тест по распределенкам. Лекция 01. Основные принципы построения распределенных информационных систем Скворцов С. Е. 15 января 2019
 Скачать 1.13 Mb. Скачать 1.13 Mb.
|

Лекция № 01. Основные принципы построения распределенных информационных системСкворцов С.Е. 15 января 2019 Просмотров: 232 Empty Такая отличительная особенность баз данных, как многоцелевое параллельное использование данных, предопределяет наличие средств, обеспечивающих практически одновременный и независимый доступ к одним и тем же данным. Причем сама база данных может быть размещена как на одном, так и на нескольких компьютерах. Общая тенденция развития технологий обработки данных позволяет в настоящее время выделить два класса распределенной обработки данных: системы распределенной обработки данных и системы распределенных баз данных. 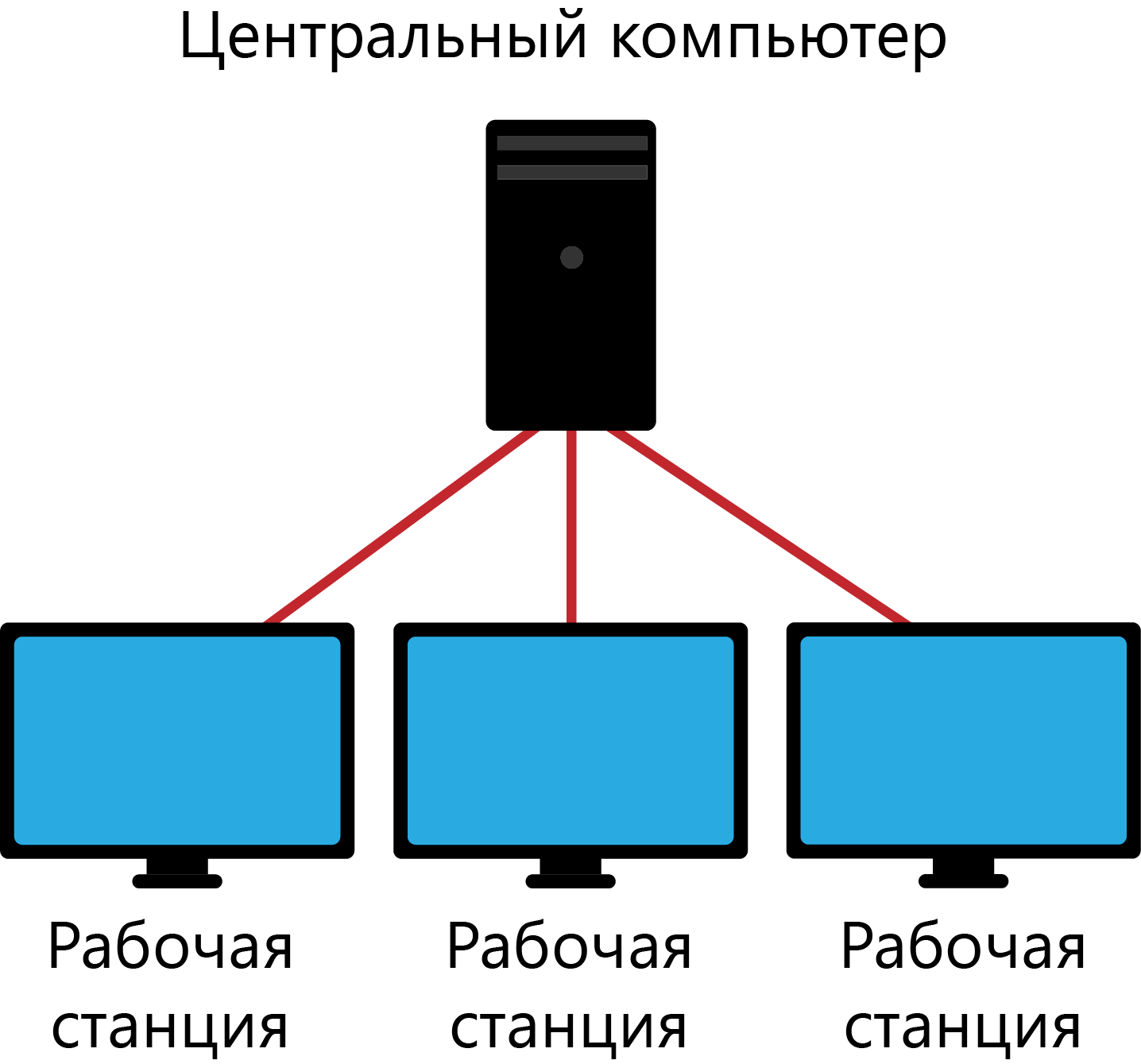 Системы распределенной обработки данных в основном отражают структуру и свойства многопользовательских операционных систем с базой данных, размещенной на центральном компьютере (мэйнфрейм, сервер). Еще до недавнего времени это был единственно возможный вариант вычислительной среды для реализации больших баз данных. Клиентские места могут реализовываться в виде терминалов или мини-ЭВМ, обеспечивающих в основном ввод-вывод данных и не обладающими собственными вычислительными ресурсами (хотя не исключено и использование обычных ПК)Развитием данного направления стоит считать технологию «Клиент-Сервер», позволяющую реализовать различные модели обработки информации в АИС. Развитие сетевых технологий в сочетании с широким распространением персональных ЭВМ и внедрениям стандартов открытых систем привело к появлению систем баз данных, размещенных в сети разнотипных компьютеров. Такие системы распределенных баз данных обеспечивают обработку распределенных запросов, когда при обработке одного запроса используются ресурсы базы, размещенные в различных узлах сети. Узлы системы взаимодействую между собой так, что база данных любого узла будет доступна пользователю, как если бы она была локальной. 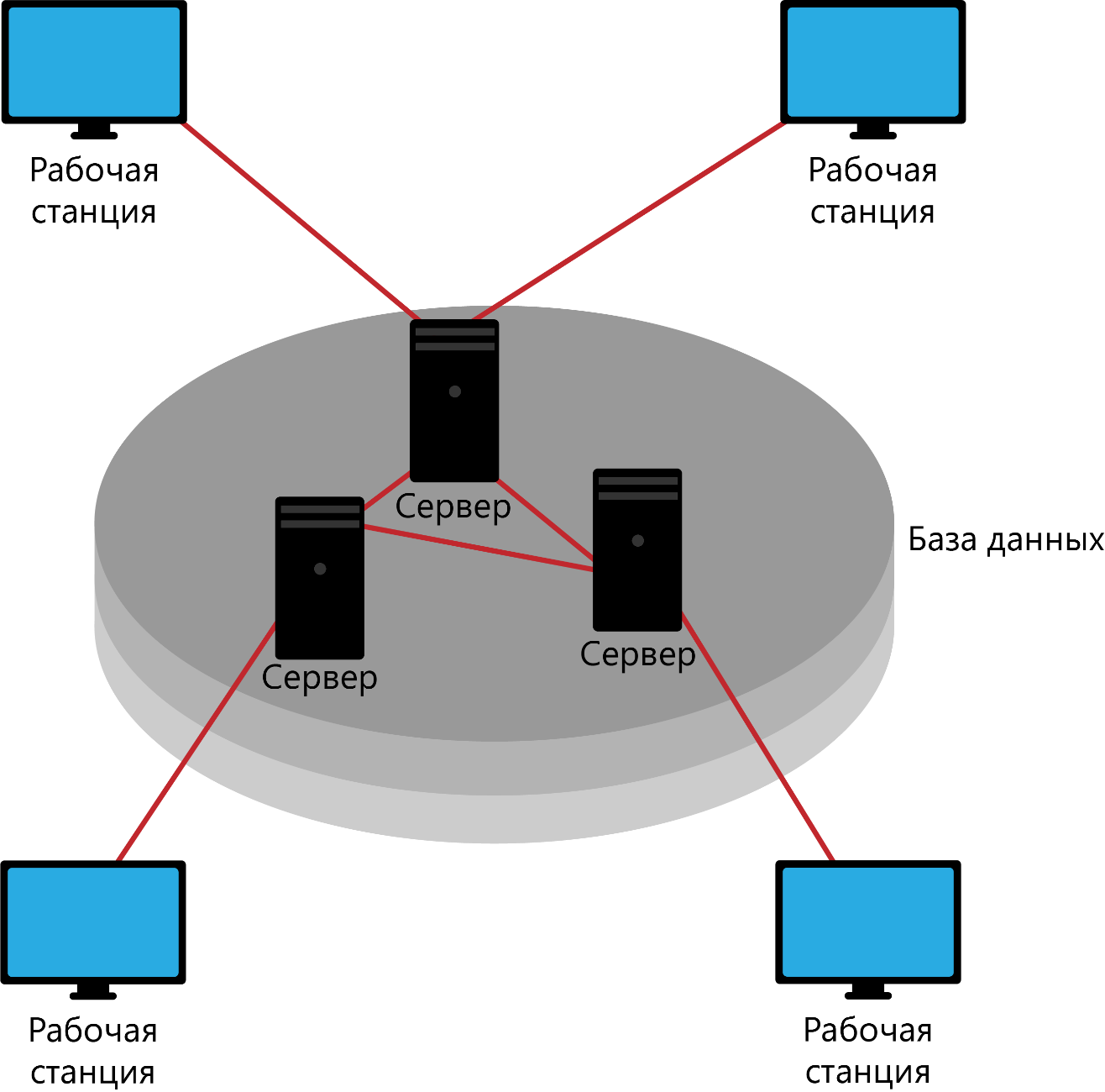 В обоих случаях программы, обеспечивающие обработку данных, могут быть организованы таким образом, чтобы обеспечить более эффективное использование вычислительных ресурсов за счет разделения функций обработки между центральным процессором сервера БД и клиентскими машинами (1 вариант), либо за счет разделения функций обработки между процессорами узлов СУБД и клиентским машинами (второй вариант). Для типового приложения обработки данных можно выделить следующие группы функций: Presentation Logic Business Logic Database Logic Управление данными и другими ресурсами БД, реализуемое внутренними средствами СУБД Управление процессами обработки: связывание и синхронизация процессов обработки данных разного уровня. Выделяют следующие, сформулированные ведущими поставщиками СУБД, свойства «идеальной» системы управления распределенными базами данных: прозрачность относительно расположения данных: СУБД должна представлять данные так, как если бы они хранились на локальном компьютере; гетерогенность системы: СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью (независиость от СУБД); прозрачность относительно сети: СУБД должна одинаково работать в условиях разнородных сетей; поддержка распределенных запросов: пользователь должен иметь возможность объединять данные из любых баз, даже если они размещены в разных системах; поддержка распределенных изменений: пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права, даже если эти базы размещены в различных системах; поддержка распределенных транзакций: СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность распределенной БД даже при возникновении отказов в отдельных системах или в сети; безопасность: СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа; универсальность доступа: СУБД должна обеспечивать единую методику доступа ко всем данным. Однако ни одна из существующих СУБД не достигает этого идеала вследствие следующих практических проблем: · низкая и несбалансированная производительность сетей передачи данных, что в распределенных транзакциях сильно снижает общую производительность обработки; · обеспечение целостности данных в распределенных транзакциях базируется на принципе «все или ничего», и требует специального протокола двухфазного завершения транзакций, что приводит к длительной блокировке изменяемых данных; · необходимо обеспечить совместимость данных стандартного типа, для хранения которых в разных системах используются разные форматы и кодировки. · Выбор схемы размещения системных каталогов. Если каталог будет храниться в одной системе с данными, то удаленный доступ будет замедлен. Если отдельно – изменения придется синхронизировать. · Необходимо обеспечить совместимость СУБД разных типов и поставщиков Указанные причины определили на практике частичность и этапность введения в СУБД тех или иных возможностей по распределенной обработке данных. В простейшем случае пользователь имеет возможность обращаться по сети к записям БД, размещенным на другом компьютере. В других случаях сама СУБД производит аутентификацию удаленного пользователя и устанавливает сетевые соединения. В общем случае режимы работы с БД можно классифицировать по следующим признакам: Многозадачность – однопользовательский или многопользовательский Правило обслуживания запросов – последовательное или параллельное Схема размещения данных – централизованная или распределенная БД |