Компьютерные сети. Принц, техн, прот 1-303. Книга переведена на английский, испанский, китайский и португальский языки
 Скачать 5.49 Mb. Скачать 5.49 Mb.
|

|
Отображение потоков SDH Первое обстоятельство, на которое нужно обратить внимание, – кадры STM-N по своим размерам превышают размер поля данных кадра OTN. Действительно, кадр STM-16 имеет размер 16 х 9 х 270 байт = 38 880 байт, в то время как поле данных кадра OTN имеет размер 15 232 байта, то есть для переноса одного кадра STM-16 необходимо примерно 2,5 кадра OTN. Решение состоит в том, что данные кадров STM размещаются в поле данных кадра OTN сплошным потоком, без учета границ между кадрами OTN. При доставке кадров OTN до конечного мультиплексора данные пользовательских кадров STM также извлекаются сплошным потоком, предоставляя пользовательскому оборудованию самому разбирать этот поток на пользовательские кадры, используя для этого признаки начала кадра STM (рис. 9.11). На рисунке показаны четыре последовательных кадра OTN, в поле данных которых помещены данные кадров STM-16. Начало каждого кадра STM-16 никак не синхронизировано с началом поля данных OPU кадра OTN. Иногда бывает полезно рассматривать последовательность кадров OTN как мультикадр. Мультикадр OTN состоит из 256 кадров. В заголовке OTU ОН кадра имеется специальное однобайтовое поле MFAS (Multi Frame Alignment Signal), позволяющее рассматривать каждый кадр как часть мультикадра. Поле MFAS работает как счетчик, принимающий значения от 0 до 255. Значение счетчика наращивается для каждого последующего кадра. Например, если у первого кадра OTN, показанного на рисунке, значение поля MFAS равно 15, то у второго оно равно 16, у третьего – 17 и у четвертого – 18. Все четыре кадра принадлежат одному мультикадру, занимая в нем промежуточные места с 15-го по 18-е. 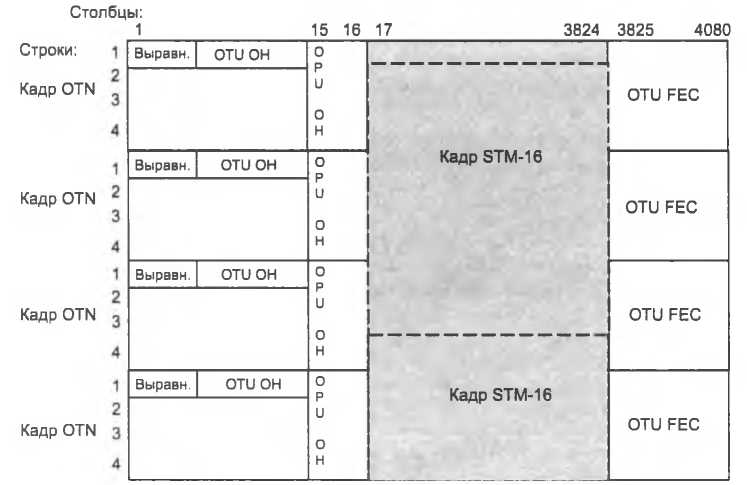 Преимуществом объединения кадров является то, что у мультикадра некоторые поля заголовков кадра считаются общими, то есть рассматриваются как непрерывное поле, состоящее из N х 256 байт, где N – длина поля в заголовке отдельного кадра. Например, поле идентификатора пути TTI (Trail Trace Identifier) из заголовка OTU ОН содержит два идентификатора – идентификатор мультиплексора источника и идентификатор мультиплексора назначения. Каждый идентификатор состоит из 16 байт, то есть для его размещения необходимо 32 байта, но в заголовке OTU ОН для поля TTI отведен только один байт. Проблема решается за счет того, что данные TTI размещаются в последовательных 32 кадрах мультикадра, по одному байту в каждом кадре. Преимуществом объединения кадров является то, что у мультикадра некоторые поля заголовков кадра считаются общими, то есть рассматриваются как непрерывное поле, состоящее из N х 256 байт, где N – длина поля в заголовке отдельного кадра. Например, поле идентификатора пути TTI (Trail Trace Identifier) из заголовка OTU ОН содержит два идентификатора – идентификатор мультиплексора источника и идентификатор мультиплексора назначения. Каждый идентификатор состоит из 16 байт, то есть для его размещения необходимо 32 байта, но в заголовке OTU ОН для поля TTI отведен только один байт. Проблема решается за счет того, что данные TTI размещаются в последовательных 32 кадрах мультикадра, по одному байту в каждом кадре.Выравнивание потоков SDH Для помещения пользовательских данных (кадров STM-N) в поля данных OPU, а также для выравнивания их скоростей в стандарте OTN определены две процедуры: BMP (Bit-synchronous Mapping Procedure) – процедура бит-синхронного отображения нагрузки; AMP (Asynchronous Mapping Procedure, AMP) – процедура асинхронного отображения нагрузки. Процедура BMPсинхронизирует прием байтов из пользовательского потока, используя синхробайты из заголовка кадра STM-N. В этом случае механизм выравнивания фактически простаивает, так как скорость передачи данных всегда равна скорости их поступления. Процедура АМР используется, если мультиплексор OTN синхронизируется от собственного источника синхроимпульсов, который не зависит от пользовательских данных (это может быть любой из способов синхронизации, рассмотренных в разделе, посвященном технологии PDH). В этом случае рассогласование скоростей неизбежно и необходим механизм выравнивания. Механизм выравнивания АМР подобен механизму положительного и отрицательного выравнивания SDH, но без использования указателя на начало пользовательского кадра. Указатель для процедуры АМР не нужен, потому что мультиплексор OTN игнорирует внутреннюю структуру пользовательских данных, не занимается выделением из потока пользовательских байтов кадров STM-N и коммутацией контейнеров разного уровня, содержащихся в этих кадрах, – это дело вышележащего уровня, реализованного в клиентском оборудовании SDH, которое подключено к портам сети OTN. Для выравнивания скоростей в кадре OTN используются два байта (см. рис. 9.11): байт возможности отрицательного выравнивания NJO(Negative Justification Opportunity), находящийся в заголовке OPU ОН, а также байт возможности положительного выравнивания PJO(Positive Justification Opportunity), размещенный в поле пользовательских данных, сразу после байта NJO. Говоря о выравнивании скоростей, можно заметить, что существует только три возможных варианта: скорость пользовательских данных и скорость мультиплексора' равны, в этом случае скорость выравнивать не нужно, мультиплексор помещает все пользовательские байты в поле данных, используя в том числе байт PJO. Байт NJO остается пустым байтом выравнивания; скорость пользовательского потока выше скорости мультиплексора', лишний байт пользовательских данных помещается в поле NJO – то есть происходит отрицательное выравнивание. В этом случае в оба байта, NJO и PJO, загружены данные; скорость пользовательского потока меньше скорости мультиплексора, и ему не хватает байтов для заполнения поля данных. В этом случае в байт PJO вставляется «запол- 1 Под скоростью мультиплексора здесь понимается скорость передачи блока OPU. нитель», который представляет собой байт с нулевым значением, – так выполняется положительное выравнивание. Таким образом, в данном случае оба байта, NJO и PJO, оказываются пустыми. Рис. 9.12. Заголовок выравнивания JOH и байты выравнивания NJO и PJO Чтобы конечный мультиплексор сети мог правильно выполнить демультиплексирование пользовательских данных, ему нужна информация о том, как обстояло дело с выравниванием, были ли заполнены байты NJO и PJO данными или они находятся в своем исходном нулевом состоянии. Такую информацию мультиплексор извлекает из специально предназначенного для этих целей байта управления выравниванием (Justification Control, JC). На рис. 9.12 показано, что в 16-м столбце заголовка OPU ОН, называющемся заголовком выравнивания (Justification OverHead, JOH), находится три копии байта J С. Это повышает надежность – в случае искажения битов одной из копий мультиплексор может голосованием решить, какая копия является корректной. В байте управления выравниванием JC используется только два младших бита. Из четырех возможных значений, которые могут принимать эти два бита, используется три: 00, 01 и 11, каждая комбинация кодирует один из трех возможных вариантов соотношения скоростей, которые были рассмотрены выше. В таблице на рис. 9.12 символ J означает, что соответствующий байт выравнивания не содержит данных, а символ D – содержит. Легко видеть, что значение 00 соответствует случаю, когда скорости были равны, 01 – когда скорость пользовательских данных опережала скорость мультиплексора, 11 – скорость мультиплексора превысила скорость данных. Отображение и выравнивание компьютерного трафика Компьютерный трафик имеет, как мы знаем, пульсирующий характер, хотя данные внутри каждого кадра (например, кадра Ethernet) поступают с постоянной битовой скоростью, из- за случайных пауз между кадрами средняя скорость поступления данных в мультиплексор OTN может колебаться в больших пределах, от нуля на некоторых периодах (периоды молчания) до битовой скорости протокола на других. Для выравнивания такой неравномерности процедура отображения компьютерных данных вставляет в периоды молчания пустые компьютерные кадры – кадры, состоящие только из заголовка, в котором указывается нулевая длина поля данных. 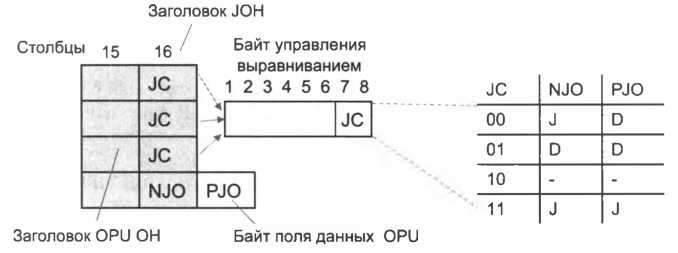 Для того чтобы эта процедура была прозрачной, то есть не зависела от протокола компьютерной сети, исходный компьютерный кадр упаковывается в кадр формата обобщенной про цедуры инкапсуляции данныхGFP(Generic Framing Procedure), специально разработанного ITU-T для единообразного обрамления пользовательских кадров любого формата. Так, если данные поступают в виде кадров Ethernet, то перед размещением их в поле данных к ним добавляют заголовок GFP Для того чтобы эта процедура была прозрачной, то есть не зависела от протокола компьютерной сети, исходный компьютерный кадр упаковывается в кадр формата обобщенной про цедуры инкапсуляции данныхGFP(Generic Framing Procedure), специально разработанного ITU-T для единообразного обрамления пользовательских кадров любого формата. Так, если данные поступают в виде кадров Ethernet, то перед размещением их в поле данных к ним добавляют заголовок GFPЗаголовок GFP состоит из четырех байтов, два из которых отводятся для хранения длины его поля данных (ноль, если это пустой кадр, и длина инкапсулированного кадра в противном случае), а еще два – для контрольной суммы поля данных. Процедура GFP поддерживает два режима работы: GFP-F(кадровый режим, или Frame Mode) и GFP-Т (прозрачный режим, или Transparent Mode). Режим GFP-F предназначен для инкапсуляции компьютерных кадров, а режим GFP-T – для инкапсуляции данных синхронного чувствительного к задержкам трафика, отличного от SDH, например, протокола сетей хранения данных Fibre Channel. Особенностью режима GFP-Т является то, что исходный синхронный поток байтов разбивается на блоки равной длины и к ним добавляется заголовок, который позволяет распознать начало блока и корректность данных в нем по контрольной сумме блока. Заголовки кадров режимов GFP-F и GFP-Т имеют одинаковый формат. Итак, пусть на входной порт мультиплексора OTN поступает очередной кадр компьютерной сети. Перед передачей его в составе данных поля OPU в сеть он полностью буферизуется, так как асинхронный характер компьютерного трафика это позволяет; для него вычисляется контрольная сумма, добавляется заголовок GFP. Упакованный таким образом компьютерный кадр размещается в поле данных кадра OTN (рис. 9.13) и побайтно передается на выходной порт мультиплексора OTN. Если к моменту окончания передачи всех байтов этого компьютерного кадра следующий кадр компьютерной сети еще нс поступил в буфер, то в поле данных кадра OTN помещается пустой кадр GFP, то есть четырехбайтный заголовок с указанием нулевой длины поля данных. Тем самым выравниваются скорости поступления пользовательских данных и передачи кадра OTN. Мультиплексирование блоков OTN  Как и во всех других технологиях, мультиплексирование в OTN используется для эффективной передачи по высокоскоростной магистрали многих пользовательских потоков, имеющих более низкую скорость. Как и во всех других технологиях, мультиплексирование в OTN используется для эффективной передачи по высокоскоростной магистрали многих пользовательских потоков, имеющих более низкую скорость.В OTN данные нескольких блоков ODU некоторого уровня скорости мультиплексируются в поле данных OPU более высокого уровня скорости, причем не обязательно следующего. Это означает, что блоки ODU1 могут мультиплексироваться как в блоки второго уровня OPU2, так и в блоки третьего уровня OPU3. Принцип мультиплексирования Рассмотрим технику мультиплексирования OTN на примере мультиплексирования четырех блоков ODU1 в один блок OTU2. Чтобы скорость данных блока низшего уровня осталась прежней в том случае, когда они переносятся по сети в блоках более высокого уровня, кратность мультиплексирования должна соответствовать кратности скоростей уровней. Так как скорость ODU2 в 4 раза выше скорости ODU1, то и кратность мультиплексирования ODU1 в ODU2 должна быть равна 4. 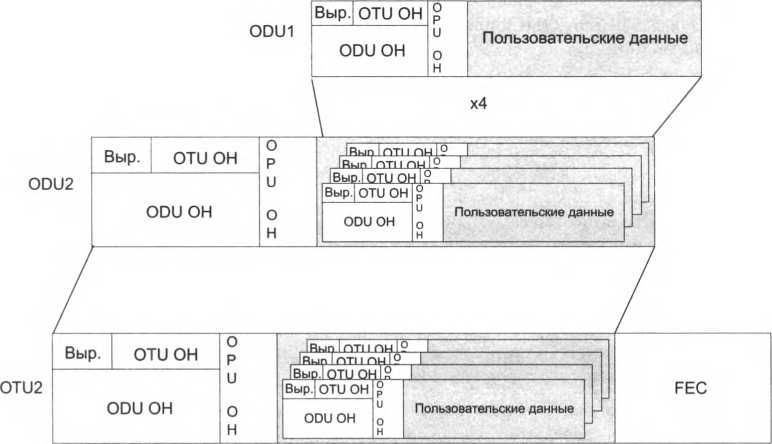 На рис. 9.14 показано, что каждый из четырех блоков ODU1 мультиплексируется в поле данных ODU2, который после добавления концевика FEC превращается в блок OTU2. На рисунке этапы мультиплексирования блоков ODU1 показаны очень упрощенно, многие детали опущены, например, то, что для помещения четырех блоков ODU в поле данных ODU2 нужен не один, а четыре последовательных кадра ODU2. Для упорядоченного размещения блоков ODU 1 в поле OPU2 это поле разбивается на так называемые |