Этапы. Этапы эконометрического моделирования
 Скачать 0.7 Mb. Скачать 0.7 Mb.
|

|
Этапы эконометрического моделирования Выделяют следующие этапы: постановочный; априорный; спецификация модели; информационный; идентификация модели; верификация модели; интерпретация результатов. Причины наличия в регрессионной модели случайного отклонения. Среди таких причин можно выделить наиболее существенные: не включение в модель всех объясняющих переменных, неправильный выбор функциональной формы модели, агрегирование переменных, ошибки измерений, ограниченность статистических данных, непредсказуемость человеческого фактора. Типы моделей и переменных, применяемых в эконометрике. Чем регрессионная модель отличается от функции регрессии? Для моделирования эконометрических взаимосвязей между экономическими явлениями чаще всего применяется три типа моделей и три типа переменных. Типы моделей: 1) Модели временных рядов - Модель представляет собой зависимость результативного признака от переменной времени или переменных, относящихся к другим моментам времени. 2) Модели регрессии - это уравнение, в котором объясняемая переменная представляется в виде функции от объясняющих переменных (например, модель спроса на некоторый товар в зависимости от его цены и дохода покупателей). 3) Системы одновременных уравнений - системы уравнений, состоящие из регрессионных уравнений и тождеств, в каждом из которых помимо объясняющих – независимых – переменных содержатся объясняемые переменные из других уравнений системы. Типы переменных: 1) Экзогенные (внешние, независимые)- это внешние для модели переменные, управляемые из вне, влияющие на эндогенные переменные, но не зависящие от них. Х-обознач. 2) Эндогенные (внутренние, зависимые)- это внутренние, формируемые в модели переменные, зависимые от предопределенных переменных. Y-обоз. 3) Предопределенные (экзогенные и лаговые эндогенные)-называют экзогенные переменные х и лаговые эндогенные переменные yt-l. Регрессионная модель – это уравнение, в котором объясняемая переменная представляется в виде функции от объясняющих переменных. Функция регрессии –функция f(x1,x2..)описывает зависимость условного среднего значения результативной переменной y от заданных объясняющих переменных. Суть метода наименьших квадратов (мнк). Задача заключается в нахождении коэффициентов линейной зависимости, при которых функция двух переменных а и b принимает наименьшее значение. То есть, при данныха и b сумма квадратов отклонений экспериментальных данных от найденной прямой будет наименьшей. В этом вся суть метода наименьших квадратов. Таким образом, решение примера сводится к нахождению экстремума функции двух переменных. Вывод формул для нахождения коэффициентов. Составляется и решается система из двух уравнений с двумя неизвестными. Находим частные производные функции по переменныма и b, приравниваем эти производные к нулю Предпосылки МНК: 1 - случайный характер остатков; 2 - гомоскедастичность – дисперсия остатков одинакова для всех значений фактора; 3 - отсутствие автокорреляции остатков (то есть остатки распределены независимо друг от друга); 4 - остатки подчиняются нормальному закону распределения. Выполнимость данной предпосылки называется гомоскедастичностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностью (непостоянством дисперсий отклонений) Баланс для сумм квадратов отклонений результативного признака. или Q = Qr + Qe, где Q – общая сумма квадратов отклонений зависимой переменной от средней, Qr и Qe – соответственно, сумма квадратов, обусловленная регрессией, и остаточная сумма квадратов, характеризующая влияние неучтённых факторов. Общая СКО равна факторной, когда прочие факторы не влияют на результат, y связан с x функционально, и остаточная СКО равна нулю. , Нулевая гипотеза принимается, если . Проверка гипотез об общем статистическом качестве модели множественной линейной регрессии. (1) Гипотеза о статистической незначимости коэффициента детерминации . , где – значение критической точки распределения Фишера при уровне значимости и значениях степеней свободы , . (2) Гипотеза о равенстве двух коэффициентов детерминации вложенных моделей. Пусть для выборке из n наблюдений получено уравнение регрессии вида. , (А). и коэффициент детерминации для этой модели равен . Исключим из рассмотрения k экзогенных переменных, предположив, не нарушая общности, что это переменные при последних k коэффициентах Использование критерия Стьюдента для проверки значимости параметров регрессионной модели Проверка статистической значимости параметров регрессионного уравнения (коэффициентов регрессии) выполняется по t-критерию Стьюдента, который рассчитывается по формуле: где P - значение параметра; Sp - стандартное отклонение параметра. Рассчитанное значение критерия Стьюдента сравнивают с его табличным значением при выбранной доверительной вероятности (как правило, 0.95) и числе степеней свободы N-k-1, где N-число точек, k-число переменных в регрессионном уравнении (например, для линейной модели Y=A*X+B подставляем k=1). Если вычисленное значение tp выше, чем табличное, то коэффициент регрессии является значимым с данной доверительной вероятностью. В противном случае есть основания для исключения соответствующей переменной из регрессионной модели. Величины параметров и их стандартные отклонения обычно рассчитываются в алгоритмах, реализующих метод наименьших квадратов. Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. Согласно F-критерию Фишера, выдвигается «нулевая» гипотеза H0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Непосредственному расчету F-критерия предшествует анализ дисперсии. Наблюдаемые значения результативного признака yi можно представить в виде суммы двух составляющих ŷi и εi: yi = ŷi+ εi. Из данного уравнения следует следующее соотношение между дисперсиями наблюдаемых значений переменной D(y), ее расчетных значений D(ŷ) и остатков D(е) (остаточной дисперсией Dост = D(ε))  Статический смысд Коэффициент детерминации - это статистическое измерение, которое исследует, как различия в одной переменной могут быть объяснены различием во второй переменной при прогнозировании исхода данного события. Другими словами, этот коэффициент, более известный как r-квадрат (или r2), оценивает, насколько сильна линейная зависимость между двумя переменными, и на него в значительной степени полагаются инвесторы при проведении анализа тренда. Какова связь между линейным коэффициентом корреляции и коэффициентом регрессии в линейной модели парной регрессии? ⇐ ПредыдущаяСтр 3 из 10 коэффициент детерминации рассчитывается как квадрат линейного коэффициента корреляции r 2. Он характеризует долю дисперсии результативного признака y, объясняемую регрессией, в общей дисперсии результативного признака: 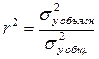 Величина коэффициента детерминации служит одним из критериев оценки качества линейной модели. Чем больше доля объясненной вариации, тем соответственно меньше роль прочих факторов, и, следовательно, линейная модель хорошо аппроксимирует исходные данные и ею можно воспользоваться для прогноза значений результативного признака При линейной регрессии в качестве показателя тесноты связи выступает линейный коэффициент корреляции 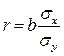 . Коэффициент регрессии показывает, на сколько единиц в среднем изменится У, когда Х увеличивается на одну единицу. Однако он зависит от единиц измерения переменных. Как показателя тесноты связи нужна такая стандартная система единиц измерения, в которой данные по различным характеристикам оказались бы сравнимы между собой. . Коэффициент регрессии показывает, на сколько единиц в среднем изменится У, когда Х увеличивается на одну единицу. Однако он зависит от единиц измерения переменных. Как показателя тесноты связи нужна такая стандартная система единиц измерения, в которой данные по различным характеристикам оказались бы сравнимы между собой. Имеется следующая гипотетическая структурная модель: Y1 = b12Y2 + a11X1 + a12X2 Y2 = b21Y1 + b23Y3 + a22X2 Y3 = b32Y2 + a31X1 + a33X3 Приведенная форма модели имеет вид: Y1 = 3X1 - 6X2 + 2X3 Y2 = 2X1 + 4X2 + 10X3 Y3 = -5X1 + 6X2 +5X3 Требуется проверить структурную форму модели на идентификацию проверить структурную форму модели на идентификацию. Решение: Для того чтобы система одновременных уравнений была идентифицируема, необходимо, чтобы каждое уравнение системы было идентифицируемо, т.е. выполнялись необходимое и достаточное условия идентификации. Необходимое условие идентификации можно записать в виде следующего счетного правила: * если D+1<Н, то уравнение неидентифицируемо; * если D+1=Н, то уравнение идентифицируемо; * если D+1>Н, то уравнение сверхидентифицируемо, где Н - число эндогенных переменных в уравнении; D - число предопределенных переменных, которые содержатся в системе уравнений, но не входят в данное уравнение. Достаточное условие идентификации для данного уравнения выполнено, если определитель полученной матрицы не равен нулю, а ранг матрицы не меньше, чем количество эндогенных переменных в системе без одного. Проверим первое уравнение системы Y1 = b12Y2 + a11X1 + a12X2 на выполнение необходимого и достаточного условия идентификации. В этом уравнении две эндогенные переменные Y1 и Y2 (Н=2). В нем отсутствуют эндогенная переменная Y3 и экзогенная переменная X3 (D=2). Уравнение сверхидентифицируемо, т.к. D+1>H; (3>2), а значит необходимое условие идентификации выполнено. Для проверки на достаточное условие составим матрицу из коэффициентов при переменных Y3 и X3, взятых в других уравнениях.
Определитель полученной матрицы не равен нулю, т.к. b23*a33 - (-1)*0 = 0, а ранг матрицы равен 2. Значит, достаточное условие выполнено, и первое уравнение идентифицируемо. Проверим второе уравнение системы Y2 = b21Y1 + b23Y3 + a22X2 на выполнение необходимого и достаточного условия идентификации. В этом уравнении три эндогенные переменные Y1, Y2 и Y3 (H=3). В нем отсутствуют две экзогенные переменные X1 и X3 (D=2). Уравнение идентифицируемо, т.к. D+1=H; (3=3), а значит необходимое условие идентификации выполнено. , взятых в других уравнениях.
Определитель полученной матрицы не равен нулю, т.к. a11*a33 - a31*0 = 0, а ранг матрицы равен 2. Значит, достаточное условие выполнено, и второе уравнение идентифицируемо. Проверим третье уравнение системы Y3 = b32Y2 + a31X1 + a33X3 на выполнение необходимого и достаточного условия идентификации. В этом уравнении две эндогенные переменные Y2 и Y3 (H=2). В нем отсутствуют эндогенная переменная Y1 и экзогенная переменная X2 (D=2). Уравнение сверхидентифицируемо, т.к. D+1>H; (3>2), а значит необходимое условие идентификации выполнено. Для проверки на достаточное условие составим матрицу из коэффициентов при переменных Y1 и X2, взятых в других уравнениях.
  Задача 1.Зависимость объема продаж (Y) от расходов на рекламу (X) характеризуется по 12 предприятиям концерна следующим образом: 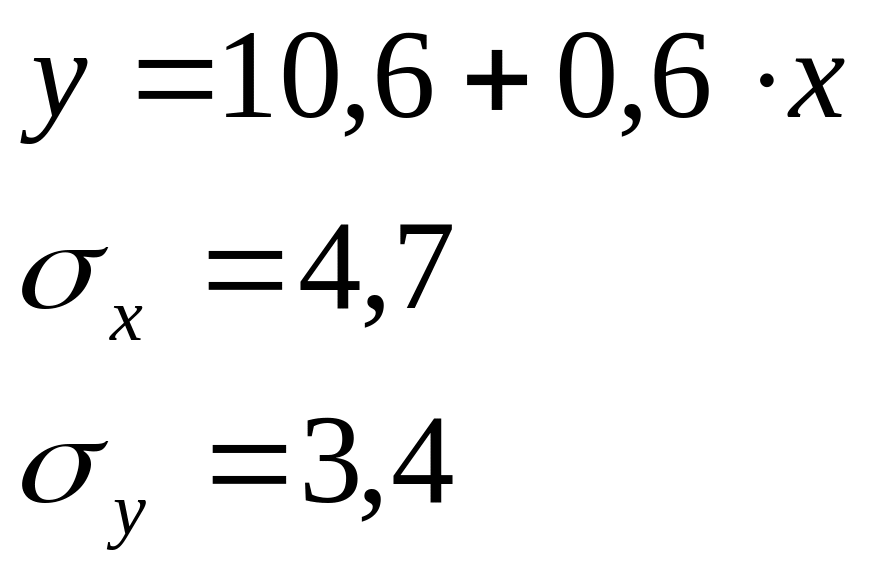 Задание: определите линейный коэффициент парной корреляции, регрессионную сумму квадратов отклонений, постройте таблицу дисперсионного анализа для оценки значимости уравнения в целом, определите F-статистику, t-статистику и доверительный интервал коэффициента регрессии. Решение: Для определения коэффициента корреляции применим формулу: Значение коэффициента корреляции свидетельствует о тесной линейной взаимосвязи между объемом продаж и расходами на рекламу. Коэффициент детерминации составит: Определим регрессионную сумму квадратов отклонений: Составим таблицу дисперсионного анализа и определим F-cтатистику Фишера. Дисперсионный анализ результатов регрессии
Поскольку Fфакт >Fтабл, то признается статистическая значимость, надежность уравнения регрессии. Связь между F-статистикой Фишера, t-статистикой Стьюдента для коэффициента регрессии, t-статистикой Стьюдента для коэффициента корреляции выражается равенством: Значит, Экономическая интерпретация параметров линейной модели парной регрессии.  Экономический смысл свободного коэффициента Параметр а, или свободный коэффициент регрессионного уравнения, имеет экономический смысл: он показывает значение результативного признака y, если факторный x = 0. b — коэффициент регрессии. Показывает, на какую величину в среднем изменится y при увеличении фактора х на 1 единицу.  8.Модели нелинейной регрессии, коэффициент эластичностиСреди нелинейных функций, которые могут быть приведены к линейному виду, в эконометрических исследованиях очень широко используется степенная функция: Связано это с тем, что параметр bв ней имеет четкое экономическое истолкование, т. е. он являетсякоэффициентом эластичности. Это значит, что величина коэффициента bпоказывает, на сколько процентов изменится в среднем результат, если фактор изменится на 1 %. Например, если зависимость спроса от цен характеризуется уравнением вида В силу того, что коэффициент эластичности для нелинейной функции не является величиной постоянной, а зависит от соответствующего значения х, то обычно рассчитывается средний показатель эластичностипо формуле: Поскольку коэффициенты эластичности представляют экономический интерес, а виды моделей не ограничиваются только степенной функцией, приведем формулы расчета коэффициентов эластичности для наиболее распространенных типов уравнений регрессии. Коэффициенты эластичности по разным видам регрессионных моделей. 1.Линейная 2. Парабола 2 порядка 3. Гипербола 4. Показательная 5. Степенная 6. Полулогарифмическая 7. Логистическая 8. Обратная   | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||