Лабораторная работа ╣ 2 (1). Лабораторная работа по Data Mining
 Скачать 0.55 Mb. Скачать 0.55 Mb.
|

3. Группировка данныхСложно делать выводы на основе необработанной первичной информации. Аналитику для принятия решения почти всегда нужна сводная информация. Совокупные данные намного более информативны, тем более, если их можно получить в различных разрезах. В Deductor Studio предусмотрен инструмент, реализующий сбор сводной информации – «Группировка». Группировка позволяет объединять записи по полям - измерениям и агрегируя данные в полях-фактах для дальнейшего анализа. Исходные данные Допустим, что у аналитика имеется статистика по банкам России за определенный период. Она находится в файле «banks.txt». Перед ним стоит задача выявления ряда городов, в которых прибыль банков самая большая для использования этих данных в дальнейшем. Для этого аналитик должен обратить внимание на следующие поля таблицы из файла: «БАНК», «ФИЛИАЛЫ», «ГОРОД», «ПРИБЫЛЬ». Т.е. информация о названии банка, городе, в котором он находится (филиалы банка могут находиться в разных городах – следовательно, по одному и тому же банку может быть несколько записей с данными по разным городам) и прибыль банка. Ясно, что для решения поставленной задачи первым делом необходимо найти суммарную прибыль всех банков в каждом городе. Для этого и необходима группировка. Для начала следует импортировать данные по банкам из текстового файла. Просмотреть исходную информацию можно в виде куба, где по строкам будут названия банков, а по столбцам – города. С помощью визуализатора «Куб» также можно получить требуемую информацию, выбрав в качестве измерения поле «ГОРОД», а в качестве факта «ПРИБЫЛЬ». Но нам необходимо получить эти данные для последующей обработки, следовательно, необходимо сделать аналогичную группировку. Группировка по городам Находясь в узле импорта, запустим мастер обработки. Выберем в качестве обработки группировку данных. На втором шаге мастера установим назначение поля «ГОРОД» как измерение, а назначение поля «ПРИБЫЛЬ» как факт. В качестве функции агрегации у поля «ПРИБЫЛЬ» следует указать Сумму. 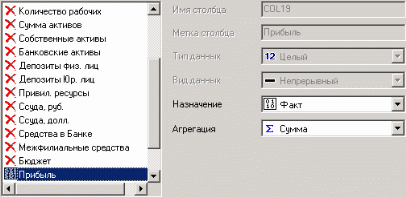 Таким образом, после обработки получим суммарные данные по прибыли всех банков по каждому городу. Их можно просмотреть, используя таблицу. Теперь аналитику можно выполнять следующий этап обработки данных. 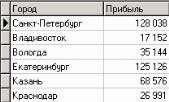 !! В этом задании необходимо сделать 2 вида группировки – Город-Прибыль и Банк-Прибыль (в виде «Таблицы»). 4. Преобразование данных к скользящему окнуКогда требуется прогнозировать временной ряд, тем более, если налицо его периодичность (сезонность), то лучшего результата можно добиться, учитывая значения факторов не только в данный момент времени, но и, например, за аналогичный период прошлого года. Такую возможность можно получить после трансформации данных к скользящему окну. То есть, например, при сезонности продаж с периодом 12 месяцев, для прогнозирования количества продаж на месяц вперед можно в качестве входного фактора указать не только значение количества продаж за предыдущий месяц, но и за 12 месяцев назад. Обработка создает новые столбцы путем сдвига данных исходного столбца вниз и вверх (глубина погружения, горизонт прогноза). Исходные данные Продемонстрируем сам принцип трансформации данных, используя данные из файла «Sliding.txt». В нем всего 2 поля – «АРГУМЕНТ» - аргумент (время), «ФУНКЦИЯ» – временной ряд. Импортируем данные из файла (необходимо указать тип полей – вещественный) и построим диаграмму. 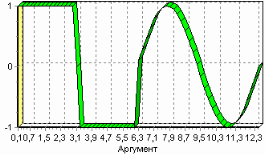 Преобразование скользящим окном В мастере преобразования укажем назначение столбца «ФУНКЦИЯ» используемым, установим для него глубину погружения 12. 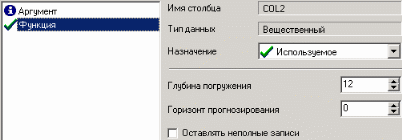 После трансформации были получены новые столбцы – «ФУНКЦИЯ - 12», ... «ФУНКЦИЯ - 2», «ФУНКЦИЯ - 1» на основе столбца «ФУКЦИЯ». Если на диаграмме посмотреть несколько таких столбцов, то видно, что данные в них сдвинуты относительно друг друга. 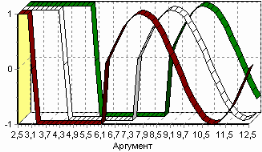 5. Прогнозирование умножения с помощью нейронных сетейНейросети – механизм, который используют для прогнозирования и решения задач классификации. Они применяются в основном там, где существует нелинейные зависимости результата от входных факторов. Исходные данные Рассмотрим прогнозирование с помощью нейронных сетей на примере прогнозирования результата умножения двух чисел – файл «multi.txt». В нем содержится таблица со следующими полями: «АРГУМЕНТ1», «АРГУМЕНТ2» – множители, «ПРОИЗВЕДЕНИЕ» – их произведение. Импортировав данные из файла, можно посмотреть результат умножения, используя таблицу. 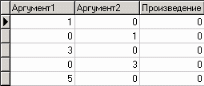 Прогнозирование результата умножения Пусть необходимо построить модель прогноза умножения, подавая на вход которой два множителя получать на выходе их произведение. Для этого необходимо, находясь на узле импорта, открыть мастер обработки. В нем выбрать в качестве обработки нейронную сеть и перейти к следующему шагу мастера. На втором шаге мастера необходимо установить назначение полей «АРГУМЕНТ1» и «АРГУМЕНТ2» как входные, а поле «ПРОИЗВЕДЕНИЕ» – как выходное. 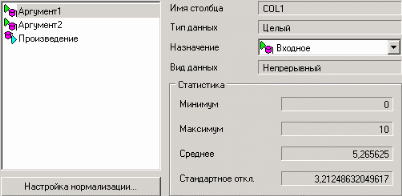 На следующем шаге предлагается настроить разбиение исходного множества данных на обучающее тестовое и валидационное. Здесь необходимо только указать способ разбиения исходного множества данных «Случайно». 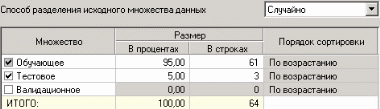 На следующем шаге необходимо указать количество нейронов в скрытом слое – 1, остальное можно оставить по умолчанию. 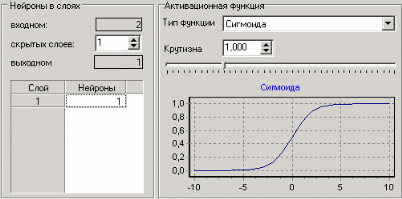 Следующий шаг предлагает выбрать алгоритм обучения и его параметры. Здесь тоже ничего менять не нужно.  Следующий шаг предлагает настроить условия остановки обучения. Укажем, что следует считать пример распознанным, если ошибка меньше 0.005, и также укажем условие остановки обучения при достижении эпохи 10000. 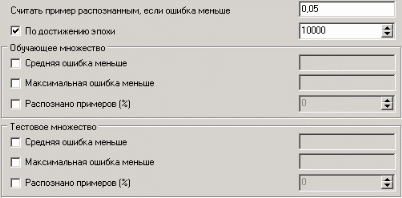 Следующий шаг мастера предлагает запустить процесс обучения и наблюдать в процессе обучения величину ошибки, а также процент распознанных примеров. Параметр «Частота обновления» отвечает за то, через какое количество эпох обучения выводится данная информация. 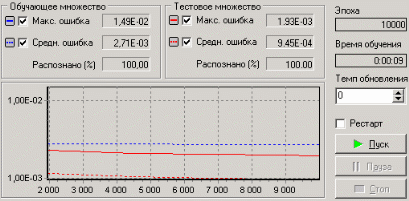 После обучения сети, в качестве визуализаторов выберем Диаграмму, Диаграмму рассеяния, Граф нейросети, Что-если.  Результаты наглядно видны на диаграмме рассеяния, которая показывает рассеяние прогнозируемых данных относительно эталонных. 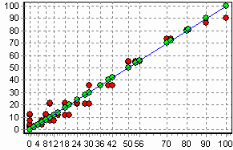 Также можно сравнить эталонные данные с прогнозируемыми, выбрав на обычной диаграмме два поля – «ПРОИЗВЕДЕНИЕ» и «ПРОИЗВЕДЕНИЕ_OUT». 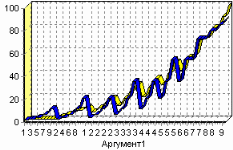 Визуализатор «Что-если» позволит провести эксперимент, введя любые значения множителей АРГУМЕНТ1 и АРГУМЕНТ2 и рассчитав результат их произведения. 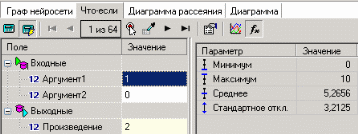 Вид построенной сети можно посмотреть, выбрав визуализатор “Граф нейронной сети”. 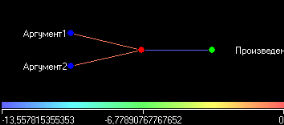 |