Классификация по модели данных
 Скачать 2.86 Mb. Скачать 2.86 Mb.
|

|
1.5 Выводы В первой главе выпускной квалификационной работы была исследованна поставленная задача и составлен определен перечень функций, которые необходимо реализовать в программном продукте, а так же список системных требований и требований к входным и выходным файлам. Основными пунктами рассмотрения в первой главе стали: - описание поставленной задачи; - обоснование актуальности; - обзор методов решения подобных задач; - постановка задачи, системные требования, требования к выходным данным и входным формам. 2. ПРОЕКТИРОВАНИЕ СТРУКТУРЫ И АРХИТЕКТУРЫ ПРОГРАММНОГО ПРОДУКТА .1 Выбор методов и средств для реализации, его обоснование Для разработки программного продукта была выбрана интегрированная среда разработки Microsoft Visual Studio 2008. Visual Studio 2008 - выпущена 19 ноября 2007, одновременно с .NET Framework 3.5. Нацелена на создание приложений для операционной системы Windows Vista (но поддерживает и XP), Office 2007 и веб-приложений. Включает в себя LINQ, новые версии языков C# и Visual Basic. В студию не вошёл Visual J#. Одним из его плюсов является полностью русский интерфейс. Visual Studio включает в себя редактор исходного кода с поддержкой технологии IntelliSense и возможностью простейшего рефакторинга кода. Встроенный отладчик может работать как отладчик уровня исходного кода, так и как отладчик машинного уровня. Остальные встраиваемые инструменты включают в себя редактор форм для упрощения создания графического интерфейса приложения, веб-редактор, дизайнер классов и дизайнер схемы базы данных. Visual Studio позволяет создавать и подключать сторонние дополнения (плагины) для расширения функциональности практически на каждом уровне, включая добавление поддержки систем контроля версий исходного кода (как например, Subversion и Visual SourceSafe), добавление новых наборов инструментов (например, для редактирования и визуального проектирования кода на предметно-ориентированных языках программирования или инструментов для прочих аспектов процесса разработки программного обеспечения (например, клиент Team Explorer для работы с Team Foundation Server). Все инструментальные среды Visual Studio 2008 на основе языка C# отличаются такими особенностями, как: - возможностью формулировать задачи на языке взаимодействия объектов; - высокой модульностью программного кода; - адаптируемостью к желанием пользователей; - высокой степенью повторной используемости программ; - большое число подключаемых библиотек. .2 Описание применяемых алгоритмов В разработке данного программного обеспечения можно выделить две основные трудности: построение распознавателя для программируемых шаблонов и создание программной модели, которая бы использовалась в шаблонах, создаваемых при помощи конструктора. . Программируемые шаблоны. Так как код, используемый в шаблонах, чем-то схож с кодом, используемым в языках программирования, необходимо, чтобы данный распознаватель перенял некоторые функции компилятора кода, а точнее его анализирующие функции. В структуре компилятора анализирующая часть состоит из лексического, синтаксического и семантического анализа. Лексический анализатор читает литеры программы на исходном языке и строит из них лексемы исходного языка. Результатом его работы становится таблица идентификаторов. Синтаксический анализатор выполняет выделение синтаксических конструкций в тексте исходной программы, обработанным лексическим анализатором. Приводит синтаксические правила программы в соответствие с грамматикой языка. Синтаксический анализатор является распознавателем текста входного языка. Семантический анализатор проверяет правильность текста исходной программы с точки зрения смысла входного языка. С помощью кода должны реализоваться следующие возможности: создание цикла, получение и вывод данных о количестве строк и столбцов, получение типа данных и названия столбцов, а так же получение содержимого ячеек базы данных. Для этого в первую очередь необходимо составить список всех возможных состояний автомата. Возможные состояния распознавателя представлены в таблице 2.1. Таблица 2.1 - Список возможных состояний распознавателя
На основании составленной таблицы можно построить конечный автомат возможных переходов состояний. На рисунке 2.1 изображен конечный автомат. 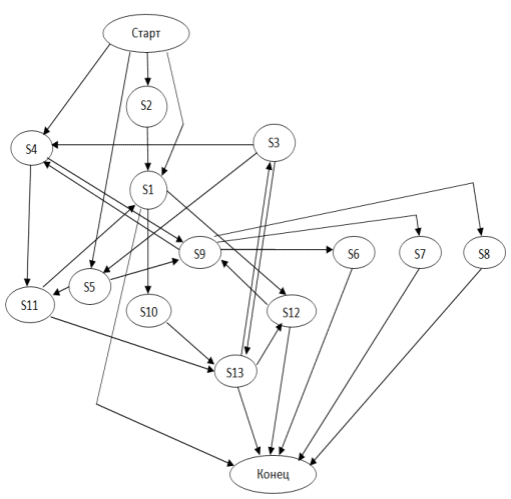 Рисунок 2.1 - Конечный автомат возможных переходов На основе построенного автомата можно построить нисходящий распознаватель с возвратом (с подбором альтернатив). Нисходящий распознаватель с возвратом служит для определения принадлежности цепочки к грамматике. Он анализирует текущее состояние, ищет правило перехода из текущего состояния в следующее, если следующее состояние совпадает, то процедура повторяется для следующего. Если распознаватель не может найти правило перехода из текущего состояния в следующее, значит, эта цепочка не принадлежит данной грамматике, то есть строка кода написана с логической ошибкой. Если вариантов перехода несколько, то распознаватель запоминает состояние, в котором возникла альтернатива и возвращается к нему, если цепочка не принадлежит грамматике. Во время анализа шаблонов ведется журнал ошибок, содержащий в себе информацию о том, в каком шаблоне ошибка, в какой конкретно строке кода и тип ошибки. Ошибки могут быть следующих типов: неопознанный идентификатор (попытка использовать служебные слова или специальные символы, непредусмотренные данным кодом), нарушение логического смысла (строка кода не прошла проверку распознавателем), попытка обратиться к несуществующей переменной (обращение переменной к не созданной переменной или обращение к переменной вне цикла), не указано начало цикла (начало и конец цикла должны быть обязательно указаны в виде открывающейся и закрывающейся фигурных скобок). 2. Шаблоны, создаваемые при помощи конструктора. Одним из вариантов решения является структура, используемая в логических языках программирования: применять фильтры условий к общей входной информации, которой в данном случае является содержимое таблицы базы данных. На рисунке 2.3 изображена общая структура таблицы баз данных.
Рисунок 2.3 - Общая структура таблицы БД 3. 4. В качестве реализации было выбрано решение с использованием «Таблицы истинности». Эта таблица представляет собой таблицу, с n+1 столбцов и m+1 строк, где n и m - число столбцов и строк во входной таблице. Каждая ячейка таблицы хранит значение true или false. На рисунке 2.4 изображена «Таблица истинности».
Рисунок 2.4 - «Таблица истинности» В случае применения фильтра значения true заменяются на false в зависимости от того к чему применялся фильтр. Если фильтр применялся к содержимому ячеек, то значения будут меняться для каждой ячейке конкретно, а если к строкам или столбцам, то только в дополнительных строке или столбце. При работе с базой данных можно выделить следующие сущности: индекс строки, индекс столбца, количество строк, количество столбцов, тип столбца, название столбца, содержимое ячейки. Так же были выделены условия: «<», «>», «=», «содержит», «совпадает». 5. Выделенных сущностей и условий достаточно, чтобы выводить все возможные данные или накладывать всевозможные условия. На рисунке 2.5 изображена «Таблица истинности» с применением фильтров. Рисунок 2.5 - «Таблица истинности» с применением фильтров
При выводе информации в XML файл, программа определяет, что необходимо вывести, а затем, используя «Таблицу истинности», выводит только те значения, которые соответствуют значению true. Для создания макета шаблона были созданы следующие типы тегов: главный, простой, глобальный, блочный. Главный - тег, этого типа может быть всего один в документе и он обязателен, он содержит информацию о XML документе. Простой - теги этого типа являются единственным способом выводить данные и накладывать условия на «Таблицу истинности». Они состоят из следующих частей: название, источник и условие. В качестве источника и условия используются ранее выделенные сущности. В случае если у тега будет пустое имя, его содержимое выводиться не будет, но условие к «Таблице истинности» будет применяться. Глобальный - теги этого типа не несут логической нагрузки, они необходимы просто для вывода. Блочный - теги этого типа необходимы для объединения логики простых тегов, а так же все что записано в блочном теге будет выводиться для каждой ячейки удовлетворяющей «Таблице истинности». Сам блочный тег в XML документ не выводится. |