Лабораторная работа Построение диаграммы декомпозиции первого уровня в нотации idef0 Цель работы
 Скачать 8.2 Mb. Скачать 8.2 Mb.
|

Лабораторная работа № 5.Построение диаграммы декомпозиции в нотации IDEF3Цель работы:
IDEF3 - методология моделирования, использующая графическое описание информационных потоков, взаимоотношений между процессами обработки информации и объектов, являющихся частью этих процессов. IDEF3 дает возможность аналитикам описать ситуацию, когда процессы выполняются в определенной последовательности, а также описать объекты, участвующие совместно в одном процессе. Любая IDEF3-диаграмма может содержать работы, связи, перекрестки и объекты ссылок. Работа (Unit of Work, activity). Изображается прямоугольником с прямыми углами (рис. 1) и имеет имя, выраженное отглагольным существительным, обозначающим процесс действия, одиночным или в составе фразы, и номер (идентификатор); другое имя существительное в составе той же фразы обычно отображает основной выход (результат) работы (например, «Изготовление изделия»). Все стороны работы равнозначны. В каждую работу может входить и выходить ровно по одной стрелке.  Рисунок 1. Работа IDEF3 Связи. Связи показывают взаимоотношения работ. Все связи в IDEF3 однонаправлены и могут быть направлены куда угодно, но обычно диаграммы IDEF3 стараются построить так, чтобы связи были направлены слева направо. В IDEF3 возможны три вида связей:
Перекрестки (Junction). Окончание одной работы может служить сигналом к началу нескольких работ, или же одна работа для своего запуска может ожидать окончания нескольких работ. Перекрестки используются для отображения логики взаимодействия стрелок при слиянии и разветвлении или для отображения множества событий, которые могут или должны быть завершены перед началом следующей работы. Различают перекрестки для слияния (Fan-in Junction) и разветвления (Fan-out Junction) стрелок. Перекресток не может использоваться одновременно для слияния и для разветвления. Типы перекрестков:
Объект ссылки. Объект ссылки в IDEF3 выражает некую идею, концепцию или данные, которые нельзя связать со стрелкой, перекрестком или работой. Они используются в модели для привлечения внимания читателя к каким-либо важным аспектам модели. При внесении объектов ссылок помимо имени следует указывать тип объекта ссылки (рис. 2).  Рисунок 2. Объект ссылки В данной лабораторной работе необходимо одну из работ, находящихся на диаграммах IDEF0, рассмотреть детально с помощью методологии IDEF3. При декомпозиции работы IDEF0 (и DFD) нужно учитывать, что стрелки на диаграммах IDEF0 или DFD означают потоки информации или объектов, передаваемых от одной работы к другой. На диаграммах IDEF3 стрелки могут показывать только последовательность выполнения работ, т.е. они имеют другой смысл, чем стрелки IDEF0 или DFD. Поэтому при декомпозиции работы IDEF0 или DFD в диаграмму IDEF3 стрелки не мигрируют на нижний уровень. Если необходимо показать на дочерней диаграмме IDEF3 те же объекты, что и на родительских диаграммах IDEF0 или DFD, необходимо использовать объекты ссылки. Проведем декомпозицию работы Сборка настольных компьютеров диаграммы А3 "Сборка и тестирование компьютеров". Данная работа начинает выполняться, когда поступают заказы на сборку. Первым действием проверяется наличие необходимых для сборки комплектующих и заказ со склада отсутствующих. Далее комплектующие подготавливаются для последующей сборки (освобождение от упаковки, снятие заглушек и т.п.). Следующим шагом начинается непосредственно сам процесс сборки: установка материнской платы в корпус и процессора на материнскую плату, установка ОЗУ и винчестера. Данные действия выполняются всегда, независимо от конфигурации компьютера. Далее по желанию клиента могут быть установлены некоторые дополнительные комплектующие - DVD привод, ТВ-тюнер, кард-ридер. На этом сборка компьютера завершается. Следующим шагом идет установка операционной системы. По желанию клиента также может быть установлено дополнительное программное обеспечение. Последним действием составляется отчет о проделанной работе. Выделим работу Сборка настольных компьютеров диаграммы А3 "Сборка и тестирование компьютеров", нажмем на кнопку "Go to Child Diagram" панели инструментов и выберем нотацию IDEF3. Дочерние работы всегда можно добавить на диаграмму в процессе ее построения, поэтому число дочерних работ оставим по умолчанию. При создании дочерней диаграммы BPWin переносит граничные стрелки родительской работы, их необходимо удалить и заменить на объекты ссылок. Заменим стрелки "Заказы на настольные компьютеры", "Необходимые комплектующие", "Список необходимых комплектующих", "Настольные компьютеры" и "Результаты сборки" на объекты ссылок - кнопка "Referent" на панели инструментов, в появившемся окне выбрать переключатель "Arrow" и выбрать из списка нужное название (рис. 3): 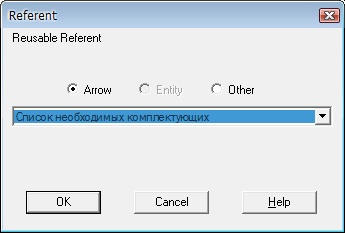 Рисунок 3. Добавление объекта ссылки Далее начинаем располагать на диаграмме работы, отражающие указанные выше действия, выполняемые при сборке компьютеров. Итоговая диаграмма декомпозиции работы в нотации IDEF3 имеет вид: 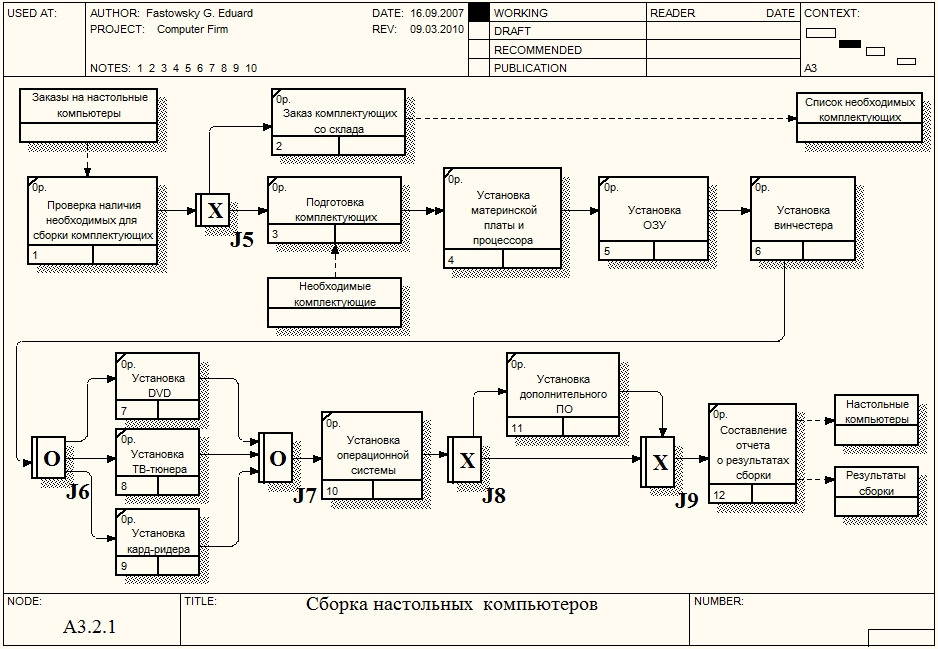 Рисунок 4. Диаграмма декомпозиции Рассмотрим основные особенности этой диаграммы. После проверки наличия необходимых для сборки комплектующих возможно одно из двух действий - или заказ со склада недостающих комплектующих, или, если все комплектующие в наличии, их подготовка. Поэтому мы поставили перекресток разветвления типа "Исключающее ИЛИ". Работы "Подготовка комплектующих" и "Установка материнской платы и процессора" соединены связью "Поток объектов". Тем самым мы показываем, что между этими работами передаются объекты. Все последующие работы соединяются связями "старшая стрелка", поскольку они только показывают последовательность действий над одними и теме же объектами. После установки винчестера возможна установка DVD привода, ТВ-тюнера, кард-ридера или любая их комбинация. Поэтому мы поставили перекресток разветвления типа "Асинхронное ИЛИ". Такой же перекресток стоит и после завершения этих работ. Далее после установки операционной системы может быть установлено дополнительное ПО, или же сразу формируется отчет, поэтому мы поставили перекресток разветвления типа "Исключающее ИЛИ". За перекрестком разветвления типа "Исключающее ИЛИ" может следовать только такой же перекресток слияния, поэтому перед работой "Составление отчета о результатах сборки" мы поставили такой же. Содержание отчета:
Лабораторная работа № 6.Построение диаграммы декомпозиции в нотации DFDЦель работы:
Диаграммы потоков данных (Data flow diagram, DFD) используются для описания документооборота и обработки информации. Подобно IDEF0, DFD представляет моделируемую систему как сеть связанных между собой работ. Их можно использовать как дополнение к модели IDEF0 для более наглядного отображения текущих операций документооборота в корпоративных системах обработки информации. Главная цель DFD - показать, как каждая работа преобразует свои входные данные в выходные, а также выявить отношения между этими работами. Любая DFD-диаграмма может содержать работы, внешние сущности, стрелки (потоки данных) и хранилища данных. Работы. Работы изображаются прямоугольниками с закругленными углами (рис. 1), смысл их совпадает со смыслом работ IDEF0 и IDEF3. Так же как работы IDEF3, они имеют входы и выходы, но не поддерживают управления и механизмы, как IDEF0. Все стороны работы равнозначны. В каждую работу может входить и выходить по несколько стрелок.  Рисунок 1. Работа в DFD Внешние сущности. Внешние сущности изображают входы в систему и/или выходы из нее. Одна внешняя сущность может одновременно предоставлять входы (функционируя как поставщик) и принимать выходы (функционируя как получатель). Внешняя сущность представляет собой материальный объект, например заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что они находятся за пределами границ анализируемой системы. Внешние сущности изображаются в виде прямоугольника с тенью и обычно располагаются по краям диаграммы (рис. 2).  Рисунок 2. Внешняя сущность в DFD Стрелки (потоки данных).Стрелки описывают движение объектов из одной части системы в другую (отсюда следует, что диаграмма DFD не может иметь граничных стрелок). Поскольку все стороны работы в DFD равнозначны, стрелки могут могут начинаться и заканчиваться на любой стороне прямоугольника. Стрелки могут быть двунаправлены. Хранилище данных. В отличие от стрелок, описывающих объекты в движении, хранилища данных изображают объекты в покое (рис. 3). Хранилище данных - это абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми. Оно в общем случае является прообразом будущей базы данных, и описание хранящихся в нем данных должно соответствовать информационной модели (Entity-Relationship Diagram).  Рисунок 3. Хранилище данных в DFD Декомпозиция работы IDEF0 в диаграмму DFD. При декомпозиции работы IDEF0 в DFD необходимо выполнить следующие действия:
Строго придерживаться правил нотации DFD не всегда удобно, поэтому BPWin позволяет создавать в DFD диаграммах граничные стрелки. Построение диаграммы декомпозиции. Проведем декомпозицию работы Отгрузка и снабжение диаграммы А0 "Деятельность предприятия по сборке и продаже компьютеров и ноутбуков". В этой работе мы выделили следующие дочерние работы:
Выделим работу Отгрузка и снабжение диаграммы А0 "Деятельность предприятия по сборке и продаже компьютеров и ноутбуков", нажмем на кнопку "Go to Child Diagram" панели инструментов и выберем нотацию DFD. При создании дочерней диаграммы BPWin переносит граничные стрелки родительской работы, их необходимо удалить и заменить на внешние сущности. Стрелки механизмов, стрелки управления "Правила и процедуры", "Управляющая информация" и стрелку выхода "Отчеты" на дочерней диаграмме задействованы не будут, чтоб не загромождать диаграмму менее существенными деталями. Остальные стрелки заменим на внешние сущности - кнопка "External Reference Tool" на панели инструментов, в появившемся окне выбрать переключатель "Arrow" и выбрать из списка нужное название (рис. 4): 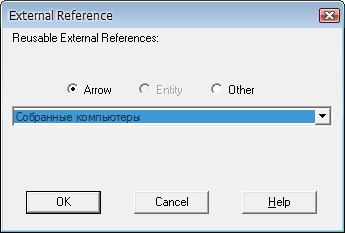 Рисунок 4. Добавление внешней сущности Далее разместим дочерние работы, свяжем их со внешнеми сущностями и между собой (рис. 5):  Рисунок 5. Работы и внешние сущности Центральной здесь является работа "Хранение комплектующих и собранных компьютеров". На ее вход поступают собранные компьютеры и полученные от поставщиков комплектующие, а также список необходимых для сборки компьютеров комплектующих. Выходом этой работы будут необходимые комплектующие (если они есть в наличии), список отсутствующих комплектующих, передаваемый на вход работы "Снабжение необходимыми комплектующими" и собранные компьютеры, передаваемые на отгрузку. Выходами работ "Снабжение необходимыми комплектующими" и "Отгрузка готовой продукции" будут, соответственно, заказы поставщикам и готовая продукция. Следующим шагом необходимо определить, какая информация необходима для каждой работы, т.е. необходимо разместить на диаграмме хранилища данных (рис. 6).  Рисунок 6. Итоговая диаграмма декомпозиции Работа "Снабжение необходимыми комплектующими" работает с информацией о поставщиках и с информацией о заказах, сделанных у этих поставщиков. Стрелка, соединяющая работу и хранилище данных "Список поставщиков" двунаправленная, т.к. работа может как получать информацию о имеющихся поставщиках, так и вносить данные о новых поставщиках. Стрелка, соединяющая работу с хранилищем данных "Список заказов" однонаправленная, т.к. работа только вносит информацию о сделанных заказах. Работа "Хранение комплектующих и собранных компьютеров" работает с информацией о получаемых и выдаваемых комплектующих и собранных компьютеров, поэтому стрелки, соединяющая работу с хранилищами данных "Список комплектующих" и "Список собранных компьютеров" двунаправленные. Также эта работа при получении комплектующих должна делать отметку о том, что заказ поставщикам выполнен. Для этого она связана с хранилищем данных "Список заказов" однонаправленной стрелкой. Обратите внимание, что на DFD диаграммах одно и тоже хранилище данных может дублироваться. Наконец, работа "Отгрузка готовой продукции" должна хранить информацию по выполненным отгрузкам. Для этого вводится соответствующее хранилище данных - "Данные по отгрузке". Последним действием необходимо стрелки родительской работы затуннелировать (рис. 7): 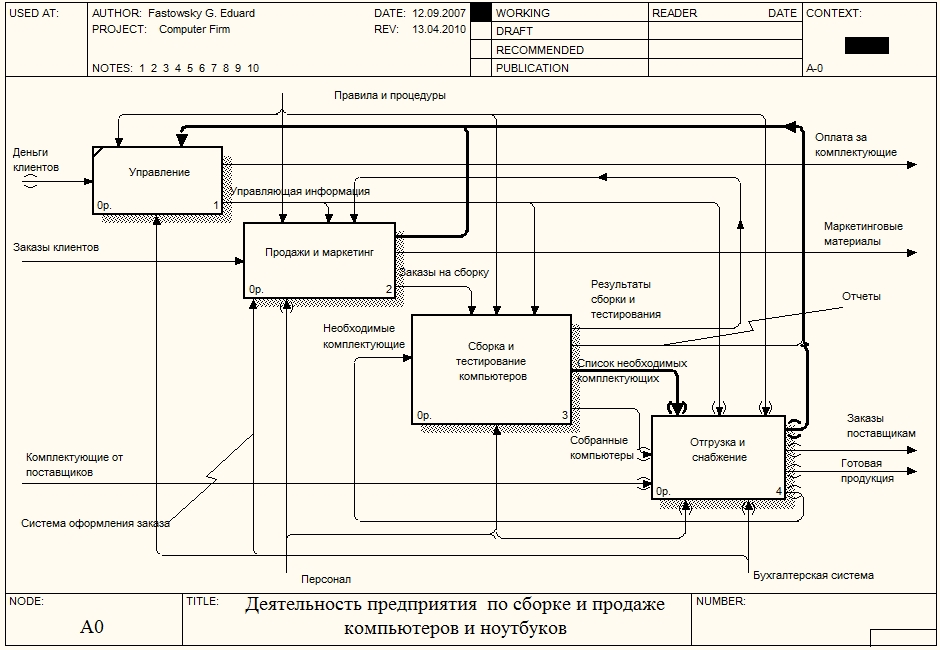 Рисунок 7. Диаграмма IDEF0 с затуннелированными стрелками работы "Отгрузка и снабжение" Содержание отчета:
Лабораторная работа № 7.Построение FEO диаграмм и диаграмм дерева узловЦель работы:
FEO диаграммыFEO (For Exposition Only) диаграммы (другое название - диаграммы только для экспозиции, описания) используются для иллюстрации альтернативной точки зрения, для отображения отдельных деталей, которые не поддерживаются явно синтаксисом IDEF0. FEO диаграммы позволяют нарушить любое синтаксическое правило, посколько эти диаграммы - фактически обычные картинки - копии стандартных диаграмм. Например, работа на FEO диаграмме может не иметь стрелок выхода или управления. AllFusion Process Modeler позволяет также строить FEO диаграммы для диаграмм в нотации DFD. Для построения FEO диаграммы необходимо выбрать пункт меню Diagram -> Add FEO Diagram и в появившемся окне выбрать диаграмму, на базе которой будет строиться FEO диаграмма (рис. 1). 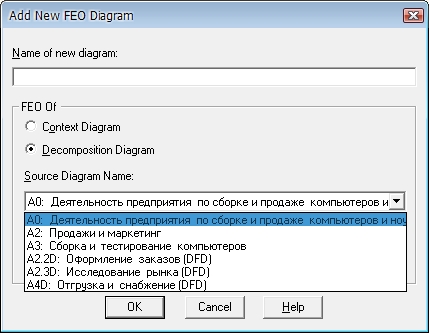 Рисунок 1. Добавление FEO диаграммы Созданная диаграмма будет точной копией родительской диаграммы и будет иметь номер, равный номеру родительской диаграммы + буква F. После создания диаграммы ее можно изменять. При этом изменения не будут влиять на родительскую диаграмму. Для просмотра списка имеющихся FEO диаграмм нужно выбрать в Обозревателе Модели (Model Explorer) вкладку Diagrams (рис.2).  Рисунок 2. Просмотр списка имеющихся FEO диаграмм Построим FEO диаграмму для диаграммы декомпозиции второго уровня А0 "Деятельность предприятия по сборке и продаже компьютеров и ноутбуков" и покажем на ней как дочерние работы связаны между собой. Для этого создаем диаграмму, как показано выше, и удаляем на ней все граничные стрелки. Итоговая FEO диаграмма показана на рис.3: 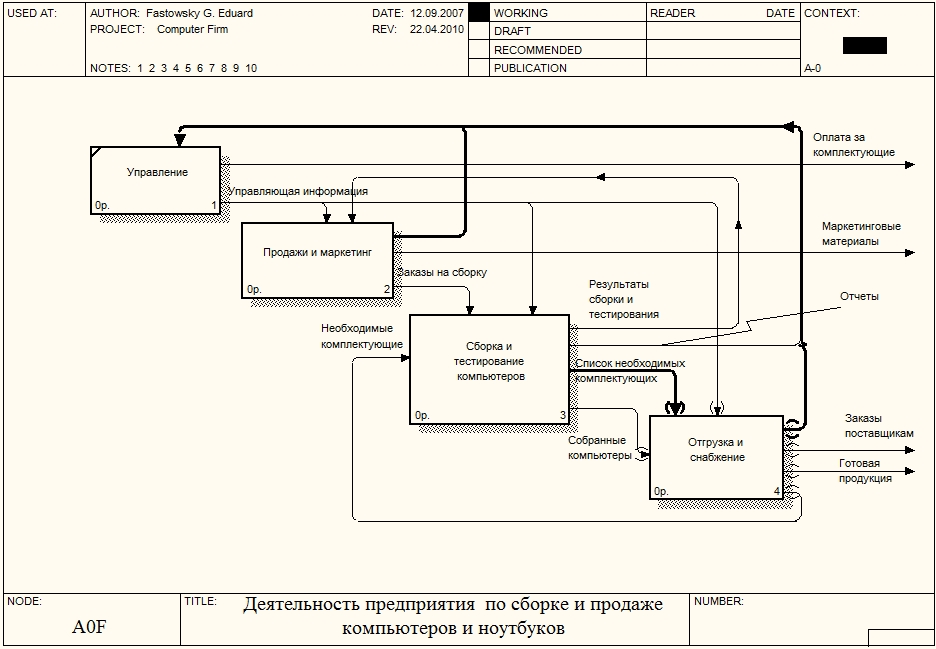 Рисунок 3. FEO диаграмма Диаграммы дерева узловДиаграмма дерева узлов показывает иерархическую зависимость работ, но не взаимосвязи между работами. В одной модели диаграмм дерева узлов может быть множество, поскольку дерево может быть построено на произвольную глубину и не обязательно с корня. Для построения диаграммы дерева узлов необходимо выбрать пункт меню Diagram -> Add Node Tree. Появляется мастер, с помощью которого диаграмма будет создана. На первом шаге (рис.4) задается имя диаграммы дерева узлов, узел верхнего уровня и глубина дерева. Имя дерева узлов по умолчанию совпадает с именем работы верхнего уровня, а номер диаграммы генерируется автоматически как номер узла верхнего уровня + буква N. 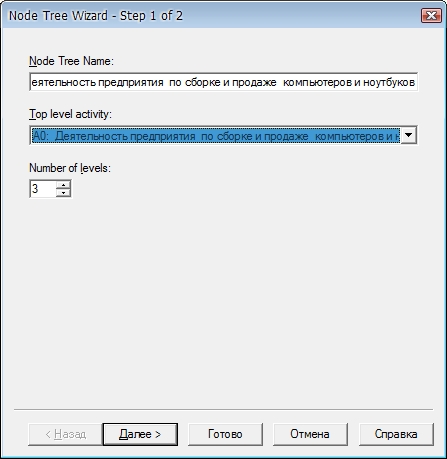 Рисунок 4. Создание диаграммы дерева узлов. Шаг 1 На втором шаге мастера (рис.5) задаются свойства диаграммы дерева узлов. 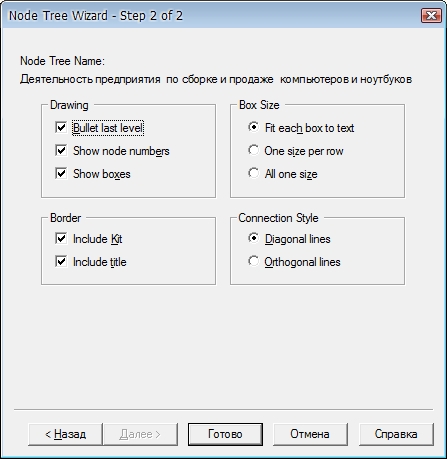 Рисунок 5. Создание диаграммы дерева узлов. Шаг 2 По умолчанию нижний уровень декомпозиции показывается в виде списка, остальные работы - в виде прямоугольников. Если необходимо отобразить все дерево в виде прямоугольников, то следует снять галочку возле опции "Bullet last level". Список всех созданных диаграмм дерева узлов можно посмотреть в Обозреватели Модели. Диаграмма дерева узлов для всех узлов модели показана на рис. 6:  Рисунок 6. Диаграммы дерева узлов Содержание отчета:
Лабораторная работа № 8.Основы работы с программным продуктомAllFusion ERwin Data ModelerCA ERwin Data Modeler (далее ERwin) - CASE-средство для проектирования и документирования баз данных, которое позволяет создавать, документировать и сопровождать базы данных, хранилища и витрины данных. Работа с программой начинается с создания новой модели, для которой нужно указать тип и целевую СУБД (рис.1). 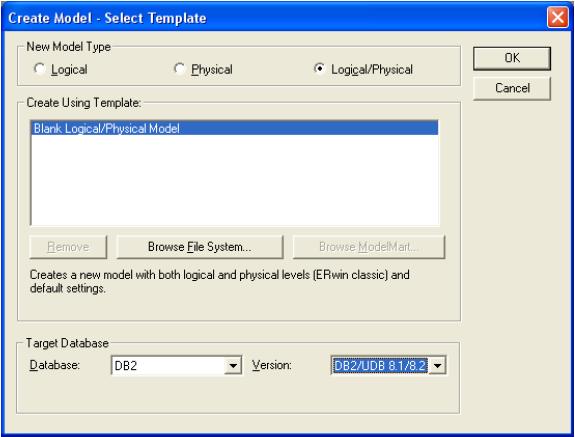 Рисунок 1.Создание новой модели ERwin позволяет создавать логическую, физическую модели и модель, совмещающую логический и физический уровни. Логический уровень - это абстрактный взгляд на данные, на нем данные представляются так, как выглядят в реальном мире, и могут называться так, как они называются в реальном мире (например "Постоянный клиент", "Отдел" или "Заказ"). Объекты модели, представляемые на логическом уровне, называются сущностями и атрибутами. Логическая модель данных является универсальной и никак не связана с конкретной реализацией СУБД. Физический уровень зависит от конкретной СУБД. В физической модели содержится информация о всех объектах БД. Физическая модель зависит от конкретной реализации СУБД. Одной и той же логической модели могут соответствовать несколько разных физических моделей. На логическом уровне ERwin поддерживает две нотации (IE и IDEF1X), на физическом - три (IE, IDEF1X и DM). Далее будет рассматриваться работа с ERwin в нотации IDEF1X. Переключение между логической и физической моделями данных осуществляется через список выбора на стандартной панели (рис.2).  Рисунок 2.Переключение между уровнями Примечание. В созданной модели с настройками по умолчанию некорректно отображаются русские символы. Чтобы устранить этот недостаток, необходимо подкорректировать используемые в модели шрифты. Для этого необходимо зайти в меню Format -> Default Fonts & Colors, последовательно пройтись по всем вкладкам, в качестве шрифта выбрав любой шрифт, название которого заканчивается на CYR (например, Arial CYR), и выставив переключатель Apply To в значение All Objects. Логический уровень модели данныхДля создания на логическом уровне сущностей и связей между ними предназначена панель Toolbox: Рисунок 3.Панель Toolbox
После создания сущности ей нужно задать атрибуты. Для этого нужно дважды щелкнуть по ней или в контекстном меню выбрать пункт Attributes (рис.4). 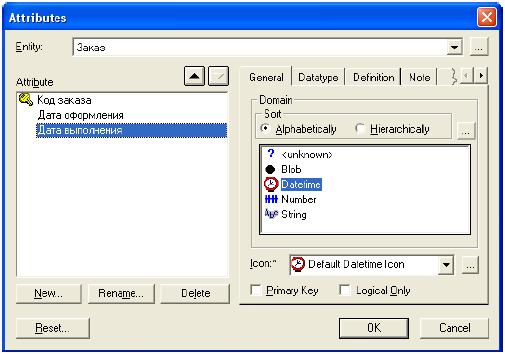 Рисунок 4.Окно атрибутов выбранной сущности В появившемся окне можно просмотреть и отредактировать информацию о созданных атрибутах, создать новые. Здесь же задается первичный ключ. Для создания нового атрибута следует нажать кнопку New. В появившемся окне можно выбрать тип атрибута (BLOB, дата/время, число, строка), задать имя атрибута (Attribute Name) и имя столбца (Column Name), который будет соответствовать атрибуту на физическом уровне (рис.5).  Рисунок 5.Окно создания атрибута После создания сущностей создаются связи между ними. При создании идентифицирующей связи атрибуты, составляющие первичный ключ сущности-родителя, мигрируют в состав первичного ключа сущности-потомка, при создании неидентифицирующей связи - просто в состав атрибутов сущности-потомка. Задать свойства связи или поменять ее тип можно дважды щелкнув по ней или выбрав в контекстном меню пункт Relationship Properties (рис. 6). Здесь во вкладке General можно задать имя связи (в направлении родитель-потомок и потомок-родитель), мощность связи (ноль, один или больше; один и больше (Р); ноль или один (Z); точно (конкретное число) ), поменять тип связи. Во вкладке RI Action можно задать ограничения целостности. Пример логической модели базы данных приведен на рис. 7. 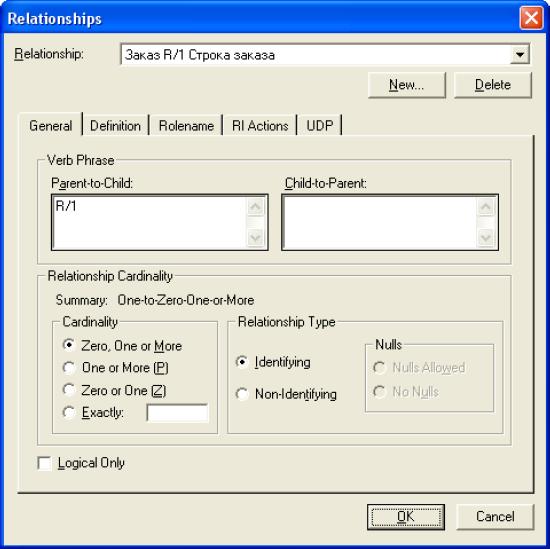 Рисунок 6.Окно свойств связи  Рисунок 7.Пример логической схемы БД Физический уровень модели данныхПри переключении с логического уровня на физический автоматически будет создана физическая схема базы данных (рис.8)  Рисунок 8.Автоматически созданная физическая схема БД Ее можно дополнить, отредактировать или изменить. Принципы работы с физической схемой аналогичны принципам работы с логической схемой. По готовой физической схеме можно сгенерировать скрипты для выбранной СУБД. Для этого предназначен пункт меню Tools -> Forward Engineering/Schema Generation (рис.9). 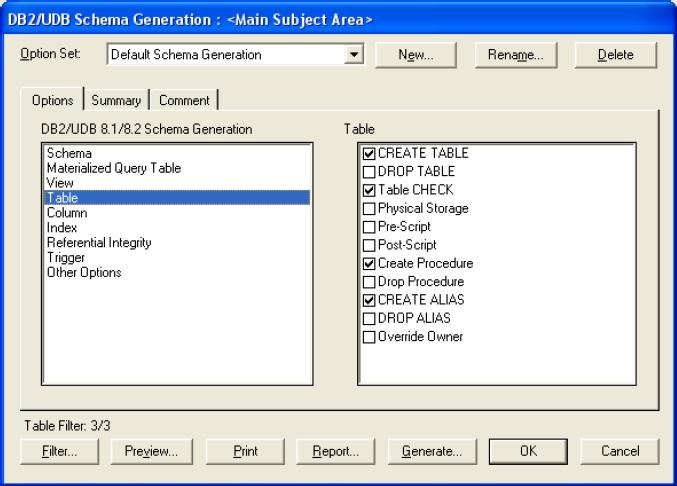 Рисунок 9.Окно генерации SQL-скриптов для целевой СУБД__ Здесь можно указать, какие именно скрипты следует генерировать, предварительно просмотреть их и непосредственно сгенерировать (при этом ERwin произведет подключение к целевой СУБД и в автоматическом режиме выполнит все SQL-скрипты). Данная лабораторная работа будет засчитываться вместе с лабораторной работой № 9 "Построение логической модели данных предметной области". Лабораторная работа № 9.Построение логической модели данных предметной областиЦель работы:
В данной лабораторной работе необходимо построить в нотации IDEF1X в CASE-средстве ERwin Data Modeler логическую схему данных предметной области, бизнес-процессы которой моделировались в предыдущих лабораторных работах. Примечание. При построении модели можно ограничиться 5-6 сущностями. IDEF1X IDEF1X основан на подходе Чена и позволяет построить модель данных, эквивалентную реляционной модели в третьей нормальной форме. Нотация Чена и сам процесс построения диаграмм сущность-связь изучалась в курсе "Организация баз данных и знаний", поэтому здесь мы рассмотрим только отличия IDFE1X от нотации Чена. Сущность (Entity) - реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области. Каждая сущность должна иметь наименование, выраженное существительным в единственном числе. Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Атрибут (Attribute) - любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Наименование атрибута должно быть выражено существительным в единственном числе. Связь (Relationship) - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. В методе IDEF1X все сущности делятся на зависимые и независимые от идентификаторов. Сущность является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности. Независимая сущность изображается в виде обычного прямоугольника, зависимая - в виде прямоугольника с закругленными углами. В IDEF1X существуют следующие виды мощностей связей:
Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком, с точкой на конце линии у сущности-потомка. По умолчанию мощность связи принимается равной N. Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае — неидентифицирующей. Идентифицирующая связь изображается сплошной линией, неидентифицирующая - пунктирной линией. В ERwin'е при установлении идентифицирующей связи атрибуты первичного ключа родительской сущности автоматически переносятся в состав первичного ключа дочерней сущности. Эта операция называется миграцией атрибутов. В дочерней сущности новые атрибуты помечаются как внешний ключ (FK). При установке неидентифицирующей связи атрибуты первичного ключа родительской сущности мигрируют в состав неключевых полей дочерней сущности. Построение логической модели данных предприятия по сборке и продаже компьютеров и ноутбуков. Построение модели данных начинается с выделения сущностей данной предметной области. В нашем случае были выделены следующие сущности:
Далее рассмотрим связи между сущностями:
Итоговая диаграмма показана на рис. 1:  Рисунок 1. Логическая модель данных предприятия по сборке компьютеров и ноутбуков Содержание отчета:
Лабораторная работа № 9 Соответствие логической модели ERwin и модели процессов BPwin Цель работы:изучить на практических примерах соответствие между логической моделью Erwin и моделью процессов Bpwin и генерацию отчетов в Bpwin. Задание:Экспортировать данные из ERwin в Bpwin, привязать в Bpwin полученные данные к одной из работ и к связанным с ней стрелкам и сгенерировать отчет в Bpwin, содержащий данные о привязанных сущностях и атрибутах. Дополнить в Bpwin словарь новой сущностью и связанными с ней атрибутами и экспортировать данные из словаря сущностей из Bpwin в Erwin, сгенерировать отчет по сущностям и атрибутам Bpwin. Заполнить данные, характеризующие модель Bpwin в целом и одну из диаграмм и сгенерировать отчеты, включающие эту информацию. Создать в одной из работ Bpwin пояснения к работе и относящимся к ней стрелкам и сгенерировать отчет, включающий эти пояснения. Ход работы: Этап экспорта данных из ERwin в Bpwin и связывания полученных данных с работами и стрелками. Из модели данных командой экспорта создаем файл экспорта данных из ERwin. В процессе экспорта данных из Erwin создается сообщение о результатах экспорта (Рис.1). В реальной задаче следует создавать сущности и атрибуты на русском языке. 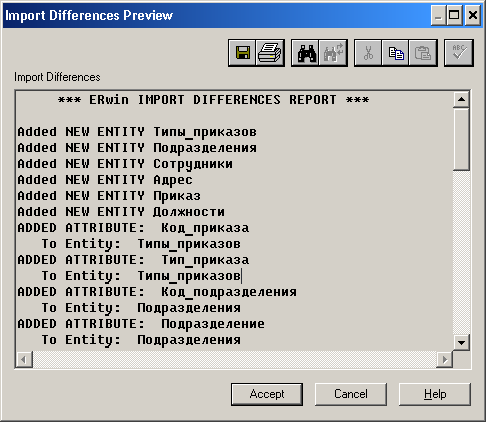 Рис.1. Экспортированные данные из ERwin в Bpwin Далее импортируем данные в Bpwin и привязываем полученные данные к одной из работ и к связанным с ней стрелкам. Генерируем отчет DataUsage Report, содержащий данные о привязанных сущностях и атрибутах (Рис.2).  Рис.2. Отчет DataUsage Report Этап дополнения словаря в Bpwin новой сущностью и атрибутами и экспорта данных из словаря сущностей из Bpwin в Erwin. Новая импортированная в Erwin сущность не имеет первичного ключа и не связана с другими сущностями. Назначение атрибутов первичным ключом и связывание сущностей можно провести только средствами Erwin; другими словами, сущности и атрибуты, созданные в BPwin и затем импортированные в Erwin, можно рассматривать как заготовку для создания полноценной модели данных, а не как готовую модель. Дополним словарь Bpwin новой сущностью и связанными с ней атрибутами. На рисунках 3 и 4 показан пример создания новых сущностей и атрибутов в словаре BPwin. 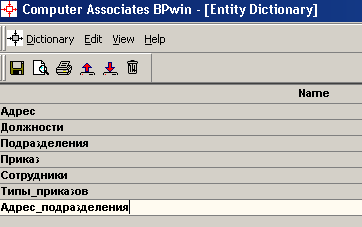 Рис.3. Добавление новой сущности 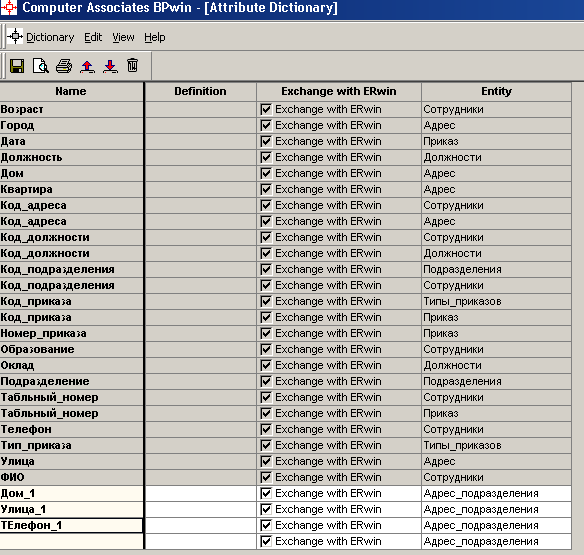 Рис.4. Связывание атрибутов с новой сущностью Командой экспорта экспортируем данные из словаря сущностей из Bpwin в файл экспорта. При импорте данных в Erwin создается сообщение (Рис.5). 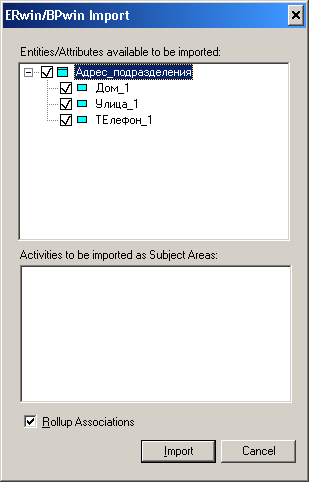 Рис.5. Импортирование данные из Bpwin в Erwin Этап создания отчетов. После заполнения данных, характеризующих модель Bpwin в целом (автор, цель и т.д.) и одну из диаграмм (описание диаграммы), генерируем отчеты Model Report (Рис.6) и Diagram Report (Рис.7). 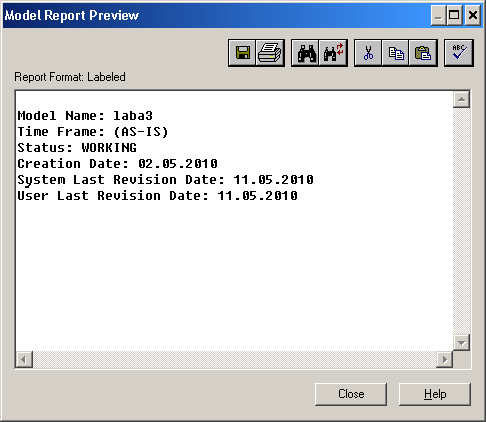 Рис.6. Отчет Model Report 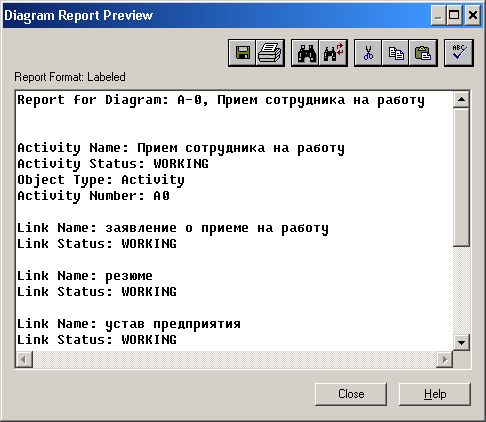 Рис.7. Отчет Diagram Report Создаем в одной из работ Bpwin пояснения к работе и относящимся к ней стрелкам и генерируем отчет Diagram Object Report (Рис.8). 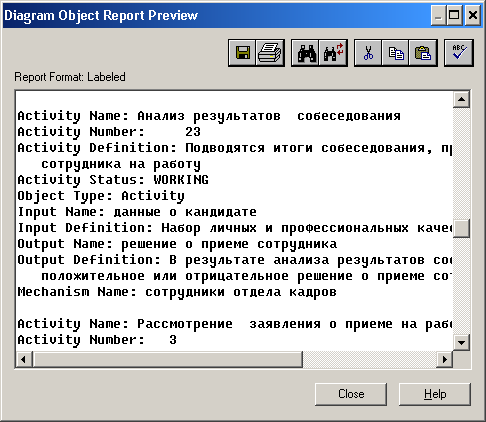 Рис.8. Отчет Diagram Object Report Вывод:благодаря проделанной работе мы на практических примерах получили соответствие между логической моделью Erwin и моделью процессов Bpwin и технологию генерации отчетов в Bpwin. Лабораторная работа № 11 Лабораторная работа № 7 ERwin. Прямое и обратное проектирование Цель работы:овладеть навыками прямого и обратного проектирования в среде ERwin для «файл-серверных» и «клиент-серверных» СУБД. Задание:Реализовать прямое проектирование в архитектуре «файл-сервер» Access. Изменить структуру БД и осуществить обратное проектирование. Реализовать прямое проектирование в архитектуре «клиент-сервер» (MS SQL Server), сгенерировать SQL – код создания базы данных на основе физической модели данных. Ход работы: Этап прямого проектирования в архитектуре «файл-сервер». Рассмотрим исходные логические и физические модели данных (Рис.1, Рис.2).  Рис.1. Логическая модель проектируемой ИС 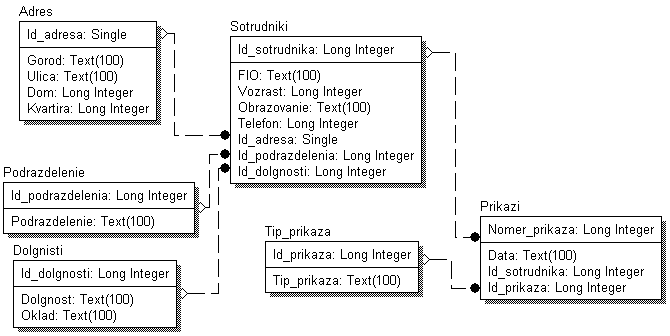 Рис.2. Физическая модель проектируемой ИС Открываем физическую модель ИС и выбираем Access в качестве нужного типа СУБД, после чего типы данных в физической модели изменятся, так как по умолчанию она может быть настроена на другую СУБД. Создаем пустую базу данных в Access и подключаемся к ней (Рис.3, Рис.4).  Рис.3. Подключение к СУБД Access  Рис.4. Выбор БД Access Далее в меню выбираем Tools/ Forward Engineer/Shema Generation. В открывшемся окне на вкладке Options в пункте Index поставили галочки напротив пунктов Primary Key и Foreign Key, отвечающих за генерацию первичных и внешних ключей (Рис.5). 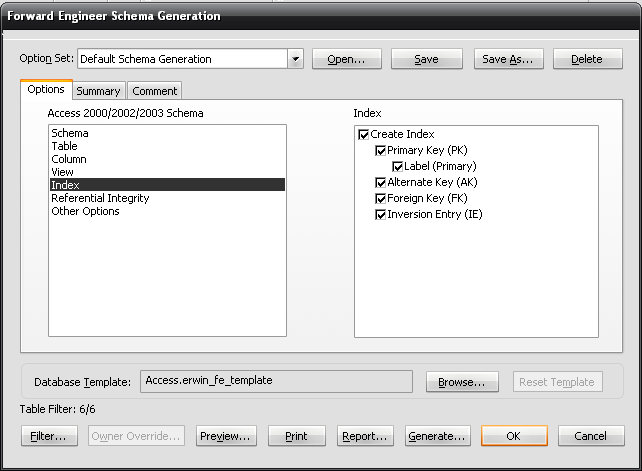 Рис.5. Установки по генерации схемы для базы данных Access После завершения операции по переносу физической модели в Access заходим в полученную базу данных и проверяем результат (Рис.6). 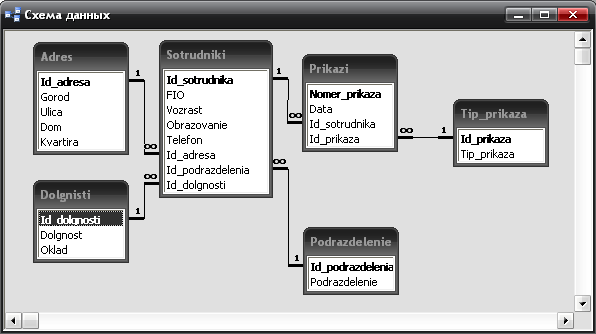 Рис.6. Схема данных в Access Этап обратного проектирования. В базе данных Access в таблице Адрес добавили поле e-mail и сохранили изменения. Далее зашли в Erwin и в меню выбрали Tools/ Reverse Engineer. В открывшемся окне выбрали тип новой модели - физическая, и СУБД из которой будем импортироваться физическая модель – Access (Рис.7).  Рис.7. Установки обратного проектирования Далее настраиваем параметры проектирования (Рис.8). 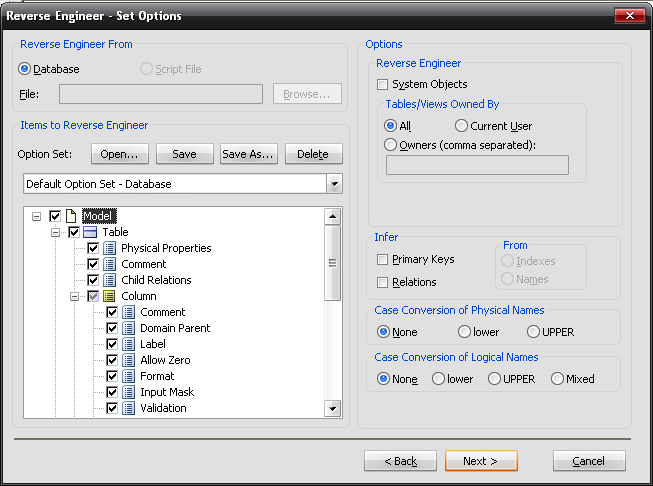 Рис.8. Установки по генерированию схемы для Erwin. Подключение к Access аналогично режиму прямого проектирования. Получаем физическую модель (Рис.9). 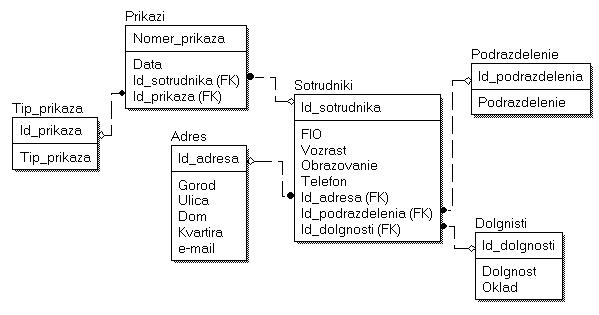 Рис.9. Физическая модель, полученная из БД Access Этап проектирования БД для архитектуры “клиент-сервер”. Проделываем действия как и для варианта с подключением к Access, а также сохраняем SQL-запрос на создание БД В среде Erwin открыли физическую модель ИС, изменили тип СУБД на Microsoft SQL Server, в меню выбрали Tools/ ForwardEngineer/ShemaGeneration. В открывшемся окне на вкладке Options в пункте Index поставили галочки напротив пунктов PrimaryKey и ForeignKey, отвечающих за генерацию первичных и внешних ключей. Нажали кнопку Preview (Рис.10). 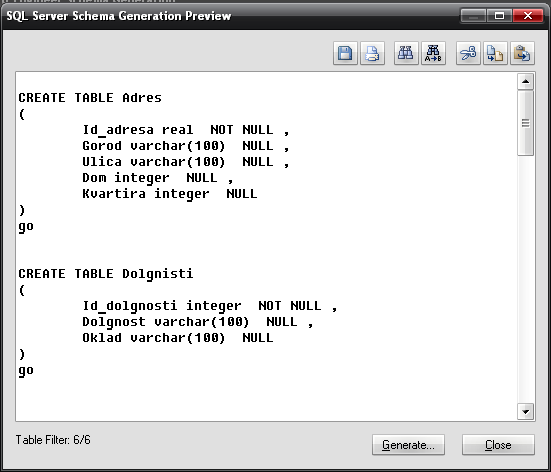 Рис.10. Генерация SQL-кода для MS SQL Вывод:В процессе выполнения лабораторной работы получены навыки прямого и обратного проектирования в среде Erwin для «файл-серверных», «клиент-серверных» СУБД. |