виртуальные сегменты образуют одно общее непрерывное линейное ВАП процесса в диапазоне (0000000016 – FFFFFFFF16), показанное на рис.5.11. Координаты байта в ВАП теоретически можно задать двумя способами: линейным виртуальным адресом, который равен сдвигу данного байта относительно границы общего линейного ВАП; парой чисел вида (номер сегмента, смещение от начала сегмента), а также указать начальный виртуальный адрес сегмента с данным номером. Системы виртуальной памяти ОС с сегментно-страничной 99 организацией используют именно второй способ, как позволяющий непосредственно определить принадлежность адреса некоторому сегменту и проверить права доступа процесса к нему. Первый этап. Работает механизм сегментации. Исходный виртуальный адрес вида (номер сегмента, смещение) преобразуется в линейный виртуальный адрес. Для этого по базовому адресу таблицы сегментов и номеру сегмента из таблицы сегментов извлекается дескриптор этого сегмента. Производится анализ полей дескриптора. Если доступ к сегменту разрешен, то вычисляется линейный виртуальный адрес путем сложения базового виртуального адреса сегмента (из дескриптора) и смещения. Второй этап. Работает страничный механизм. Полученный линейный виртуальный адрес преобразуется в искомый физический адрес. Вначале выделяются его составляющие (номер виртуальной страницы, смещение в странице), понятные страничному механизму. Благодаря тому, что размер страницы равен 2k, эта задача решается простым отделением младших k двоичных разрядов. При этом смещением является содержимое младших k разрядов, а номером виртуальной страницы – содержимое оставшихся старших разрядов. Далее преобразование адреса в физический происходит так же, как при страничной организации. Номер виртуальной страницы дает адрес дескриптора страницы в таблице страниц, по которому из дескриптора выбирается номер физической страницы. Последний операцией конкатенации присоединяется к смещению. 109. Разделяемые сегменты памяти Подсистема виртуальной памяти может обеспечивать и совместный доступ нескольких процессов к одному и тому же сегменту памяти, который в этом случае называется разделяемой памятью (shared memory). Разделяемый сегмент необходимо поместить в ВАП каждого работающего с ним процесса, после чего настроить параметры отображения этих виртуальных сегментов так, чтобы они соответствовали одной и той же области ОП. Детали такой настройки зависят от используемой в ОС модели виртуальной памяти, поддерживающей сегменты (сегментной или сегментно-страничной). Разделяемые сегменты памяти как средство межпроцессной связи позволяют процессам иметь общие области виртуальной памяти и, как следствие, разделять содержащуюся в них информацию. Единицей разделяемой памяти являются сегменты, свойства которых зависят от аппаратных особенностей управления памятью. Разделение памяти обеспечивает наиболее быстрый обмен данными между процессами. Работа с разделяемой памятью начинается с того, что процесс при помощи системного вызова shmget создает разделяемый сегмент, специфицируя первоначальные права доступа к сегменту (чтение и / или запись) и его размер в байтах. Чтобы затем получить доступ к разделяемому сегменту, его нужно присоединить посредством системного вызова shmat(), который разместит сегмент в виртуальном пространстве процесса. После присоединения, в соответствии с правами доступа, процессы могут читать данные из сегмента и записывать их (быть может, синхронизируя свои действия с помощью семафоров). Когда разделяемый сегмент становится ненужным, его следует отсоединить, воспользовавшись системным вызовом shmdt(). Для выполнения управляющих действий над разделяемыми сегментами памяти служит системный вызов shmctl(). В число управляющих действий входит предписание удерживать сегмент в оперативной памяти и обратное предписание о снятии удержания. После того, как последний процесс отсоединил разделяемый сегмент, следует выполнить управляющее действие по удалению сегмента из системы. 110. Задачи ОС по управлению УВВ и файлами. Одной из главных задач ОС является обеспечение обмена данными между работающими программами и УВВ компьютера. В современных ОС эти функции выполняет подсистема ввода-вывода, клиентами которой являются не только пользователи и приложения, но и компоненты самой ОС при необходимости получения или вывода ими каких-то системных данных. Подсистема ввода-вывода (Input-Output Subsystem) мультипрограммной ОС при обмене данными с внешними устройствами компьютера должна решать ряд общих задач, из которых наиболее важными являются следующие: организация параллельной работы устройств ввода-вывода и процессора; согласование скоростей обмена и кэширование данных; разделение устройств и данных между процессами; обеспечение удобного логического интерфейса между устройствами и остальной частью системы; поддержка широкого спектра драйверов с возможностью простого включения в систему нового драйвера; динамическая загрузка и выгрузка драйверов; поддержка нескольких файловых систем; поддержка синхронных и асинхронных операций ввода-вывода. Рассмотрим перечисленные задачи более подробно. Организация параллельной работы устройств ввода-вывода и процессора. Каждое устройство ввода-вывода вычислительной системы - диск, принтер, терминал и т. п. - снабжено специализированным блоком управления, называемым контроллером. Контроллер взаимодействует с драйвером - системным программным модулем, предназначенным для управления данным устройством. Контроллер периодически принимает от драйвера выводимую на устройство информацию, а также команды управления, которые говорят о том, что с этой информацией нужно сделать (например, вывести в виде текста в определенную область терминала или записать в определенный сектор диска). Под управлением контроллера устройство может некоторое время выполнять свои операции автономно, не требуя внимания со стороны центрального процессора. Процессы, происходящие в контроллерах, протекают в периоды между выдачами команд независимо от ОС. От подсистемы ввода-вывода требуется спланировать в реальном масштабе времени (в котором работают внешние устройства) запуск и приостановку большого количества разнообразных драйверов, обеспечив приемлемое время реакции каждого драйвера на независимые события контроллера. При этом необходимо минимизировать загрузку процессора задачами ввода-вывода, оставив как можно больше процессорного времени на выполнение пользовательских потоков. Согласование скоростей обмена и кэширование данных. При обмене данными всегда возникает задача согласования скорости. Например, если один пользовательский процесс вырабатывает некоторые данные и передает их другому пользовательскому процессу через оперативную память, то в общем случае скорости генерации данных и их чтения не совпадают. Согласование скорости обычно достигается за счет буферизации данных в оперативной памяти и синхронизации доступа процессов к буферу. В подсистеме ввода-вывода для согласования скоростей обмена также широко используется буферизация данных в оперативной памяти. В тех специализированных ОС, в которых обеспечение высокой скорости ввода-вывода является первоочередной задачей (управление в реальном времени, услуги сетевой файловой службы и т. п.), большая часть оперативной памяти отводится не под коды прикладных программ, а под буферизацию данных. Однако буферизация только на основе оперативной памяти в подсистеме ввода-вывода оказывается недостаточной. Разница между скоростью обмена с оперативной памятью, куда процессы помещают данные для обработки, и скоростью работы внешнего устройства часто становится слишком значительной, чтобы в качестве временного буфера можно было бы использовать оперативную память - ее объема может просто не хватить. Для таких случаев необходимо предусмотреть особые меры, и часто в качестве буфера используется дисковый файл, называемый также спул-файлом (от spool - шпулька, тоже буфер, только для ниток). Типичный пример применения спулинга дает организация вывода данных на принтер. 111. Особенности важнейших задач подсистемы ввода-вывода. Организация параллельной работы УВВ и процессора. Каждое УВВ ВС снабжено специализированным блоком управления – контроллером, который взаимодействует с драйвером – системным программным модулем, предназначенным для управления данным устройством. Согласование скоростей обмена и кэширование данных. Согласование скоростей обычно достигается за счет буферизации данных в ОП и синхронизации доступа процессов к буферу Разделение УВВ и данных между процессами. УВВ могут предоставляться процессам в монопольное или совместное (разделяемое) использование. При этом ОС должна обеспечивать контроль доступа теми же способами, что и при доступе процессов к другим ресурсам ВС – путем проверки прав пользователя или группы, от имени которых действует процесс, на выполнение данной операции над УВВ. Обеспечение удобного логического интерфейса между УВВ и остальной частью ОС. Разнообразие УВВ делает особенно актуальной функцию ОС по созданию экранирующего логического интерфейса между периферийными устройствами и приложениями. 1 2 |