Контрольная работа №1 по вычислительным системам. КР№1. Контрольная работа 1 по дисциплине Вычислительные системы (по материалам лекций 16) Задание 1
 Скачать 93.89 Kb. Скачать 93.89 Kb.
|

|
Промежуточная контрольная работа №1 по дисциплине: «Вычислительные системы» (по материалам лекций 1-6) Задание №1 Архитектура СОД может быть определена как совокупность трёх категорий: сущность информационных потоков, например, существование двух потоков – команд и данных; характер взаимодействия информационных потоков, например, жесткая последовательность команд управляет обработкой данных; способ обработки данных, например, последовательный или параллельный. В таком случае, понятие архитектуры отображает определение системы с точки зрения существующих в ней информационных потоков и способа их обработки. Примеры архитектур: фон-неймановская архитектура, усовершенствованная фон-неймановская архитектура, нетрадиционная архитектура. Задание №2 Скалярный процессор самый простой тип процессора. Этот процесс имеет по одному объекту, как правило, целые числа или числа с плавающей точкой, которые являются числами слишком большими или малыми, чтобы быть представлены целыми числами. Так как каждая команда обрабатывается последовательно, основная скалярная обработка может занять некоторое время. В отличие от этого, векторный процессор работает на массив точек данных. Это означает, что вместо обработки каждого элемента по отдельности, векторный процессор обрабатывает сразу несколько элементов, имеющих одинаковые инструкции, которые могут быть обработаны одновременно. Это может сэкономить время по сравнению с скалярной обработкой, но также добавляет сложности к системе, которая может замедлить другие функции. Векторная обработка данных работает лучше всего, когда есть большой объем данных, подлежащих обработке групп, которые могут обрабатываться одной инструкцией. Векторные и скалярные процессоры различаются также и в их времени запуска. Векторный процессор зачастую требует длительной загрузки компьютера, поскольку он выполняет много задач, которые нужно выполнить. Скалярные процессоры запускают компьютер в гораздо более короткий промежуток времени, поскольку выполняются только одна задача. Суперскалярный процессор имеет элементы каждого типа и объединяет их для еще более быстрой обработки. Использование параллелизма на уровне инструкций, позволяет суперскалярную обработку выполнять за несколько операций одновременно. Это позволяет процессору выполнять гораздо быстрее задачи, чем обычный скалярный процессор, без дополнительных сложностей и других ограничений векторного процессора. Внешняя память. Внешняя память предназначена для длительного хранения программ и данных, и целостность её содержимого не зависит от того, включен или выключен компьютер. В отличие от оперативной памяти, внешняя память не имеет прямой связи с процессором. Устройства внешней памяти или, иначе, внешние запоминающие устройства весьма разнообразны. Постоянная память. Постоянная – энергонезависимая память, используется для хранения данных, которые никогда не потребуют изменения. Содержание памяти специальным образом «зашивается» в устройстве при его изготовлении для постоянного хранения. Из ПЗУ можно только читать. Оперативная память. Назначение оперативной памяти – хранение данных, работа с которыми осуществляется в данный момент времени. Оперативная память обеспечивает возможность обращения процессора к любой ее ячейке, поэтому называется памятью с произвольным доступом. Кэш-память. Кэш – это память с большей скоростью доступа, предназначенная для ускорения обращения к данным, содержащимся постоянно в памяти с меньшей скоростью доступа. Кэширование применяется ЦПУ, жёсткими дисками, браузерами, веб-серверами, службами DNS и WINS. Производительность как характеристику вычислительной мощности системы, определяющую количество выполненной работы за единицу времени. Таким образом, если имеем в виду вычислительную систему, то под работой можно понимать решение задач. В этом случае производительность есть число задач, выполненных системой в единицу времени. Следовательно, производительность системы будет различной для задач различных классов. Существует большое число методов оценки производительности ВС, связанных с тем или иным классом задач, однако главные из них основаны на использовании специально созданных тестов. В первых ЭВМ быстродействие измерялось в количестве коротких операций в секунду, например, типа «регистр-регистр» или «сложение с фиксированной точкой», то современные ЭВМ и ВС характеризуются числом выполняемых операций с плавающей точкой в секунду, которые получили название флопов (FLOPS). Для специализированных ВС используются другие единицы измерения, например, характерные для них операции, транзакции и т. д. Компилятор VLIW создаёт такой план выполнения, имея полное представление о процессоре VLIW, причём создаёт этот план так, чтобы добиться требуемой записи выполнения – последовательности событий, которые действительно происходят во время работы программы. Компилятор передаёт план выполнения (через архитектуру набора команд, которая точно описывает параллелизм) аппаратному обеспечению, которое, в свою очередь, выполняет этот план. Процессоры VLIW представляют собой пример архитектуры, для которой программа представляет точную информацию о параллелизме. Компилятор выявляет параллелизм в программе и сообщает программному обеспечению, какие операции не зависят друг от друга. Эта информация имеет важное значение для аппаратного обеспечения, поскольку в этом случае оно «знает» без дальнейших проверок, какие операции можно начинать выполнять в одном и том же такте. Достоинства VLIW заключаются в следующем: Компилятор может эффективнее исследовать зависимости между командами и выбирать параллельно исполняемые команды, чем это делает аппаратура суперскалярного процессора, ограниченная размером окна исполнения. VLIW процессор имеет более простое устройство управления и потенциально может иметь более высокую тактовую частоту. Однако у VLIW процессоров есть серьёзный фактор, снижающий их производительность. Это команды ветвления, зависящие от данных, значения которых становятся известны только в динамике вычислений. Окно исполнения VLIW-процессора, не может быть очень большим в виду отсутствия у компилятора информации о зависимостях, формируемых динамически, в процессе выполнения. Этот недостаток препятствует возможности переупорядочивания операций в VLIW процессоре. Кроме того, VLIW реализация требует большого размера памяти имён, многовходовых регистровых файлов, большого числа перекрёстных связей. Конвейер команд - предполагает разбивку выполнения каждой инструкции на несколько этапов, причем каждый этап выполняется на своей ступени конвейера процессора. При выполнении инструкция продвигается по конвейеру по мере освобождения последующих ступеней. Таким образом, на конвейере одновременно может обрабатываться несколько последовательных инструкций, и производительность процессора можно оценивать темпом выхода выполненных инструкций со всех его конвейеров. Для достижения максимальной производительности процессора — обеспечения полной загрузки конвейеров с минимальным числом лишних штрафных циклов— программа должна составляться с учетом архитектурных особенностей процессора. Конечно, и код, сгенерированный обычным способом, будет исполняться на процессорах классов Pentium и Р6 достаточно быстро. Конвейер «классического» процессора Pentium имеет пять ступеней. Конвейеры процессоров с суперконвейерной архитектурой имеют большее число ступеней, что позволяет упростить каждую из них и, следовательно, сократить время пребывания в них инструкций. Задание №3 Фон-Неймановская архитектура – класс объектов с архитектурой, которая основана на использовании двух информационных потоков -команд и данных, с чисто последовательным характером обработки данных под управлением заранее составленной последовательности команд (программы). Задание №4 Представление программы в Ярусно-параллельной форме обеспечивает возможность, используя формальное представление с помощью соответствующего языка параллельного программирования, автоматизировать процесс распараллеливания задачи. 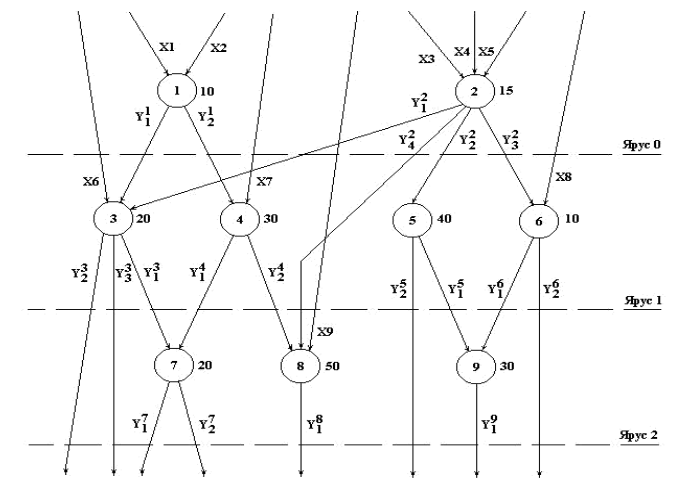 Кружками с цифрами внутри обозначены ветви (цифра – порядковый номер ветви). Длина ветви представляется цифрой, стоящей около кружка, и может соответствовать числу временных единиц, которые требуются для её исполнения (например, число машинных тактов). Стрелками показаны входные данные и результаты обработки. Входные данные обозначаются символом X, нижние цифровые индексы которых соответствуют номеру входных величин. Выходные данные обозначаются символом Y, верхний цифровой индекс которых соответствует номеру ветви, при выполнении которой получен данный результат, а нижний индекс означает порядковый номер результата, полученного при реализации данной ветви программы. Изображённая на рисунке программа содержит 9 ветвей, расположенных на трёх ярусах. Очевидно, что для ветвей каждого яруса выполняется первое условие независимости. Допустим, что выполняются и остальные три условия независимости ветвей (на графе для простоты изложения отсутствуют связи по памяти, управлению и подпрограммам). Тогда можно считать, что ветви одного яруса являются независимыми и, следовательно, есть принципиальная возможность при наличии в ВС нескольких процессоров, организовать параллельные вычисления. Можно выделить следующие уровни параллелизма: Первый – это уровень скалярных операций, когда различные операции одновременно выполняются на различных исполнительных узлах над различными данными. Второй – это уровень векторных операций, когда одна и та же операция одновременно выполняется на одинаковых исполнительных узлах над различными однотипными данными. Одним из наиболее распространённых типов параллелизма в обработке информации является параллелизм на уровне независимых ветвей (подзадач) прикладной задачи. Прежде чем подробнее остановиться на этом уровне параллелизма, отметим, что существует более высокий уровень – уровень естественного параллелизма независимых задач. Реализация этого уровня базируется на предположении о том, что в ВС поступает непрерывный поток не связанных между собой задач, решение которых не зависит от результатов решения других задач. Преобразование последовательной части программы в параллельную форму базируется на следующем. Пусть операции алгоритма разбиваются на группы, упорядоченные таким образом, что каждая операция любой группы зависит либо от начальных данных алгоритма, либо от результатов выполнения операций, находящихся в предыдущих группах. Следовательно, все операции одной группы должны быть независимыми и обладать возможностью быть выполненными одновременно на имеющихся в системе функциональных узлах. Представление алгоритма в таком виде и является параллельной формой алгоритма. Тогда каждая группа операций в ней называется ярусом параллельной формы, число групп – высотой параллельной формы, максимальное число операций в ярусе – шириной параллельной формы. Три уровня представления последовательных программ, на которых их распараллеливание даёт существенный выигрыш в производительности вычислительной системы. Первый уровень основан на том, что программа разбивается на относительно небольшие участки, достаточно тесно связанные между собой как по данным так и по управлению, и среди них выделяются те, которые могут быть выполнены параллельно. Второй уровень связан с распараллеливанием циклов. Границы циклов находятся по формальным признакам описания циклов в соответствующих языках программирования. Процесс преобразования последовательного цикла для параллельного выполнения заключается в том, что из переменных формируются векторы, над которыми выполняются векторные операции. Поскольку векторные операции выполняются параллельно над всеми или частью элементов вектора (в зависимости от вычислительных ресурсов ВС), то происходит значительное ускорение вычислительного процесса. Третий уровень – это распараллеливание линейных участков. Линейным участком программы назовём часть программы, операторы которой выполняются в естественном порядке или порядке, определённом командами безусловных переходов. Линейный участок ограничен начальным и конечным операторами. Задание №5 Вычислительная система характеризуется следующим: – производительность; – надёжность; – стоимость. Для того чтобы характеристику, а, следовательно, и эффективность системы оценить количественно, вводится понятие показателя характеристики. Быстродействие – которое характеризуется числом команд, выполняемых ЭВМ за одну секунду. Поскольку в состав команд ЭВМ включаются операции, различные по длительности выполнения и по вероятности их использования, то имеет смысл характеризовать его или средним быстродействием ЭВМ, или предельным. Современные вычислительные машины имеют очень высокие характеристики по быстродействию, измеряемые десятками и сотнями миллионов операций в секунду. Производительность – объем работ, осуществляемых ЭВМ в единицу времени. Например, можно определять этот параметр числом задач, выполняемых за определенное время. Однако сравнение по данной характеристике ЭВМ различных типов может вызвать затруднения. Поскольку оценка производительности различных ЭВМ является важной практической задачей, хотя такая постановка вопроса также не вполне корректна, были предложены к использованию относительные характеристики производительности. Скорость передачи информации – скорость передачи данных, выраженная в количестве бит, символов или блоков, передаваемых за единицу времени. Время доступа – время, необходимое для получения информации из компьютерной памяти или для записи информации в память. Время доступа может варьировать от миллионной доли секунды при быстродействующей электронной памяти до секунды и более при работе с памятью на магнитной ленте. Производительность - это характеристика вычислительной мощности системы, определяющая количество вычислительной работы, выполняемой системой в единицу времени (другими словами, количество прикладных задач, выполненных системой в единицу времени). В настоящее время существует большое количество различных способов, методов и методик оценки производительности ВС и это связано не только с существованием огромного количества видов ВС, но и с тем, что производительность определяется большим числом параметров, как самой вычислительной системы, так и прикладных задач. Производительность бывает следующая: Номинальная производительность; Комплексная производительность; Системная производительность. Способы оценки производительности через применение по существу тактовой частоты работы основных устройств системы (либо длительности цикла) и статистических методов. С подходом, основанным на сравнении производительности микропроцессоров по их рабочим частотам, тесно связан подход по оценке производительности системы по тому, насколько быстро система может выполнять команды процессора. Однако это весьма расплывчатый показатель. Скорость работы процессора, обычно выражаемая в миллионах операций в секунду (millions of Instructions per second – MIPS), сильно привязана к его тактовой частоте. Кроме того, оценка производительности в MIPS существенно зависит от системы команд микропроцессора: одна команда в микропроцессоре одного типа может быть эквивалентна по вычислительной мощности нескольким командам другого МП. К тому же различные операции, особенно в CISC-микропроцессорах, требуют разного времени для их выполнения. Следовательно, MIPS – оценка существенно зависит от того, какие команды принимаются в расчет. Таким образом, MIPS является полезным показателем лишь при сравнении процессоров одного производителя. Такие процессоры должны поддерживать одинаковую систему команд. Кроме того, следует применять одинаковые компиляторы. Аналогичным подходом является измерение производительности работы процессора в миллионах операций с плавающей точкой в секунду (millions of floating-point operations per second – MFLOPS). Обычно скорость в MFLOPS вычисляют для смеси операций сложений и умножений с плавающей точкой. Но поскольку микропроцессоры становятся все быстрее и быстрее, значение максимума MFLOPS перестает быть полезным в качестве разумной меры производительности операций с плавающей точкой: ограничивающим фактором становится пропускная способность каналов памяти (насколько быстро данные можно перемещать из процессора и в процессор). Одним из самых распространённых методов оценки производительности систем в научных кругах является использование аналитических моделей. Метод основан на представлении ВС чаще всего в терминах теории массового обслуживания (ТМО). Математические модели обычно отображают поведение системы в целом с заранее предусмотренными существенными ограничениями. И даже с такими ограничениями не всегда удаётся построить математическую модель системы. В этом случае прибегают к её декомпозиции, создавая математические модели отдельных частей системы с последующим их объединением. Основная проблема, связанная с построением моделей, состоит в том, что каждая такая модель должна разрабатываться индивидуально для очень узкого класса систем, а иногда и только для конкретной системы. К недостаткам этого метода также относятся следующие: Невозможность учитывать функционирование системного программного обеспечения; Невозможность учитывать случайные внешние и внутренние прерывания вычислительного процесса; Трудности изменения набора входных параметров моделей; Сложность выбора математического аппарата и высокая трудоёмкость построения самой модели. Следует обратить внимание также на то, что высокопроизводительные системы в настоящее время строятся с обеспечением свойства масштабируемости, учитывать некоторые элементы которого в аналитических моделях практически невозможно. Задание №6 SPEC (Standard Performance Evaluation Corporation) – это корпорация, созданная в 1988 году, объединяющая ведущих производителей вычислительной техники и программного обеспечения. Основной целью этой организации является разработка и поддержка стандартизованного набора специально подобранных тестовых программ для оценки производительности новейших поколений высокопроизводительных компьютеров. Корпорация SPEC выполняет две основные функции: 1. Разрабатывает тестовые пакеты. 2. Собирает и публикует официальные результаты тестов. Разработчики тестов отказались от использования стандартных абсолютных единиц типа MFLOPS или MIPS. Вместо этого используются собственные относительные единицы SPEC. Результаты «нормализуются» по отношению к аналогичным результатам на так называемой «эталонной» машине. SPEC предлагает следующие основные продукты: – CPU 2000 – тесты вычислительной производительности (ранее использовался пакет тестов CPU95); – JVM98 – виртуальный тест Java-машины; – HPC96 – тесты для высокопроизводительных систем: приложение сейсмической обработки SPECseis96 (Seismic), приложение вычислительной химии SPECchem96 (GAMESS) и приложение моделирования климата SPECclimate (MM5). |