Лабораторная работа ╣ 2 (1). Лабораторная работа по Data Mining
 Скачать 0.55 Mb. Скачать 0.55 Mb.
|

|
Лабораторная работа по Data Mining. Аналитическая платформа Deductor 1. Примеры обработки данных с помощью инструментов Deductor Studio 1 2. Примеры предобработки данных 5 3. Группировка данных 12 4. Преобразование данных к скользящему окну 13 5. Прогнозирование умножения с помощью нейронных сетей 14 6. Классификация с помощью деревьев решений 18 7. Кластеризация с помощью самоорганизующейся карты Кохонена 22 8. Поиск ассоциативных правил. 26 9. Пример расчета автокорреляции столбцов 31 10. Пример прогноза временного ряда 32 1. Примеры обработки данных с помощью инструментов Deductor StudioDeductor Studio – программа, являющаяся составной частью платформы Deductor. Она содержит механизмы импорта, обработки, визуализации и экспорта данных для быстрого и эффективного анализа и прогнозирования. Данный файл позволит ознакомиться с возможностями, заложенными в Deductor Studio, рассмотреть каждую из них на конкретном примере, а также узнать, как набор механизмов действует в комплексе, ознакомившись в конце со способом построения законченного решения по прогнозированию объемов продаж товаров на три месяца вперед. Все примеры разбиты на несколько категорий, в зависимости от цели, которая ставится перед аналитиком. Так, существует группа инструментов предобработки данных, которая приводит исходные «сырые» данные к виду, пригодному для анализа и обработки (устранение аномалий, сглаживание, заполнение пропусков…), группа инструментов преобразования данных, которая изменяет данные на основе настроек аналитика (группирует, дискретизирует, фильтрует…), группа инструментов анализа данных позволяет найти зависимости одних факторов от других, выявить противоречивые данные, найти сезонность во временных рядах, значимость влияния факторов на результат, а также построить модель прогноза и получить желаемый результат (провести эксперимент, спрогнозировать временной ряд). Импорт данных Импорт данных является отправной точкой анализа данных. Импорт в Deductor может осуществляться из популярных форматов хранения данных, таких как Excel, Access, MS SQL, Oracle, Текстовый файл и прочих. Кроме того, имеется универсальный доступ к любому источнику данных посредством ADO или ODBC.  Рассмотрим пример импорта данных из текстового файла с разделителями, который будет необходим при апробировании технологий платформы Deductor на предлагаемых примерах. Импорт осуществляется путем вызова мастера импорта на панели «Сценарии»  После запуска мастера импорта укажем тип импорта “Текстовый файл с разделителями” и перейдем к настройке импорта. Укажем имя файла, из которого необходимо получить данные (пример для парциальной обработки). В окне просмотра выбранного файла можно увидеть содержание данного файла. 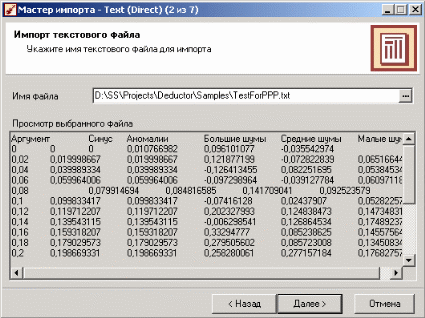 Далее перейдем к настройке параметров импорта. На этой странице мастера предоставляется возможность указать, с какой строки следует начать импорт, указать, то, что первая строка является заголовком, возможность добавить первичный ключ. Указать, что является символом-разделителем столбцов, а также указать ограничитель строк, разделитель целой и дробной части вещественного числа, разделитель компонентов даты и ее формат. Далее перейдем к настройке параметров импорта. На этой странице мастера предоставляется возможность указать, с какой строки следует начать импорт, указать, то, что первая строка является заголовком, возможность добавить первичный ключ. Указать, что является символом-разделителем столбцов, а также указать ограничитель строк, разделитель целой и дробной части вещественного числа, разделитель компонентов даты и ее формат. 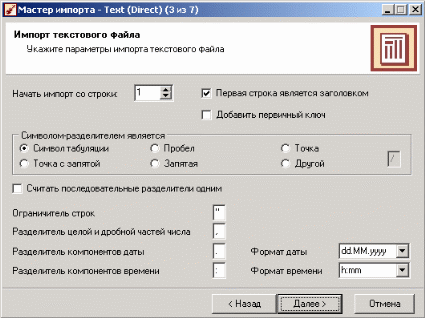 В данном случае параметры по умолчанию на этой странице мастера установлены правильно, а именно: начать импорт с первой строки, первая строка является заголовком, разделителем между столбцами является знак табуляции, разделителем целой и дробной частей является запятая. Далее перейдем к настройке свойств полей. На этом шаге мастера предоставляется возможность настроить имя, название (метку), размер, тип данных, вид данных и назначение. Некоторые свойства (например, тип данных) можно задавать для выделенного набора столбцов. Вид данных определяет – конечный ли это набор (дискретные) или бесконечный (непрерывные). Назначение столбцов определяет характер их использования в алгоритмах обработки (при импорте можно оставить значение по умолчанию). 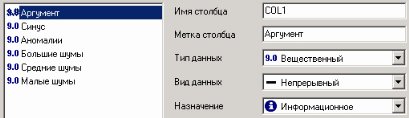 Для правильного импорта данных необходимо изменить тип данных у первых трех столбцов («АРГУМЕНТ», «СИНУС», «АНОМАЛИИ»). Тип данных по умолчанию неверный, поскольку программа определяет его, основываясь на значениях первой строки данных. В данном случае там находятся нули – целые числа. Поэтому программа определила, что столбец содержит целочисленные значения. Выделим их с помощью мыши и укажем им тип данных – «Вещественный». Далее осталось только выполнить импорт данных, нажав на кнопку «Пуск» на следующем шаге мастера импорта. После импорта данных на следующем шаге мастера необходимо выбрать способ отображения данных. В данном случае самым информативным является диаграмма, выберем ее.  От того, какие способы отображения будут выбраны на этом этапе, зависят последующие шаги мастера. В данном случае необходимо настроить, какие столбцы диаграммы следует отображать и как именно. 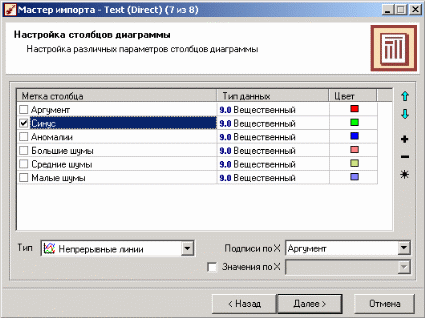 Выберем для отображения поле «СИНУС» и тип диаграммы «Линии». На последнем шаге мастера необходимо указать название ветки в дереве сценариев. Напишем в поле заголовка окна «Импорт примера для демонстрации парциальной обработки» и нажмем «Готово». На этом работа мастера импорта заканчивается. Теперь в дереве сценариев появится новый узел с необходимыми данными. В главном окне программы представлены все выбранные отображения данных этого узла. В данном случае только диаграмма. 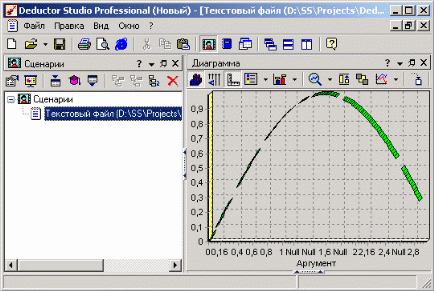 |