Лабораторная работа ╣ 2 (1). Лабораторная работа по Data Mining
 Скачать 0.55 Mb. Скачать 0.55 Mb.
|

9. Пример расчета автокорреляции столбцовВажным фактором для анализа временного ряда и прогноза является определение сезонности. В Deductor Studio таким инструментом является автокорреляция. Вообще корреляция подразумевает под собой зависимость значения одной величины от значения другой. Если их корреляция равна единице, то величины прямо зависимы друг от друга, если нулю – то нет, если минус единица, то зависимость обратная. Линейная автокорреляция ищет зависимости между значениями одной и той же величины, но в разное время. Поэтому нахождение линейной автокорреляционной зависимости и применяется для определения периодичности (сезонности) при обработке временных рядов. Исходные данные Пусть аналитик располагает данными по месячному количеству продаж за определенный период времени. Ему необходимо определить есть ли сезонность, и если есть, то какая. Данные по продажам находятся в файле «Trade.txt». Таблица содержит следующие столбцы: «ПЕРИОД» – год и месяц продаж, «КОЛИЧЕСТВО» – количество продаж за этот месяц. Импортируем данные из текстового файла. Обратите внимание на то, что в файле данные о количестве находятся не в стандартном формате: разделитель дробной и целой части числа не запятая, а точка, поэтому необходимо внести соответствующие изменения в настройки по умолчанию параметров импорта. Выберем в качестве визуализатора Диаграмму для просмотра исходной информации. 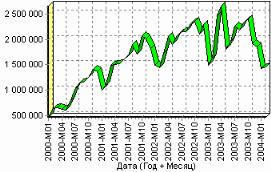 Автокорреляция столбца Количество Как видно, не каждый аналитик сможет судить о сезонности по этим данным, поэтому необходимо воспользоваться автокорреляцией. Для этого откроем мастер обработки, выберем в качестве обработки автокорреляцию и перейдем на второй шаг мастера. В нем необходимо настроить параметры столбцов. Укажем поле «Дата (Год + Месяц)» неиспользуемым, а поле «КОЛИЧЕСТВО» используемым (ведь необходимо определить сезонность количества продаж). Предположим, что сезонность, если она имеет место, не больше года. В связи с этим зададим количество отсчетов равным 15 (тогда будет искаться зависимость u1086 от месяца назад, двух, ..., пятнадцати месяцев назад). Также должен стоять флажок «Включить поле отсчетов набор данных». Он необходим для более удобной интерпретации автокорреляционного анализа.  Перейдем на следующий шаг мастера и запустим процесс обработки. По окончанию, результаты удобно анализировать как в виде таблицы, так и в виде диаграммы. После обработки были получены два столбца – «Лаг» (благодаря установленному флажку в мастере) и «КОЛИЧЕСТВО» - результат автокорреляции. 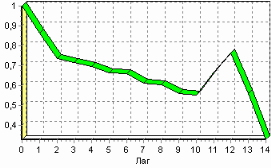 Видно, что вначале корреляция равна единице – то как значение зависит само от себя. Далее зависимость убывает и затем виден пик зависимости от данных 12 месяцев назад. Это как раз и говорит о наличии годовой сезонности. 10. Пример прогноза временного рядаПрогнозирование результата на определенное время вперед, основываясь на данных за прошедшее время – задача, встречающаяся довольно часто (к примеру, перед большинством торговых фирм стоит задача оптимизации складских запасов, для решения которой требуется знать, чего и сколько должно быть продано через неделю, и т.п.; задача предсказания стоимости акций какого-нибудь предприятия через день и т.д. и другие подобные вопросы). Deductor Studio предлагает для этого инструмент «Прогнозирование». Прогнозирование появляется в списке мастера обработки только после построения какой-либо модели прогноза: нейросети, линейной регрессии и т.д. Прогнозировать на несколько шагов вперед имеет смысл только временной ряд (к примеру, если есть данные по недельным суммам продаж за определенный период, можно спрогнозировать сумму продаж на две недели вперед). Поскольку при построении модели прогноза необходимо учитывать много факторов (зависимость результата от данных день, два, три, четыре назад), то методика имеет свои особенности. Покажем ее на примере. Исходные данные У аналитика имеются данные о месячном количестве проданного товара за несколько лет. Ему необходимо, основываясь на этих данных, сказать, какое количество товара будет продано через неделю и через две. Исходные данные по продажам находятся в файле «Trade.txt», известному по предыдущему примеру (расчет автокорреляции). Выполним импорт данных из файла, не забыв указать в мастере, чтобы в качестве разделителя дробной целой частей была точка, а не запятая. Удаление аномалий и сглаживание После импорта данных воспользуемся диаграммой для их просмотра. На ней видно, что данные содержат аномалии (выбросы) и шумы, за которыми трудно разглядеть тенденцию. Поэтому перед прогнозированием необходимо удалить аномалии и сгладить данные. Сделать это можно при помощи парциальной обработки. Запустим мастер обработки, выберем в качестве обработки данных парциальную обработку и перейдем на следующий шаг u1084 мастера. Как известно, второй шаг мастера отвечает за обработку пропущенных значений, которых в исходных данных нет. Поэтому здесь ничего не настраиваем. Следующий шаг отвечает за удаление аномалий из исходного набора. Выберем поле для обработки «КОЛИЧЕСТВО» и укажем для него обработку аномальных явлений (степень подавления – малая). Четвертый шаг мастера позволяет провести спектральную обработку. Из исходных данных необходимо исключить шумы, поэтому выбираем столбец «КОЛИЧЕСТВО» и указываем способ обработки «вычитание шума» (степень вычитания – малая). На следующем шаге запустим обработку, нажав на «пуск». После обработки просмотрим полученный результат на диаграмме. 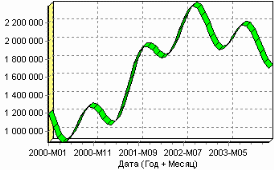 Видно, что данные сгладились, аномалии и шумы исчезли. Также видна тенденция. Теперь перед аналитиком встает вопрос, а как, собственно, прогнозировать временной ряд. Во всех предыдущих примерах мы сталкивались с ситуацией, когда есть входные столбцы - факторы и есть выходные столбцы – результат. В данном случае столбец один. Строить прогноз на будущее необходимо, основываясь на данных прошлых периодов. Т.е. предполагается, что количество продаж на следующий месяц зависит от количества продаж за предыдущие месяцы. Т.е. входными факторами для модели могут быть продажи за текущий месяц, продажи за месяц ранее и т.д., а результатом должны быть продажи за следующий месяц. Т.е. здесь явно необходимо трансформировать данные к скользящему окну. Скользящее окно 12 месяцев назад Запустим мастер обработки, выберем в качестве обработчика скользящее окно и перейдем на следующий шаг. Аналитик провел также авторегрессионый анализ и выяснил наличие годовой сезонности (см. пример с авторегрессией). В связи с этим было решено строить прогноз на неделю вперед, основываясь на данных за 12, 11 месяцев назад, два месяца назад и месяц назад. Поэтому необходимо, назначив поле «КОЛИЧЕСТВО» используемым, выбрать глубину погружения 12. Тогда данные трансформируются к скользящему окну так, что аналитику будут доступны u1074 все требуемые факторы для построения прогноза. 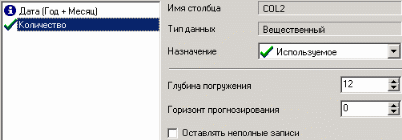 Просмотреть полученные данные можно в виде таблицы. 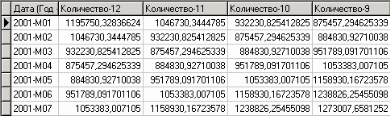 Как видно, теперь в качестве входных факторов можно использовать «КОЛИЧЕСТВО - 12», «КОЛИЧЕСТВО - 11» - данные по количеству 12 и 11 месяцев назад (относительно прогнозируемого месяца) и остальные необходимые факторы. В качестве результата прогноза буден указан столбец «КОЛИЧЕСТВО». Обучение нейросети (прогноз на 1 месяц вперед) Перейдем непосредственно к самому построению модели прогноза. Откроем мастер обработки и выберем в нем нейронную сеть. На втором шаге мастера, согласно с принятым ранее решением, установим в качестве входных поля «КОЛИЧЕСТВО - 12», «КОЛИЧЕСТВО - 11», «КОЛИЧЕСТВО - 2» и «КОЛИЧЕСТВО - 1», а в качестве выходного - «КОЛИЧЕСТВО». Остальные поля сделаем информационными. 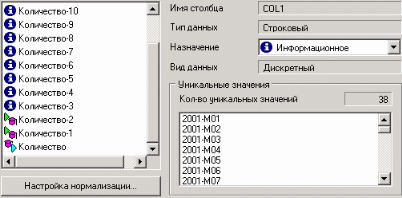 Оставив все остальные параметры построения модели по умолчанию, обучим нейросеть (см. пример «прогнозирование умножения с помощью нейронной сети»). После построения модели для просмотра качества обучения представим полученные данные в виде диаграммы и диаграммы рассеяния. В мастере настройки диаграммы выберем для отображения поля «КОЛИЧЕСТВО» и «КОЛИЧЕСТВО_OUT» - реальное и спрогнозированное значение. 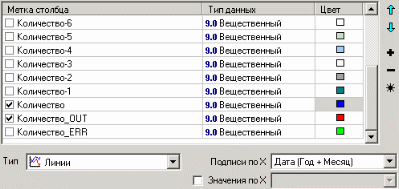 Результатом будет два графика. 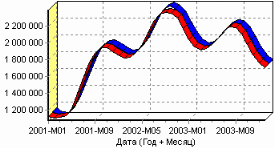 Диаграмма рассеяния более наглядно показывает качество обучения. 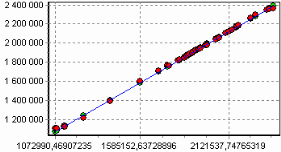 Построение прогноза Нейросеть обучена, теперь осталось самое главное – построить требуемый прогноз. Для этого открываем мастер обработки и выбираем появившийся теперь обработчик «Прогнозирование». На втором шаге мастера предлагается настроить связи столбцов для прогнозирования временного ряда – откуда брать данные для столбца при очередном шаге прогноза. Мастер сам верно настроил все переходы, поэтому остается только указать горизонт прогноза (на сколько вперед будем прогнозировать) равным трем, а также, для наглядности, необходимо добавить к прогнозу исходные данные, установив в мастере соответствующий флажок. 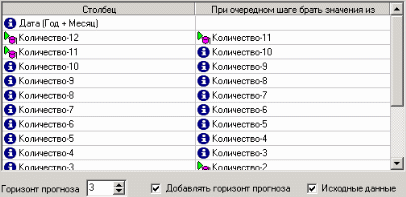 После этого необходимо в качестве визуализатора выбрать диаграмму прогноза, которая появляется только после прогнозирования временного ряда. В мастере настройки столбцов диаграммы прогноза необходимо указать в качестве отображаемого столбец «КОЛИЧЕСТВО», а в качестве подписей по оси Х указать столбец «ШАГ ПРОГНОЗА». Теперь аналитик может дать ответ на вопрос, какое количество товаров будет продано в следующем месяце и даже два месяца спустя. 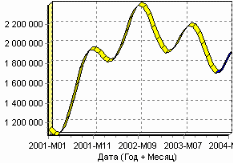 Данный пример показал, как с помощью Deductor Studio прогнозировать временной ряд. При решении задачи были применены механизмы очистки данных от шумов, аномалий, которые обеспечили качество построения модели прогноза далее и соответственно достоверный результат самого прогнозирования количества продаж на три месяца вперед. Также был продемонстрирован принцип прогнозирования временного ряда – импорт, выявление сезонности, очистка, сглаживание, построение модели прогноза и собственно построение прогноза временного ряда, а также экспорт результатов во внешний файл. Подобный сценарий – основа любого прогнозирования временного ряда с той разницей, что для каждого случая приходится, как получить необходимый временной ряд посредством инструментов Deductor Studio (например, группировки), так и подобрать параметры очистки данных и параметры модели прогноза (например, структуры сети, если используется обучение нейронной сети, определение значимых входных факторов). В данном случае приемлемые результаты получились с настройками по умолчанию, в большинстве же случаев предстоит работа по их подбору (например, оценивая качество модели по диаграмме рассеяния). Дополнительно – факторный и корреляционный анализ (см. описание демопримера). |