Лекции и практики (1). Курс лекций и материалы для практических занятий
 Скачать 1.01 Mb. Скачать 1.01 Mb.
|

|
IN – предикат вхождения в список: <выражение> IN (<список значений>) определяет множество значений, с которыми будет сравниваться значе- ние <выражения>. Предикат считается истинным, если значение выра- жения равно хотя бы одному из элементов множества. BETWEEN – предикат нахождения в диапазоне: <выражение> BETWEEN <значение1> AND <значение2> определяет, входит ли значение <выражения> в указанные границы. Если значение выражения меньше, чем <значение1>, или больше, чем <значение2>, предикат возвращает "ложь". LIKE – предикат подобия: <выражение> LIKE 'образец' используется для сравнения строк, применяется только к полям типа CHAR, VARCHAR. Возможно использование шаблонов: '_' – один любой символ и '%' – произвольное количество символов (в т.ч., ни одного); IS NULL – предикат неопределённого значения: <выражение> IS NULL определяет, установлено ли значение поля; возвращает истину, если не установлено. Другие предикаты и операторы сравнения возвращают не- определённый результат (NULL), если хотя бы один из операндов имеет значение NULL. Значение NULL интерпретируется как "ложь". Все эти предикаты могут комбинироваться с операцией "не": NOT IN, NOT LIKE, NOT BETWEEN, IS NOT NULL. Примеры: Вывести список программистов и ведущих программистов: SELECT depno, name, post FROM emp WHERE post like ('%программист%');
Увеличить на 10% оклады начальникам отделов и программистам: UPDATE emp SET salary=salary*1.1 WHERE post LIKE 'нач%отдел%' OR post LIKE '%програм%'; 4 строки обновлено. Вывести список сотрудников старше 40 лет из 1-го и 3-го отделов: SELECT depno, name, trunc(months_between(sysdate, born) / 12) AS age FROM emp WHERE depno IN (1, 3) AND trunc(months_between(sysdate, born)/12) > 40;
Примечание: в Oracle функция months_between() возвращает количество месяцев, про- шедших между двумя датами, функция trunc() усекает полученное число до целого. Список сотрудников, не имеющих телефонов: SELECT tabno, name, post FROM emp WHERE phone IS NULL;
Список сотрудников, родившихся в 80-е годы ХХ века: SELECT tabno, name, born, post FROM emp WHERE born BETWEEN '1980-01-01' AND '1989-12-31' ORDER BY name;
Для лучшего понимания работы с базой данных рассмотрим в несколько упрощённом виде, как СУБД выполняет предыдущую команду SELECT: Фаза разбора. По первому ключевому слову определяется тип команды (выборка дан- ных). Разбор команды начинается с части FROM. По словарю-справочнику данных (ССД) система проверяет, что есть та- кая таблица emp, а в ней есть поля tabno,name,born,post. Команда проверяется на синтаксическую правильность: если есть ошиб- ки, пользователю выдаётся сообщение об ошибке. Далее система проверяет права пользователя, который запустил эту ко- манду (также с помощью информации из ССД): если права на чтение данных из указанной таблицы есть, то система приступает к выполнению операции; иначе – выдаёт сообщение о недостаточности прав. Фаза выполнения. Из ССД извлекается адрес, по которому расположены данные указанной таблицы. Система начинает по одной строке считывать данные таблицы из памяти. Для каждой строки проверяется выполнение условия: если условие вы- полняется, то строка помещается в курсор, иначе – пропускается. После считывания всех строк содержимое курсора упорядочивается, из строк в курсоре извлекаются те поля, которые участвуют в списке выбо- ра, и выводятся на экран в виде таблицы (если пользователь работает в интерактивном режиме). Примечание: в действительности кроме вышеперечисленных шагов СУБД выполняет много дополнительных действий (например, выбирает способ доступа к данным для более эффективного выполнения запроса), но об этом мы поговорим позже (в главе 8). Функции агрегирования Для подсчёта различных агрегированных значений (по группе записей) стандарт SQL включает т.н. функции агрегирования: COUNT(*) – определяет количество строк (записей) в результате. MAX(<поле>), MIN(<поле>) – определяет максимальное (минимальное) значение указанного поля в результирующем множестве. SUM(<поле>) – определяет арифметическую сумму значений указанного числового поля в результирующем множестве записей. AVG(<поле>) – определяет среднее арифметическое значений указанного числового поля в результирующем множестве записей. Правила уточнения использования агрегирующих функций: COUNT (<поле>) – подсчёт количества ненулевых значений поля; COUNT (distinct <поле>) – подсчёт количества разных значений поля; SUM (distinct <поле>) – суммирование разных значений поля; AVG (distinct <поле>) – среднее арифметическое разных значений поля. Примеры: Посчитать количество сотрудников предприятия: SELECT count(*), ' человек(а)' FROM emp;
Определить минимальную и максимальную зарплату сотрудников: SELECT min(salary) AS minsal, max(salary) AS maxsal FROM emp;
Определить среднюю зарплату сотрудников 3-го отдела: SELECT avg(salary) AS avg3 FROM emp WHERE depno=3;
Агрегирующие функции можно комбинировать с фразой GROUP BY: в этом случае подсчёт будет производиться для каждой группы записей с одина- ковым значением комбинации полей, указанных в GROUP BY. Примеры: Посчитать количество сотрудников по отделам: SELECT depno, count(*), ' сотрудник(а)' FROM emp GROUP BY depno;
Сумма зарплаты по отделам: SELECT depno, sum(salary) AS sumsal FROM emp GROUP BY depno;
 Если включить в список выбора поля, не указанные в GROUP BY, то СУБД не будет выполнять такой запрос и выдаст ошибку "нарушение условия группирования" (not a GROUP BY expression). Например, нельзя получить сведения о том, у каких сотрудников самая высокая зарплата в своём отделе с помощью такого запроса: select depno, name, max(salary) as max_sal from emp group by depno; Здесь список выбора содержит поле, не входящее в список полей (усло- вий) агрегирования GROUP BY. На рис. 3.7 приведён пример данных о со- трудниках. Для этих данных система не сможет выдать однозначный результат для вышеприведённого запроса: выдавать для отдела 3 фамилию Саниной или фамилию Павлова в качестве обладателей самой высокой зарплаты в отделе. Поэтому данный запрос синтаксически неверен! 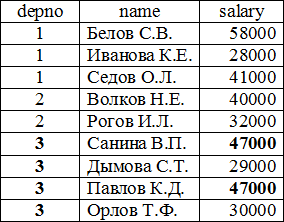 Рис. 3.7. Пример данных о сотрудниках Примечание: в некоторых СУБД (например, в MySQL) нарушение правила использования фразы GROUP BY не является синтаксической ошибкой. Тем не менее, его следует придерживаться в любых СУБД, если вы хотите получить предсказуемый результат. Если при использовании фразы GROUP BY необходимо вывести не все группы, а только те, которые удовлетворяют некоторому условию, то условие на результаты агрегирующих функций можно указать только в части HAVING. В части WHERE указывать агрегирующие функции нельзя: это синтаксическая ошибка. Это ограничение определяется порядком вычисления результатов ко- манды SELECT: если указать условие на агрегирующую функцию в части WHERE, то на момент проверки этого условия значения агрегирующих функ- ций ещё не подсчитано, поэтому его невозможно проверить. Ниже приведён пример использования фразы HAVING. Вывести список отделов, в которых количество сотрудников больше трёх: SELECT depno as "Отдел", count(*) as "Количество сотрудников" FROM emp GROUP BY depno HAVING count(*)>3;
Запрос SELECT на нескольких таблицах Результатом запроса SELECT на нескольких таблицах будет декартово произведение исходных таблиц. Если в части WHEREпри этом указать усло- вие соответствия значений полей разных таблиц, то получится соединение таб- лиц. Для полей с одинаковыми именами необходимо указывать имя таблицы (или алиас) перед именем поля, разделяя их точкой (т.н. квалифицированная ссылка). Примеры: Соединение таблиц. Вывести список сотрудников с детьми: SELECT e.name, c.name AS child, c.born FROM emp e, children c /* e, c – алиасы таблиц*/ WHERE e.tabno = c.tabno /* условие соединения */ ORDER BY e.name, c.born;
Другой формой записи операции соединения является использование ключевых слов INNERJOIN: SELECT e.name, c.name AS child, c.born FROM emp e INNER JOIN children c ON e.tabno = c.tabno ORDER BY e.name, c.born; Посчитать количество сотрудников по отделам: SELECT d.name, count(*), ' сотрудник(а)' FROM emp e, depart d WHERE e.depno=d.depno GROUP BY d.depno, d.name;
Обратите внимание: данные об отделе 4, в котором нет сотрудников, вы- ведены не будут, т.к. для записи о 4-м отделе не выполняется условие соеди- нения (e.depno=d.depno). Кроме внутреннего соединения (INNER JOIN) существует ещё внешнее соединение (OUTERJOIN). Продемонстрируем его на примере. Различают 3 типа внешнего (открытого) соединения: LEFT JOIN – левое открытое соединение таблиц R и S, при котором в ре- зультат входят все строки левой таблицы R и те строки правой таблицы S, которые удовлетворяют условию соединения таблиц; RIGHT JOIN – правое открытое соединение таблиц R и S, при котором в результат входят все строки правой таблицы S и те строки левой таблицы R, которые удовлетворяют условию соединения таблиц; FULL JOIN – полное открытое соединение таблиц R и S, которое являет- ся объединением левого и правого открытого соединения. Таблица 3.6. Филиалы фирмы (Departs) Таблица 3.7. Объекты недвижимости (Obj)   Для данных из таблиц 3.6 – 3.7 эти операции можно записать так: select id, o.City, Oid from departs d LEFT JOIN obj o ON d.city = o.city; select id, o.City, Oid from departs d RIGHT JOIN obj o ON d.city = o.city; select id, o.City, Oid from departs d FULL JOIN obj o ON d.city = o.city; Данные в табл. 3.8 являются результатом полного внешнего соединения таблиц 3.6 и 3.7, при этом первые 5 строк образуют левое открытое соединение, а последние пять строк – правое открытое соединение. Таблица 3.8. Внешнее соединение
{ } Обратите внимание: при отсутствии соответствия строк правой и левой таблицы пустые ячейки имеют значение NULL. Подзапросы Подзапросом называется запрос SELECT, который находится внутри другой команды SQL. Подзапросы можно разделить на следующие группы в зависимости от возвращаемых результатов: Скалярные – это подзапросы, возвращающие единственное значение. Векторные – подзапросы, возвращающие от 0 до нескольких однотипных элементов (список элементов). Табличные – это подзапросы, возвращающие таблицу. Подзапросы бывают коррелированные и некоррелированные. Коррели- рованные подзапросы содержат ссылки на значения полей в запросе верхнего уровня, а некоррелированные – не содержат. Некоррелированный подзапрос вычисляется один раз для запроса верхнего уровня, а коррелированный – для каждой строки запроса верхнего уровня. Сначала рассмотрим использование подзапросов в команде SELECT. Подзапросы могут располагаться в разных частях этой команды: в части FROM– табличные некоррелированные; в части WHERE– любые; в части HAVING– любые; в части SELECT– скалярные. Подзапрос всегда стоит справа от оператора сравнения или предиката. Следующие операторы используются для модификации операторов сравнения: ALL– оператор, эквивалентный понятию "все". Например: > ALL(< ALL) – больше (меньше) каждого значения элементов результиру- ющего множества. ANY(SOME) – оператор, эквивалентный понятию "любой". = ANY– равно одному из значений элементов результирующего множества (эквивалентно использованию предиката IN). > ANY(< ANY) – больше (меньше) любого значения элементов результиру- ющего множества. EXISTS – оператор, эквивалентный понятию "существует". Может исполь- зоваться с логическим оператором NOT. Если список, модифицированный оператором ALL, содержит NULL- значение, то результирующий запрос будет пуст, т.к. нельзя сравнить никакое значение с NULL-значением. Выражение <>ANY(…) не эквивалентно NOT IN: оно выполняется всегда, кроме случаев сравнения со списком NULL-значений. Примерыиспользованияподзапросоввчасти WHERE: Выдать список сотрудников, имеющих детей: а) с помощью операции соединения таблиц: SELECT distinct e.* FROM emp e, children c WHERE e.tabno=c.tabno; б) с помощью некоррелированного векторного подзапроса: SELECT * FROM emp WHERE tabno IN (SELECT tabno FROM children); в) с помощью коррелированного табличного подзапроса: SELECT * FROM emp e WHERE EXISTS (SELECT * FROM children c WHERE e.tabno=c.tabno); Оператор EXISTS возвращает "истину", если подзапрос выбирает хотя бы одну строку, и "ложь", если результат подзапроса пуст.
Выдать список сотрудников, оклад которых выше среднего на предприятии (некоррелированный скалярный подзапрос): SELECT depno, name, salary FROM emp WHERE salary > ANY(SELECT avg(salary) FROM emp);
ПримерыиспользованияподзапросоввчастиFROM: Выдать список сотрудников, имеющих оклады выше среднего по отделу: а) с помощью подзапроса в части WHERE: SELECT depno, name, post, salary FROM emp e WHERE salary > (SELECT avg(salary) FROM emp m WHERE m.depno = e.depno); б) с помощью подзапроса в части FROM: SELECT e.depno, name, post, salary FROM emp e, (SELECT depno, avg(salary) as avgsal FROM emp GROUP BY depno) m WHERE e.depno=m.depno AND e.salary>avgsal;
Второй вариант будет работать быстрее, т.к. подзапрос в части FROM вы- числяется один раз, а коррелированный подзапрос в части WHERE вычисляется для каждой строки запроса верхнего уровня (в нашем случае – для каждого со- трудника). ПримериспользованияподзапросоввчастиHAVING: Выдать список отделов, в которых средние оклады ниже среднего оклада по предприятию: SELECT depno, avg(salary) FROM emp GROUP BY depno HAVING avg(salary) < (SELECT avg(salary) FROM emp);
Предложение UNIONпозволяет объединять результаты нескольких за- просов SELECT для реализации соответствующей операции реляционной ал- гебры. Результаты этих запросов должны быть построены по одной схеме. Предложение ORDER BYможет встречаться в таком запросе один раз – в кон- це последнего предложения SELECT. ПримериспользованияоперацииUNION: Посчитать количество сотрудников по всем отделам (включая те отделы, в которых нет сотрудников): SELECT depno, count(*), ' сотрудник(а)' FROM emp GROUP BY depno UNION SELECT depno, 0, ' сотрудников' FROM depart WHERE depno NOT IN (SELECT depno FROM emp) ORDER BY 1; /* упорядочение по первому столбцу */
А с помощью подзапроса в части SELECT можно запрос из примера 23 написать гораздо короче. (К сожалению, использование подзапроса в части SELECTподдерживается не всеми СУБД). ПримериспользованияподзапросоввчастиSELECT: Подсчёт количества сотрудников по всем отделам (включая те отделы, в ко- торых нет сотрудников): SELECT depno, (SELECT count(*) FROM emp e WHERE e.depno=d.depno) AS cnt FROM depart d ORDER BY 1; /* упорядочение по первому столбцу */ Самосоединение В команде SELECT можно обратиться к одной и той же таблице несколь- ко раз. При этом для каждой таблицы необходимо задать свой алиас, чтобы можно было обращаться к полям этих таблиц. Система будет выполнять такой запрос на основе декартова произведения таблиц, поэтому необходимо указы- вать условие соединения. А для того чтобы исключить соединение записи таб- лицы с самой собой в запросе на самосоединение необходимо также указывать условие типа "не равно" (<>, >, <). Примериспользованиясамосоединения: Вывести список детей сотрудников, у которых есть младшие братья или сёстры: SELECT e.name, c1.name AS child1, c1.born AS born1, c2.name AS child2, c2.born AS born2 FROM children c1, children c2, emp e WHERE c1.tabno=e.tabno -- первое условие соединения AND c1.tabno=c2.tabno -- второе условие соединения AND c1.born
Замечания по использованию NULL-значений Понятие неопределённого значения (NULL-значения) включено в стан- дарт SQL. Это значение не зависит от типа данных и может быть присвоено по- лю любого типа. Значение NULL несравнимо ни с каким другим значением, даже со значе- нием NULL. То есть при сравнении двух неопределённых значений А и В (А IS NULLи В IS NULL) условие (А=В) даст NULL, и это будет интерпретиро- вано как "ложь". Таким образом, в SQL применяется трёхзначная логика ("да", "нет", "не знаю"), о чём надо помнить при формировании условий сравнения. ПримервлиянияNULL-значенийнарезультат: Вывести список сотрудников, причём сначала – тех, у которых номер теле- фона начинается с '114', а затем – всех остальных: SELECT e.* FROM emp e WHERE phone LIKE '114%' UNION ALL SELECT e.* FROM emp e WHERE phone not LIKE '114%'; В результате выполнения данного запроса те сотрудники, у которых нет те- лефона (phone IS NULL), выведены не будут, хотя с точки зрения привычной двузначной логики условие (phone LIKE '114%' UNION ALL phone NOT LIKE '114%') даёт полное множество событий. Тем не менее, из правила о несравнимости NULL-значений ни с какими другими значениями есть исключения: предложение GROUPBYобъединяет все NULL-значения в одну группу, предикат DISTINCT<имя поля> оставляет только одно значение NULL, функция AVGне учитывает NULL-значения, и сумма значений поля делится на количество ненулевых (ISNOTNULL) значений. Оператор CASE Многие СУБД поддерживают оператор CASE. Этот оператор может быть использован в одной из двух синтаксических форм записи: |