Информатика. Информация продукт взаимодействия между соосбщением и его потребителем
 Скачать 421.81 Kb. Скачать 421.81 Kb.
|

КлючиДля начала давайте подумаем над таким вопросом: какую информацию нужно дать о человеке, чтобы собеседник точно сказал, что это именно тот человек, сомнений быть не может, второго такого нет? Сообщить фамилию, очевидно, недостаточно, поскольку существуют однофамильцы. Если собеседник человек, то мы можем приблизительно объяснить, о ком речь, например вспомнить поступок, который совершил тот человек, или еще как-то. Компьютер же такого объяснения не поймет, ему нужны четкие правила, как определить, о ком идет речь. В системах управления базами данных для решения такой задачи ввели понятие первичного ключа. Первичный ключ (primary key, PK) – минимальный набор полей, уникально идентифицирующий запись в таблице. Значит, первичный ключ – это в первую очередь набор полей таблицы, во-вторых, каждый набор значений этих полей должен определять единственную запись (строку) в таблице и, в-третьих, этот набор полей должен быть минимальным из всех обладающих таким же свойством. Поскольку первичный ключопределяет только одну уникальную запись, то никакие две записи таблицы не могут иметь одинаковых значений первичного ключа. Например, в нашей таблице (см. выше) ФИО и адрес позволяют однозначно выделить запись о человеке. Если же говорить в общем, без связи с решаемой задачей, то такие знания не позволяют точно указать на единственного человека, поскольку существуют однофамильцы, живущие в разных городах по одному адресу. Все дело в границах, которые мы сами себе задаем. Если считаем, что знания ФИО, телефона и адреса без указания города для наших целей достаточно, то все замечательно, тогда поля ФИО и адрес могут образовывать первичный ключ. В любом случае проблема созданияпервичного ключа ложится на плечи того, кто проектирует базу данных (разрабатывает структуру хранения данных). Решением этой проблемы может стать либо выделение характеристик, которые естественным образом определяют запись в таблице (задание так называемого логического, или естественного, PK), либо создание дополнительного поля, предназначенного именно для однозначной идентификации записей в таблице (задание так называемого суррогатного, или искусственного, PK). Примером логического первичного ключа является номер паспорта в базе данных о паспортных данных жителей или ФИО и адрес в телефонной книге (таблица выше). Для задания суррогатного первичного ключа в нашу таблицу можно добавить поле id (идентификатор), значением которого будет целое число, уникальное для каждой строки таблицы. Использование таких суррогатных ключейимеет смысл, если естественный первичный ключ представляет собой большой набор полей или его выделение нетривиально. Кроме однозначной идентификации записи, первичные ключи используются для организации связей с другими таблицами. Например, у нас есть три таблицы: содержащая информацию об исторических личностях (Persons), содержащая информацию об их изобретениях (Artifacts) и содержащая изображения как личностей, так и артефактов (Images) (рис 10.1). Первичным ключом во всех этих таблицах является поле id (идентификатор). В таблице Artifacts есть поле author, в котором записан идентификатор, присвоенный автору изобретения в таблице Persons. Каждое значение этого поля является внешним ключомдля первичного ключа таблицы Persons. Кроме того, в таблицах Persons и Artifacts есть поле photo, которое ссылается на изображение в таблице Images. Эти поля также являются внешними ключами для первичного ключа таблицы Images и устанавливают однозначную логическую связь Persons-Images и Artifacts-Images. То есть если значениевнешнего ключа photo в таблице личности равно 10, то это значит, что фотография этой личности имеет id=10 в таблице изображений. Таким образом, внешние ключииспользуются для организации связей между таблицами базы данных (родительскими и дочерними) и для поддержания ограничений ссылочной целостности данных. ИндексированиеОдна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно небольшое время и с достаточной точностью. Для этого (для оптимизации производительности запросов) производят индексирование некоторых полей таблицы. Использовать индексы полезно для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице, начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше таблица, тем больше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, тобаза данных может быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Это происходит потому, что база данных помещает проиндексированные поля поближе в памяти, так, чтобы можно было побыстрее найти их значения. Для таблицы, содержащей 1000 строк, это будет как минимум в 100 раз быстрее по сравнению с последовательным перебором всех записей. Однако в случае, когда необходим доступ почти ко всем 1000 строкам, быстрее будет последовательное чтение, так как при этом не требуется операций поиска по диску. Так что иногда индексы бывают только помехой. Например, если копируется большой объем данных в таблицу, то лучше не иметь никаких индексов. Однако в некоторых случаях требуется задействовать сразу несколько индексов (например, для обработки запросов к часто используемым таблицам). Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, иINDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев. PRIMARY – уникальный индекс (ключ) с ограничением, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, но он может состоять из нескольких полей. UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения. INDEX – обычный индекс (как мы описали выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки. 37. Классификация баз данных По типу хранимой информации БД делятся на
Среди документальных баз различают библиографические, реферативные и полнотекстовые. К лексикографическим базам данных относятся различные словари (классификаторы, многоязычные словари, словари основ слов и т. п.). В системах фактографического типа в БД хранится информация об интересующих пользователя объектах предметной области в виде «фактов» (например, биографические данные о сотрудниках, данные о выпуске продукции производителями и т.п.); в ответ на запрос пользователя выдается требуемая информация об интересующем его объекте (объектах) или сообщение о том, что искомая информация отсутствует в БД. В документальных БД единицей хранения является какой-либо документ (например, текст закона или статьи), и пользователю в ответ на его запрос выдается либо ссылка на документ, либо сам документ, в котором он может найти интересующую его информацию. БД документального типа могут быть организованы по- разному: без хранения и с хранением самого исходного документа на машинных носителях. К системам первого типа можно отнести библиографические и реферативные БД, а также БД- указатели, отсылающие к источнику информации. Системы, в которых предусмотрено хранение полного текста документа, называются полнотекстовыми. В системах документального типа целью поиска может быть не только какая-то информация, хранящаяся в документах, но и сами документы. Так, возможны запросы типа «сколько документов было создано за определенный период времени» и т. п. Часто в критерий поиска в качестве признаков включаются «дата принятия документа», «кем принят» и другие «выходные данные» документов. Специфической разновидностью баз данных являются базы данных форм документов. Они обладают некоторыми чертами документальных систем (ищется документ, а не информация о конкретном объекте, форма документа имеет название, по которому обычно и осуществляется его поиск), и специфическими особенностями (документ ищется не с целью извлечь из него информацию, а с целью использовать его в качестве шаблона). В последние годы активно развивается объектно- ориентированный подход к созданию информационных систем. Объектные базы данных организованы как объекты и ссылки к объектам. Объект представляет собой данные и правила, по которым осуществляются операции с этими данными. Объект включает метод, который является частью определения объекта и запоминается вместе с объектом. В объектных базах данных данные запоминаются как объекты, классифицированные по типам классов и организованные в иерархическое семейство классов. Класс - коллекция объектов с одинаковыми свойствами. Объекты принадлежат классу. Классы организованы в иерархии. По характеру организации хранения данных и обращения к ним различают
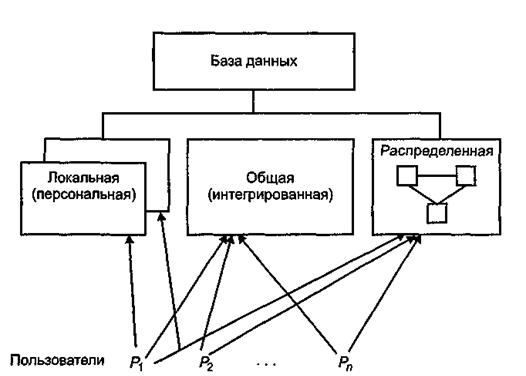 Персональная база данных - это база данных, предназначенная для локального использования одним пользователем. Локальные БД могут создаваться каждым пользователем самостоятельно, а могут извлекаться из общей БД. Интегрированные и распределенные БД предполагают возможность одновременного обращения нескольких пользователей к одной и той же информации (многопользовательский, параллельный режим доступа). Это привносит специфические проблемы при их проектировании и в процессе эксплуатации БнД. РаспределенныеБД, кроме того, имеют характерные особенности, связанные с тем, что физически разные части БД могут быть расположены на разных ЭВМ, а логически, с точки зрения пользователя, они должны представлять собой единое целое. БД классифицируются по объему. Особое место здесь занимают так называемые очень большие базы данных. Это вызвано тем, что для больших баз данных по-иному ставятся вопросы обеспечения эффективности хранения информации и обеспечения ее обработки. По характеру организации данных БД могут быть разделены на
Этот классификационный признак относится к информации, представленной в символьном виде. К неструктурированным БД могут быть отнесены базы, организованные в виде семантических сетей. Частично структурированными можно считать базы данных в виде обычного текста или гипертекстовые системы. Структурированные БД требуют предварительного проектирования и описания структуры БД. Только после этого базы данных такого типа могут быть заполнены данными. Структурированные БД, в свою очередь, по типу используемой модели делятся на
Классификация по типу модели распространяется не только на базы данных, но и на СУБД. 38.СУБД Систе́ма управле́ния ба́зами да́нных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных[1]. Основные функции СУБД
Обычно современная СУБД содержит следующие компоненты:
Компоненты СУБД СУБД состоит из нескольких программных компонентов (модулей), представленных на рис. 5.1, каждый из которых предназначен для выполнения определенной операции. На этой схеме также показано, как СУБД взаимодействует с другими программными компонентами, например с такими, как пользовательские запросы и методы доступа (т.е. методы управления файлами, используемые при сохранении и извлечении записей с данными). /Файловая организация и методы доступа подробно описываются в работах Тиори и Фрая (Teorey and Fry, 1982), Видерхольда (Weiderhold, 1983), Смита и Барнса (Smith and Bames, 1987), а также Ульмана (Ullman, 1988)./ На рис. 5.1 показаны следующие программные компоненты среды СУБД. Процессор запросов. Это основной компонент СУБД, который преобразует запросы в последовательность низкоуровневых инструкций для контроллера базы данных. 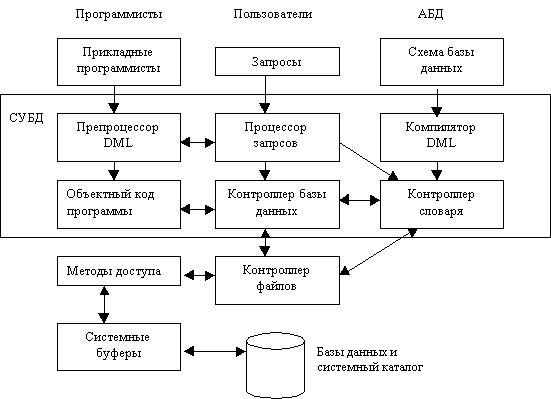 Рисунок 2. Основные компоненты типичной системы управления базами данных Контроллер базы данных. Этот компонент взаимодействует с запущенными пользователями прикладными программами и запросами. Контроллер базы данных принимает запросы и проверяет внешние и концептуальные схемы для определения тех концептуальных записей, которые необходимы для удовлетворения требований запроса. Затем контроллер базы данных вызывает контроллер файлов для выполнения поступившего запроса. Контроллер файлов манипулирует предназначенными для хранения данных файлами и отвечает за распределение доступного дискового пространства. Он создает и поддерживает список структур и индексов, определенных во внутренней схеме. Если используются хешированные файлы, то в его обязанности входит и вызов функций хеширования для генерации адресов записей. Однако контроллер файлов не управляет физическим вводом и выводом данных непосредственно, а лишь передает запросы соответствующим методам доступа, которые считывают данные в системные буферы или записывают их оттуда на диск. Препроцессор языка DML. Этот модуль преобразует внедренные в прикладные программы DML-операторы в вызовы стандартных функций базового языка. Для генерации соответствующего кода препроцессор языка DML должен взаимодействовать с процессором запросов. Компилятор языка DDL. Компилятор языка DDL преобразует DDL-команды в набор таблиц, содержащих метаданные. Затем эти таблицы сохраняются в системном каталоге, а управляющая информация - в заголовках файлов с данными. Контроллер словаря. Контроллер словаря управляет доступом к системному каталогу и обеспечивает работу с ним. Системный каталог доступен большинству компонентов СУБД. Ниже перечислены основные программные компоненты, входящие в состав контроллера базы данных. Контроль прав доступа. Этот модуль проверяет наличие у данного пользователя полномочий для выполнения затребованной операции. Процессор команд. После проверки полномочий пользователя для выполнения затребованной операции управление передается процессору команд. Средства контроля целостности. В случае операций, которые изменяют содержимое базы данных, средства контроля целостности выполняют проверку того, удовлетворяет ли затребованная операция всем установленным ограничениям поддержки целостности данных (например, требованиям, установленным для ключей). Оптимизатор запросов. Этот модуль определяет оптимальную стратегию выполнения запроса. Контроллер транзакций. Этот модуль осуществляет требуемую обработку операций, поступающих в процессе выполнения транзакций. Планировщик. Этот модуль отвечает за бесконфликтное выполнение параллельных операций с базой данных. Он управляет относительным порядком выполнения операций, затребованных в отдельных транзакциях. Контроллер восстановления. Этот модуль гарантирует восстановление базы данных до непротиворечивого состояния при возникновении сбоев. В частности, он отвечает за фиксацию и отмену результатов выполнения транзакций. Контроллер буферов. Этот модуль отвечает за перенос данных между оперативной памятью и вторичным запоминающим устройством - например, жестким диском или магнитной лентой. Контроллер восстановления и контроллер буферов иногда (в совокупности) называют контроллером данных. Для воплощения базы данных на физическом уровне помимо перечисленных выше модулей нужны некоторые другие структуры данных. К ним относятся файлы данных и индексов, а также системный каталог. Группой DAFTG (Data-base Architecture Framework Task Group) была предпринята попытка стандартизации СУБД, и в 1986 году ею была предложена некоторая эталонная модель. Назначение эталонной модели заключается в определении концептуальных рамок для разделения предпринимаемых попыток стандартизации на более управляемые части и указания взаимосвязей между ними на очень 39. КЛАССИФИКАЦИЯ СУБД 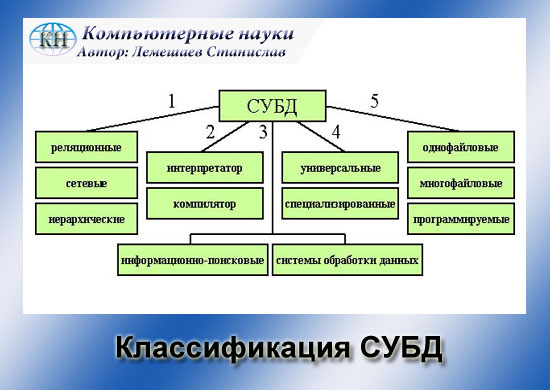 Прочитав несколько статей в интернете, захотелось провести четкуюклассификацию СУБД. Но вскоре пришел к выводу, что четкой классификации сделать не получается, так как классифицироваться СУБД могут разными способами. Однако в этой статье будут рассмотрены несколько самых популярных классификаций СУБД, но прежде дадим сначала определение СУБД.(Кстати, определений СУБД тоже существует довольно таки много, но мне понравилось следующее) Прочитав несколько статей в интернете, захотелось провести четкуюклассификацию СУБД. Но вскоре пришел к выводу, что четкой классификации сделать не получается, так как классифицироваться СУБД могут разными способами. Однако в этой статье будут рассмотрены несколько самых популярных классификаций СУБД, но прежде дадим сначала определение СУБД.(Кстати, определений СУБД тоже существует довольно таки много, но мне понравилось следующее)Системой Управления Базами Данных (СУБД) называют набор программных и языковых средств, который должен обеспечивать создание, ведение и совместное использование Базы Данных несколькими пользователями. Из этого определения следует, что СУБД можно назвать такую программу с помощью которой, можно создать базу данных, ввести ее или редактировать. А также имеется возможность использование ее одним или несколькими пользователями. |