История развития нейронных сетей. Httpsfuture2day runejronnyeseti#
 Скачать 1.07 Mb. Скачать 1.07 Mb.
|

|
3. Сети Кохонена для кластер-анализа и классификации без учителя Построение отношений на множестве объектов - одна из самых загадочных и открытых для творчества областей применения искусственного интеллекта. Первым и наиболее распространенным примером этой задачи является классификация без учителя. Задан набор объектов, каждому объекту сопоставлен вектор значений признаков (строка таблицы). Требуется разбить эти объекты на классы эквивалентности. Естественно, прежде, чем приступать к решению этой задачи, нужно ответить на один вопрос: зачем производится это разбиение и что мы будем делать с его результатом? Ответ на него позволит приступить к формальной постановке задачи, которая всегда требует компромисса между сложностью решения и точностью формализации: буквальное следование содержательному смыслу задачи нередко порождает сложную вычислительную проблему, а следование за простыми и элегантными алгоритмами может привести к противоречию со здравым смыслом. Итак, зачем нужно строить отношения эквивалентности между объектами? В первую очередь - для фиксации знаний. Люди накапливают знания о классах объектов - это практика многих тысячелетий, зафиксированная в языке: знание относится к имени класса (пример стандартной древней формы: "люди смертны", "люди" - имя класса). В результате классификации как бы появляются новые имена и правила их присвоения. Для каждого нового объекта мы должны сделать два дела: найти класс, к которому он принадлежит; использовать новую информацию, полученную об этом объекте, для исправления (коррекции) правил классификации. Какую форму могут иметь правила отнесения к классу? Веками освящена традиция представлять класс его "типичным", "средним", "идеальным" и т.п. элементом. Этот типичный объект является идеальной конструкцией, олицетворяющей класс. Отнесение объекта к классу проводится путем его сравнения с типичными элементами разных классов и выбора ближайшего. Правила, использующие типичные объекты и меры близости для их сравнения с другими, очень популярны и сейчас. Простейшая мера близости объектов - квадрат евклидового расстояния между векторами значений их признаков (чем меньше расстояние ‑ расстояние - тем ближе объекты). Соответствующее определение признаков типичного объекта - среднее арифметическое значение признаков по выборке, представляющей класс. Мы не оговариваем специально существование априорных ограничений, налагаемых на новые объекты - естественно, что "вселенная" задачи много 'уже и гораздо определеннее Вселенной. Другая мера близости, естественно возникающая при обработке сигналов, изображений и т.п. - квадрат коэффициента корреляции (чем он больше, тем ближе объекты). Возможны и иные варианты - все зависит от задачи. Если число классов m заранее определено, то задачу классификации без учителя можно поставить следующим образом. Пусть {xp } - векторы значений признаков для рассматриваемых объектов и в пространстве таких векторов определена мера их близости r{x,y}. Для определенности примем, что чем ближе объекты, тем меньше r. С каждым классом будем связывать его типичный объект. Далее называем его ядром класса. Требуется определить набор из m ядер y1 , y2 , ... ym и разбиение {xp} на классы: минимизирующее следующий критерий
где для каждого (i -го) класса
Минимум Q берется по всем возможным положениям ядер Если число классов заранее не определено, то полезен критерий слияния классов: классы Y i и Yj сливаются, если их ядра ближе, чем среднее расстояние от элемента класса до ядра в одном из них. (Возможны варианты: использование среднего расстояния по обоим классам, использование порогового коэффициента, показывающего, во сколько раз должно расстояние между ядрами превосходить среднее расстояние от элемента до ядра и др.) Использовать критерий слияния классов можно так: сначала принимаем гипотезу о достаточном числе классов, строим их, минимизируя Q, затем некоторые Y i объединяем, повторяем минимизацию Q с новым числом классов и т.д. Существует много эвристических алгоритмов классификации без учителя, основанных на использовании мер близости между объектами. Каждый из них имеет свою область применения, а наиболее распространенным недостатком является отсутствие четкой формализации задачи: совершается переход от идеи кластеризации прямо к алгоритму, в результате неизвестно, что ищется (но что-то в любом случае находится, иногда - неплохо). Сетевые алгоритмы классификации без учителя строятся на основе итерационного метода динамических ядер. Опишем его сначала в наиболее общей абстрактной форме. Пусть задана выборка предобработанных векторов данных {xp}. Пространство векторов данных обозначим E. Каждому классу будет соответствовать некоторое ядро a. Пространство ядер будем обозначать A. Для каждых xÎE и aÎA определяется мера близости d(x,a). Для каждого набора из k ядер a1,...,ak и любого разбиения {xp} на k классов {xp}=P1ÈP2È...ÈPk определим критерий качества:
Требуется найти набор a1,...,ak и разбиение {xp}=P1ÈP2È...ÈPk, минимизирующие D. Шаг алгоритма разбивается на два этапа: 1-й этап - для фиксированного набора ядер a1,...,ak ищем минимизирующее критерий качества D разбиение {xp}=P1ÈP2È...ÈPk; оно дается решающим правилом: xÎP i, если d(x,a i )<d(x ,aj ) при i ¹j, в том случае, когда для x минимум d(x,a) достигается при нескольких значениях i , выбор между ними может быть сделан произвольно; 2-й этап - для каждого P i (i =1,...,k), полученного на первом этапе, ищется a iÎA, минимизирующее критерий качества (т.е. слагаемое в D для данного i - Начальные значения a1,...,ak, {xp}=P1ÈP2È...ÈPk выбираются произвольно, либо по какому-нибудь эвристическому правилу. На каждом шаге и этапе алгоритма уменьшается критерий качества D, отсюда следует сходимость алгоритма - после конечного числа шагов разбиение {xp}=P1ÈP2È...ÈPk уже не меняется. Если ядру a i сопоставляется элемент сети, вычисляющий по входному сигналу x функцию d(x,a i), то решающее правило для классификации дается интерпретатором "победитель забирает все": элемент x принадлежит классу P i, если выходной сигнал i -го элемента d(x,a i) меньше всех остальных Единственная вычислительная сложность в алгоритме может состоять в поиске ядра по классу на втором этапе алгоритма, т.е. в поиске aÎA, минимизирующего В связи с этим, в большинстве конкретных реализаций метода мера близости d выбирается такой, чтобы легко можно было найти a, минимизирующее D для данного P . В простейшем случае пространство ядер A совпадает с пространством векторов x, а мера близости d(x,a) - положительно определенная квадратичная форма от x‑a, например, квадрат евклидового расстояния или другая положительно определенная квадратичная форма. Тогда ядро a i, минимизирующее D i, есть центр тяжести класса P i :
где |P i| ‑ число элементов в P i. В этом случае также упрощается и решающее правило, разделяющее классы. Обозначим d(x,a)=(x-a,x-a), где (.,.) ‑ билинейная форма (если d - квадрат евклидового расстояния между x и a, то (.,.) - обычное скалярное произведение). В силу билинейности d(x,a)=(x‑a,x‑a)=(x,x)‑2(x,a)+(a,a). Чтобы сравнить d(x,a i) для разных i и найти среди них минимальное, достаточно вычислить линейную неоднородную функцию от x: d1(x,a i) = (a i,a i)‑2(x,a i). Минимальное значение d(x,a i) достигается при том же i , что и минимум d1(x,a i), поэтому решающее правило реализуется с помощью k сумматоров, вычисляющих d(x,a) и интерпретатора, выбирающего сумматор с минимальным выходным сигналом. Номер этого сумматора и есть номер класса, к которому относится x. Пусть теперь мера близости - коэффициент корреляции между вектором данных и ядром класса: 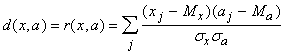 где 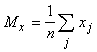 (и аналогично ), n ‑ размерность пространства данных, (и аналогично ). (и аналогично ), n ‑ размерность пространства данных, (и аналогично ).Предполагается, что данные предварительно обрабатываются (нормируются и центрируются) по правилу: . Точно также нормированы и центрированы векторы ядер a. Поэтому все обрабатываемые векторы и ядра принадлежат сечению единичной евклидовой сферы (||x||=1) гиперплоскостью ( ). В таком случае . Задача поиска ядра для данного класса P имеет своим решением
В описанных простейших случаях, когда ядро класса точно определяется как среднее арифметическое (или нормированное среднее арифметическое) элементов класса, а решающее правило основано на сравнении выходных сигналов линейных адаптивных сумматоров, нейронную сеть, реализующую метод динамических ядер, называют сетью Кохонена. В определении ядер a для сетей Кохонена входят суммы . Это позволяет накапливать новые динамические ядра, обрабатывая по одному примеру и пересчитывая ai после появления в P i нового примера. Сходимость при такой модификации, однако, ухудшается. Закончим раздел рассмотрением различных способов использования полученных классификаторов. 1. Базовый способ: для вектора данных x i и каждого ядра a i вычисляется y i=d(x,a i) (условимся считать, что правильному ядру отвечает максимум d, изменяя, если надо,знак d); по правилу «победитель забирает все» строка ответов y i преобразуется в строку, где только один элемент, соответствующий максимальному y i, равен 1, остальные ‑ нули. Эта строка и является результатом функционирования сети. По ней может быть определен номер класса (номер места, на котором стоит 1) и другие показатели. 2. Метод аккредитации: за слоем элементов базового метода, выдающих сигналы 0 или 1 по правилу "победитель забирает все" (далее называем его слоем базового интерпретатора), надстраивается еще один слой выходных сумматоров. С каждым (i -м) классом ассоциируется q-мерный выходной вектор z i с координатами z ij . Он может формироваться по-разному: от двоичного представления номера класса до вектора ядра класса. Вес связи, ведущей от i -го элемента слоя базового интерпретатора к j-му выходному сумматору определяется в точности как z ij . Если на этом i -м элементе базового интерпретатора получен сигнал 1, а на остальных - 0, то на выходных сумматорах будут получены числа z ij. 3. Нечеткая классификация. Пусть для вектор данных x обработан слоем элементов, вычисляющих y i=d(x,a i). Идея дальнейшей обработки состоит в том, чтобы выбрать из этого набора {y i} несколько самых больших чисел и после нормировки объявить их значениями функций принадлежности к соответствующим классам. Предполагается, что к остальным классам объект наверняка не принадлежит. Для выбора семейства G наибольших y i определим следующие числа: где число a характеризует отклонение "уровня среза" s от среднего значения aÎ[-1,1], по умолчанию обычно принимается a=0. Множество J={i |y iÎG} трактуется как совокупность номеров тех классов, к которым может принадлежать объект, а нормированные на единичную сумму неотрицательные величины (при i ÎJ и f = 0 в противном случае) интерпретируются как значения функций принадлежности этим классам. 4. Метод интерполяции надстраивается над нечеткой классификацией аналогично тому, как метод аккредитации связан с базовым способом. С каждым классом связывается q-мерный выходной вектор z i. Строится слой из q выходных сумматоров, каждый из которых должен выдавать свою компоненту выходного вектора. Весовые коэффициенты связей, ведущих от того элемента нечеткого классификатора, который вычисляет fi, к j-му выходному сумматору определяются как z ij. В итоге вектор выходных сигналов сети есть В отдельных случаях по смыслу задачи требуется нормировка fi на единичную сумму квадратов или модулей. Выбор одного из описанных четырех вариантов использования сети (или какого-нибудь другого) определяется нуждами пользователя. Предлагаемые четыре способа покрывают большую часть потребностей. Програмное обеспечение, системное обеспечение NeuroPro Программа NeuroPro 0.25 является свободно распространяемой бета-версией разрабатываемого программного продукта для работы с нейронными сетями и производства знаний из данных с помощью обучаемых искусственных нейронных сетей. Главное окно программы приведено на рис. 1.13. 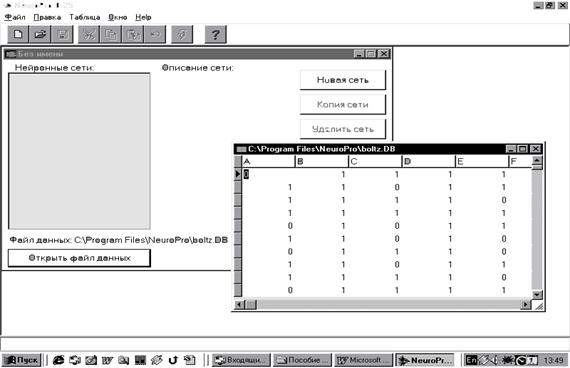 Рис. 1.13. Главное окно программы Требования к аппаратуре: - Процессор Intel Pentium. - Монитор SVGA с разрешением 800*600 точек и выше. - Операционная система Microsoft Windows 95 или Microsoft Windows NT 4.0. Основные возможности программы: 1. Создание нейропроекта (см. рис. 1.13: «Файл» — «Создать»). 2. Подключение к нейропроекту файла (базы) данных (см. рис. 1.13: «Открыть файл данных»). В качестве файлов данных (содержащих обучающую выборку для нейронных сетей) используются файлы форматов DBF (форматы пакетов Dbase, FoxBase, FoxPro, Clipper) и DB (Paradox). Возможно чтение и редактирование этих файлов, и сохранение измененных файлов на диске. Программа не накладывает ограничений на число записей (строк) в файле данных. 3. Редактирование файла данных и создание нейронной сети. Встроенные возможности нейроимиатора по редактированию файлов данных достаточно ограничены. Для внесения изменений в файл данных целесообразно воспользоваться табличным процессором MS Excel с последующим сохранением файла в формате DBF 4, который читается программой Neuropro 0.25 (см. таблицу данных на рис. 1.13). Добавление в нейропроект нейронной сети слоистой архитектуры с числом слоев нейронов от 1 до 10, числом нейронов в слое – до 100 (число нейронов для каждого слоя сети может задаваться отдельно). Для создания новой сети необходимо щелкнуть по кнопке «Новая сеть», которая находится за таблицей данных и становится активной после открытия файла данных (рис. 1.14). 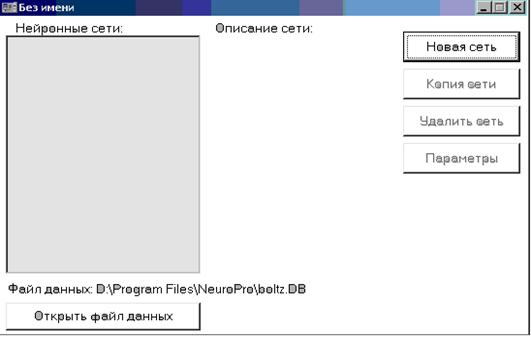 Рис. 1.14. Создание нейронной сети 4. Выбор алгоритма обучения, назначение требуемой точности прогноза, настройка параметров нейронной сети. Обучение нейронной сети на некотором задачнике производится градиентными методами оптимизации, градиент вычисляется по принципу двойственности. В программе реализованы четыре алгоритма оптимизации: - Градиентный спуск. - Модифицированный ParTan. - Метод сопряженных градиентов. - Квазиньютоновский BFGS-метод. При создании нейропроекта в качестве алгоритма по умолчанию принимается ParTan. Изменение алгоритма осуществляется через пункты меню «Настройка» — «Метод оптимизации». Примеру задачника соответствует запись (строка) файла данных. Для включения записи файла данных в задачник в записи должны присутствовать данные для всех полей, используемых нейронной сетью в качестве входных и выходных. Обучение прекращается при достижении заданной точности решения задачи либо при невозможности дальнейшей оптимизации. Програмное обеспечение, системное обеспечение SimInTech SimInTech — российская система модельно-ориентированного проектирования систем автоматического управления (САУ). Программное обеспечение SimInTech состоит из графической среды разработки и исполнительной системы реального времени NordWind. SimInTech — среда создания математических моделей, алгоритмов управления, интерфейсов управления и автоматической генерации кода для программируемых контроллеров и графических дисплеев. NordWind — исполнительная система реального времени, которая позволяет запускать сформированные алгоритмы на контроллере. Может:* использоваться для моделирования нестационарных процессов в физике, в электротехнике, в динамике машин и механизмов, в астрономии и т. д., а также для решения нестационарных краевых задач (теплопроводность, гидродинамика и др.);* функционировать в многокомпьютерных моделирующих комплексах, в том числе и в системах удаленного доступа к технологическим и информационным ресурсам;* функционировать как САПР при групповой разработке и сопровождении жизненного цикла изделия (проекта) при модельно-ориентированном подходе к проектированию.Не имеет аналогов среди отчественного программного обеспечения; за рубежом аналогами SimInTech являются такие программным продукты как SimuLink, MATRIX, VisSim, Esterel SCADE, Amesim, DYMOLA, SimulationX и некоторые другие. |
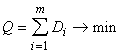 .
.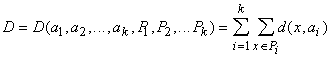
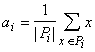 ,
,