Лекция 01 Данные в экономике. Лекция 01. Данные в экономике 1 Понятие анализа данных 1 2 измерительные шкалы 3
 Скачать 398.64 Kb. Скачать 398.64 Kb.
|

3 СТРУКТУРИРОВАННЫЕ И НЕСТРУКТУРИРОВАННЫЕ ДАННЫЕНа каждом предприятии существует множество различных баз данных, которые пополняются от источников структурированных данных. Структурированные данные – данные, которые вводятся в базы данных в определенной форме, например, таблиц Excel, со строго определенными полями. Совокупность баз данных предприятия называется в англоязычной литературе EnterpriseDataWarehouse (EDW) – буквально «склад данных». Для красоты будем использовать английскую аббревиатуру EDW. Источники структурированных данных – это приложения, которые снимают данные различных транзакций. Например, это могут финансовые транзакции по банковским счетам, данные системы ERP, данные прикладных программ, и др.  Бизнес-аналитика BI (BusinessIntelligence) – компонент обработки данных. Это различные приложения, инструменты и утилиты, которые позволяют анализировать собранные в EDW данные и принимать решения на их основе. Это системы генерации операционных отчетов, выборочные запросы, приложения OLAP (On-LineAnalyticalProcessing), системы предикативного анализа и визуализации данных. Примечание: Предикативная или прогностическая аналитика (Predictive analytics) - это прежде всего множество методов статистики, анализа данных и теории игр, которые используются для анализа текущих и исторических данных/событий для прогноза данных/событий в будущем. Попросту говоря, менеджер должен видеть бизнес-процесс в удобной для восприятия форме, лучше всего графической и анимационной, чтобы быстро принимать оптимальные решения. Первый закон бизнеса: правильное решение – это решение принятое вовремя. Если правильное решение для вчерашнего дня принято сегодня, не факт, что оно еще остается правильным. А что делать, если источники данных – неструктурированные, разнородные, полученные из разных источников? Как будут работать с ними аналитические системы? Примеры неструктурированных данных: электронная почта, информация из соцсетей, данные XML, файлы видео-, аудио- и изображений, данные GPS, спутниковые изображения, данные с сенсоров, веб-логи, данные о перемещении мобильного абонента в хендовере, тэги RFID, документы PDF… Примечание: Хэндовер (англ.Handover)— в сотовой связипроцесс передачи сессии абонента от одной базовой станциик другой. В спутниковой связипроцесс передачи контроля над спутником от одного научно-измерительного пунктакдругомубез нарушения и потери обслуживания. Для хранения подобной информации в центрах обработки данных (ЦОД) используется распределенная файловая система Hadoop, HDFS (HadoopDistributedFileSystem). HDFS может хранить все типы данных: структурированные, неструктурированные и полуструктрированные. Примечание: Hadoop — проект фонда Apache Software Foundation, свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. HDFS (Hadoop Distributed File System) — файловая система, предназначенная для хранения файлов больших размеров, поблочно распределённых между узлами вычислительного кластера.  Приложения BigData для бизнес-аналитики – компонент не только обработки, но и с данными, как структурированными, так и нет. Они включают приложения, инструменты и утилиты, помогают анализировать большие объемы данных и принимать решения, на основе данных Hadoop и других нереляционных систем хранения. Он не включают традиционные приложения BI-аналитики, а также инструменты расширения самого Hadoop. Переход на системы BigData вовсе не означает, что традиционные EDW надо отправить в утиль. Напротив, их можно использовать совместно, чтобы использовать преимущество тех и других, а также извлекать новые ценности бизнеса за счет их синергии. Для чего это все нужно. Среди потребителей ИТ- и телеком-оборудования широко бытует мнение, что все эти эффектные иностранные слово- и буквосочетания – CloudComputing, BigData и разные прочие IMS с софтсвитчами придумываются хитрыми поставщиками оборудования, чтобы поддерживать свою маржинальность. То есть, чтобы впаривать, впаривать и впаривать новые разработки. А иначе не будет выполнен план по продажам и Билл Джобс Чемберс скажет «ай-яй-яй». И «накрылась премия в квартал». Поэтому поговорим о нужности этого всего и тенденциях. Наверное, многие еще не забыли страшный вирус гриппа H1N1. Были опасения, что он может оказаться даже сильнее испанки 1918 года, когда счет жертв шел на десятки миллионов. Хотя врачи должны были регулярно сообщать об участившихся случаях заболеваний (и они таки сообщали), однако анализ этой информации запаздывал на 1-2 недели. И сами люди обращались, как правило, через 3-5 дней после начала болезни. Т.е., меры принимались, по большому счету, задним числом. Зависимость ценности информации от времени обычно имеет вид U-образной кривой. 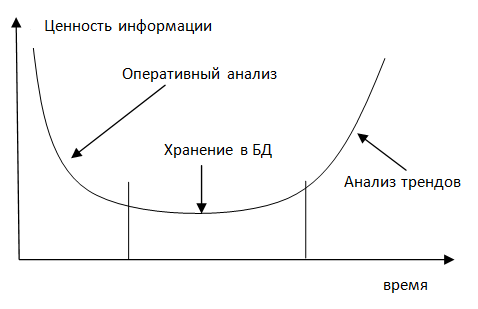 Информация наиболее ценна либо сразу после ее получения (для принятия оперативных решений), либо спустя некоторое время (для анализа тренда). Компания Google, хранящая многолетнюю историю запросов, решила проанализировать 50 миллионов наиболее популярных запросов из мест очага предыдущих эпидемий гриппа, и сравнить их с данными медицинской статистики во время этих эпидемий. Была разработана система установления корреляции между частотой определенных запросов и найдено 40-50 типичных запросов. Коэффициент корреляции достигал 97%. В 2009 году и удалось избежать серьезных последствий эпидемии H1N1, именно потому, что данные были получены сразу, а не спустя 1-2 недели, когда в поликлиниках в местах эпидемии уже было бы не протолкнуться. Это было, пожалуй, самое первое использование технологии «больших данных», хотя в то время они еще так не назывались. Хорошо известно, что цена авиабилета – вещь очень непредсказуемая, и зависящая от многих факторов. Недавно я оказался в ситуации, когда можно было купить один и тот же билет экономкласса, одной и той же авиакомпании в один и тот же город в двух возможных вариантах. На рейс, улетающий вечером через три часа, билет стоил 12 тыс. рублей, а на раннее утро завтрашнего дня – 1500 рублей. Повторю, авиакомпания – одна и даже самолет на обоих рейсах одного типа. Обычно цена на билет тем дороже, чем ближе время вылета. На цену билета влияют еще много разных факторов – как-то раз агент по бронированию объяснял мне суть этого сонма тарифов, но я так ничего и не понял. Возможны случаи, когда цена на билет, наоборот, падает, если при приближении даты вылета остается много непроданных мест, в случае проведения каких либо акций и пр. Однажды, ОренЭнциони, директор программы искусственного интеллекта в Университете штата Вашингтон, собрался лететь на свадьбу брата. Поскольку свадьбы обычно планируются заранее, то и билет он купил сразу же, задолго до вылета. Билет действительно был недорогой, гораздо дешевле, чем обычно, когда он покупал билет для срочной командировки. В полете он похвастался соседу, как дешево ему удалось купить билет. Оказалось, что у соседа билет ещё дешевле, а покупал он его позже. Мистер Энциони с досады устроил импровизированный социологический опрос прямо в салоне самолета о ценах на билеты и датах их покупки. Большинство пассажиров заплатило меньше, чем Энциони, и почти все купили билет позже него. Это было очень странно. И Энциони, как профессионал, решил заняться этой проблемой. Приобретя выборку из 12 тысяч транзакций на сайте одного из туристических агентств, он создал модель прогнозирования цен на авиабилеты. Система анализировала только цены и даты, не учитывая никаких факторов. Только «что» и «сколько», без анализа «почему». На выходе получалась прогностическая вероятность снижения или повышения цены на рейс, на основе истории изменений цен на другие рейсы. В результате ученый основал небольшую консультационную фирму Farecast (игра слов:Fare — тариф, цена; Forecast — прогноз) по прогнозированию цен на авиабилеты, на основе большой базы данных по бронированию рейсов, которая, конечно, не давала 100%-ную точность (что указывалось в пользовательском соглашении), но с достаточной степенью вероятности могла ответить на вопрос, покупать билет прямо сейчас, или подождать. Чтобы еще больше обезопаситься от судебных исков, система также выдавала «оценку доверия самой себе» примерно в таком виде: «С вероятностью 83,65% цена на билет будет ниже через три дня». Потом компанию Farecast за несколько миллиардов долларов купила Microsoft и встроила ее модель в свой поисковик Bing. (И, как это чаще всего бывает у Microsoft , об этом функционале больше ничего не слышно, т.к. этим Bing’ом мало кто пользуется, а кто пользуется, ничего об этой функции не знает). Эти два примера показывают, как с помощью анализа Больших Данных можно извлечь общественную пользу и экономическую выгоду. Что же это все-таки такое — BigData? Для «больших данных» нет строгого определения. По мере появления технологий для работы с большими объемами данных, для которых уже не хватало памяти одного компьютера и их приходилось где-то хранить, появилась возможность оперировать намного бóльшими объемами данных, чем прежде. При этом данные могли быть неструктурированными. Это дает возможность отказаться от ограничений т.н. «репрезентативных выборок», на основе которых делаются более масштабные заключения. Анализ причинности заменяется при этом анализом простых корреляций: анализируется не «почему», а «что» и «сколько». Это в корне меняет устоявшиеся подходы о том, как принимать решения и анализировать ситуацию. На фондовых рынках каждый день происходит десятки миллиардов транзакций, из них около двух третей торгов решаются с помощью компьютерных алгоритмов на основе математических моделей с использованием огромных объемов данных. Еще в 2000 году количество оцифрованной информации, составляло лишь 25% общего количества информации в мире. К настоящему времени количество хранимой информации в мире составляет величину порядка зетабайт, из которых на нецифровую информацию приходится менее 2%. По данным историков, с 1453 по 1503 год (за 50 лет) напечатано около 8 миллионов книг. Это больше всех рукописных книг, написанных писцами с Рождества Христова. Другими словами, потребовалось 50 лет, чтобы приблизительно вдвое увеличить информационный фонд. Сегодня это происходит каждые три дня. Чтобы понять ценность «больших данных» и механизм их работы, приведем такой простой пример. До изобретения фотографии, для того, чтобы нарисовать портрет человека, требовалось от нескольких часов до нескольких дней или даже недель. При этом художник делал определенное количество мазков или штрихов, число которых (для достижения «потретного сходства») можно измерить сотнями и тысячами. При этом важно было КАК рисовать, как класть краски, как штриховать и пр. С изобретением фотографии, число «зерен» в аналоговой фотографии, или число «пикселов» в цифровой изменилось на несколько порядков, и то КАК их расположить нам неважно – за нас это делает фотоаппарат. Однако результат по большому счету один – изображение человека. Но есть и различия. В рукописном портрете точность сходства весьма относительна и зависит от «видения» художника, неизбежны искажения пропорций, добавление оттенков и деталей, которых в «оригинале», т.е. в человеческом лице, не было. Фотография точно и скрупулезно передает «ЧТО», оставляя «КАК» на заднем плане. С некоторой аллегорией можно сказать, что фотография – это BigData для рукописного портрета. А теперь будем фиксировать каждое движение человека через строго определенные и достаточно малые интервалы времени. Получится кинофильм. Кинофильм – это «большие данные» по отношению к фотографии. Увеличили количество данных, соответствующим образом их обработали – получили новое качество – движущееся изображение. Изменяя количество, добавляя алгоритм обработки, мы получаем новое качество. Теперь уже и сами видео-изображения служат пищей для компьютерных систем BigData. При увеличении масштаба обрабатываемых данных появляются новые возможности, недоступные при обработке данных меньших объемов. Google прогнозирует эпидемии гриппа не хуже, и гораздо быстрее, чем официальная медицинская статистика. Для этого нужно произвести тщательный анализ сотен миллиардов исходных данных, в результате чего она дает ответ намного быстрее, чем официальные источники. Ну, и кратко о еще двух аспектах больших данных. Точность. Системы BigData могут анализировать огромное массивы данных, а в некоторых случаях — все данные, а НЕ их выборки. Используя все данные, мы получаем более точный результат и можем увидеть нюансы, недоступные при ограничении выборочного анализа. Однако, при этом приходится довольствоваться общим представлением, а не пониманием явления вплоть до мельчайших деталей. Однако, неточности на микро-уровне позволяют при большом количестве данных позволяют делать открытия на макро-уровне. Причинность. Мы привыкли во всем искать причины. На этом, собственно, и основан научный анализ. В мире больших данных причинность не так важна. Важнее – корреляции между данными, которые могут дать необходимые знания. Корреляции не могут дать ответ на вопрос «почему», но хорошо прогнозирует «что» произойдет, в случае обнаружения тех или иных корреляций. И чаще всего именно это и требуется. |