Базы данных. Лекции БД. Лекция 5 Основные понятия информационных систем 5 История развития компьютеризации информационных процессов и систем. 5
 Скачать 1.07 Mb. Скачать 1.07 Mb.
|

3. Ранние подходы к организации БД. Системы, основанные на инвертированных списках, иерархические и сетевые СУБД.Прежде, чем перейти к детальному и последовательному изучению реляционных систем БД, остановимся коротко на ранних (дореляционных) СУБД. В этом есть смысл по трем причинам: во-первых, эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь про их предшественников; во-вторых, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем; в-третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД. Заметим, что в этой лекции мы ограничиваемся рассмотрением только общих подходов к организации трех типов ранних систем, а именно, систем, основанных на инвертированных списках, иерархических и сетевых систем управления базами данных. Начнем с некоторых наиболее общих характеристик ранних систем: Эти системы активно использовались в течение многих лет, дольше, чем используется какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами. Все ранние системы не основывались на каких-либо абстрактных моделях. Как мы упоминали, понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем. В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом. Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователя самого производить всю оптимизацию доступа к БД, без какой-либо поддержки системы. После появления реляционных систем большинство ранних систем было оснащено "реляционными" интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме. 3.1. Основные особенности систем, основанных на инвертированных спискахК числу наиболее известных и типичных представителей таких систем относятся Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на использование на машинах основного класса фирмы IBM, и Adabas компании Software AG. Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам). Кстати, когда мы будем рассматривать внутренние интерфейсы реляционных СУБД, вы увидите, что они очень близки к пользовательским интерфейсам систем, основанных на инвертированных списках. 3.1.1. Структуры данныхБаза данных, организованная с помощью инвертированных списков, похожа на реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям. При этом: Строки таблиц упорядочены системой в некоторой физической последовательности. Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB). Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям. 3.1.2.Манипулирование даннымиПоддерживаются два класса операторов: Операторы, устанавливающие адрес записи, среди которых: прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа); операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа. . б. Операторы над адресуемыми записями Типичный набор операторов: LOCATE FIRST - найти первую запись таблицы T в физическом порядке; возвращает адрес записи; LOCATE FIRST WITH SEARCH KEY EQUAL - найти первую запись таблицы T с заданным значением ключа поиска K; возвращает адрес записи; LOCATE NEXT - найти первую запись, следующую за записью с заданным адресом в заданном пути доступа; возвращает адрес записи; LOCATE NEXT WITH SEARCH KEY EQUAL - найти cледующую запись таблицы T в порядке пути поиска с заданным значением K; должно быть соответствие между используемым способом сканирования и ключом K; возвращает адрес записи; LOCATE FIRST WITH SEARCH KEY GREATER - найти первую запись таблицы T в порядке ключа поиска K cо значением ключевого поля, большим заданного значения K; возвращает адрес записи; RETRIVE - выбрать запись с указанным адресом; UPDATE - обновить запись с указанным адресом; DELETE - удалить запись с указанным адресом; STORE - включить запись в указанную таблицу; операция генерирует адрес записи. 3.1.3.Ограничения целостностиОбщие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу. 3.2. Иерархические системыТипичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом как на новую технологию БД, так и на новую технику. 3.2.1. Иерархические структуры данныхИерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи. Пример типа дерева (схемы иерархической БД): 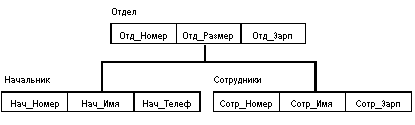 Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники - потомки Отдел. Между типами записи поддерживаются связи. База данных с такой схемой могла бы выглядеть следующим образом (мы показываем один экземпляр дерева): 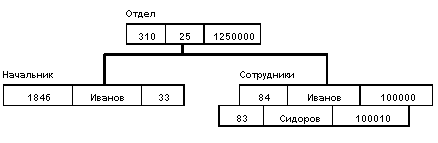 Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо. В IMS использовалась оригинальная и нестандартная терминология: "сегмент" вместо "запись", а под "записью БД" понималось все дерево сегментов. 3.2.2. Манипулирование даннымиПримерами типичных операторов манипулирования иерархически организованными данными могут быть следующие: Найти указанное дерево БД (например, отдел 310); Перейти от одного дерева к другому; Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику); Перейти от одной записи к другой в порядке обхода иерархии; Вставить новую запись в указанную позицию; Удалить текущую запись. 3.2.3. Ограничения целостностиАвтоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается . В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть иерархия |