Консп. конспект_ лекций_СПД. Конспект лекций по курсу "Системы передачи данных" Для студентов, обучающихся по направлению
 Скачать 4.08 Mb. Скачать 4.08 Mb.
|

|
1.5. Появление стандартных технологий локальных сетей В середине 80-х годов ХХ века положение дел в локальных сетях стало меняться. Утвердились стандартные технологии объединения компьютеров в сеть – Ethernet, Arcnet, Token Ring, Token Bus, несколько позже – FDDI. Все стандартные технологии локальных сетей опирались на тот же принцип коммутации, который был с успехом опробован и доказал свои преимущества при передаче трафика данных в глобальных компьютерных сетях – принцип коммутации пакетов. Стандартные сетевые технологии сделали задачу построения локальной сети почти тривиальной. Для создания сети достаточно было приобрести сетевые адаптеры соответствующего стандарта, например Ethernet, стандартный кабель, присоединить адаптеры к кабелю стандартными разъемами и установить на компьютер одну из популярных сетевых операционных систем, например Novell NetWare. После этого сеть начинала работать, и последующее присоединение каждого нового компьютера не вызывало никаких проблем – естественно, если на нем был установлен сетевой адаптер той же технологии. В 80-е годы были приняты основные стандарты на коммуникационные технологии для локальных сетей: в 1980 году – Ethernet, в 1985 – Token Ring, в конце 80-х – FDDI. Это позволило обеспечить совместимость сетевых операционных систем на нижних уровнях, а также стандартизировать интерфейс ОС с драйверами сетевых адаптеров. Конец 90-х выявил явного лидера среди технологий локальных сетей – семейство Ethernet, в которое вошли классическая технология Ethernet 10 Мбит/c, а также Fast Ethernet 100 Мбит/c и Gigabit Ethernet 1000 Мбит/c. Простые алгоритмы работы предопределили низкую стоимость оборудования Ethernet. Широкий диапазон иерархии скоростей позволяет рационально строить локальную сеть, применяя ту технологию, которая в наибольшей степени отвечает задачам предприятия и потребностям пользователей. Важно также, что все технологии Ethernet очень близки друг другу по принципам работы, что упрощает обслуживание и интеграцию построенных на их основе сетей. 2. ОСНОВНЫЕ ПРОБЛЕМЫ ПОСТРОЕНИЯ КОМПЬЮТЕРНЫХ СЕТЕЙ При создании вычислительных сетей разработчикам пришлось решать множество самых разных задач, связанных с кодированием и синхронизацией электрических (оптических) сигналов, выбором конфигурации физических и логических связей, разработкой схем адресации устройств, созданием различных способов коммутации, мультиплексированием и демультиплексированием потоков данных, совместным использованием передающей среды. Начнем с наиболее простого случая непосредственного соединения двух устройств физическим каналом, такое соединение называется связью "точка-точка" (point-to-point). 2.1. Связь компьютера с периферийными устройствами Частным случаем связи "точка-точка" является соединение компьютера с периферийным устройством. Поскольку механизмы взаимодействия компьютеров в сети многое позаимствовали у схемы взаимодействия компьютера с периферийными устройствами, начнем рассматривать принципы работы сети с этого "досетевого" случая. Для обмена данными компьютер и периферийное устройство (ПУ) оснащены внешними интерфейсами или портами (рис. 2.1). В данном случае к понятию "интерфейс" относятся: • электрический разъем; • набор проводов, соединяющих устройства; • совокупность правил обмена информацией по этим проводам. Со стороны компьютера логикой передачи сигналов на внешний интерфейс управляют: • контроллер ПУ– аппаратный блок, часто реализуемый в виде отдельной платы; • драйвер ПУ– программа, управляющая контроллером периферийного устройства. 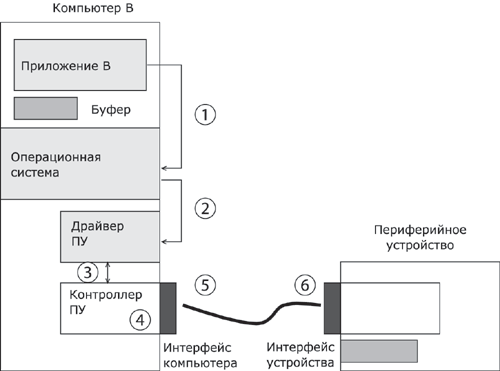 Рисунок 2.1. Связь компьютера с периферийным устройством Со стороны ПУ интерфейс чаще всего реализуется аппаратным устройством управления ПУ, хотя встречаются и программно-управляемые периферийные устройства. Обмен данными между ПУ и компьютером, как правило, является двунаправленным. Так, например, даже принтер, который представляет собой устройство вывода информации, возвращает в компьютер данные о своем состоянии. Таким образом, по каналу, связывающему внешние интерфейсы, передается следующая информация: − данные, поступающие от контроллера на ПУ, например байты текста, который нужно распечатать на бумаге; − команды управления, которые контроллер передает на устройство управления ПУ; в ответ на них оно выполняет специальные действия, например переводит головку диска на соответствующую дорожку или же выталкивает из принтера лист бумаги; − данные, возвращаемые устройством управления ПУ в ответ на запрос от контроллера, например данные о готовности к выполнению операции. Рассмотрим последовательность действий, которые выполняются в том случае, когда некоторому приложению требуется напечатать текст на принтере. 1. Приложение обращается с запросом на выполнение операции печати к операционной системе. В запросе указываются: адрес данных в оперативной памяти, идентифицирующая информация принтера и операция, которую требуется выполнить (например, чтение или запись). 2. Получив запрос, операционная система анализирует его, решает, может ли он быть выполнен, и если решение положительное, то запускает соответствующий драйвер, передавая ему в качестве параметров адрес выводимых данных. Дальнейшие действия, относящиеся к операции ввода-вывода, со стороны компьютера реализуются совместно драйвером и контроллером принтера. 3. Драйвер передает команды и данные контроллеру, который помещает их в свой внутренний буфер. 4. Контроллер перемещает данные из внутреннего буфера во внешний порт. 5. Контроллер начинает последовательно передавать биты в линию связи, представляя каждый бит соответствующим электрическим сигналом. Чтобы сообщить устройству управления принтера о том, что начинается передача байта, перед передачей первого бита данных контроллер формирует стартовый сигнал специфической формы, а после передачи последнего информационного бита – стоповый сигнал. Эти сигналы синхронизируют передачу байта. Кроме информационных бит, контроллер может передавать бит контроля четности для повышения достоверности обмена. 6. Устройство управления принтера, обнаружив на соответствующей линии стартовый бит, выполняет подготовительные действия и начинает принимать информационные биты, формируя из них байт в своем приемном буфере. Если передача сопровождается битом четности, то выполняется проверка корректности передачи: при правильно выполненной передаче в соответствующем регистре устройства управления принтера устанавливается признак завершения приема информации. Наконец, принятый байт обрабатывается принтером – выполняется соответствующая команда или печатается символ. Возможное распределение функций между драйвером и контроллером (УУ). Функции, выполняемые драйвером: − ведение очередей запросов; − буферизация данных; − подсчет контрольной суммы последовательности байтов; − анализ состояния ПУ; − загрузка очередного байта данных (или команды) в регистр контроллера; − считывание байта данных или байта состояния ПУ из регистра контроллера. Функции, выполняемые контроллером: − преобразование байта из регистра (порта) в последовательность бит; − передача каждого бита в линию связи; − обрамление байта стартовым и стоповым битами – синхронизация; − формирование бита четности; − установка признака завершения приема/передачи байта.2. 2.2. Связь двух компьютеров Предположим, что пользователь другого компьютера хотел бы распечатать текст. Сложность состоит в том, что к его компьютеру не подсоединен принтер и требуется воспользоваться тем принтером, который связан с другим компьютером (рис. 2.2). Программа, работающая на одном компьютере, не может получить непосредственный доступ к ресурсам другого компьютера – его дискам, файлам, принтеру. Она может только "попросить" об этом другую программу, выполняемую на том компьютере, которому принадлежат эти ресурсы. Эти "просьбы" выражаются в виде сообщений, передаваемых по каналам связи между компьютерами. Такая организация печати называется удаленной. 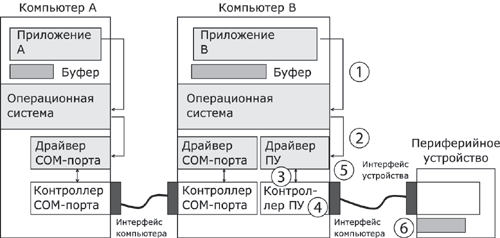 Рисунок 2.2. Взаимодействие двух компьютеров Предположим, что мы связали компьютеры по кабелю через COM-порты, которые, как известно, реализуют интерфейс RS-232C (такое соединение часто называют нуль-модемным). Связь между компьютерами осуществляется аналогично связи компьютера с ПУ. Только теперь контроллеры и драйверы портов действуют с двух сторон. Вместе они обеспечивают передачу по кабелю между компьютерами одного байта информации. Итак, механизм обмена байтами между двумя компьютерами определен. Теперь нужно договориться о правилах обмена сообщениями между приложениями А и В. Приложение В должно "уметь" расшифровать получаемую от приложения А информацию. Для этого программисты, разрабатывавшие приложения А и В, строго оговаривают форматы сообщений, которыми будут обмениваться приложения, и их семантику. Вернемся к последовательности действий, которые необходимо выполнить для распечатки текста на принтере "чужого" компьютера. 1. Приложение А формирует очередное сообщение (содержащее, например, строку, которую необходимо вывести на принтер) приложению В, помещает его в буфер оперативной памяти и обращается к ОС с запросом на передачу содержимого буфера на компьютер В. 2. ОС компьютера А обращается к драйверу COM-порта, который инициирует работу контроллера. 3. Действующие с обеих сторон пары драйверов и контроллеров COM-порта последовательно, байт за байтом, передают сообщение на компьютер В. 4. Драйвер компьютера В периодически выполняет проверку на наличие признака завершения приема, устанавливаемого контроллером при правильно выполненной передаче данных, и при его появлении считывает принятый байт из буфера контроллера в оперативную память, тем самым делая его доступным для программ компьютера В. В некоторых случаях драйвер вызывается асинхронно, по прерываниям от контроллера. Аналогично реализуется и передача байта в другую сторону – от компьютера B к компьютеру A. 5. Приложение В принимает сообщение, интерпретирует его, и в зависимости от того, что в нем содержится, формирует запрос к своей ОС на выполнение тех или иных действий с принтером. В нашем примере сообщение содержит указание на печать текста, поэтому ОС передает драйверу принтера запрос на печать строки. Далее выполняются все действия 1–5, описывающие выполнение запроса приложения к ПУ в соответствии с рассмотренной ранее схемой "локальная ОС – драйвер ПУ – контроллер ПУ – устройство управления ПУ" (см. предыдущий раздел). В результате строка будет напечатана. Рассмотрели последовательность работы системы при передаче только одного сообщения от приложения А к приложению В. Однако порядок взаимодействия этих двух приложений может предполагать неоднократный обмен сообщениями разного типа. Например, после успешной печати строки (в предыдущем примере) согласно правилам, приложение В должно послать сообщение-подтверждение. Это ответное сообщение приложение B помещает в буферную область оперативной памяти, а далее с помощью драйвера COM-порта передает его по каналу связи в компьютер А, где оно и попадает к приложению А. 2.3. Клиент, редиректор и сервер Можно представить, что любая программа, которой потребуется печать на "чужом" принтере, должна включать в себя функции, подобные тем, которые выполняет приложение А. Но нагружать этими стандартными действиями каждое приложение – текстовые и графические редакторы, системы управления базами данных и другие приложения – не очень рационально (хотя существует большое количество программ, которые действительно самостоятельно решают все задачи по обмену данными между компьютерами, например Kermit – программа обмена файлами через COM-порты, реализованная для различных ОС, Norton Commander 3.0 с его функцией Link). Гораздо выгоднее создать специальный программный модуль, который (вместо приложения А) будет выполнять формирование сообщений-запросов к удаленной машине и прием результатов для всех приложений. Такой служебный модуль называется клиентом. На стороне же компьютера В (на месте приложения В) должна работать другая специализированная программа – сервер, постоянно ожидающий прихода запросов на удаленный доступ к принтеру (или файлам, расположенным на диске) этого компьютера. Схема взаимодействия клиента и сервера с приложениями и локальной операционной системой приведена на рис. 2.3. 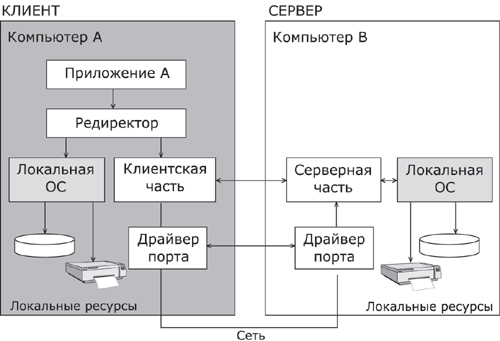 Рисунок 2.3. Взаимодействие программных компонентов при связи двух компьютеров Для того чтобы компьютер мог работать в сети, его операционная система должна быть дополнена клиентским и/или серверным модулем, а также средствами передачи данных между компьютерами. В результате такого добавления операционная система компьютера становится сетевой ОС. До сих пор рассматривали сеть, состоящую всего из двух машин. При объединении в сеть большего количества компьютеров возникает целый комплекс новых проблем: - выбор топологии; - адресация узлов в сети; - доступ к общей среде передачи. 3. ТОПОЛОГИЯ ФИЗИЧЕСКИХ СВЯЗЕЙ 3.1. Типы конфигураций связи компьютеров Как только компьютеров становится больше двух, возникает проблема выбора конфигурации физических связейили топологии. Под топологией сети понимается конфигурация графа, вершинам которого соответствуют конечные узлы сети (например, компьютеры) и коммуникационное оборудование (например, маршрутизаторы), а ребрам – электрические и информационные связи между ними. Число возможных конфигураций резко возрастает при увеличении числа связываемых устройств. Так, если три компьютера мы можем связать двумя способами, то для четырех компьютеров (рис. 3.1) можно предложить уже шесть топологически различных конфигураций (при условии неразличимости компьютеров).  Рисунок 3.1. Варианты связи компьютеров: а – трех компьютеров; б – четырех компьютеров Среди множества возможных конфигураций различают полносвязныеи неполносвязные(см. рис.3.2). 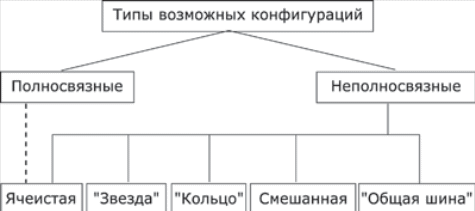 Рисунок 3.2. Типы конфигураций Полносвязнаятопология (рис. 3.3) соответствует сети, в которой каждый компьютер непосредственно связан со всеми остальными. Несмотря на логическую простоту, этот вариант громоздкий и неэффективный. Действительно, каждый компьютер в сети должен иметь большое количество коммуникационных портов, достаточное для связи с каждым из остальных компьютеров. Для каждой пары компьютеров должна быть выделена отдельная физическая линия связи. (Полносвязные топологии в крупных сетях применяются редко, так как для связи N узлов требуется N(N-1)/2 физических дуплексных линий связи, то есть имеет место квадратическая зависимость. Чаще этот вид топологии используется в многомашинных комплексах или в сетях, объединяющих небольшое количество компьютеров. 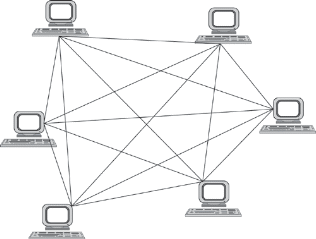 Рисунок 3.3. Полносвязная конфигурация Все другие варианты основаны на неполносвязных топологиях, когда для обмена данными между двумя компьютерами может потребоваться промежуточная передача данных через другие узлы сети. Ячеистаятопология (mesh) получается из полносвязной путем удаления некоторых возможных связей. Ячеистая топология допускает соединение большого количества компьютеров и характерна для крупных сетей (рис. 3.4).  Рисунок 3.4. Ячеистая топология В сетях с кольцевой конфигурацией (рис. 3.5) данные передаются по кольцу от одного компьютера к другому.  Рисунок 3.5. Топология "кольцо" Главное достоинство "кольца" в том, что оно по своей природе обладает свойством резервирования связей. Действительно, любая пара узлов соединена здесь двумя путями – по часовой стрелке и против. "Кольцо" представляет собой очень удобную конфигурацию и для организации обратной связи – данные, сделав полный оборот, возвращаются к узлу-источнику. Поэтому отправитель в указанном случае может контролировать процесс доставки данных адресату. Часто это свойство "кольца" используется для тестирования связности сети и поиска узла, работающего некорректно. В то же время в сетях с кольцевой топологией необходимо принимать специальные меры, чтобы в случае выхода из строя или отключения какой-либо станции не прерывался канал связи между остальными станциями "кольца". Топология "звезда" (рис. 3.6) образуется в том случае, когда каждый компьютер с помощью отдельного кабеля подключается к общему центральному устройству, называемому концентратором. В функции концентратора входит направление передаваемой компьютером информации одному или всем остальным компьютерам сети. В роли концентратора может выступать как компьютер, так и специализированное устройство, такое как многовходовый повторитель, коммутатор или маршрутизатор. 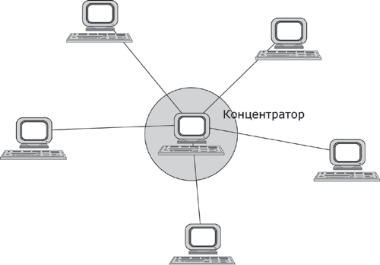 Рисунок 3.6. Топология "звезда" К недостаткам топологии типа "звезда" относится более высокая стоимость сетевого оборудования, связанная с необходимостью приобретения специализированного центрального устройства. Кроме того, возможности наращивания количества узлов в сети ограничиваются количеством портов концентратора. Иногда имеет смысл строить сеть с использованием нескольких концентраторов, иерархически соединенных между собой связями типа "звезда" (рис. 3.7). Получаемую в результате структуру называют также деревом. В настоящее время дерево является самым распространенным типом топологии связей, как в локальных, так и в глобальных сетях. 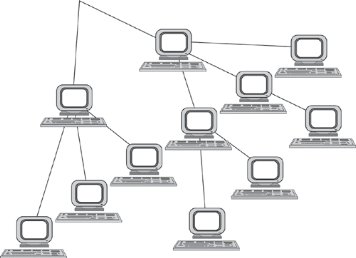 Рисунок 3.7. Топология "иерархическая звезда" или "дерево" Особым частным случаем конфигурации "звезда" является конфигурация "общая шина" (рис. 3.8). Здесь в роли центрального элемента выступает пассивный кабель, к которому по схеме "монтажного ИЛИ" подключается несколько компьютеров (такую же топологию имеют многие сети, использующие беспроводную связь – роль общей шины здесь играет общая радиосреда).  Рисунок 3.8. Топология "общая шина" Передаваемая информация распространяется по кабелю и доступна одновременно всем присоединенным к нему компьютерам. Основными преимуществами такой схемы являются низкая стоимость и простота наращивания, то есть присоединения новых узлов к сети. Самым серьезным недостатком "общей шины" является ее недостаточная надежность: любой дефект кабеля или какого-нибудь из многочисленных разъемов полностью парализует всю сеть. Другой недостаток "общей шины" – невысокая производительность, так как при таком способе подключения в каждый момент времени только один компьютер может передавать данные по сети, поэтому пропускная способность канала связи всегда делится между всеми узлами сети. До недавнего времени "общая шина" являлась одной из самых популярных топологий для локальных сетей. В то время как небольшие сети, как правило, имеют типовую топологию – "звезда", "кольцо" или "общая шина", для крупных сетей характерно наличие произвольных связей между компьютерами. В таких сетях можно выделить отдельные произвольно связанные фрагменты (подсети), имеющие типовую топологию, поэтому их называют сетями со смешаннойтопологией. 4. АДРЕСАЦИЯ УЗЛОВ СЕТИ Еще одной проблемой, которую нужно учитывать при объединении трех и более компьютеров, является проблема их адресации, точнее адресации их сетевых интерфейсов По количеству адресуемых интерфейсов адреса можно классифицировать следующим образом: - уникальный адрес (unicast) используется для идентификации отдельных интерфейсов; - групповой адрес (multicast) идентифицирует сразу несколько интерфейсов, поэтому данные, помеченные групповым адресом, доставляются каждому из узлов, входящих в группу; - данные, направленные по широковещательному адресу (broadcast), должны быть доставлены всем узлам сети; - в новой версии протокола IPv6 определен адрес произвольной рассылки (anycast), который, так же как и групповой адрес, задает группу адресов, однако данные, посланные по этому адресу, должны быть доставлены не всем адресам данной группы, а любому из них. Адреса могут быть: - аппаратными (МАС-адрес 00.la.ff.ff); - числовыми (IP-адрес 129.26.255.255); -символьными (site.domen.ru, willi-winki). Символьные адреса (имена) предназначены для запоминания людьми и поэтому обычно несут смысловую нагрузку. Множество всех адресов, которые являются допустимыми в рамках некоторой схемы адресации называется адресным пространством. Адресное пространство может иметь плоскую (линейную) организацию (рис. 4.1) или иерархическую организацию (рис. 4.2).  Рисунок 4.1. Плоская организация адресного пространства При плоской организации множество адресов никак не структурировано. Примером плоского числового адреса является МАС-адрес. Такой адрес обычно используется только аппаратурой, поэтому его стараются сделать по возможности компактным и записывают в виде двоичного или шестнадцатеричного числа, например 00-la-ff-ff. При задании МАС-адресов не требуется выполнение ручной работы, так как они обычно встраиваются в аппаратуру компанией-изготовителем, поэтому их называют также аппаратными адресами (hardware addresses). 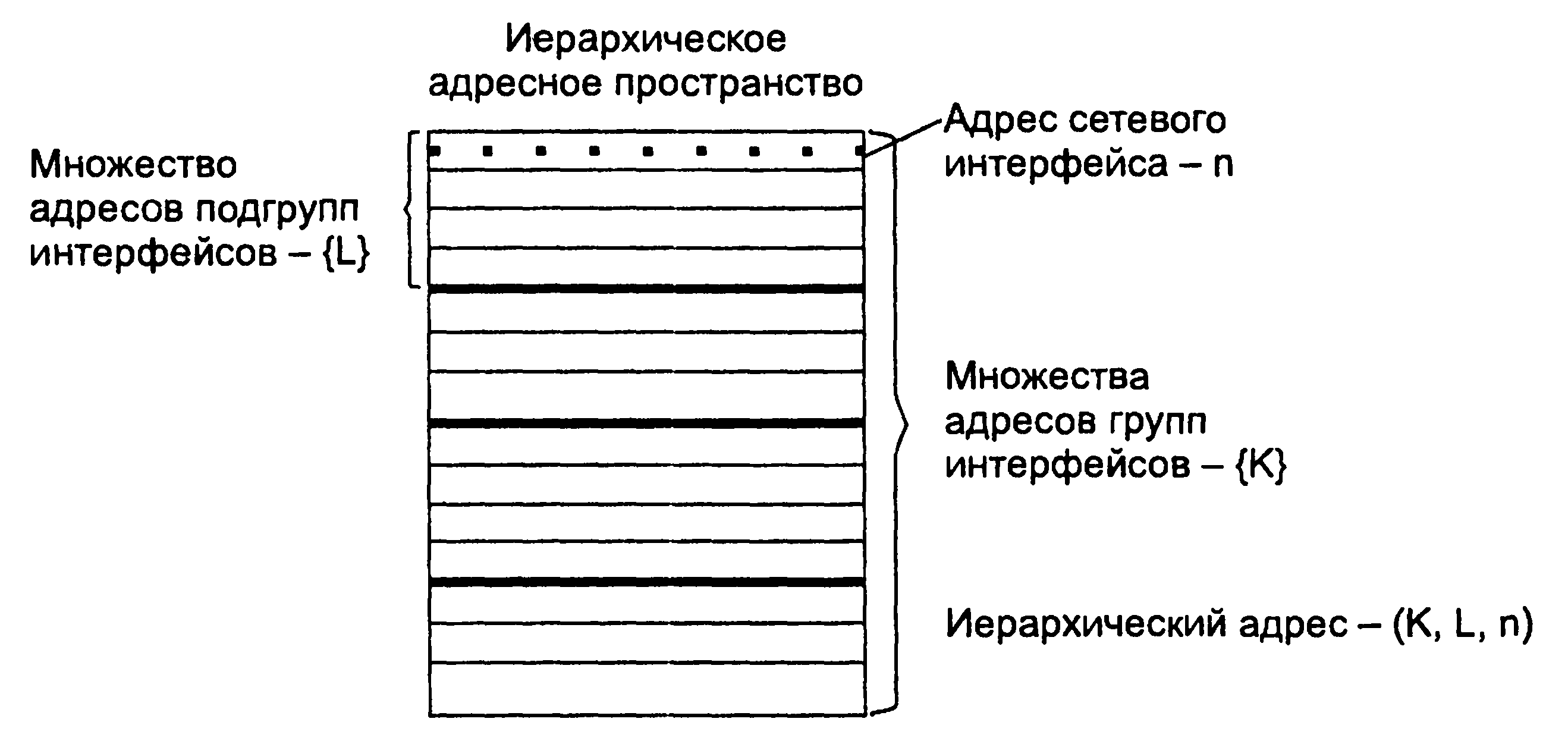 Рисунок. 4.2. Иерархическая организация адресного пространства При иерархической организации адресное пространство организовано в виде вложенных друг в друга подгрупп, которые, последовательно сужая адресуемую область, в конце концов, определяют отдельный сетевой интерфейс. В показанной на рис. 4.2 трехуровневой структуре адресного пространства адрес конечного узла задается тремя составляющими: идентификатором группы (К), в которую входит данный узел, идентификатором подгруппы (L) и, наконец, идентификатором узла (n), однозначно определяющим его в подгруппе. Иерархическая адресация во многих случаях оказывается более рациональной, чем плоская. В больших сетях, состоящих из многих тысяч узлов, использование плоских адресов приводит к большим издержкам — конечным узлам и коммуникационному оборудованию приходится оперировать таблицами адресов, состоящими из тысяч записей. В противоположность этому иерархическая система адресации позволяет при перемещении данных до определенного момента пользоваться только старшей составляющей адреса (например, идентификатором группы К), затем для дальнейшей локализации адресата задействовать следующую по старшинству часть (L) и в конечном счете — младшую часть (n). Типичными представителями иерархических числовых адресов являются сетевые IP- и IPX-адреса. В них поддерживается двухуровневая иерархия, адрес делится на старшую часть — номер сети и младшую — номер узла. До сих пор мы говорили об адресах сетевых интерфейсов, компьютеров и коммуникационных устройств, однако конечной целью данных, пересылаемых по сети, являются не сетевые интерфейсы или компьютеры, а выполняемые на этих устройствах программы — процессы. Поэтому в адресе назначения наряду с информацией, идентифицирующей интерфейс устройства, должен указываться адрес процесса, которому предназначены посылаемые по сети данные. Очевидно, что достаточно обеспечить уникальность адреса процесса в пределах компьютера. Примером адресов процессов являются номера портов TCP и UDP, используемые в стеке TCP/IP. 5. КОММУТАЦИЯ Итак, пусть компьютеры физически связаны между собой в соответствии с некоторой топологией и выбрана система адресации. Остается нерешенной самая важная проблема: каким способом передавать данные между конечными узлами? Особую сложность приобретает эта задача, когда топология сети неполносвязная. В таком случае обмен данными между произвольной парой конечных узлов (пользователей) должен идти в общем случае через транзитные узлы. Соединение конечных узлов через сеть транзитных узлов называют коммутацией. Последовательность узлов, лежащих на пути от отправителя к получателю образует маршрут.  Рисунок 5.1. Коммутация абонентов через сеть транзитных узлов Например, в сети, показанной на рис. 5.1, узлы 2 и 4, непосредственно между собой не связанные, вынуждены передавать данные через транзитные узлы, в качестве которых могут выступить, например, узлы 1 и 5. Узел 1 должен выполнить передачу данных между своими интерфейсами А и В, а узел 5 - между интерфейсами F и В. В данном случае маршрутом является последовательность: 2-1-5-4, где 2 ‑ узел-отправитель, 1 и 5 ‑ транзитные узлы, 4 ‑ узел-получатель. В самом общем виде задача коммутации может быть представлена в виде следующих взаимосвязанных частных задач. 1. Определение информационных потоков, для которых требуется прокладывать маршруты. 2. Маршрутизация потоков. 3. Продвижение потоков, то есть распознавание потоков и их локальная коммутация на каждом транзитном узле. 4. Мультиплексирование и демультиплексирование потоков. 5.1.Определение информационных потоков Понятно, что через один транзитный узел может проходить несколько маршрутов, например, через узел 5 (см. рис. 2.12) проходят как минимум все данные, направляемые узлом 4 каждому из остальных узлов, а также все данные, поступающие в узлы 3, 4 и 10. Транзитный узел должен уметь распознавать поступающие на него потоки данных, для того чтобы обеспечивать передачу каждого из них именно на тот свой интерфейс, который ведет к нужному узлу. Информационным потоком или потоком данных называют непрерывную последовательность данных, объединенных набором общих признаков, выделяющих их из общего сетевого трафика. Например, как поток можно определить все данные, поступающие от одного компьютера; объединяющим признаком в данном случае служит адрес источника. Эти же данные можно представить как совокупность нескольких подпотоков, каждый из которых в качестве дифференцирующего признака имеет адрес назначения. Наконец, каждый из этих подпотоков, в свою очередь, можно разделить на более мелкие подпотоки, порожденные разными сетевыми приложениями — электронной почтой, программой копирования файлов, веб-сервером. Данные, образующие поток, могут быть представлены в виде различных информационных единиц данных — пакетов, кадров или ячеек. В англоязычной литературе для потоков данных, передающихся с равномерной и неравномерной скоростью, обычно используют разные термины — соответственно «data stream» и «data flow». Например, при передаче веб-страницы через Интернет предложенная нагрузка представляет собой неравномерный поток данных, а при вещании музыки интернет-станцией — равномерный. Для сетей передачи данных характерна неравномерная скорость передачи, поэтому далее в большинстве ситуаций под термином «поток данных» мы будем понимать именно неравномерный поток данных и указывать на равномерный характер этого процесса только тогда, когда это нужно подчеркнуть. Очевидно, что при коммутации в качестве обязательного признака выступает адрес назначения данных. На основании этого признака весь поток входящих в транзитный узел данных разделяется на подпотоки, каждый из которых передается на интерфейс, соответствующий маршруту продвижения данных. Адрес источника и адрес назначения определяют поток для пары соответствующих конечных узлов. Однако часто бывает полезно представить этот поток в виде нескольких подпотоков, причем для каждого из них может быть проложен свой особый маршрут. Рассмотрим пример, когда на одной и той же паре конечных узлов выполняется несколько взаимодействующих по сети приложений, каждое из которых предъявляет к сети свои особые требования. В таком случае выбор маршрута должен осуществляться с учетом характера передаваемых данных, например, для файлового сервера важно, чтобы передаваемые им большие объемы данных направлялись по каналам, обладающим высокой пропускной способностью, а для программной системы управления, которая посылает в сеть короткие сообщения, требующие обязательной и немедленной отработки, при выборе маршрута более важна надежность линии связи и минимальный уровень задержек на маршруте. Кроме того, даже для данных, предъявляющих к сети одинаковые требования, может прокладываться несколько маршрутов, чтобы за счет распараллеливания ускорить передачу данных. Признаки потока могут иметь глобальное или локальное значение — в первом случае они однозначно определяют поток в пределах всей сети, а во втором — в пределах одного транзитного узла. Пара адресов конечных узлов для идентификации потока — это пример глобального признака. Примером признака, локально определяющего поток в пределах устройства, может служить номер (идентификатор) интерфейса данного устройства, на который поступили данные. Например, возвращаясь к рис. 5.1, узел 1 может быть настроен передавать все данные, поступившие с интерфейса А, на интерфейс В, а данные, поступившие с интерфейса D, на интерфейс С. Такое правило позволяет отделить поток данных узла 2 от потока данных узла 7 и направлять их для транзитной передачи через разные узлы сети, в данном случае поток узла 2 — через узел 5, а поток узла 7 — через узел 8. Метка потока — это особый тип признака. Она представляет собой некоторое число, которое несут все данные потока. Глобальная метка назначается данным потока и не меняет своего значения на всем протяжении его пути следования от узла источника до узла назначения, таким образом, она уникально определяет поток в пределах сети. В некоторых технологиях используются локальные метки потока, динамически меняющие свое значение при передаче данных от одного узла к другому. 5.2.Маршрутизация Задача маршрутизации, в свою очередь, включает в себя две подзадачи: □ определение маршрута; □ оповещение сети о выбранном маршруте. Определить маршрут — это значит выбрать последовательность транзитных узлов и их интерфейсов, через которые надо передавать данные, чтобы доставить их адресату. Определение маршрута — сложная задача, особенно когда конфигурация сети такова, что между парой взаимодействующих сетевых интерфейсов существует множество путей. Чаще всего выбор останавливают на одном - оптимальном по некоторому критерию маршруте (на практике для снижения объема вычислений ограничиваются поиском не оптимального в математическом смысле, а рационального, то есть близкого к оптимальному, маршрута.). В качестве критериев оптимальности могут выступать, например, номинальная пропускная способность и загруженность каналов связи; задержки, вносимые каналами; количество промежуточных транзитных узлов; надежность каналов и транзитных узлов. Но даже в том случае, когда между конечными узлами существует только один путь, при сложной топологии сети его нахождение может представлять собой нетривиальную задачу. Маршрут может определяться эмпирически («вручную») администратором сети на основании различных, часто не формализуемых соображений. Среди побудительных мотивов выбора пути могут быть: особые требования к сети со стороны различных типов приложений, решение передавать трафик через сеть определенного поставщика услуг, предположения о пиковых нагрузках на некоторые каналы сети, соображения безопасности. Однако эмпирический подход к определению маршрутов мало пригоден для большой сети со сложной топологией. В этом случае используются автоматические методы определения маршрутов. Для этого конечные узлы и другие устройства сети оснащаются специальными программными средствами, которые организуют взаимный обмен служебными сообщениями, позволяющий каждому узлу составить свое «представление» о сети. Затем на основе собранных данных программными методами определяются рациональные маршруты. При выборе маршрута часто ограничиваются только информацией о топологии сети. Этот подход иллюстрирует рис. 5.2. Для передачи трафика между конечными узлами А и С существуют два альтернативных маршрута: А-1-2-3-С и А-1-3-С. Если мы учитываем только топологию, то выбор очевиден — маршрут А-1-3-С, который имеет меньше транзитных узлов. 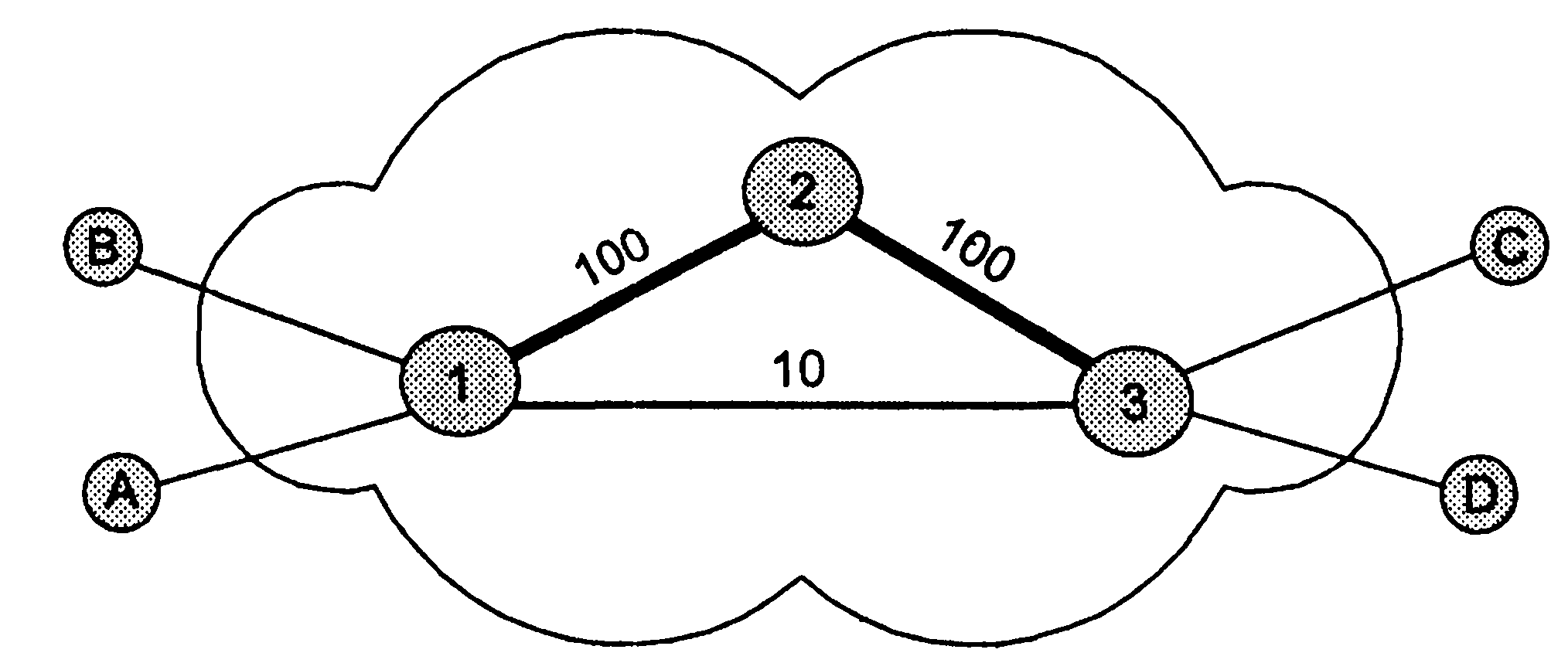 Рисунок 5.2. Выбор маршрута Решение было найдено путем минимизации критерия, в качестве которого в данном примере выступала длина маршрута, измеренная количеством транзитных узлов. Однако, возможно, наш выбор был не самым лучшим. На рисунке показано, что каналы 1-2 и 2-3 обладают пропускной способностью 100 Мбит/с, а канал 1-3 — только 10 Мбит/с. Если мы хотим, чтобы наша информация передавалась по сети с максимально возможной скоростью, то нам следовало бы выбрать маршрут А-1-2-3-С, хотя он и проходит через большее количество промежуточных узлов. То есть можно сказать, что маршрут А-1-2-3-С в данном случае оказывается «более коротким». Абстрактный способ измерения степени близости между двумя объектами называется метрикой. Так, для измерения длины маршрута могут быть использованы разные метрики — количество транзитных узлов, как в предыдущем примере, линейная протяженность маршрута и даже его стоимость в денежном выражении. Для построения метрики, учитывающей пропускную способность, часто используют следующий прием: длину каждого канала-участка характеризуют величиной, обратной его пропускной способности. Чтобы оперировать целыми числами, выбирают некоторую константу, заведомо большую, чем пропускные способности каналов в сети. Например, если мы в качестве такой константы выберем 100 Мбит/с, то метрика каждого из каналов 1-2 и 2-3 равна 1, а метрика канала 1-3 равна 10. Метрика маршрута равна сумме метрик составляющих его каналов, поэтому часть пути 1-2-3 обладает метрикой 2, а альтернативная часть пути 1-3 — метрикой 10. Мы выбираем более «короткий» путь, то есть путь А-1-2-3-С. Описанные подходы к выбору маршрутов не учитывают текущую степень загруженности каналов трафиком. Используя аналогию с автомобильным трафиком, можно сказать, что мы выбирали маршрут по карте, учитывая количество промежуточных городов и ширину дороги (аналог пропускной способности канала), отдавая предпочтение скоростным магистралям. Но мы не стали слушать радио или телевизионную программу, которая сообщает о текущих заторах на дорогах. Так что наше решение могло оказаться отнюдь не лучшим, если по маршруту А-1-2-3-С уже передается большое количество потоков, а маршрут А-1-3-С практически свободен. После того как маршрут определен (вручную или автоматически), надо оповестить о нем все устройства сети. Сообщение о маршруте должно нести каждому транзитному устройству примерно такую информацию: «каждый раз, когда в устройство поступят данные, относящиеся к потоку n, их следует передать для дальнейшего продвижения на интерфейс F». Каждое подобное сообщение о маршруте обрабатывается устройством, в результате создается новая запись в таблице коммутации. В этой таблице локальному или глобальному признаку (признакам) потока (например, метке, номеру входного интерфейса или адресу назначения) ставится в соответствие номер интерфейса, на который устройство должно передавать данные, относящиеся к этому потоку. Таблица 5.1 является фрагментом таблицы коммутации, содержащий запись, сделанную на основании сообщения о необходимости передачи потока n на интерфейс F. Таблица 5.1. Фрагмент таблицы коммутации  Конечно, детальное описание структуры сообщения о маршруте и содержимого таблицы коммутации зависит от конкретной технологии, однако эти особенности не меняют сущности рассматриваемых процессов. Передача информации транзитным устройствам о выбранных маршрутах, так же как и определение маршрута, может осуществляться и вручную, и автоматически. Администратор сети может зафиксировать маршрут, выполнив в ручном режиме конфигурирование устройства, например, жестко скоммутировав на длительное время определенные пары входных и выходных интерфейсов (как работали «телефонные барышни» на первых коммутаторах). Он может также по собственной инициативе внести запись о маршруте в таблицу коммутации. Однако поскольку топология и состав информационных потоков может меняться (отказы узлов или появление новых промежуточных узлов, изменение адресов или определение новых потоков), гибкое решение задач определения и задания маршрутов предполагает постоянный анализ состояния сети и обновление маршрутов и таблиц коммутации. В таких случаях задачи прокладки маршрутов, как правило, не могут быть решены без достаточно сложных программных и аппаратных средств. 5.3.Продвижение данных Итак, пусть маршруты определены, записи о них сделаны в таблицах всех транзитных узлов, все готово к выполнению основной операции — передаче данных между абонентами (коммутации абонентов). Для каждой пары абонентов эта операция может быть представлена несколькими (по числу транзитных узлов) локальными операциями коммутации. Прежде всего, отправитель должен выставить данные на тот свой интерфейс, с которого начинается найденный маршрут, а все транзитные узлы должны соответствующим образом выполнить «переброску» данных с одного своего интерфейса на другой, другими словами, выполнить коммутацию интерфейсов. Устройство, функциональным назначением которого является коммутация, называется коммутатором (рис. 5.3). 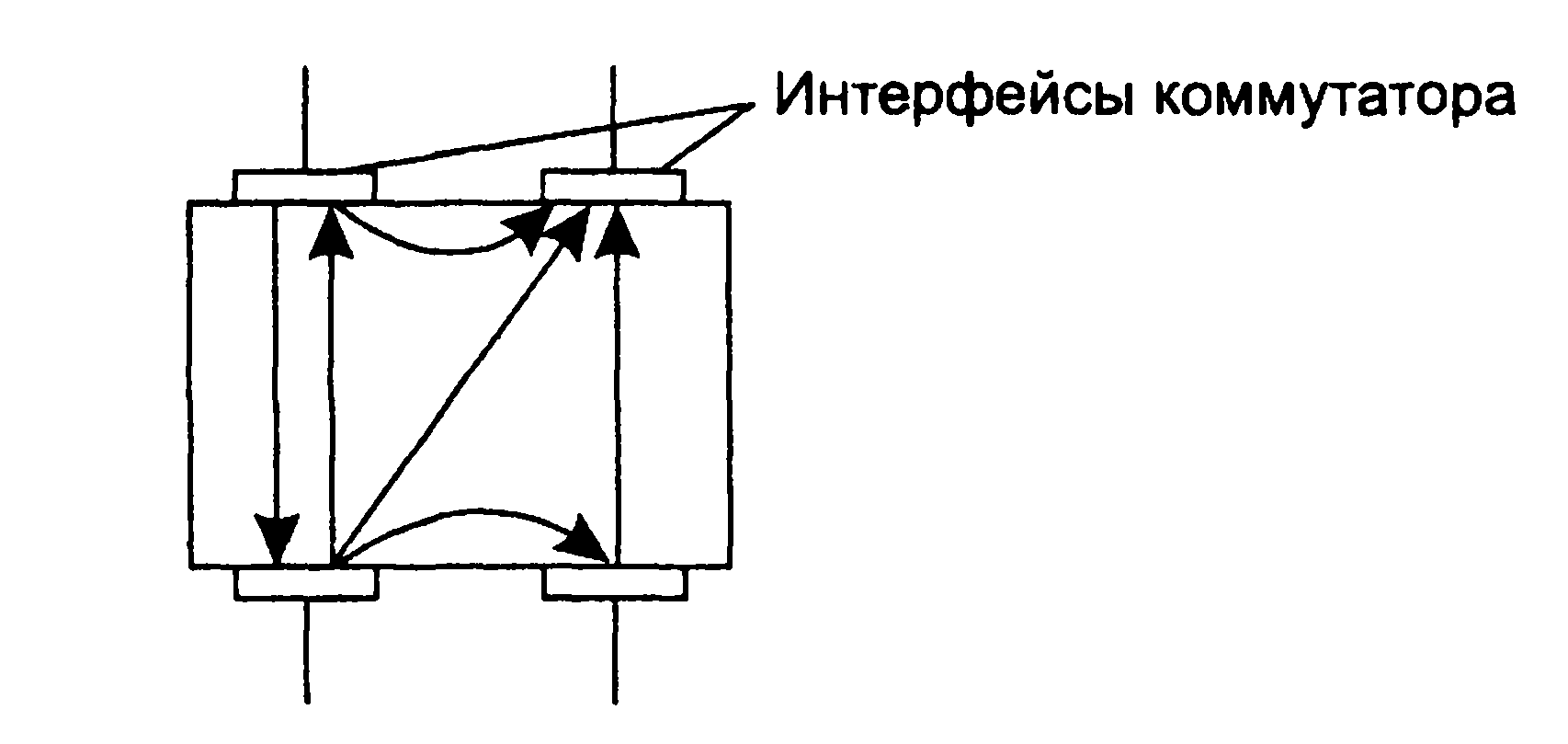 Рисунок 5.3. Коммутатор Однако прежде чем выполнить коммутацию, коммутатор должен распознать поток. Для этого поступившие данные анализируются на предмет наличия в них признаков какого-либо из потоков, заданных в таблице коммутации. Если произошло совпадение, то эти данные направляются на интерфейс, определенный для них в маршруте. ВНИМАНИЕ Термины «коммутация», «таблица коммутации» и «коммутатор» в телекоммуникационных сетях могут трактоваться неоднозначно. Мы уже определили коммутацию как процесс соединения абонентов сети через транзитные узлы. Этим же термином мы обозначаем и соединение интерфейсов в пределах отдельного транзитного узла. Коммутатором в широком смысле называется устройство любого типа, способное выполнять операции переключения потока данных с одного интерфейса на другой. Операция коммутации может быть выполнена в соответствии с различными правилами и алгоритмами. Некоторые способы коммутации и соответствующие им таблицы и устройства получили специальные названия. Например, в технологиях сетевого уровня, таких как IP и IPX, для обозначения аналогичных понятий используются термины «маршрутизация», «таблица маршрутизации», «маршрутизатор». В то же время за другими специальными типами коммутации и соответствующими устройствами закрепились те же самые названия «коммутация», «таблица коммутации» и «коммутатор», используемые в узком смысле, например, как коммутация и коммутатор локальной сети. Для телефонных сетей, которые появились намного раньше компьютерных, также характерна аналогичная терминология, коммутатор является здесь синонимом телефонной станции. Из-за солидного возраста и гораздо большей (пока) распространенности телефонных сетей чаще всего в телекоммуникациях под термином «коммутатор» понимают именно телефонный коммутатор. Коммутатором может быть как специализированное устройство, так и универсальный компьютер со встроенным программным механизмом коммутации, в этом случае коммутатор называется программным. Компьютер может совмещать функции коммутации данных с выполнением своих обычных функций как конечного узла. Однако во многих случаях более рациональным является решение, в соответствии с которым некоторые узлы в сети выделяются специально для коммутации. Эти узлы образуют коммутационную сеть, к которой подключаются все остальные. На рис. 5.4 показана коммутационная сеть, образованная из узлов 1, 5, 6 и 8, к которой подключаются конечные узлы 2, 3, 4, 7, 9 и 10. 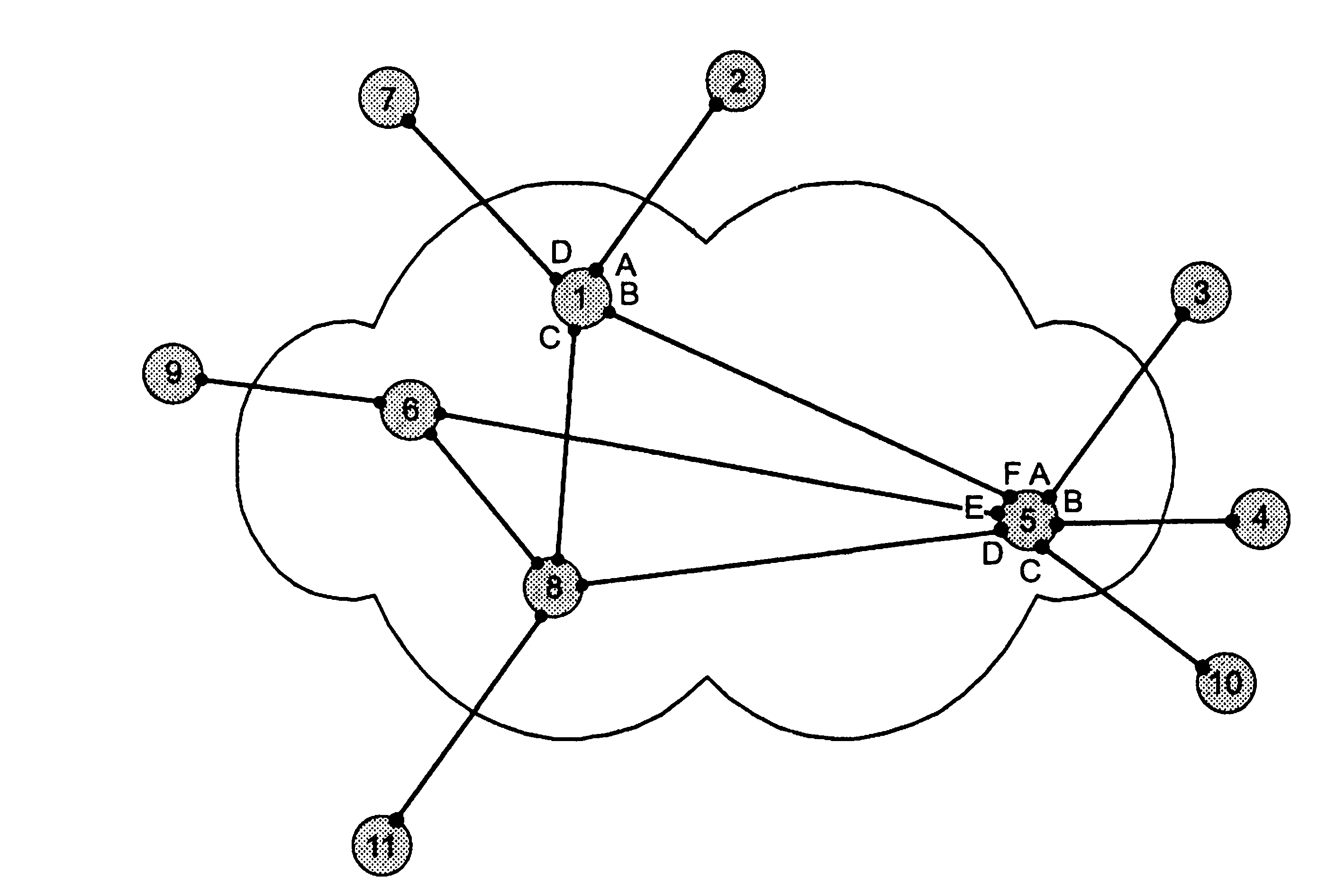 Рисунок 5.4. Коммутационная сеть 5.4.Мультиплексирование и демультиплексирование Чтобы определить, на какой интерфейс следует передать поступившие данные, коммутатор должен определить, к какому потоку они относятся. Эта задача должна решаться независимо от того, поступает на вход коммутатора только один «чистый» поток или «смешанный» поток, являющийся результатом агрегирования нескольких потоков. В последнем случае к задаче распознавания потоков добавляется задача демультиплексирования, то есть разделения суммарного агрегированного потока на несколько составляющих его потоков. Как правило, операцию коммутации сопровождает также обратная операция — мультиплексирование. При мультиплексировании из нескольких отдельных потоков образуется общий агрегированный поток, который можно передавать по одному физическому каналу связи. Операции мультиплексирования/демультиплексирования имеют такое же важное значение в любой сети, как и операции коммутации, потому что без них пришлось бы для каждого потока предусматривать отдельный канал, что привело бы к большому количеству параллельных связей в сети и свело бы «на нет» все преимущества неполносвязной сети. На рис. 5.5 показан фрагмент сети, состоящий из трех коммутаторов. Коммутатор 1 имеет пять сетевых интерфейсов. Рассмотрим, что происходит на интерфейсе Инт. 1. Сюда поступают данные с трех интерфейсов — Инт. 3, Инт. 4 и Инт. 5. Все их надо передать в общий физический канал, то есть выполнить операцию мультиплексирования. Мультиплексирование является способом разделения имеющегося одного физического канала между несколькими одновременно протекающими сеансами связи между абонентами сети. 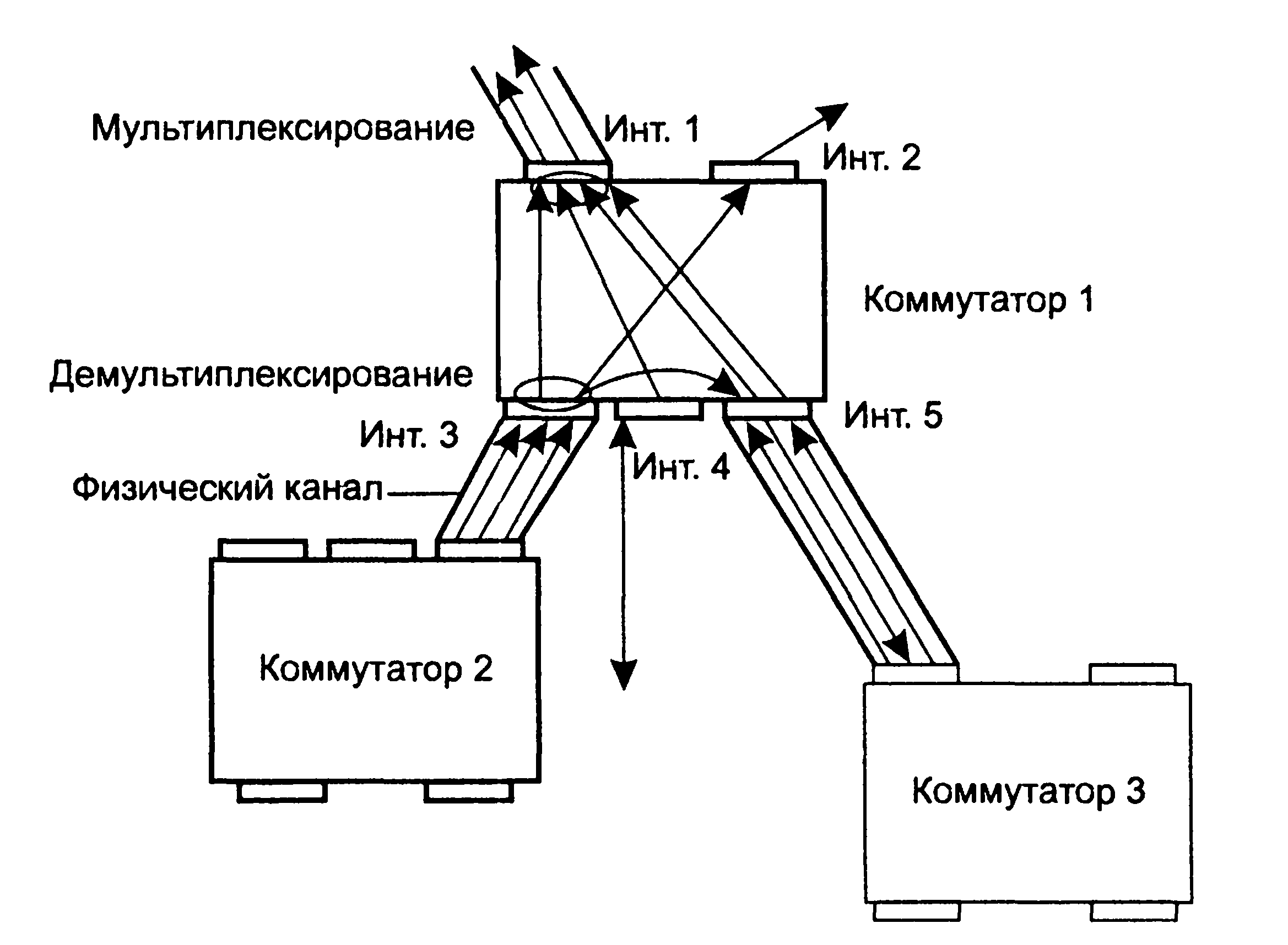 Рисунок 5.5. Операции мультиплексирования и демультиплексирования потоков при коммутации Одним из основных способов мультиплексирования потоков является разделение времени. При этом способе каждый поток время от времени (с фиксированным или случайным периодом) получает физический канал в полное свое распоряжение и передает по нему свои данные. Распространено также частотное разделение канала, когда каждый поток передает данные в выделенном ему частотном диапазоне. Технология мультиплексирования должна позволять получателю такого суммарного потока выполнять обратную операцию — разделение (демультиплексирование) данных на слагаемые потоки. На интерфейсе Инт. 3 коммутатор выполняет демультиплексирование потока на три составляющих его подпотока. Один из них он передает на интерфейс Инт. 1, другой — на Инт. 2, а третий — на Инт. 5. А вот на интерфейсе Инт. 2 нет необходимости выполнять мультиплексирование или демультиплексирование — этот интерфейс выделен одному потоку в монопольное использование. Вообще говоря, на каждом интерфейсе могут одновременно выполняться обе функции — мультиплексирования и демультиплексирования. 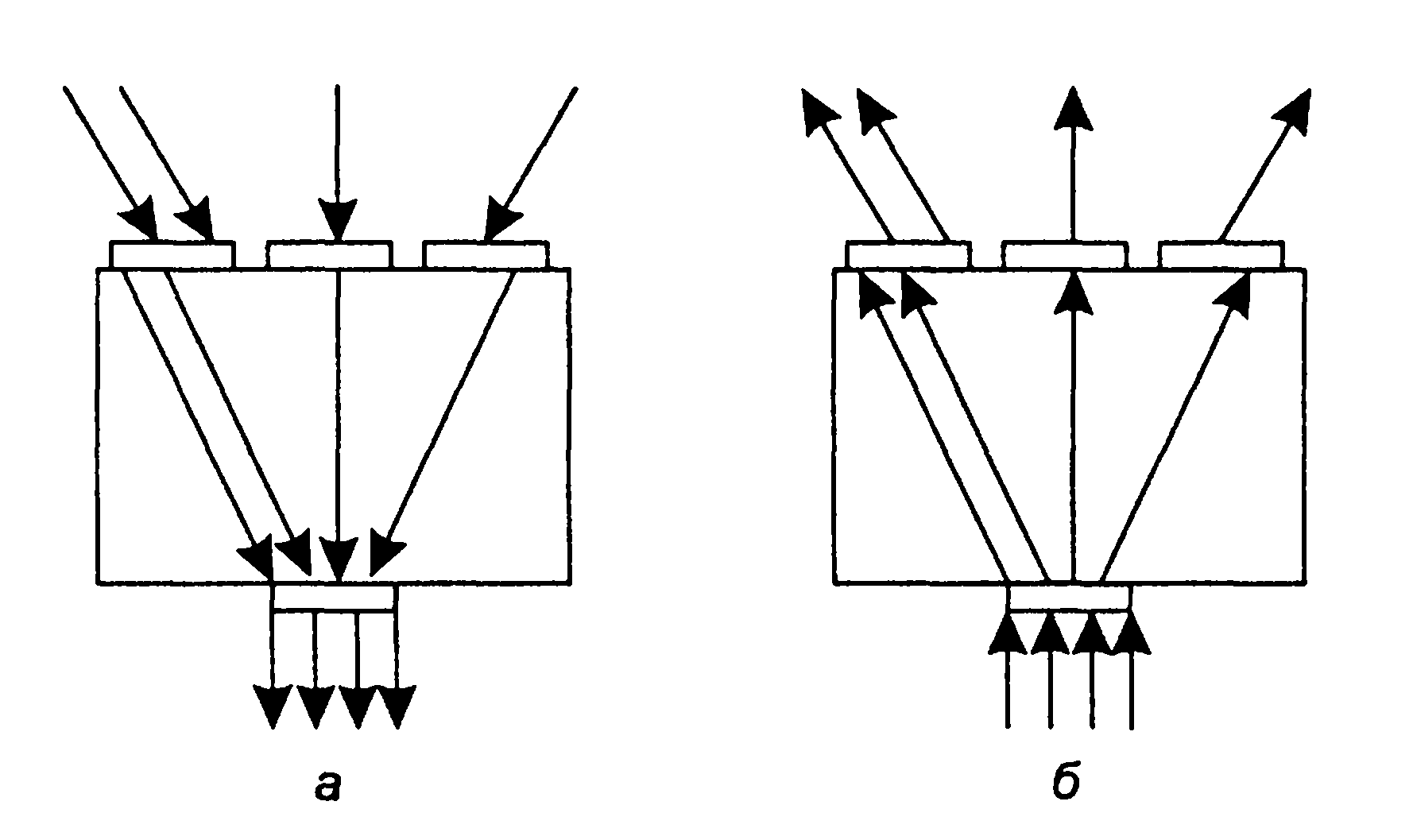 Рисунок 5.6. Мультиплексор и демультиплексор 5.5. Разделяемая среда передачи данных Еще одним параметром разделяемого канала связи является количество подключенных к нему узлов. В приведенных выше примерах к каждому каналу связи подключались только два взаимодействующих узла, точнее — два интерфейса (рис. 5.7, а и б). В телекоммуникационных сетях используется и другой вид подключения, когда к одному каналу подключается несколько интерфейсов (рис. 5.7, в). Такое множественное подключение интерфейсов порождает уже рассматривавшуюся выше топологию «общая шина», иногда называемую также шлейфовым подключением. Во всех этих случаях возникает проблема организации совместного использования канала несколькими интерфейсами. Возможны различные варианты разделения каналов связи между интерфейсами. На рис. 5.7, а коммутаторы К1 и К2 связаны двумя однонаправленными физическими каналами, то есть такими, по которым информация может передаваться только в одном направлении. В этом случае передающий интерфейс является активным, и физическая среда передачи находится под его управлением. Пассивный интерфейс только принимает данные. Проблема разделения канала между интефейсами здесь отсутствует. (Заметим, однако, что задача мультиплексирования потоков данных в канале при этом сохраняется.) На практике два однонаправленных канала, реализующие в целом дуплексную связь между двумя устройствами, обычно рассматриваются как один дуплексный канал, а пара интерфейсов одного устройства — как передающая и принимающая части одного и того же интерфейса. На рис. 5.7, б коммутаторы К1 и К2 связаны каналом, который может передавать данные в обе стороны, но только попеременно. При этом возникает необходимость в механизме синхронизации доступа интерфейсов К1 и К2 к такому каналу. Обобщением этого варианта является случай, показанный на рис. 5.7, в, когда к каналу связи подключаются несколько (больше двух) интерфейсов, образуя общую шину. Совместно используемый несколькими интерфейсами физический канал называют разделяемым (shared). Часто применяют также термин разделяемая среда передачи данных. Разделяемые каналы связи требуются не только для связей типа коммутатор-коммутатор, но и для связей компьютер-коммутатор и компьютер-компьютер. 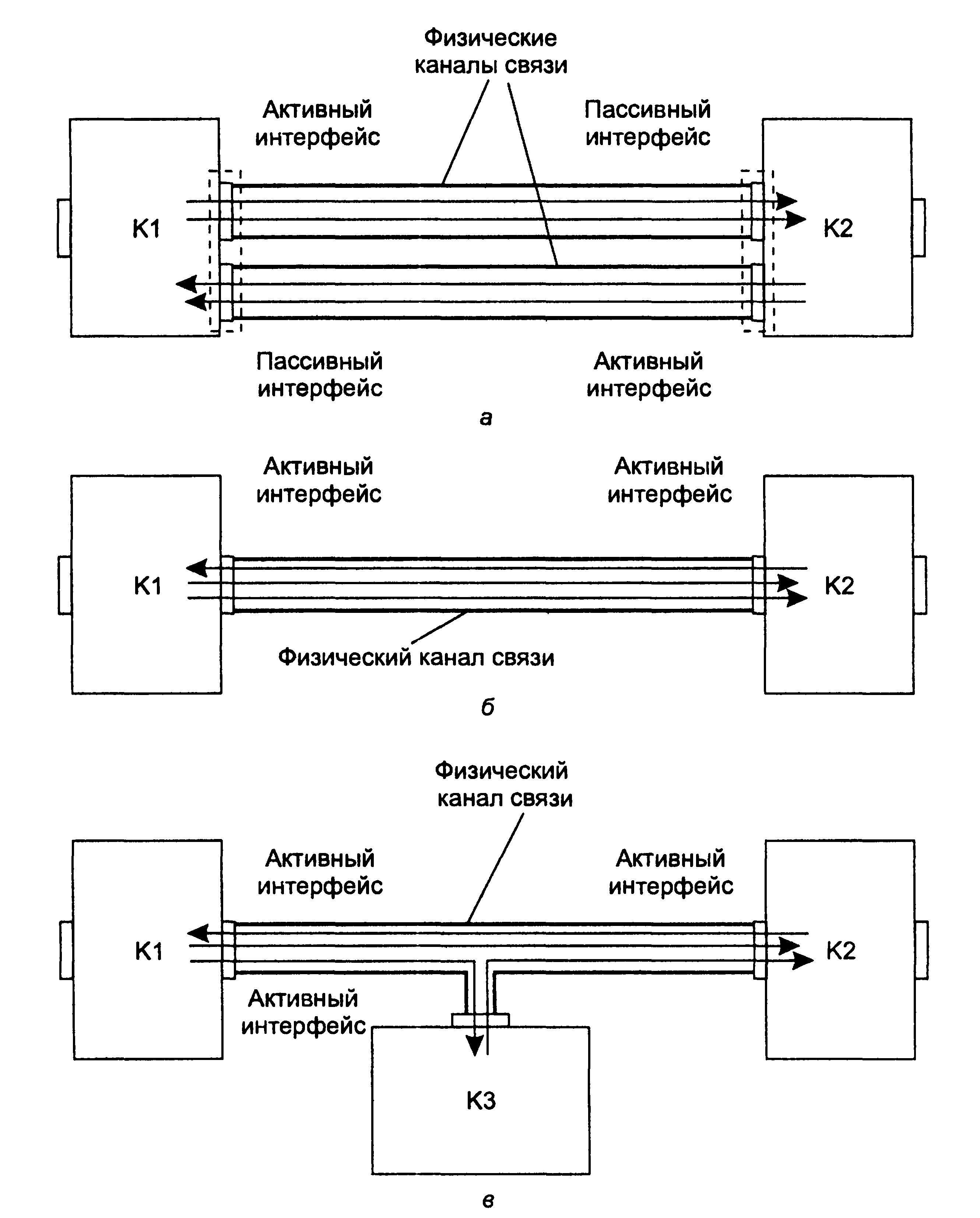 Рисунок 5.7 Совместное использование канала связи Существуют различные способы решения задачи организации совместного доступа к разделяемым линиям связи. Одни из них подразумевают централизованный подход, когда доступом управляет специальное устройство — арбитр, другие — децентрализованный. Внутри компьютера проблемы разделения линий связи между различными модулями также существуют — примером является доступ к системной шине, которым управляет либо процессор, либо специальный арбитр шины. В сетях организация совместного доступа к линиям связи имеет свою специфику из-за существенно большего времени распространения сигналов по линиям связи, поэтому процедуры согласования доступа к линии связи могут занимать слишком большой промежуток времени и приводить к значительным потерям производительности сети. Именно по этой причине разделяемые между интерфейсами среды практически не используются в глобальных сетях. В локальных же сетях разделяемые среды используются достаточно часто благодаря простоте и экономичности их реализации. Этот подход, в частности, применяется в доминирующей сегодня в локальных сетях технологии Ethernet, а также в популярных в прошлом технологиях Token Ring и FDDL Однако в последние годы стала преобладать другая тенденция — отказ от разделяемых сред передачи данных и в локальных сетях. Это связано с тем, что за достигаемое таким образом удешевление сети приходится расплачиваться производительностью. ВНИМАНИЕ Сеть с разделяемой средой при большом количестве узлов будет работать всегда медленнее, чем аналогичная сеть с индивидуальными двухточечными линиями связями, так как пропускная способность линии связи при ее совместном использовании делится между несколькими компьютерами сети. И тем не менее не только в классических, но и в некоторых совсем новых технологиях, разработанных для локальных сетей, сохраняется режим разделяемых линий связи. Например, разработчики технологии Gigabit Ethernet, принятой в 1998 году в качестве нового стандарта, включили режим разделения среды в свои спецификации наряду с режимом работы по индивидуальным линиям связи. 5.6. Типы коммутации Комплекс технических решений обобщенной задачи коммутации в своей совокупности составляет основу любой сетевой технологии. Как уже отмечалось, к этим частным задачам относятся: □ определение потоков и соответствующих маршрутов; □ фиксация маршрутов в конфигурационных параметрах и таблицах сетевых устройств; □ распознавание потоков и передача данных между интерфейсами одного устройства; □ мультиплексирование/демультиплексирование потоков; □ разделение среды передачи. Сети с коммутацией каналов имеют более богатую историю, они происходят от первых телефонных сетей. Сети с коммутацией пакетов сравнительно молоды, они появились в конце 60-х годов как результат экспериментов с первыми глобальными компьютерными сетями. Каждая из этих схем имеет свои достоинства и недостатки, но по долгосрочным прогнозам многих специалистов будущее принадлежит технологии коммутации пакетов, как более гибкой и универсальной. Пример Поясним достаточно абстрактное описание обобщенной модели коммутации на примере работы традиционной почтовой службы. Почта также работает с потоками, которые в данном случае составляют почтовые отправления. Основным признаком почтового потока является адрес получателя. Для упрощения будем рассматривать в качестве адреса только страну, например, Индия, Норвегия, Россия, Бразилия и т. д. Дополнительным признаком потока может служить особое требование к надежности или скорости доставки. Например, пометка «Avia» на почтовых отправлениях в Бразилию выделит из общего потока почты в Бразилию подпоток, который будет доставляться самолетом. Для каждого потока почтовая служба должна определить маршрут, который будет проходить через последовательность почтовых отделений, являющихся аналогами коммутаторов. В результате многолетней работы почтовой службы уже определены маршруты для большинства адресов назначения. Иногда возникают новые маршруты, связанные с появлением новых возможностей — политических, транспортных, экономических. После выбора нового маршрута нужно оповестить о нем сеть почтовых отделений. Как видно, эти действия очень напоминают работу телекоммуникационной сети. Информация о выбранных маршрутах следования почты представлена в каждом почтовом отделении в виде таблицы, в которой задано соответствие между страной назначения и следующим почтовым отделением. Например, в почтовом отделении города Саратова все письма, адресованные в Индию, направляются в почтовое отделение Ашхабада, а письма, адресованные в Норвегию, — в почтовое отделение Санкт-Петербурга. Такая таблица направлений доставки почты является прямой аналогией таблицы коммутации коммуникационной сети. Каждое почтовое отделение работает подобно коммутатору. Все поступающие от абонентов и других почтовых отделений почтовые отправления сортируются, то есть происходит распознавание потоков. После этого почтовые отправления, принадлежащие одному «потоку», упаковываются в мешок, для которого в соответствии с таблицей направлений определяется следующее по маршруту почтовое отделение. 6. ДЕКОМПОЗИЦИЯ ЗАДАЧ СЕТЕВОГО ВЗАИМОДЕЙСТВИЯ Организация взаимодействия между устройствами сети является сложной задачей. Для решения сложных задач используется известный универсальный прием — декомпозиция, то есть разбиение одной сложной задачи на несколько более простых задач-модулей. Декомпозиция состоит в четком определении функций каждого модуля, а также порядка их взаимодействия (то есть межмодульных интерфейсов). При таком подходе каждый модуль можно рассматривать как «черный ящик», абстрагируясь от его внутренних механизмов и концентрируя внимание на способе взаимодействия этих модулей. В результате такого логического упрощения задачи появляется возможность независимого тестирования, разработки и модификации модулей. Так, любой из показанных на рис. 6.1 модулей может быть переписан заново. Пусть, например, это будет модуль А, и если при этом разработчики сохранят без изменения межмодульные связи (в данном случае интерфейсы А-В и А-С), то это не потребует никаких изменений в остальных модулях. 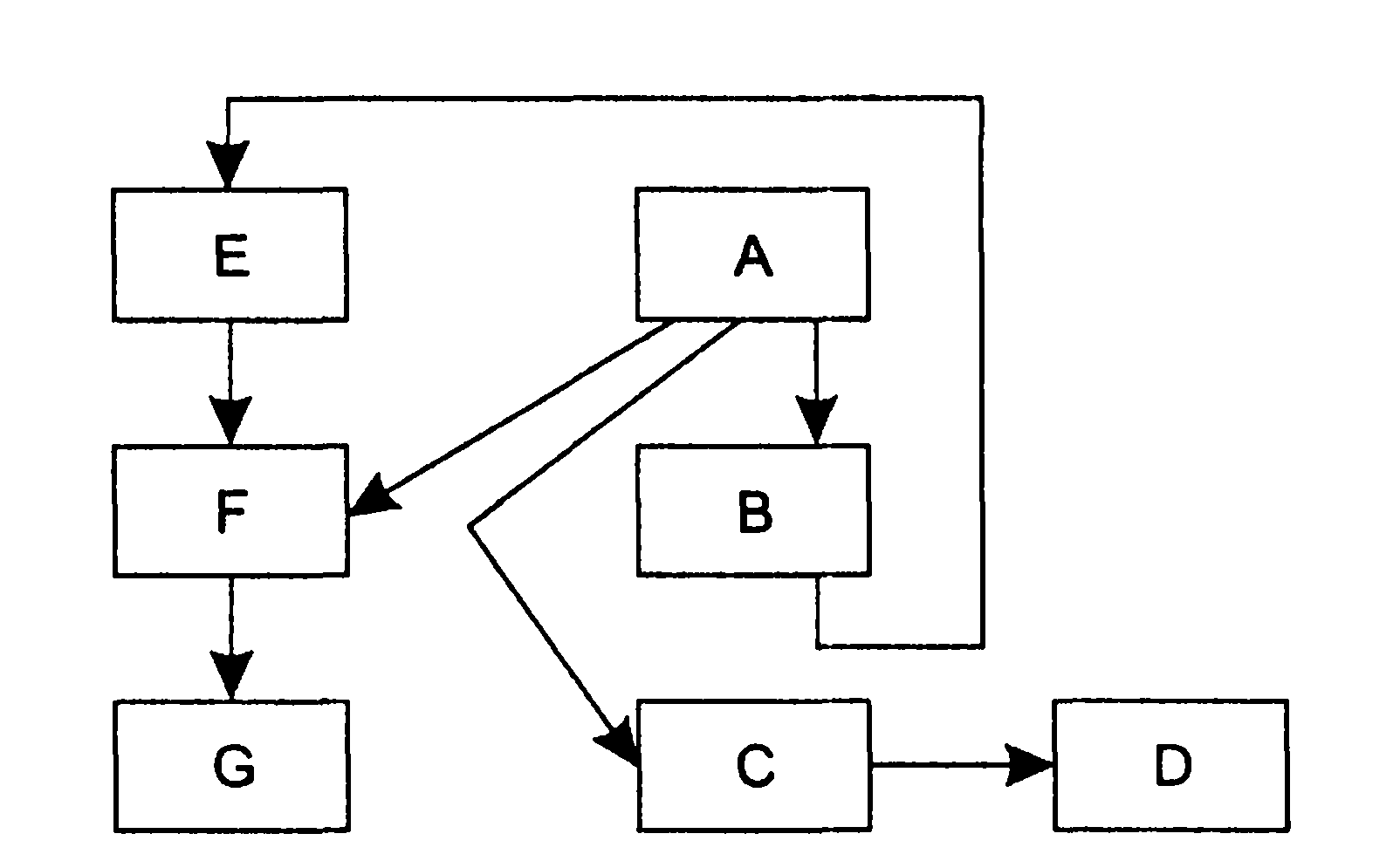 Рисунок 6.1. Пример декомпозиции задачи |