абоба. Чурсин Н. А.. Курсовая работа по дисциплине Языки программирования для статистической обработки данных
 Скачать 255.01 Kb. Скачать 255.01 Kb.
|

Кафедра прикладной математики ЗАДАНИЕ на выполнение курсовой работы по дисциплине Языки программирования для статистической обработки данных
Тема работы: Разработка автоматического сборщика данных со специализированных источников, интеграция с хранилищем данных Исходные данные: среда разработки на языке R, стандарты языка R, методическое пособие, техническая документация. Перечень вопросов, подлежащих разработке, и обязательного графического материала: Создание алгоритма автоматической сборки данных; Реализация и тестирование автоматического сборщика средствами языка R; Синхронизация автоматического сборщика с базой данных.
Москва 2022 ОТЗЫВ на курсовую работу по дисциплине «Языки программирования для статистической обработки данных» Студент Чурсин Н. А. ИНБО-05-20 (ФИО студента) (Группа) Характеристика курсовой работы
Замечаний: Рекомендуемая оценка: ___________ Митина О. А. Подпись руководителя ФИО руководителя Содержание Введение В современном мире анализ данных представляет собой важную область в математике и информационных технологиях. Но прежде чем анализировать данные определённой тематики, их необходимо найти. Существует множество способов поиска необходимых данных: взаимодействие с API сайта, получение информации непосредственно от владельца сайта напрямую (без использования API), ручной поиск информации и другие. Несмотря на это, поиск данных является нетривиальной задачей. Немногие сайты предоставляют API для взаимодействия с информационной системой, потому что разработка и последующая поддержка API может составить серьёзную статью расходов, как денежных, так и временных. Но как же тогда получить необходимую информацию? Хорошим решением данной проблемы может послужить web-scrapping. С помощью несложных скриптов можно получить огромное количество данных из различных информационных систем, осуществить предобработку данных и интегрировать их в единую базу. Также стоит отметить многоразовость кода, полученный скрипт можно использовать и после обновления информации на странице, чтобы получить актуальные данные. Цель данной курсовой работы — написание алгоритма для автоматической сборки данных посредством языка R и синхронизация этого алгоритма с базой данных. Основные задачи, решаемые в курсовой работе: изучение методических пособий и научной литературы, связанной с web-scrapping’ом; обучение оформлению официальных документов; использование языка программирования R для написания автоматического сборщика данных — web-scrapper’а; интеграция данных в единую базу. Теоретическая часть Что такое «web-scrapping» Web Scraping – это популярный метод получения контента практически даром. У нас такой метод называется «парсинг контента» или «парсинг сайтов». Метод состоит в том, что специально обученный алгоритм заходит на главную страницу сайта и начинает переходить по всем внутренним ссылкам, тщательно собирая внутренности указанных вами блоков. В качестве результата работы – готовый CSV файл, в котором вся нужная информация лежит в строгом порядке. Полученный CSV можно использовать для последующей генерации почти уникального контента. Да и в целом, как таблица, такие данные представляют большую ценность. Понятие «веб-страница» Прежде чем мы займёмся web-scrapping’ом, нам необходимо разобраться с тем, что же такое «веб-страница», и как она устроена. С точки зрения пользователя, веб-страница содержит текст, изображения и ссылки, организованные таким образом, чтобы они были эстетически привлекательными и легко читаемыми. Но сама веб-страница написана на определённых языках кодирования, которые интерпретируются веб-браузерами в привычный нам вид. Важно отметить, что для web-scrapping’а мы будем взаимодействовать с фактическим содержимым веб-страницы: кодом до того, как он будет интерпретирован браузером. Разберём основные языки, предназначенные для создания веб страниц: язык гипертекстовой разметки (HTML), используемый для форматирования структуры веб-страницы; расширяемый язык разметки (XML), применяемый для создания логической структуры данных, их хранения и передачи в виде, удобном для компьютера, и для человека; каскадные таблицы стилей (CSS), отвечающие за внешний вид веб-страницы; язык программирования JavaScript, обеспечивающий функциональность веб-страницы. Для того, чтобы лучше понять структуру веб-страницы, подробнее рассмотрим HTML, XML и CSS. HTML В отличие от R, HTML не является языком программирования. Вместо этого он называется языком разметки, — он описывает содержимое и структуру веб-страницы. HTML организован с помощью тегов, окружённых символами «<» и «>». Разные теги выполняют разные функции, также теги могут вкладываться друг в друга. Вместе теги формируют веб-страницу, включают в себя её содержимое. Каждый тег имеет определённое имя, чтобы его можно было идентифицировать в HTML-документе. Теги могут быть парными и непарными, при этом парные теги формируют «древовидную» структуру страницы. Эта древовидная структура позволит нам найти определённые теги при использовании возможностей языка R для просмотра веб-страниц. Если в теге есть другие теги, вложенные в него, мы будем называть содержащий тег родительским, а каждый из тегов в нём — дочерними. Если у родительского тега больше одного дочернего элемента, то дочерние теги вместе называются родственными. Таким образом понятия родителя, потомка и родственных тегов дают нам представление об иерархии тегов. XML Формат и структура XML менее предсказуемы, чем HTML. Хотя они и очень похожи, пользователи могут создавать свои собственные теги с помощью XML. Рассмотрим простейший пример, изображённый на рисунке 1.1.  Рисунок 1.1 — пример простой XML страницы Теги типа CSS В то время, как HTML и XML предоставляют содержимое и структуру веб-страницы, CSS предоставляет информацию о том, как должна быть оформлена веб-страница. Когда мы говорим о стиле в CSS, мы имеем в виду широкий спектр объектов. Стиль может относиться к цвету определённых элементов HTML или к их расположению. Перед изучением web-scrapping’а стоит разобраться в двух основных концепциях CSS, — это классы и идентификаторы. Сначала поговорим о классах, если бы мы хотели сделать похожие элементы веб-сайта одинаковыми, то могли бы напрямую вставить CSS-код, содержащий информацию о цвете каждой строки текстового тега HTML, как это показано на рисунке 1.2.  Рисунок 1.2 — пример CSS-кода без использования классов Атрибут «style» указывает на то, что мы пытаемся применить CSS-код к HTML-тегу « ». Внутри кавычек мы можем видеть пару ключ-значение «color:red». Мы повторили эту пару ключ-значение несколько раз, но если возникнет необходимость изменить цвет текста, то нам придётся менять каждую строку одну за другой. Вместо того, чтобы повторять атрибут «style» в каждом теге, мы можем заменить его на класс-селектор, как это указано на рисунке 1.3.  Рисунок 1.3 — замена атрибута style на класс-селектор Класс-селектор позволяет нам указать, что данные теги каким-то образом связаны. В отдельном CSS файле нам нужно создать класс, отвечающий за красный текст и определить, как он выглядит, как это показано на рисунке 1.4. 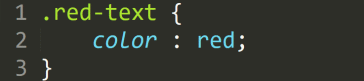 Рисунок 1.4 — создание CSS-класса Объединение этих двух элементов в одну веб-страницу даст тот же эффект, что и первый набор тегов, указанный на рисунке 1.2, но позволит нам легче вносить изменения в код страницы. Нас, конечно, интересует web-scrapping, а не создание веб-страницы. Но при просмотре веб-страниц нам часто нужно выбрать определённый класс HTML-тегов, поэтому необходимо понимать основы работы классов CSS. Точно так же нам часто может понадобиться собрать определённые данные, помеченные с помощью идентификатора. Идентификаторы CSS используются для присвоения элементу идентификационного номера или имени, при этом не меняя свойства элемента. Пример идентификатора приведён на рисунке 1.5.  Рисунок 1.5 — пример идентификатора Если идентификатор прикреплён к HTML-тегу, то нам будет легче найти и идентифицировать этот тег, когда мы будем искать наши данные с помощью языка R. Библиотека rvest Библиотека rvest является одной из библиотек пакета tidyverse, который используется для анализа данных. Это обеспечивает полноценное взаимодействие с другими библиотеками из данного пакета. Библиотека «BeautifulSoup», созданная на основе языка программирования «Python», является прородителем библиотеки rvest. Чтобы использовать rvest библиотеку, нам сначала нужно установить её, а затем импротировать с помощью функции library(). Пример установки библиотеки указан на рисунке 1.6.  Рисунок 1.6 — установка библиотеки rvest Библиотека rvest имеет особый синтаксис, унаследованный от пакета magrittr, а именно, pipes, которые мы встречали в dplyr и tidyverse: %>%. Раз у одного процесса есть вход, а у другого — выход, и их можно подменять, то логично предположить, что их можно соединить. Данный подход носит название «pipeline» (конвейер). Благодаря конвейеру можно соединять программы и протаскивать данные сквозь них, как сквозь цепочку функций, каждая из которых выступает в роли преобразователя или фильтра. Инструмент разработчка в браузере В большинстве современных браузеров есть инструмент, который позволяет пользователям напрямую просматривать исходный код веб-страницы. Данный инструмент называется «Developer tool» или инструмент разработчика. Мы можем найти инструмент разработчика, нажав правой кнопкой мыши на любой странице и в открывшемся меню выбрав вариант «Просмотр кода элемента». Откроется окно с кодом элемента, на котором был сделан клик. Большинство веб-страниц, которые мы сможем увидеть, будут чрезвычайно сложны, но инструменты разработчика облегчат нам выбор необходимых элементов веб-страницы, которые мы захотим обработать. Практическая часть | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

