бд полный курс. Информация, данные, информационные системы Информация как социальный ресурс
 Скачать 1.56 Mb. Скачать 1.56 Mb.
|

|
Сетевая модель данных Остановимся на понятии сетевой структуры, положенной в основу сетевой модели данных. Рассмотрим отношение между следующими объектами: Студенческий коллектив, Студенческая группа, Комната в общежитии и Студент. Взаимосвязь между этими объектами не является иерархической, так как порожденный элемент Студент имеет два исходных - Студенческая группа и Комната в общежитии. Такие отношения, когда порожденный элемент имеет более одного исходного, описываются в виде сетевой структуры. В такой структуре любой элемент может быть связан с любым другим элементом. Как и в случае иерархической модели, сетевую структуру можно описать в терминах исходных и порождаемых узлов, а также представить ее таким образом, чтобы порожденные узлы располагались ниже исходных. При рассмотрении некоторых сетевых структур можно говорить об уровнях. Так, рассмотренная выше сетевая структура имеет три уровня. Рассмотрим, как в сетевой модели будут представлены взаимосвязи между объектами. В нашем примере присутствуют два вида взаимосвязей: 1:M (Учебная группа - Студент) и M:1 (Студент - Комната в общежитии). Сетевые структуры, которые имеют такие связи между исходными и порожденными узлами, порожденными и исходными узлами, относят к простым сетевым структурам. Сложной сетевой структурой называют такую структуру, в которой присутствует хотя бы одна связь типа N:M. Примером такой связи является отношение Студент - Преподаватель. Такое разделение сетевых структур обусловлено технологическими сложностями реализации взаимосвязи N:M. Причем некоторые СУБД не обрабатывают сложных сетевых структур ( СЕТОР, DNS, DBMS ). База данных с сетевой структурой состоит из нескольких областей. Каждая область состоит из записей, которые состоят из полей. Объединение записей в логическую структуру возможно не только по областям, но и с помощью наборов данных. По существу набор данных - это поименованное двухуровневое дерево, которое является основой для построения многоуровневых деревьев. Сама база данных состоит из некоторой совокупности наборов данных. Набор данных - это экземпляр поименованной совокупности записей. Каждый тип набора представляет собой отношение между двумя или несколькими типами записей. Для каждого набора данных один тип записи может быть объявлен владельцем, а один или несколько типов других записей - членами набора. Набор данных, например, можно использовать для объединения записей о студентах одной группы. Тогда тип набора можно определить как состав группы с типом записи владельца. Например, Учебная группа с типом записей членов Студент: Учебная группа (запись-владельца) - Студент (совокупность записей о сту дентах в данной группе). Набор данных имеет следующие свойства: Набор данных есть поименованная совокупность связанных записей. В каждом экземпляре набора данных имеется только один экземпляр записи владельца. Экземпляр набора может содержать 0,1 или несколько записей-членов. Набор данных считается пустым, если ни один экземпляр записи-члена не связан с соответствующим экземпляром записи владельца. Экземпляр набора данных связан с записью владельца. Тип набора предполагает логическую взаимосвязь 1:M между владельцем и членом набора. Каждому типу набора данных присваивается имя, которое позволяет одной и той же паре типов объектов участвовать в нескольких взаимосвязях. Необходимо различать тип и экземпляр набора. Предварительно поясним различие между понятиями "тип" и "экземпляр" записи. Например, Студент является типом записи, а строка, содержащая информацию о конкретном студенте, является экземпляром типа записи Студент. Аналогичное различие существует между типом и экземпляром набора данных. Например, тип набора Состав группы, а его экземпляр содержит один экземпляр типа записи владельца Учебная группа и N экземпляров типа записи-члена Студент. Определенный экземпляр типа записи-члена не может одновременно принадлежать более чем одному экземпляру типа записи-владельца. Уникальность владельца типа набора является обязательным элементом сетевой модели данных. С этой точки зрения иерархическая модель является частным случаем сетевой модели данных. Концепция сетевой модели данных связана с именем Ч. Бахмана, известного специалиста в области обработки данных, который оказал определяющее влияние на создание проекта DBTG CODASYL (1971 год). Сетевая модель данных является моделью объектов-связей, где допускаются только бинарные связи типа "многие-к-одному", что позволяет использовать для представления данных простую модель ориентированных графов. В некоторых определениях сетевой модели допускаются связи типа "многие-ко-многим", но требование бинарности связи остается в силе. Для сетевой модели не существует общепринятой терминологии. Далее используется сложившая к настоящему времени группа понятий и терминов, которые используются для описания элементов сетевой модели. Для моделирования представления данных в сетевой модели используются следующие элементы данных: простое поле (элемент данных, итем) - наименьшая единица структуры данных, имеет уникальное имя, размер и тип: (табельный номер служащего); множественное поле (агрегат данных, периодическая группа) - поименованная совокупность простых полей или агрегатов; (простой агрегат: Дата = (день, месяц, год)), (составной агрегат: Организация = (наименование, адрес = (почтовый_индекс, город, улица, дома_номер))), (повторяющаяся группа: зарплата (12) = (ФИО, оклад)); запись (группа данных) - поименованный агрегат, который не входит в состав никакого другого агрегата и представляет сущность ПО БД (тип записи); групповое отношение (связь, набор) - иерархическое отношение между различными записями (графическое представление группового отношения в сетевой модели называется диаграммой Бахмана); БД - совокупность записей различного типа, объединенная системой групповых отношений различной направленности. На рис. 1.9 приведен фрагмент описания схемы БД (описание статьи записи) на примере записи из БД "Кадры", предназначенной для автоматизации работы отдела кадров организации. Для описания записи используется язык описания данных СODASYL. Описание схемы БД в CODASYL состоит из четырех статей: статья схемы: SCHEMA NAME IS Имя_схемы ; статья областей: AREA NAME IS Имя_области (файла) ; статья записи: RECORD NAME IS Имя_записи - способ выборки ; статья выбора: SET NAME IS Имя_набора ; способ включения экземпляров записей (устанавливает групповые отношения в БД).  Рис. 1.9. Описание записи в сетевой модели данных Элементы данных сетевой модели допускают обработку следующими операциями, множество которых составляет язык манипулирования данными: ЗАПОМНИТЬ - заносит экземпляр записи в БД и включает его в существующее отношение; ПРИСОЕДИНИТЬ - связывает существующие записи в групповое отношение и определяет подчинение записей (родитель-потомок); ПЕРЕКЛЮЧИТЬ - связывает экземпляр подчиненной записи с другим экземпляром записи-родителя; МОДИФИЦИРОВАТЬ - изменяет значение полей в существующих записях БД, перед выполнением этой операции запись должна быть извлечена из БД; НАЙТИ - находит записи из БД согласно критерию поиска; УДАЛИТЬ - удаляет из БД ненужную запись; ОТДЕЛИТЬ - разрывает существующую связь между записями в групповом отношении; ПОЛУЧИТЬ - извлекает записи из БД. В модели CODASYL существует набор дополнительных операций по обслуживанию БД, который здесь не рассматривается. Очень часто к недостаткам сетевого подхода в БД относят как сложность самой модели данных, так и сложность освоения средств манипулирования данными в ней. Практически, при анализе ПО БД и программировании особенно тщательно приходится отлеживать цепочки связанных групповыми отношениями данных при операциях вставки, обновления и удаления. Однако действительный источник сложности сетевой модели данных состоит в диапазоне предоставляемых моделью конструкций для представления информации и набора операции для манипулирования этими конструкциями. Модели вычислений Взгляд на использование компьютеров меняется в процессе их применения в различных сферах человеческого труда: большие вычислительные центры с мощными компьютерами, средние по мощности ЭВМ для автоматизации технологических процессов, персональные компьютеры, компьютеры, объединенные сетью коммуникаций. Неизменным остается требование пользователей к вычислительным ресурсам для удовлетворения потребностей в информации - время процессора (быстродействие), оперативная память, дисковое пространство и т.п. Проблема совместного использования ресурсов является одной из ключевых проблем решения любых прикладных задач на ЭВМ, в том числе и создания ИС. Решение этой проблемы приводит к разработке новых компьютерных технологий, которые являются сложным синтезом изменений в аппаратном и программном обеспечении. Основой таких модификаций как аппаратного, так и программного обеспечения являются модели вычислений. Что принято понимать под моделью вычислений? Обычно под моделью вычислений подразумевают совокупность аппаратно-программных средств, схему их взаимодействия между собой и пользователями, т.е. постулируется ответ на вопросы, каким образом и какие вычислительные ресурсы используются в процессе выполнения вычислений. Поскольку понятие модели вычислений связано как и с аппаратным, так и с программным обеспечением, то нередко в качестве синонима слова модель используется слово архитектура. За всю историю развития вычислительной техники было предложено не так уж много моделей вычислений. Централизованные вычисления: модель вычислений с использованием централизованной хост-ЭВМ; модель с автономными персональными вычислениями; Распределенные вычисления: модель вычислений "файл-сервер" ; модель вычислений "клиент-сервер" ; модель "вычисление по требованию". Исторически одной из первых моделей вычислений является модель с использованием централизованной хост-ЭВМ. В такой схеме вычислений пользователь получает доступ к вычислительным ресурсам ЭВМ через сеть неинтеллектуальных терминалов (т.е. терминалов, не обладающих никакими вычислительными возможностями). Центральный компьютер полностью отвечает за взаимодействие с пользователем и управление данными в многопользовательской среде. Преимуществом такой модели вычислений является их централизация. Централизованные системы позволяют совместно использовать вычислительные ресурсы (диски, принтеры, оперативную память) с высокой эффективностью, а также обеспечивать высокую надежность и актуальность хранимых данных. Самым большим недостатком такой схемы вычислений является линейная зависимость вычислительной мощности центральной ЭВМ от числа пользователей и, как следствие, высокая стоимость аппаратуры и программного обеспечения. Несмотря на устойчивую тенденцию снижения стоимости оборудования, такие системы по-прежнему остаются одними из дорогостоящих (отношение "цена/производительность" остается достаточно высокой). В 80-е годы прошлого века появились персональные компьютеры и рабочие станции. Независимые друг от друга, предоставляющие вычислительные возможности, которые сопоставимы с большими ЭВМ, доступные по цене широкому кругу потребителей (отношение "цена/производительность" в данном случае гораздо ниже, чем при использовании больших ЭВМ). Персональные компьютеры положили конец централизованному подходу в обработке данных и обозначили переход к распределенным вычислениям. Преимуществом такой модели вычислений является их автономность в использовании вычислительных ресурсов, т.е. централизованное использование компьютера, но на рабочем месте и независимо от других таких же компьютеров. В данном случае можно подобрать персональный компьютер адекватно решаемому кругу задач. Однако у независимых персональных вычислений есть и свои проблемы. Эти проблемы порождают распределенность данных (невозможность совместной работы с данными различных пользователей) по персональным компьютерам в случае, когда эти данные должны использоваться совместно в рамках одной организации. При этом выигрыш в отношении "цена/производительность" компенсируется потерями в производительности труда коллективов, работающих с распределенными таким образом данными. Проблемы совместного использования данных, расположенных на персональных компьютерах, привели к разработке концепции локальной вычислительной сети, которая восстанавливает преимущества коллективных вычислений и сохраняет простоту использования персональных компьютеров. Наличие вычислительной сети компьютеров характерно для всех моделей распределенных вычислений. Модель вычислений "файл-сервер" (или архитектура "файл-сервер") основывается на понятии сервера. Термин сервер имеет двойственный смысл. С одной стороны, сервер есть узел вычислительной сети (компьютер с сети), предназначенный для предоставления совместно используемых ресурсов и услуг, а с другой - программный компонент, предоставляющий общий функциональный сервис другим программным компонентам вычислительной сети. Файловый сервер является обычно центральным узлом сети, на котором хранятся файлы коллективного пользования и который является также концентратором совместно используемых периферийных устройств (например, принтера или дискового накопителя большой емкости). Файловый сервер не принимает участия в обработке приложения. Он выполняет сетевой транспорт совместно используемых данных (часто пересылая файл целиком конечному пользователю). Преимуществом такой модели является, несомненно, корпоративное использование территориально распределенных вычислительных ресурсов, имеющее одним из своих следствий создание глобальных вычислительных систем и новых технологий обмена информацией. Однако у такой модели есть два крупных недостатка при разработке многопользовательских приложений. Интенсивный обмен данными (рост трафика сети) приводит к быстрому достижению ее пропускной способности и тем самым к снижению (из-за увеличения времени реакции приложения за счет времени ожидания) производительности многопользовательской системы. Другая проблема - это обеспечение согласованности данных, т.е. одновременного разделения доступа к одним и тем же данным группой пользователей. Обычно файл блокируется для других пользователей, когда его начинает обрабатывать приложение. В случае, когда часть файла реплицируется на конечный узел для обработки, снижается актуализация данных, что может быть неприемлемо для систем оперативной обработки информации. Модель вычислений "клиент-сервер" явилась следующим шагом в развитии распределенных вычислений, объединив в себе преимущества коллективных вычислений в сети компьютеров с доступом к совместно используемым данным и высокие характеристики производительности вычислений с центральной ЭВМ. Основными понятиями данной модели являются сервер баз данных, клиентское приложение и сеть. Основное назначение сервера баз данных - оптимальное управление разделяемыми ресурсами на уровне данных для множества клиентов. На этом уровне достаточно эффективно решаются задачи обеспечения согласованности данных, их актуальности, защиты и целостности. Клиентское приложение является частью системы, которая обеспечивает интерфейс приложения с серверов баз данных. Логика приложения может быть полностью реализована на клиентской части системы, а обработку данных забирает на себя сервер баз данных. Сеть и коммуникационное программное обеспечение являются средствами передачи данных. Реализация этой компоненты модели обеспечивает прозрачность сервера баз данных по отношению к клиенту. 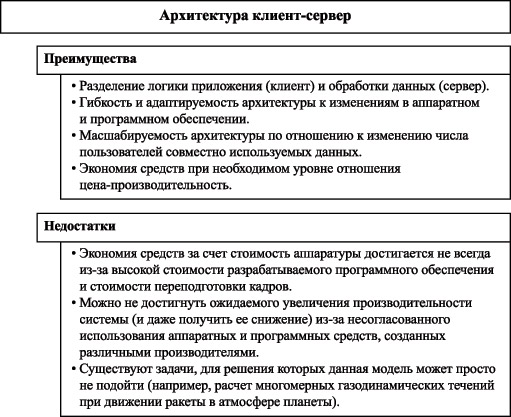 Рис. 1.10. Преимущества и недостатки модели вычислений "клиент-сервер" Несмотря на то, что модель вычислений "клиент-сервер" является высокопроизводительной распределенной моделью вычислений, она, помимо очевидных преимуществ, имеет присущие ей недостатки (рис. 1.10). Кроме того, другие модели вычислений также продолжают развиваться, обеспечивая приемлемые значения отношения "цена-производительность". Модель "вычисления по требованию" или GRID является в настоящее время одной из перспективных распределенных моделей вычислений. Суть ее состоит в использовании вычислительных ресурсов, расположенных в локальной или глобальной вычислительной сети, аналогично тому, как мы в быту используем электричество, совершенно не отдавая себе отчета в том, с какой электростанции оно поступает к нам в дом. В этой модели вычислений заявленные в сети GRID вычислительные ресурсы (компьютеры или кластеры ЭВМ) предоставляют свои свободные вычислительные ресурсы согласно правилам обслуживания заданий в очереди. Таким образом, находясь в России, вы можете запустить свою задачу на компьютере в Австралии, совершенно об этом не зная. В этой лекции мы рассмотрели ряд основных понятий и терминов, которые потребуются проектировщику реляционных баз данных в процессе решения им своих профессиональных задач. В последующих лекциях мы последовательно и детально рассмотрим основные профессиональные задачи проектировщика реляционных баз данных. |