бд полный курс. Информация, данные, информационные системы Информация как социальный ресурс
 Скачать 1.56 Mb. Скачать 1.56 Mb.
|

|
Рис. 1.5. Основные функции СУБД Определение 4. Системой управления базами данных (Data-base Management System) называется совокупность программных средств, необходимых для использования базы данных и предоставляющих разработчикам и пользователям множество различных представлений данных. Модели данных Понятие о модели данных В предыдущих разделах все время подчеркивалась роль представления данных в решении задач обработки информации (принцип независимости программ от данных, концепция баз данных и т.д.). Представление информации с помощью данных требует унифицированного подхода к понятию данных как независимого объекта моделирования. Поэтому для разработчика ИС выбор соответствующей модели данных является одной из самых важных проблем. Выбор модели данных влечет за собой выбор средств анализа предметной области (ПО БД) как сферы реального мира, подлежащего изучению и обработке средствами ВТ, - об этом мы будем говорить в следующей лекции. В конечном счете такой выбор делает разработчика "заложником" той или иной информационной технологии создания информационных систем с базами данных. Модель данных ограничивает возможность выбора СУБД, так как обычно отдельно взятая модель поддерживает определенную модель данных. Модель данных определяет и методы создания дружественного интерфейса пользователя за счет средств СУБД (особенности конкретной реализации модели (замкнутость на свою среду), иногда весьма существенные, ибо коммерческие интересы фирм - разработчиков СУБД вступают в противоречие с требованиями рынка информационных услуг). Модель данных требует приведения представлений пользователя о данных и результатах их обработки к определенному уровню понимания, что может повлечь за собой необходимость обучения пользователя методам и средствам работы с данными (необходимость использования моделей высокого уровня для описания семантики предметной области информационной системы, желательно возможностью использования средств реинжиниринга). Таким образом, понятие модели данных является одним из фундаментальных понятий информатики, от которого во многом зависят механизмы реализации ИС как программно-аппаратного комплекса. Что же такое модели данных? В самом общем случае модель данных - это логическое представление данных и совокупность операций над ними. Определение 5. Модель данных ( Data Model ) есть логическая структура данных, которая представляет присущие этим данным свойства, не зависимые от аппаратного и программного обеспечения и не связанные с функционированием компьютера. Можно рассмотреть несколько аспектов моделирования в обработке данных: информационное моделирование: концептуальное моделирование (моделирование семантики предметной области); логическое моделирование данных; физическое моделирование: создание моделей доступа к данным; оптимизация физической организации данных в аппаратной среде. Физическая модель определяется особенностями устройств хранения информации и связи. Поскольку мы в наших лекциях не занимаемся разработкой методов доступа и СУБД, то вопросы физического моделирования данных рассматриваться не будут. Информационная модель данных На рис. 1.6 иллюстрируется общее содержание понятия модели данных, сложившееся к настоящему времени.  Рис. 1.6. Представление об информационной модели данных Объектами информационной модели являются сущности реального мира из предметной области. Иногда их называют итемами, чтобы подчеркнуть их целостность. Свойства объектов (сущностей) называют атрибутами. Сущности вступают в связи друг с другом через свои атрибуты. Эти три компонента информационной модели представляют субъективные средства описания модели, которые после определенной формализации дают внешнюю схему данных БД ИС. Концепция трех схем В рамках информационного моделирования существует несколько точек зрения (схем) на абстрагирование данных. С точки зрения пользователя (называемой внешней схемой), определение данных представляется в контексте языка предметной области. Структура данных и содержание меняется в зависимости от сферы деятельности и особенностей конкретного пользователя. С точки зрения компьютера (называемой внутренней схемой), данные определяются в терминах файловых структур для хранения и поиска. Структура данных в этом случае зависит от конкретной компьютерной технологии и от требований эффективности обработки данных. При моделировании информации на основе разработки только внешней и внутренней схем по-прежнему остаются трудными для решения проблемы избыточности и противоречивости данных. Хотя СУБД значительно расширяет возможности совместного использования данных, все же ее применение не гарантирует непротиворечивости определения данных. Исследовательская группа по СУБД ANSI/X3/SPARC пришла к выводу, что для создания идеальной среды управления данными необходимо определение их с третьей, промежуточной точки зрения (концепция трех схем ANSI/X3/SPARC ). Эта точка зрения (называемая концептуальной схемой) сводится к единообразному определению данных в рамках предметной области, не ориентированному на какое-либо конкретное использование их и не зависящему от того, как данные физически обрабатываются на компьютере (рис. 1.7). 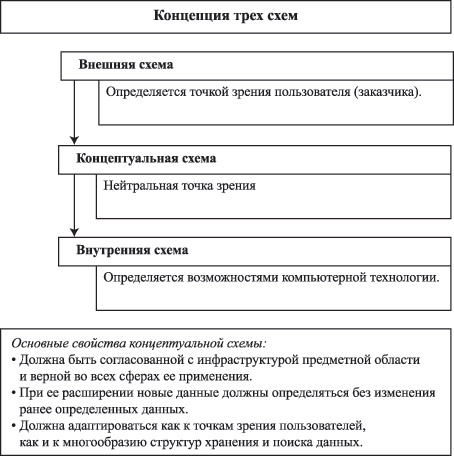 Рис. 1.7. Концепция трех схем Основной целью концептуальной схемы является выработка непротиворечивой интерпретации определения взаимосвязей данных для их объединения, совместного использования и управления целостностью данных. С другой стороны, любая информационная модель данных определяется средствами поддержки модели данных, реализуемыми СУБД. Основные типы моделей и их эквивалентность Наличие в СУБД определенной, допустимой структуры данных приводит к понятию баз структурированных данных, то есть данные в таких БД должны быть представлены как совокупность взаимосвязанных элементов. Если допустить возможность порождения новых типов и динамический процесс установления связей (во время появления объекта в БД), то мы придем к понятию баз неструктурированных данных. Допустимы и промежуточные варианты, которые носят название БД с частично детерминированной схемой. Такое деление БД с точки зрения степени структурированности сохраняемых данных оказывается существенным моментом при выборе несущей СУБД для реализации ИС, поскольку конкретная СУБД обычно поддерживает определенную модель данных. С другой стороны, следует иметь в виду, что для каждого из приведенных типов БД используются соответствующие модели данных, т.е. существует некоторое множество моделей данных. В настоящее время для баз структурированных данных различают три основных типа логических моделей данных в зависимости от характера поддерживаемых ими связей между элементами данных - сетевую, иерархическую и реляционную. Классифицирующими признаками в этих моделях являются: степень жесткости (фиксации) связи, математическое представление структуры модели и допустимые типы данных (см. таблицу 1.1). Допустимые типы данных будут обсуждаться далее при изучении реляционной модели.
Рис. 1.8 иллюстрирует особенности каждой модели данных. При сопоставлении моделей следует помнить, что все они теоретически эквивалентны. Эквивалентность моделей состоит в том, что они могут быть сведены одна к другой путем формальных преобразований. Подробное доказательство этого факта можно найти в классической монографии Дж. Мартина по БД. Суть доказательства состоит в отказе от принципа избыточности данных, то есть разрешается дублировать данные в узлах представления. Тогда преобразование одной модели в другую получается простым удвоением вершин соответствующего представления в цепочке моделей "сетевая-иерархическая-реляционная". 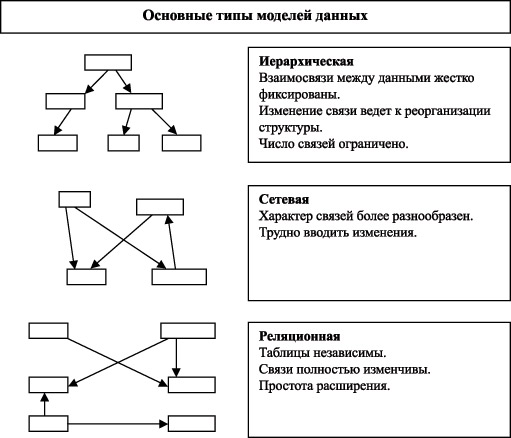 Рис. 1.8. Основные типы моделей данных Общие принципы классификации СУБД Очень часто СУБД классифицируются по типу модели данных, которую они поддерживают. Следовательно, различают СУБД сетевые, иерархические и реляционные. Однако в практике обработки данных СУБД характеризуются по их способности поддерживать определенный тип БД. В самом общем виде БД подразделяют на: фактографические, которые хранят совокупность фактов интегрированных, возможно, из различных документов; документальные, которые ориентированы на хранение документов; документально-фактографические, которые обладают чертами и тех и других. Так, СУБД CDS/ISIS в первую очередь ориентирована на поддержку работы с документом, который состоит из определенного числа рубрик, проиндексированных по тезаурусу ключевых слов. СУБД ADABAS хорошо подходит для организации фактографических БД, а СУБД ORACLE - для БД смешанного типа. Во избежание несуразностей с использованием определенной модели данных, БД, за редким исключением, целесообразно классифицировать по типу используемой модели в СУБД. Отметим, что классификация БД далеко не завершенная область исследований: попытки ввести новые типы БД продолжаются (активные, дедуктивные, нечеткие реляционные, графические БД и т.д.). Во многих случаях для разработчиков ИС бывает важно деление СУБД (и БД) по характеру обработки: на централизованные и распределенные. При использовании распределенной обработки следует обратить внимание на характер обработки транзакций, т.к. последние оказывают существенное влияние на производительность системы. Под транзакцией в самом общем случае понимают единицу работы, требуемой пользователем от БД, независимо от характера обработки. Чаще всего в результате обработки транзакции реализуется запрос пользователя либо на выборку данных из БД, либо на обновление БД, либо на выполнение каких-то иных действий над БД. При этом предполагается, что выполнение запроса сопровождается выполнением комплекса внутрисистемных действий СУБД, направленных на поддержание целостности данных, разграничение доступа и т.п. Существуют различные концептуальные подходы к обработке транзакций при распределенной обработке. Принципиальным здесь является не только вопрос как, но и где локализуется обработка транзакции: на файлах компьютера конечного пользователя или на выделенном в сети компьютере. От выбора той или иной концепции будет зависеть время отклика системы на запрос пользователя. Параметр "время отклика системы на запрос пользователя" очень часто выступает в качестве определяющего или желательного параметра разрабатываемой системы. Например, для распределенной системы бронирования авиабилетов для крупнейших мировых авиакомпаний этот параметр является существенным и закладывается в проектное решение как не превышающий 30-45 секунд. Обзор основных моделей данных Тремя основными типами моделей структурированных данных являются иерархическая, сетевая и реляционная. Первые две из них основаны на представлении информации об объектах в виде плоского графа. Иерархическая модель Иерархическая модель данных организует данные в виде древовидной структуры и является реализацией логических связей между данными типа родовидовых отношений или отношений "часть-целое". Примером простого иерархического представления может служить административная структура организации. Деревом в информатике называют совокупность корневого элемента и множества подчиненных ему элементов, в которой отношения между элементами носят подчиненный вертикальный характер. Горизонтальные связи в такой системе отношений не допускаются. Элементы описания данных в этой модели такие же, как и в сетевой: простое поле, группа, запись, групповое отношение и БД. Существенное ее отличие от сетевой модели данных касается средств организации связей, а именно, допускаются связи между объектами модели в виде древовидной структуры. Особенностью такого представления данных является наличие нескольких подчиненных уровней. В иерархической модели имеется корневой узел или корень дерева. Он располагается на 1-м, самом высоком уровне и не имеет узлов-предшественников. Остальные узлы называются порожденными и связаны между собой следующим образом: каждый узел имеет исходный, находящийся на вышестоящем уровне. На следующем уровне каждый узел может иметь более одного узла-потомка или не иметь потомков вовсе. Узлы, не имеющие порожденных, называются листьями. В иерархии рассматривают уровни, на которых расположен тот или иной узел или совокупность узлов. Между исходным узлом и порожденными узлами по условию модели существует связь "один-ко-многим" (или "многие-к-одному"). Иерархия должна удовлетворять следующим условиям: Иерархия имеет исходный узел (корень), из которого строится дерево. Каждое дерево имеет только один корень. Узел имеет непустое множество атрибутов, которые описывают объект, моделируемый в данном узле. Порожденные узлы могут добавляться в дерево как в вертикальном, так и в горизонтальном направлении. Доступ к порожденным узлам возможен только через исходный узел, поэтому существует только один путь доступа к каждому узлу. Возможно существование нескольких экземпляров каждого узла каждого уровня. При этом каждый экземпляр исходного узла начинает логическую запись. К основным недостаткам иерархической модели можно отнести: сложность отображения связи "многие-к-многим" усложнение операции включения новых объектов и удаления устаревших объектов непосредственно в базе данных (в особенности обновление и удаление связей); неоднозначность представления данных о предметной области. Пример. Пусть требуется построить иерархическую модель о преподавателях, студентах и дисциплинах, которые преподаватели преподают, а студенты изучают. Предположим, что каждый преподаватель может читать несколько дисциплин, а каждый студент также может изучать несколько дисциплин. Один из возможных вариантов построения иерархической модели может быть таковым. Корневым узлом является студент (Номер студента, ФИО, Номер группы). Для каждого студента при данном представлении имеется экземпляр корневого узла. Преподаватель и дисциплина объединяются в один порожденный узел (Табельный номер преподавателя, ФИО, Ученое звание, Кафедра, Дисциплина, Дата экзамена, Оценка, Зачет). При такой организации данных достаточно легко получать ответы на запросы типа "выдать информацию о сдаче экзаменов студентами по различным дисциплинам". Однако при ответе на вопрос, какие преподаватели принимают экзамены по ВТ, необходимо просмотреть все записи порожденных узлов для каждого корневого узла. Для этого вопроса более подходит модель, в которой корневым узлом является преподаватель (Табельный номер преподавателя, ФИО, ученое звание, кафедра), а порожденным является студент (номер студента, ФИО, номер группы, дисциплина, дата сдачи, оценка, зачет). В первом варианте модели для каждого студента дублируется информация (в экземпляре порожденного узла) о преподавателях и дисциплине, а во втором - для каждого преподавателя о студентах. Отсюда возникают проблемы включения и удаления данных. Из принципа иерархии следует, что экземпляр порожденного узла не может существовать в отсутствие соответствующего ему экземпляра исходного узла. Таким образом, невозможно без привлечения дополнительных способов включить в базу данных информацию о преподавателях, которые не принимают экзамены (для первого варианта схемы). Чтобы соблюсти принцип иерархии, нужно сформировать, например, пустой исходный узел и породить еще проблему интерпретации нуль-значений. При удалении исходного узла автоматически удаляются экземпляры порожденных узлов. Так, для второго варианта представления модели удаления сведения о преподавателе (уволился) удаляются все сведения о студентах, у него обучавшихся, а следовательно, теряется информация, необходимая для оценки качества обучения студентов. Первопричиной этих проблем является то обстоятельство, что иерархическая модель не поддерживает отношение M:N. Основной единицей обработки здесь является запись, к которой применимы операции ЗАПОМНИТЬ, МОДИФИЦИРОВАТЬ, УДАЛИТЬ, ИЗВЛЕЧЬ, НАЙТИ. В операциях создания и уничтожения связей для этой модели нет необходимости потому, что все связи предопределены заранее древовидной структурой отношений. Операция "найти" сводится к одной из трех процедур обхода дерева. При использовании иерархической модели актуальной является проблема отслеживания связей, хотя и в более простом варианте. К возможным недостаткам иерархической модели можно отнести вероятную асимметрию отношений между сущностями предметной области БД и неудобство в отображении горизонтальных связей, которые нужно выражать через вертикальные связи. | |||||||||||||||