Кластерные системы
 Скачать 270 Kb. Скачать 270 Kb.
|

История развития кластерной архитектуры.Компания DEC первой анонсировала концепцию кластерной системы в 1983 году, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. Один из первых проектов, давший имя целому классу параллельных систем – кластеры Beowulf [2] – возник в центре NASA Goddard Space Flight Center для поддержки необходимыми вычислительными ресурсами проекта Earth and Space Sciences. Проект Beowulf стартовал летом 1994 года, и вскоре был собран 16-процессорный кластер на процессорах Intel 486DX4/100 МГц. На каждом узле было установлено по 16 Мбайт оперативной памяти и по 3 сетевых Ethernet-адаптера. Для работы в такой конфигурации были разработаны специальные драйверы, распределяющие трафик между доступными сетевыми картами. Позже в GSFC был собран кластер theHIVE – Highly-parallel Integrated Virtual Environment [3], структура которого показана на рис. 2. Этот кластер состоит из четырех подкластеров E, B, G, и DL, объединяя 332 процессора и два выделенных хост-узла. Все узлы данного кластера работают под управлением RedHat Linux. 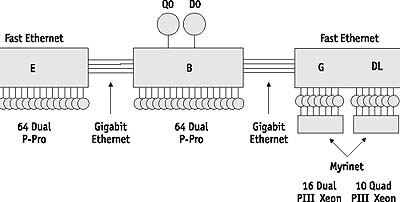 Рис. 5 В 1998 году в Лос-Аламосской национальной лаборатории астрофизик Майкл Уоррен и другие ученые из группы теоретической астрофизики построили суперкомпьютер Avalon, который представляет собой Linux-кластер на базе процессоров Alpha 21164A с тактовой частотой 533 МГц. Первоначально Avalon состоял из 68 процессоров, затем был расширен до 140. В каждом узле установлено по 256 Мбайт оперативной памяти, жесткий диск на 3 Гбайт и сетевой адаптер Fast Ethernet. Общая стоимость проекта Avalon составила 313 тыс. долл., а показанная им производительность на тесте LINPACK – 47,7 GFLOPS, позволила ему занять 114 место в 12-й редакции списка Top500 рядом с 152-процессорной системой IBM RS/6000 SP. В том же 1998 году на самой престижной конференции в области высокопроизводительных вычислений Supercomputing’98 создатели Avalon представили доклад «Avalon: An Alpha/Linux Cluster Achieves 10 Gflops for $150k», получивший первую премию в номинации «наилучшее отношение цена/производительность». В апреле текущего года в рамках проекта AC3 в Корнелльском Университете для биомедицинских исследований был установлен кластер Velocity+, состоящий из 64 узлов с двумя процессорами Pentium III/733 МГц и 2 Гбайт оперативной памяти каждый и с общей дисковой памятью 27 Гбайт. Узлы работают под управлением Windows 2000 и объединены сетью cLAN компании Giganet. Проект Lots of Boxes on Shelfes [4] реализован в Национальном Институте здоровья США в апреле 1997 года и интересен использованием в качестве коммуникационной среды технологии Gigabit Ethernet. Сначала кластер состоял из 47 узлов с двумя процессорами Pentium Pro/200 МГц, 128 Мбайт оперативной памяти и диском на 1,2 Гбайт на каждом узле. В 1998 году был реализован следующий этап проекта – LoBoS2, в ходе которого узлы были преобразованы в настольные компьютеры с сохранением объединения в кластер. Сейчас LoBoS2 состоит из 100 вычислительных узлов, содержащих по два процессора Pentium II/450 МГц, 256 Мбайт оперативной и 9 Гбайт дисковой памяти. Дополнительно к кластеру подключены 4 управляющих компьютера с общим RAID-массивом емкостью 1,2 Тбайт. Одной из последних кластерных разработок стал суперкомпьютер AMD Presto III, представляющий собой кластер Beowulf из 78 процессоров Athlon. Компьютер установлен в Токийском Технологическом Институте. На сегодняшний день AMD построила 8 суперкомпьютеров, объединенных в кластеры по методу Beowulf, работающих под управлением ОС Linux. Кластеры IBMRS/6000 Компания IBM предлагает несколько типов слабо связанных систем на базе RS/6000, объединенных в кластеры и работающих под управлением программного продукта High-Availability Clastered Multiprocessor/6000 (HACMP/6000). Узлы кластера работают параллельно, разделяя доступ к логическим и физическим ресурсам пользуясь возможностями менеджера блокировок, входящего в состав HACMP/6000. Начиная с объявления в 1991 году продукт HACMP/6000 постоянно развивался. В его состав были включены параллельный менеджер ресурсов, распределенный менеджер блокировок и параллельный менеджер логических томов, причем последний обеспечил возможность балансировки загрузки на уровне всего кластера. Максимальное количество узлов в кластере возросло до восьми. В настоящее время в составе кластера появились узлы с симметричной многопроцессорной обработкой, построенные по технологии Data Crossbar Switch, обеспечивающей линейный рост производительности с увеличением числа процессоров. Кластеры RS/6000 строятся на базе локальных сетей Ethernet, Token Ring или FDDI и могут быть сконфигурированы различными способами с точки зрения обеспечения повышенной надежности: Горячий резерв или простое переключение в случае отказа. В этом режиме активный узел выполняет прикладные задачи, а резервный может выполнять некритичные задачи, которые могут быть остановлены в случае необходимости переключения при отказе активного узла. Симметричный резерв. Аналогичен горячему резерву, но роли главного и резервного узлов не фиксированы. Взаимный подхват или режим с распределением нагрузки. В этом режиме каждый узел в кластере может "подхватывать" задачи, которые выполняются на любом другом узле кластера. IBM SP2 IBM SP2 лидируют в списке крупнейших суперкомпьютеров TOP500 по числу инсталляций (141 установка, а всего в мире работает 8275 таких компьютеров с общим числом узлов свыше 86 тыс. В основу этих суперкомпьютеров заложенный в основу архитектуры кластерный подход с использованием мощного центрального коммутатора. IBM использует этот подход уже много лет. Общая архитектура SP2Общее представление об архитектуре SP2 дает рис. 1. Основная ее особенность архитектуры — применение высокоскоростного коммутатора с низкими задержками для соединения узлов между собой. Эта внешне предельно простая схема, как показал опыт, оказалась чрезвычайно гибкой. Сначала узлы SP2 были однопроцессорными, затем появились узлы с SMP-архитектурой. 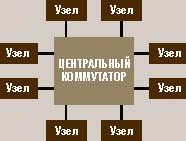 Рис. 7 Собственно, все детали скрываются в строении узлов. Мало того, узлы бывают различных типов, причем даже процессоры в соседних узлах могут быть разными. Это обеспечивает большую гибкость выбора конфигураций. Общее число узлов в вычислительной системе может достигать 512. Узлы SP2 фактически являются самостоятельными компьютерами, и их прямые аналоги продаются корпорацией IBM под самостоятельными названиями. Наиболее ярким примером этого является четырехпроцессорный SMP-сервер RS/6000 44P-270 c микропроцессорами Power3-II, который сам по себе можно отнести к классу компьютеров среднего класса или даже к мини-суперкомпьютерам. Устанавливавшиеся в узлах SP2 микропроцессоры развивались по двум архитектурным линиям: Power — Power2 — Power3 — Power3-II и по линии PowerPC вплоть до модели 604e с тактовой частотой 332 МГц. Традиционными для SP2 являются «тонкие» (Thin Node) и «широкие» (Wide Node) узлы, обладающие SMP-архитектурой. В них могут устанавливаться как PowerPC 604e (от двух до четырех процессоров), так и Power3-II (до четырех). Емкость оперативной памяти узлов составляет от 256 Мбайт до 3 Гбайт (при использовании Power3-II — до 8 Гбайт). Основные отличия между тонкими и широкими узлами касаются подсистемы ввода/вывода. Широкие узлы предназначены для задач, требующих более мощных возможностей ввода/вывода: в них имеется по десять слотов PCI (в том числе три 64-разрядных) против двух слотов в тонких узлах. Соответственно, и число монтажных отсеков для дисковых устройств в широких узлах больше. Быстродействие коммутатора характеризуется низкими величинами задержек: 1,2 мс (до 2 мс при числе узлов свыше 80). Это на порядок лучше того, что можно получить в современных Linux-кластерах Beowulf. Пиковая пропускная способность каждого порта: она составляет 150 Мбайт/с в одном направлении (то есть 300 Мбайт/с при дуплексной передаче). Той же пропускной способностью обладают и расположенные в узлах SP2 адаптеры коммутатора. IBM приводит также отличные результаты по задержкам и пропускной способности. Наиболее мощные узлы SP2 — «высокие» (High Node). Высокий узел — это комплекс, состоящий из вычислительного узла с подсоединенными устройствами расширения ввода/вывода в количестве до шести штук. Такой узел также обладает SMP-архитектурой и содержит до 8 процессоров Power3 с тактовой частотой 222 или 375 МГц. 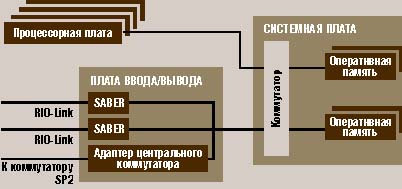 Рис. 8 Кроме того, узел этого типа содержит плату ввода/вывода, которая также подсоединена к системной плате. Плата ввода/вывода содержит два симметричных логических блока SABER, через которые осуществляется передача данных к внешним устройствам, таким как диски и телекоммуникационное оборудование. На плате ввода/вывода имеется четыре слота 64-разрядной шины PCI и один 32-разрядный слот (частота 33 МГц), а также интегрированы контроллеры UltraSCSI, Ethernet 10/100 Мбит/с, три последовательных и один параллельный порт. C появлением высоких узлов и микропроцессоров Power3-II/375 МГц на тестах Linpack parallel системы IBM SP2 достигли производительности 723,4 GFLOPS. Этот результат достигнут при использовании 176 узлов (704 процессора). Учитывая, что узлов можно установить до 512, этот результат показывает, что серийно выпускаемые IBM SP2 потенциально близки к отметке 1 TFLOPS. Кластерные решения Sun MicrosystemsSun Microsystems предлагает кластерные решения на основе своего продукта SPARCclaster PDB Server, в котором в качестве узлов используются многопроцессорные SMP-серверы SPARCserver 1000 и SPARCcenter 2000. Максимально в состав SPARCserver 1000 могут входить до восьми процессоров, а в SPARCcenter 2000 до 20 процессоров SuperSPARC. В комплект базовой поставки входят следующие компоненты: два кластерных узла на основе SPARCserver 1000/1000E или SPARCcenter 2000/2000E, два дисковых массива SPARCstorage Array, а также пакет средств для построения кластера, включающий дублированное оборудование для осуществления связи, консоль управления кластером Claster Management Console, программное обеспечение SPARCclaster PDB Software и пакет сервисной поддержки кластера. Для обеспечения высокой производительности и готовности коммуникаций кластер поддерживает полное дублирование всех магистралей данных. Узлы кластера объединяются с помощью каналов SunFastEthernet с пропускной способностью 100 Мбит/с. Для подключения дисковых подсистем используется оптоволоконный интерфейс Fibre Channel с пропускной способностью 25 Мбит/с, допускающий удаление накопителей и узлов друг от друга на расстояние до 2 км. Все связи между узлами, узлами и дисковыми подсистемами дублированы на аппаратном уровне. Аппаратные, программные и сетевые средства кластера обеспечивают отсутствие такого места в системе, одиночный отказ или сбой которого выводил бы всю систему из строя. Университетские проектыИнтересная разработка Университета штата Кентукки – кластер KLAT2 (Kentucky Linux Athlon Testbed 2 [5]). Система KLAT2 состоит из 64 бездисковых узлов с процессорами AMD Athlon/700 МГц и оперативной памятью 128 Мбайт на каждом. Программное обеспечение, компиляторы и математические библиотеки (SCALAPACK, BLACS и ATLAS) были доработаны для эффективного использования технологии 3DNow! процессоров AMD, что позволило увеличить производительность. Значительный интерес представляет и использованное сетевое решение, названное «Flat Neighbourghood Network» (FNN). В каждом узле установлено четыре сетевых адаптера Fast Ethernet от Smartlink, а узлы соединяются с помощью девяти 32-портовых коммутаторов. При этом для любых двух узлов всегда есть прямое соединение через один из коммутаторов, но нет необходимости в соединении всех узлов через единый коммутатор. Благодаря оптимизации программного обеспечения под архитектуру AMD и топологии FNN удалось добиться рекордного соотношения цена/производительность – 650 долл. за 1 GFLOPS. Идея разбиения кластера на разделы получила интересное воплощение в проекте Chiba City [6], реализованном в Аргоннской Национальной лаборатории. Главный раздел содержит 256 вычислительных узлов, на каждом из которых установлено два процессора Pentium III/500 МГц, 512 Мбайт оперативной памяти и локальный диск емкостью 9 Гбайт. Кроме вычислительного раздела в систему входят раздел визуализации (32 персональных компьютера IBM Intellistation с графическими платами Matrox Millenium G400, 512 Мбайт оперативной памяти и дисками 300 Гбайт), раздел хранения данных (8 серверов IBM Netfinity 7000 с процессорами Xeon/500 МГц и дисками по 300 Гбайт) и управляющий раздел (12 компьютеров IBM Netfinity 500). Все они объединены сетью Myrinet, которая используется для поддержки параллельных приложений, а также сетями Gigabit Ethernet и Fast Ethernet для управляющих и служебных целей. Все разделы делятся на «города» (town) по 32 компьютера. Каждый из них имеет своего «мэра», который локально обслуживает свой «город», снижая нагрузку на служебную сеть и обеспечивая быстрый доступ к локальным ресурсам. Кластерные проекты в РоссииВ России всегда была высока потребность в высокопроизводительных вычислительных ресурсах, и относительно низкая стоимость кластерных проектов послужила серьезным толчком к широкому распространению подобных решений в нашей стране. Одним из первых появился кластер «Паритет», собранный в ИВВиБД и состоящий из восьми процессоров Pentium II, связанных сетью Myrinet. В 1999 году вариант кластерного решения на основе сети SCI был апробирован в НИЦЭВТ, который, по сути дела, и был пионером использования технологии SCI для построения параллельных систем в России. Высокопроизводительный кластер на базе коммуникационной сети SCI, установлен в Научно-исследовательском вычислительном центре Московского государственного университета [7]. Кластер НИВЦ включает 12 двухпроцессорных серверов «Эксимер» на базе Intel Pentium III/500 МГц, в общей сложности 24 процессора с суммарной пиковой производительностью 12 млрд. операций в секунду. Общая стоимость системы – около 40 тыс. долл. или примерно 3,33 тыс. за 1 GFLOPS. Вычислительные узлы кластера соединены однонаправленными каналами сети SCI в двумерный тор 3x4 и одновременно подключены к центральному серверу через вспомогательную сеть Fast Ethernet и коммутатор 3Com Superstack. Сеть SCI – это ядро кластера, делающее данную систему уникальной вычислительной установкой суперкомпьютерного класса, ориентированной на широкий класс задач. Максимальная скорость обмена данными по сети SCI в приложениях пользователя составляет более 80 Мбайт/с, а время латентности около 5,6 мкс. При построении данного вычислительного кластера использовалось интегрированное решение Wulfkit, разработанное компаниями Dolphin Interconnect Solutions и Scali Computer (Норвегия). Основным средством параллельного программирования на кластере является MPI (Message Passing Interface) версии ScaMPI 1.9.1. На тесте LINPACK при решении системы линейных уравнений с матрицей размера 16000х16000 реально полученная производительность составила более 5,7 GFLOPS. На тестах пакета NPB производительность кластера сравнима, а иногда и превосходит производительность суперкомпьютеров семейства Cray T3E с тем же самым числом процессоров. Основная область применения вычислительного кластера НИВЦ МГУ – это поддержка фундаментальных научных исследований и учебного процесса. Из других интересных проектов следует отметить решение, реализованное в Санкт-Петербургском университете на базе технологии Fast Ethernet [8]: собранные кластеры могут использоваться и как полноценные независимые учебные классы, и как единая вычислительная установка, решающая единую задачу. В Самарском научном центре пошли по пути создания неоднородного вычислительного кластера, в составе которого работают компьютеры на базе процессоров Alpha и Pentium III. В Санкт-Петербургском техническом университете собирается установка на основе процессоров Alpha и сети Myrinet без использования локальных дисков на вычислительных узлах. В Уфимском государственном авиационном техническом университете проектируется кластер на базе двенадцати Alpha-станций, сети Fast Ethernet и ОС Linux. |