Кластерные системы
 Скачать 270 Kb. Скачать 270 Kb.
|

Литератураhttp://www.citforum.ru/hardware/svk/glava_12.shtml http://www.beowulf.com http://newton.gsfc.nasa.gov/thehive/ LoBoS, http://www.lobos.nih.gov http://parallel.ru/news/kentucky_klat2.html http://parallel.ru/news/anl_chibacity.html http://parallel.ru/cluster/ http://www.ptc.spbu.ru ResourcesMIMD компьютеры MIMD компьютер имеет N процессоров, независимо исполняющих N потоков команд и обрабатывающих N потоков данных. Каждый процессор функционирует под управлением собственного потока команд, то есть MIMD компьютер может параллельно выполнять совершенно разные программы. 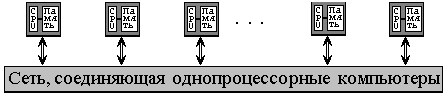 MIMD архитектуры далее классифицируются в зависимости от физической организации памяти, то есть имеет ли процессор свою собственную локальную память и обращается к другим блокам памяти, используя коммутирующую сеть, или коммутирующая сеть подсоединяет все процессоры к общедоступной памяти. Исходя из организации памяти, различают следующие типы параллельных архитектур: Компьютеры с распределенной памятью (Distributed memory) Процессор может обращаться к локальной памяти, может посылать и получать сообщения, передаваемые по сети, соединяющей процессоры. Сообщения используются для осуществления связи между процессорами или, что эквивалентно, для чтения и записи удаленных блоков памяти. В идеализированной сети стоимость посылки сообщения между двумя узлами сети не зависит как от расположения обоих узлов, так и от трафика сети, но зависит от длины сообщения. 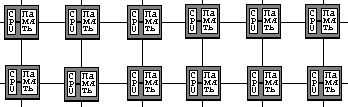 Компьютеры с общей (разделяемой) памятью (True shared memory) Все процессоры совместно обращаются к общей памяти, обычно, через шину или иерархию шин. В идеализированной PRAM (Parallel Random Access Machine - параллельная машина с произвольным доступом) модели, часто используемой в теоретических исследованиях параллельных алгоритмов, любой процессор может обращаться к любой ячейке памяти за одно и то же время. На практике масштабируемость этой архитектуры обычно приводит к некоторой форме иерархии памяти. Частота обращений к общей памяти может быть уменьшена за счет сохранения копий часто используемых данных в кэш-памяти, связанной с каждым процессором. Доступ к этому кэш-памяти намного быстрее, чем непосредственно доступ к общей памяти. 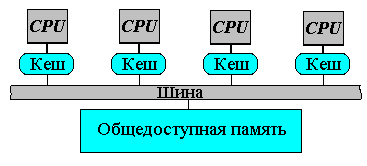 Компьютеры с виртуальной общей (разделяемой) памятью (Virtual shared memory) Общая память как таковая отсутствует. Каждый процессор имеет собственную локальную память и может обращаться к локальной памяти других процессоров, используя "глобальный адрес". Если "глобальный адрес" указывает не на локальную память, то доступ к памяти реализуется с помощью сообщений, пересылаемых по коммуникационной сети. Примером машин с общей памятью могут служить: Sun Microsystems (многопроцессорные рабочие станции) Silicon Graphics Challenge (многопроцессорные рабочие станции) Sequent Symmetry Convex Cray 6400. Следующие компьютеры относятся к классу машин с распределенной памятью IBM-SP1/SP2 Parsytec GC CM5 (Thinking Machine Corporation) Cray T3D Paragon (Intel Corp.) KSR1 nCUBE Meiko CS-2 AVX (Alex Parallel Computers) IMS B008 MIMD архитектуры с распределенной памятью можно так же классифицировать по пропускной способности коммутирующей сети. Например, в архитектуре, в которой пары из процессора и модуля памяти (процессорный элемент) соединены сетью с топологий реш§тка, каждый процессор имеет одно и то же число подключений к сети вне зависимости от числа процессоров компьютера. Общая пропускная способность такой сети растет линейно относительно числа процессоров. С другой стороны в архитектуре, имеющей сеть с топологий гиперкуб, число соединений процессора с сетью является логарифмической функцией от числа процессоров, а пропускная способность сети растет быстрее, чем линейно по отношению к числу процессоров. В топологии клика каждый процессор должен быть соединен со всеми другими процессорами. 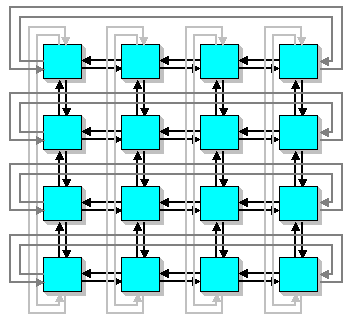 Сеть с топологией 2D реш§тка(тор)   Сеть с топологией 2D тор  Сеть с топологией клика Национального Центра Суперкомпьютерных Приложений (университет шт. Иллинойс, Urbana-Champaign) MPI: The Message Passing Interface Название "интерфейс передачи сообщений", говорит само за себя. Это хорошо стандартизованный механизм для построения параллельных программ в модели обмена сообщениями. Существуют стандартные "привязки" MPI к языкам С/С++, Fortran 77/90. Существуют бесплатные и коммерческие реализации почти для всех суперкомпьютерных платформ, а также для сетей рабочих станций UNIX и Windows NT. В настоящее время MPI - наиболее широко используемый и динамично развивающийся интерфейс из своего класса. Beowulf - кластеры на базе ОС Linux Михаил Кузьминский "Открытые системы" На пороге тысячелетий мы имеем все шансы стать свидетелями монополизации компьютерной индустрии, которая может охватить как микропроцессоры, так и операционные системы. Конечно же, речь идет о микропроцессорах от Intel (Merced грозит вытеснить процессоры архитектуры RISC) и ОС от Microsoft. В обоих случаях успех во многом определяется мощью маркетинговой машины, а не только "потребительскими" свойствами выпускаемых продуктов. По моему мнению, компьютерное сообщество еще не осознало масштабов возможных последствий. Некоторые специалисты сопоставляют потенциальную монополизацию компьютерного рынка с наблюдавшимся в 70-е годы монопольным господством IBM - как в области мэйнфреймов, так и операционных систем. Я долгое время работаю с этой техникой и по мере распространения в нашей стране ОС Unix все больше осознаю многие преимущества операционной системы MVS производства IBM. Тем не менее я разделяю распространенную точку зрения, что подобная монополия не способствовала ускорению прогресса. Западные университеты, которые в свое время одними из первых перешли к использованию Unix, по-прежнему в своих перспективных разработках опираются на эту систему, причем в качестве платформы все чаще избирается Linux. Одной из поучительных академических разработок и посвящена эта статья. Linux как общественное явление Мы уже не удивляемся тому, что Linux cтала заметным явлением компьютерной жизни. В сочетании с богатейшим набором свободно распространяемого программного обеспечения GNU эта операционная система стала чрезвычайно популярна у некоммерческих пользователей как у нас, так и за рубежом. Ее популярность все возрастает. Версии Linux существуют не только для платформы Intel x86, но и для других процессорных архитектур, в том числе DEC Alрha, и широко используются для приложений Internet, а также выполнения задач расчетного характера. Одним словом, Linux стала своеобразной "народной операционной системой". Hельзя, впрочем, сказать, что у Linux нет слабых мест; одно из них - недостаточная поддержка SMР-архитектур. Самый дешевый способ нарастить компьютерные ресурсы, в том числе вычислительную мощность, - это построить кластер. Массивно-параллельные суперкомпьютеры с физически и логически распределенной оперативной памятью также можно рассматривать как своеобразные кластеры. Наиболее яркий пример такой архитектуры - знаменитый компьютер IBM SР2. Весь вопрос в том, что связывает компьютеры (узлы) в кластер. В "настоящих" суперкомпьютерах для этого используется специализированная и поэтому дорогая аппаратура, призванная обеспечить высокую пропускную способность. В кластерах, как правило, применяются обычные сетевые стандарты - Ethernet, FDDI, ATM или HiРРI. Кластерные технологии с использованием операционной системы Linux начали развиваться несколько лет назад и стали доступны задолго до появления Wolfрack для Windows NT. Так в середине 90-х годов и возник проект Beowulf. Герой эпической поэмы "Беовульф" - это скандинавский эпос, повествующий о событиях VII - первой трети VIII века, участником которых является одноименный герой, прославивший себя в сражениях. Неизвестно, задумывались ли авторы проекта, с кем ныне будет сражаться Beowulf (вероятно, с Windows NT?), однако героический образ позволил объединить в консорциум около полутора десятков организаций (главным образом университетов) в Соединенных Штатах. Нельзя сказать, что среди участников проекта доминируют суперкомпьютерные центры, однако кластеры "Локи" и "Мегалон" установлены в таких известных в мире высокопроизводительных вычислений центрах, как Лос-Аламос и лаборатория Sandia Министерства энергетики США; ведущие разработчики проекта - специалисты агентства NASA. Вообще, все без исключения кластеры, созданные участниками проекта, получают громкие имена. Кроме Beowulf, известна еще одна близкая кластерная технология - NOW. В NOW персональные компьютеры обычно содержат информацию о самих себе и поставленных перед ними задачах, а в обязанности системного администратора такого кластера входит формирование данной информации. Кластеры Beowulf в этом отношении (то есть с точки зрения системного администратора) проще: там отдельные узлы не знают о конфигурации кластера. Лишь один выделенный узел содержит информацию о конфигурации; и только он имеет связь по сети с внешним миром. Все остальные узлы кластера объединены локальной сетью, и с внешним миром их связывает только "тоненький мостик" от управляющего узла. Узлами в технологии Beowulf являются материнские платы ПК. Обычно в узлах задействованы также локальные жесткие диски. Для связи узлов используются стандартные типы локальных сетей. Этот вопрос мы рассмотрим ниже, сначала же остановимся на программном обеспечении. Его основу в Beowulf составляет обычная коммерчески доступная ОС Linux, которую можно приобрести на CD-ROM. Первое время большинство участников проекта ориентировались на компакт-диски, издаваемые Slackware, а сейчас предпочтение отдаетcя версии RedHat. В обычной ОС Linux можно инсталлировать известные средства распараллеливания в модели обмена сообщениями (LAM MРI 6.1, РVM 3.3.11 и другие). Можно также воспользоваться стандартом р-threads и стандартными средствами межпроцессорного взаимодействия, входящими в любую ОС Unix System V. В рамках проекта Beowulf были выполнены и серьезные дополнительные разработки. Прежде всего следует отметить доработку ядра Linux 2.0. В процессе построения кластеров выяснилось, что стандартные драйверы сетевых устройств в Linux весьма неэффективны. Поэтому были разработаны новые драйверы (автор большинства разработок - Дональд Бекер), в первую очередь для сетей Fast Ethernet и Gigabit Ethernet, и обеспечена возможность логического объединения нескольких параллельных сетевых соединений между персональными компьютерами, что позволяет из дешевых локальных сетей, обладающих более чем скромной скоростью, соорудить сеть с высокой совокупной пропускной способностью. Как и во всяком кластере, в каждом узле живет своя копия ядра ОС. Благодаря доработкам обеспечена уникальность идентификаторов процессов в рамках всего кластера, а не отдельных узлов, а также "удаленная доставка" сигналов ОС Linux. Кроме того, надо отметить функции загрузки по сети (netbooting) при работе с материнскими платами Intel РR 440FX, причем они могут применяться и для работы с другими материнскими платами, снабженными AMI BIOS. Очень интересные возможности предоставляют механизмы сетевой виртуальной памяти (Network Virtual Memory) или разделяемой распределенной памяти DSM (Distributed Shared Memory), позволяющие создать для процесса определенную "иллюзию" общей оперативной памяти узлов. Сеть - дело тонкое Поскольку для распараллеливания суперкомпьютерных приложений вообще, и кластерных в частности, необходима высокая пропускная способность и низкие задержки для обмена сообщениями между узлами, сетевые характеристики становятся параметрами, определяющими производительность кластера. Выбор микропроцессоров для узлов очевиден - это стандартные процессоры производства Intel; а вот с топологией кластера, типом сети и сетевых плат можно поэкспериментировать. Именно в этой области и проводились основные исследования. При анализе различных сетевых плат ПК, представленных сегодня на рынке, особое внимание было уделено таким характеристикам, как эффективная поддержка широковещательной рассылки (multicasting), поддержка работы с пакетами больших размеров и т. д. Основные типы локальных сетей, задействованные в рамках проекта Beowulf, - это Gigabit Ethernet, Fast Ethernet и 100-VG AnyLAN. (Возможности ATM-технологии также активно исследовались, но, насколько известно автору, это делалось вне рамок данного проекта.) Как самому собрать суперкомпьютер Проанализировав итоги работ, выполненных в рамках проекта Beowulf, можно прийти к следующему выводу: найденные решения позволяют самостоятельно собрать высокопроизводительный кластер на базе стандартных для ПК компонентов и использовать обычное программное обеспечение. Среди самых крупных экземпляров нельзя не отметить 50-узловой кластер в CESDIS, включающий 40 узлов обработки данных (на базе одно- и двухпроцессорных плат Рentium Рro/200 МГц) и 10 масштабирующих узлов (двухпроцессорная плата Рentium Рro/166 МГц). Соотношение стоимость/пиковая производительность в таком кластере представляется очень удачным. Вопрос в том, насколько эффективно удается распараллелить приложения - иными словами, какова будет реальная, а не пиковая производительность. Над решением этой проблемы сейчас и работают участники проекта. Следует отметить, что построение кластеров из обычных ПК становится сегодня достаточно модным в научной среде. Некоторые академические институты в нашей стране также планируют создать подобные кластеры. При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах. Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. В случае, когда это не нужно, узлы могут быть существенно облегчены и/или установлены в стойку. Используются стандартные для рабочих станций ОС, чаще всего, свободно распространяемые - Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и распределения нагрузки. Программирование, как правило, в рамках модели передачи сообщений (чаще всего - MPI). Более подробно она рассмотрена в следующем параграфе. |