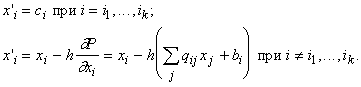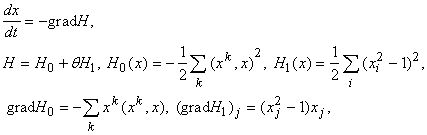История развития нейронных сетей. Httpsfuture2day runejronnyeseti#
 Скачать 1.07 Mb. Скачать 1.07 Mb.
|

|
2. Сети Хопфилда Перейдем от одноэлементных систем к нейронным сетям. Пусть aij ‑ вес связи, ведущей от j-го нейрона к i -му (полезно обратить внимание на порядок индексов). Для полносвязных сетей определены значения aij при всех i ,j, для других архитектур связи, ведущие от j-го нейрона к i -му для некоторых i ,j не определены. В этом случае положим aij=0. В данном разделе речь пойдет в основном о полносвязных сетях. Пусть на выходах всех нейронов получены сигналы xj (j-номер нейрона). Обозначим x вектор этих выходных сигналов. Прохождение вектора сигналов x через сеть связей сводится к умножению матрицы (aij) на вектор сигналов x. В результате получаем вектор входных сигналов нелинейных элементов нейронов: Это соответствие «прохождение сети º умножение матрицы связей на вектор сигналов» является основой для перевода обычных численных методов на нейросетевой язык и обратно. Практически всюду, где основной операцией является умножение матрицы на вектор, применимы нейронные сети. С другой стороны, любое устройство, позволяющее быстро осуществлять такое умножение, может использоваться для реализации нейронных сетей. В частности, вычисление градиента квадратичной формы Что можно сделать, если мы умеем вычислять градиент квадратичной формы? В первую очередь, можно методом наискорейшего спуска искать точку минимума многочлена второго порядка. Пусть задан такой многочлен: Зададим теперь функционирование сети формулой
Нелинейных элементов вовсе не нужно! Каждый (j-й) нейрон имеет входные веса Итак, простая симметричная полносвязная сеть без нелинейных элементов может методом наискорейшего спуска искать точку минимума квадратичного многочлена. Решение системы линейных уравнений Поэтому решение системы может производиться нейронной сетью. Простейшая сеть, вычисляющая градиент этого многочлена, не полносвязна, а состоит из двух слоев: первый с матрицей связей Небольшая модификация позволяет вместо безусловного минимума многочлена второго порядка P искать точку условного минимума с условиями следует использовать:
Устройство, способное находить точку условного минимума многочлена второго порядка при условиях вида Предположим, что получаемые в ходе испытаний векторы данных подчиняются многомерному нормальному распределению: где Mx ‑ вектор математических ожиданий координат, Напомним определение матрицы где M ‑ символ математического ожидания, нижний индекс соответствует номеру координаты. В частности, простейшая оценка ковариационной матрицы по выборке дает:  где m ‑ число элементов в выборке, верхний индекс j ‑ номер вектора данных в выборке, верхний индекс Т означает транспонирование, а Ä ‑ произведение вектора-столбца на вектор-строку (тензорное произведение). Пусть у вектора данных x известно несколько координат: Таким образом, чтобы построить сеть, заполняющую пробелы в данных, достаточно сконструировать сеть для поиска точек условного минимума многочлена На первый взгляд, пошаговое накопление Если же добавка D имеет вид
Заметим, что решение задачи (точка условного минимума многочлена) не меняется при умножении Q на число. Поэтому полагаем: где 1 ‑ единичная матрица, e>0 ‑ достаточно малое число, В формуле для пошагового накопления матрицы Q ее изменение DQ при появлении новых данных получается с помощью вектора y= Описанный процесс формирования сети можно назвать обучением. Вообще говоря, можно проводить формальное различение между формированием сети по явным формулам и по алгоритмам, не использующим явных формул для весов связей (неявным). Тогда термин «обучение» предполагает неявные алгоритмы, а для явных остается название «формирование». Здесь мы такого различия проводить не будем. Если при обучении сети поступают некомплектные данные Во всех задачах оптимизации существенную роль играет вопрос о правилах остановки: когда следует прекратить циклическое функционирование сети, остановиться и считать полученный результат ответом? Простейший выбор ‑ остановка по малости изменений: если изменения сигналов сети за цикл меньше некоторого фиксированного малого d (при использовании переменного шага d может быть его функцией), то оптимизация заканчивается. До сих пор речь шла о минимизации положительно определенных квадратичных форм и многочленов второго порядка. Однако самое знаменитое приложение полносвязных сетей связано с увеличением значений положительно определенных квадратичных форм. Речь идет о системах ассоциативной памяти [4-7,9,10,12]. Предположим, что задано несколько эталонных векторов данных
где h ‑ малый шаг, приведет к увеличению проекции x на те эталоны, скалярное произведение на которые Ограничимся рассмотрением эталонов, и ожидаемых результатов обработки с координатами
где верхними индексами обозначаются номера векторов-эталонов, нижними ‑ координаты векторов. Функция H называется «энергией» сети, она минимизируется в ходе функционирования. Слагаемое Подробнее системы ассоциативной памяти рассмотрены в отдельной главе. Здесь же мы ограничимся обсуждением получающихся весов связей. Матрица связей построенной сети определяется функцией
Эта простая формула имеет чрезвычайно важное значение для развития теории нейронных сетей. Вклад k-го эталона в связь между i -м и j-м нейронами ( В результате возбуждение i -го нейрона передается j-му (и симметрично, от j-го к i -му), если у большинства эталонов знак i -й и j-й координат совпадают. В противном случае эти нейроны тормозят друг друга: возбуждение i -го ведет к торможению j-го, торможение i -го ‑ к возбуждению j-го (воздействие j-го на i -й симметрично). Это правило образования ассоциативных связей (правило Хебба) сыграло огромную роль в теории нейронных сетей. |