Компьютерные сети. Принц, техн, прот 1-303. Книга переведена на английский, испанский, китайский и португальский языки
 Скачать 5.49 Mb. Скачать 5.49 Mb.
|

|
протоколе разрешения адресов (Address Resolution Protocol, ARP) стека TCP/IP. Достоинство распределенного подхода состоит в том, что он позволяет отказаться от выделения специального компьютера в качестве сервера имен, который к тому же часто требует ручного задания таблицы соответствия адресов. Недостатком его является необходимость широковещательных сообщений, перегружающих сеть. Именно поэтому распределенный подход используется в небольших сетях, а централизованный – в больших. До сих пор мы говорили об адресах сетевых интерфейсов, компьютеров и коммуникационных устройств, однако конечной целью данных, пересылаемых по сети, являются не сетевые интерфейсы или компьютеры, а выполняемые на этих устройствах программы – процессы. Поэтому в адресе назначения наряду с информацией, идентифицирующей интерфейс устройства, должен указываться адрес процесса, которому предназначены посылаемые по сети данные. Очевидно, что достаточно обеспечить уникальность адреса процесса в пределах компьютера. Примером адресов процессов являются номера портов TCPи UDP, используемые в стеке TCP/IP. Коммутация Пусть компьютеры физически связаны между собой в соответствии с некоторой топологией, выбрана система адресации. Остается нерешенным вопрос: каким образом передавать данные между конечными узлами? Особую сложность приобретает эта задача для неполносвязной топологии сети, когда обмен данными между произвольной парой конечных узлов (пользователей) должен идти в общем случае через транзитные узлы. Соединение конечных узлов через сеть транзитных узлов называют коммутацией. Последовательность узлов, лежащих на пути от отправителя к получателю, образует маршрут. Например, в сети, показанной на рис. 2.12, узлы 2 и 4, непосредственно между собой не связанные, вынуждены передавать данные через транзитные узлы, в качестве которых могут выступить, например, узлы 1 и 5. Узел 1 должен выполнить передачу данных между своими интерфейсами А и В, а узел 5 – между интерфейсами FhВ. В данном случае маршрутом является последовательность: 2-1-5-4, где 2 – узел-отправитель, 1 и 5 – транзитные узлы, 4 – узел-получатель. 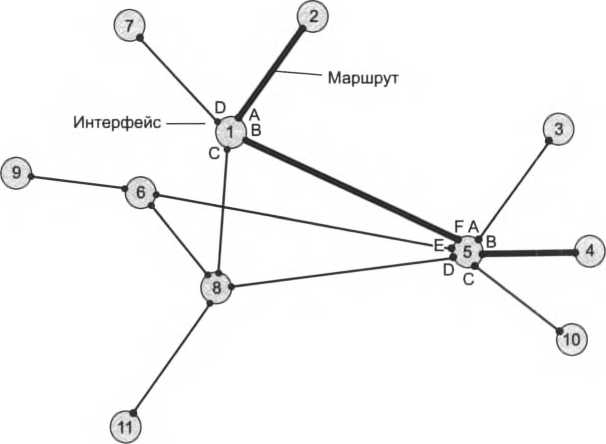 Обобщенная задача коммутации В самом общем виде задача коммутации может быть представлена в виде следующих взаимосвязанных частных задач: Определение информационных потоков, для которых требуется прокладывать маршруты. Маршрутизация потоков – прокладка маршрутов. Продвижение потоков, то есть распознавание потоков и их локальная коммутация на каждом транзитном узле. Мультиплексирование и демультиплексирование потоков. Определение информационных потоков Понятно, что через один транзитный узел может проходить несколько маршрутов, например, через узел 5 (см. рис. 2.12) проходят как минимум все данные, направляемые узлом 4 каждому из остальных узлов, а также все данные, поступающие в узлы 3, 4 и 10. Транзитный узел должен уметь распознавать поступающие на него потоки данных, чтобы обеспечивать передачу каждого из них именно на тот свой интерфейс, который ведет к нужному узлу, и, возможно, чтобы выбрать специфический для данного потока способ его обработки. Информационным потоком, или потоком данных, называют непрерывную последовательность данных, объединенных набором общих признаков, выделяющих эти данные из общего сетевого трафика. Например, как поток можно определить все данные, поступающие от одного компьютера; объединяющим признаком в данном случае служит адрес источника. Эти же данные можно представить как совокупность нескольких подпотоков, каждый из которых в качестве дифференцирующего признака имеет адрес назначения. Наконец, каждый из этих подпотоков, в свою очередь, можно разделить на более мелкие подпотоки, порожденные разными сетевыми приложениями – электронной почтой, программой копирования файлов, вебсервером. Данные, образующие поток, могут быть представлены в виде последовательности различных информационных единиц данных – пакетов, кадров, ячеек. ПРИМЕЧАНИЕ В англоязычной литературе для потоков данных, передающихся с равномерной и неравномерной скоростью, обычно используют разные термины – соответственно «data stream» и «data flow». Например, при передаче веб-страницы через Интернет предложенная нагрузка представляет собой неравномерный поток данных, а при вещании музыки интернет-станцией – равномерный. Для сетей передачи данных характерна неравномерная скорость передачи, поэтому далее в большинстве ситуаций под термином «поток данных» мы будем понимать именно неравномерный поток данных и указывать на равномерный характер этого процесса только тогда, когда это нужно подчеркнуть. Очевидно, что при коммутации в качестве обязательного признака выступает адрес назначения данных. На основании этого признака весь поток входящих в транзитный узел данных разделяется на подпотоки, каждый из которых передается на интерфейс, соответствующий тому или иному маршруту продвижения данных. Адреса источника и назначения определяют поток для пары соответствующих конечных узлов. Однако часто бывает полезно представить этот поток в виде нескольких подпотоков, причем для каждого из них может быть проложен свой особый маршрут. Рассмотрим пример, когда на одной и той же паре конечных узлов выполняется несколько взаимодействующих по сети приложений, каждое из которых предъявляет к сети свои особые требования. В таком случае выбор маршрута должен осуществляться с учетом характера передаваемых данных, например, для файлового сервера важно, чтобы передаваемые им большие объемы данных направлялись по каналам, обладающим высокой пропускной способностью, а для программной системы управления, которая посылает в сеть короткие сообщения, требующие обязательной и немедленной отработки, при выборе маршрута более важна надежность линии связи и минимальный уровень задержек на маршруте. Кроме того, даже для данных, предъявляющих к сети одинаковые требования, может прокладываться несколько маршрутов, чтобы за счет распараллеливания ускорить передачу данных. Возможна и обратная по отношению к выделению подпотоков операция – агрегирование потоков. Обычно она выполняется на магистралях сетей, которые передают очень большое количество индивидуальных потоков. Агрегирование потоков, имеющих общую часть маршрута через сеть, позволяет уменьшить количество хранимой промежуточными узлами сети информации, так как агрегированные потоки описываются в них как одно целое. В результате снижается нагрузка на промежуточные узлы сети и повышается их быстродействие. Признаки потока могут иметь глобальное или локальное значение – в первом случае они однозначно определяют поток в пределах всей сети, а во втором – в пределах одного транзитного узла. Пара идентифицирующих поток адресов конечных узлов – это пример глобального признака. Примером признака, локально определяющего поток в пределах устройства, может служить номер (идентификатор) интерфейса данного устройства, на который поступили данные. Например, возвращаясь к рис. 2.12, узел 1 может быть настроен так, чтобы передавать на интерфейс В все данные, поступившие с интерфейса Л, а на интерфейс С – данные, поступившие с интерфейса D. Такое правило позволяет отделить поток данных узла 2 от потока данных узла 7 и направлять их для транзитной передачи через разные узлы сети, в данном случае поток узла 2 – через узел 5, а поток узла 7 – через узел 8. Метка потока – это особый тип признака. Она представляет собой некоторое число, которое несут все данные потока. Глобальная метка назначается данным потока и не меняет своего значения на всем протяжении его пути следования от узла источника до узла назначения, таким образом, она уникально определяет поток в пределах сети. В некоторых технологиях используются локальные метки потока, динамически меняющие свое значение при передаче данных от одного узла к другому. Таким образом, распознавание потоков во время коммутации происходит на основании признаков, в качестве которых, помимо обязательного адреса назначения данных, могут выступать и другие признаки – такие, например, как идентификаторы приложений. Маршрутизация Задача маршрутизации, в свою очередь, включает в себя две подзадачи: определение маршрута; оповещение сети о выбранном маршруте. Определить маршрут означает выбрать последовательность транзитных узлов и их интерфейсов, через которые надо передавать данные, чтобы доставить их адресату. Определение маршрута – сложная задача, особенно когда конфигурация сети такова, что между парой взаимодействующих сетевых интерфейсов существует множество путей. Чаще всего выбор останавливают на одном оптимальном'VI по некоторому критерию маршруте. В качестве критериев оптимальности могут выступать, например, пропускная способность и загруженность каналов связи; задержки, вносимые каналами; количество промежуточных транзитных узлов; надежность каналов и транзитных узлов. Маршрут может определяться эмпирически («вручную») администратором сети на основании различных, часто не формализуемых соображений. Среди побудительных мотивов выбора пути могут быть: особые требования к сети со стороны различных типов приложений, решение передавать трафик через сеть определенного поставщика услуг, предположения о пиковых нагрузках на некоторые каналы сети, соображения безопасности. Однако эмпирический подход к определению маршрутов малопригоден для большой сети со сложной топологией. В этом случае используются автоматические методы определения маршрутов. Для этого конечные узлы и другие устройства сети оснащаются специальными программными средствами, которые организуют взаимный обмен служебными сообщениями, позволяющий каждому узлу составить свое «представление» о сети. Затем на основе собранных данных программными методами определяются рациональные маршруты. При выборе маршрута часто ограничиваются только информацией о топологии сети. Этот подход иллюстрирует рис. 2.13. Для передачи трафика между конечными узлами А и С существуют два альтернативных маршрута: А-1-2-3-С и А-1-3-С. Если мы учитываем только топологию, то выбор очевиден – маршрут А-1-3-С, который имеет меньше транзитных узлов. 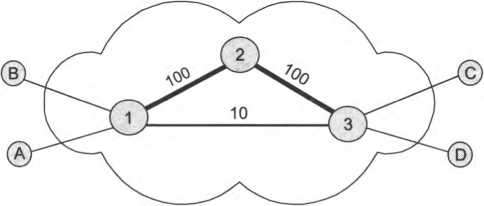 Решение было найдено путем минимизации критерия, в качестве которого в данном примере выступала длина маршрута, измеренная количеством транзитных узлов. Однако, возможно, наш выбор был не самым лучшим. На рисунке показано, что каналы 1-2 и 2-3 обладают пропускной способностью 100 Мбит/с каждый, а канал 1-3 – только 10 Мбит/с. Чтобы наша информация передавалась по сети с максимально возможной скоростью, следовало бы выбрать маршрут А-1-2-3-С, хотя он и проходит через большее количество промежуточных узлов. То есть можно сказать, что маршрут А-1-2-3-С в данном случае оказывается «более коротким». Абстрактная оценка условного «расстояния» между двумя узлами сети называется метрикой. Так, для измерения длины маршрута могут быть использованы разные метрики – количество транзитных узлов, как в предыдущем примере, линейная протяженность маршрута и даже его стоимость в денежном выражении. Для построения метрики, учитывающей пропускную способность, часто применяют следующий прием: длину каждого канала-участка характеризуют величиной, обратной его пропускной способности. Чтобы оперировать целыми числами, выбирают некоторую константу, заведомо большую, чем пропускные способности каналов в сети. Например, если мы в качестве такой константы выберем 100 Мбит/с, то метрика каждого из каналов 1-2 и 2-3 равна 1, а метрика канала 1-3 составляет 10. Метрика маршрута равна сумме метрик составляющих его каналов, поэтому часть пути 1-2-3 обладает метрикой 2, а альтернативная часть пути 1-3 – метрикой 10. Мы выбираем более «короткий» путь, то есть путь Л-1-2-3-С. Описанные подходы к выбору маршрутов не учитывают текущую степень загруженности каналов трафикомVII. Используя аналогию с автомобильным трафиком, можно сказать, что мы выбирали маршрут по карте, учитывая количество промежуточных городов и ширину дороги (аналог пропускной способности канала), отдавая предпочтение скоростным магистралям. Но при этом мы не учли радио- или телесообщения о текущих заторах на дорогах. Так что наше решение оказывается отнюдь не лучшим, когда по маршруту А-1-2-3-С уже передается большое количество потоков, а маршрут А-1-3-С практически свободен. После того как маршрут определен (вручную или автоматически), надо оповестить о нем все устройства сети. Сообщение о маршруте должно нести каждому транзитному устройству примерно такую информацию: «каждый раз, когда в устройство поступят данные, относящиеся к потоку п, их следует передать для дальнейшего продвижения на интерфейс г/1». Каждое подобное сообщение о маршруте обрабатывается транзитным устройством, в результате создается новая запись в таблице коммутации (называемой также таблицей маршрутизации) данного устройства. В этой таблице локальному или глобальному признаку (признакам) потока (например, метке, номеру входного интерфейса или адресу назначения) ставится в соответствие номер интерфейса, на который устройство должно передавать данные, относящиеся к этому потоку. Таблица 2.1 является фрагментом таблицы коммутации, содержащим запись, сделанную на основании сообщения о необходимости передачи потока п на интерфейс г/1. Таблица 2.1. Фрагмент таблицы коммутации
В этой таблице в качестве признака потока использованы адрес назначения DA, адрес источника SA и тип приложения А, которое генерирует пакеты потока. Оповещение транзитных устройств о выбранных маршрутах, как и определение маршрута, может осуществляться вручную или автоматически. Администратор сети может зафиксировать маршрут, выполнив в ручном режиме конфигурирование устройства, например, жестко скоммутировав на длительное время определенные пары входных и выходных интерфейсов (как работали «телефонные барышни» на первых коммутаторах). Он может также по собственной инициативе внести запись о маршруте в таблицу коммутации. Однако поскольку топология и состав информационных потоков могут меняться (отказы узлов или появление новых промежуточных узлов, изменение адресов или определение новых потоков), гибкое решение задач определения и задания маршрутов предполагает постоянный анализ состояния сети и обновление маршрутов и таблиц коммутации. В таких случаях задачи прокладки маршрутов, как правило, не могут быть решены без достаточно сложных программных и аппаратных средств. Продвижение данных Итак, пусть маршруты определены, записи о них сделаны в таблицах всех транзитных узлов, все готово к выполнению основной операции – передаче данных между абонентами (коммутации абонентов). Для каждой пары абонентов эта операция может быть представлена несколькими (по числу транзитных узлов) локальными операциями коммутации. Прежде всего отправитель должен выставить данные на тот свой интерфейс, с которого начинается найденный маршрут, а все транзитные узлы должны соответствующим образом выполнить «переброску» данных с одного своего интерфейса на другой, другими словами, выполнить |