Базы данных. Лекции БД. Лекция 5 Основные понятия информационных систем 5 История развития компьютеризации информационных процессов и систем. 5
 Скачать 1.07 Mb. Скачать 1.07 Mb.
|

Лекция 3.4.Реляционная модель данныхРеляционная модель в настоящее время доминирует на рынке баз данных. Основу этой модели составляет набор взаимосвязанных таблиц, в которых хранятся данные. Основные теоретические идеи реляционной модели были изложены в работах по теории отношений американского логика Чарльза Содерса Пирса (1839—1914) и немецкого логика Эрнста Шредера (1841 —1902), а также американского математика Эдгара Кодда. В работах Пирса и Шредера было доказано, что множество отношений замкнуто относительно некоторых специальных операций, совместно образующих абстрактную алгебру. В дальнейшем это важнейшее свойство отношений было использовано в реляционной модели для разработки языка манипулирования данными. В 1970 году появилась статья Эдгара Кодда о представлении данных, организованных в виде двумерных таблиц, называемых отношениями (Соdd Е. F., "A relational model for large shared data banks", Comm. ACM, 13:6, рр. 377—387). В этой работе впервые введены основные понятия и ограничения реляционной модели как основы хранения данных, а также показана возможность обработки данных с помощью традиционных операций над множествами и специальных введенных реляционных операций. В ней сказано, что «реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т. е. без потребности введения какой-либо дополнительной структуры для целей машинного представления». Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского rеlаtion — «отношение»). Реляционная модель является удобной и наиболее привычной формой представления данных в виде таблицы (применительно к базам данных понятия «реляционная БД» и «табличная БД» по существу являются синонимами). В отличие от иерархической и сетевой модели такой способ представления: понятен пользователю-непрограммисту; позволяет легко изменять схему - присоединять новые элементы данных и записи без изменения соответствующих подсхем; обеспечивает необходимую гибкость при обработке непредвиденных запросов. К тому же любая сетевая или иерархическая схема может быть представлена двумерными отношениями. Одним из основных преимуществ реляционной модели является ее однородность. Все данные рассматриваются как хранимые в таблицах, в которых каждая строка имеет один и тот же формат. Каждая строка в таблице представляет некоторый объект реального мира или соотношение между объектами. 4.1.Основные понятия реляционной модели данных
Таблица 4.1. Элементы реляционной модели. 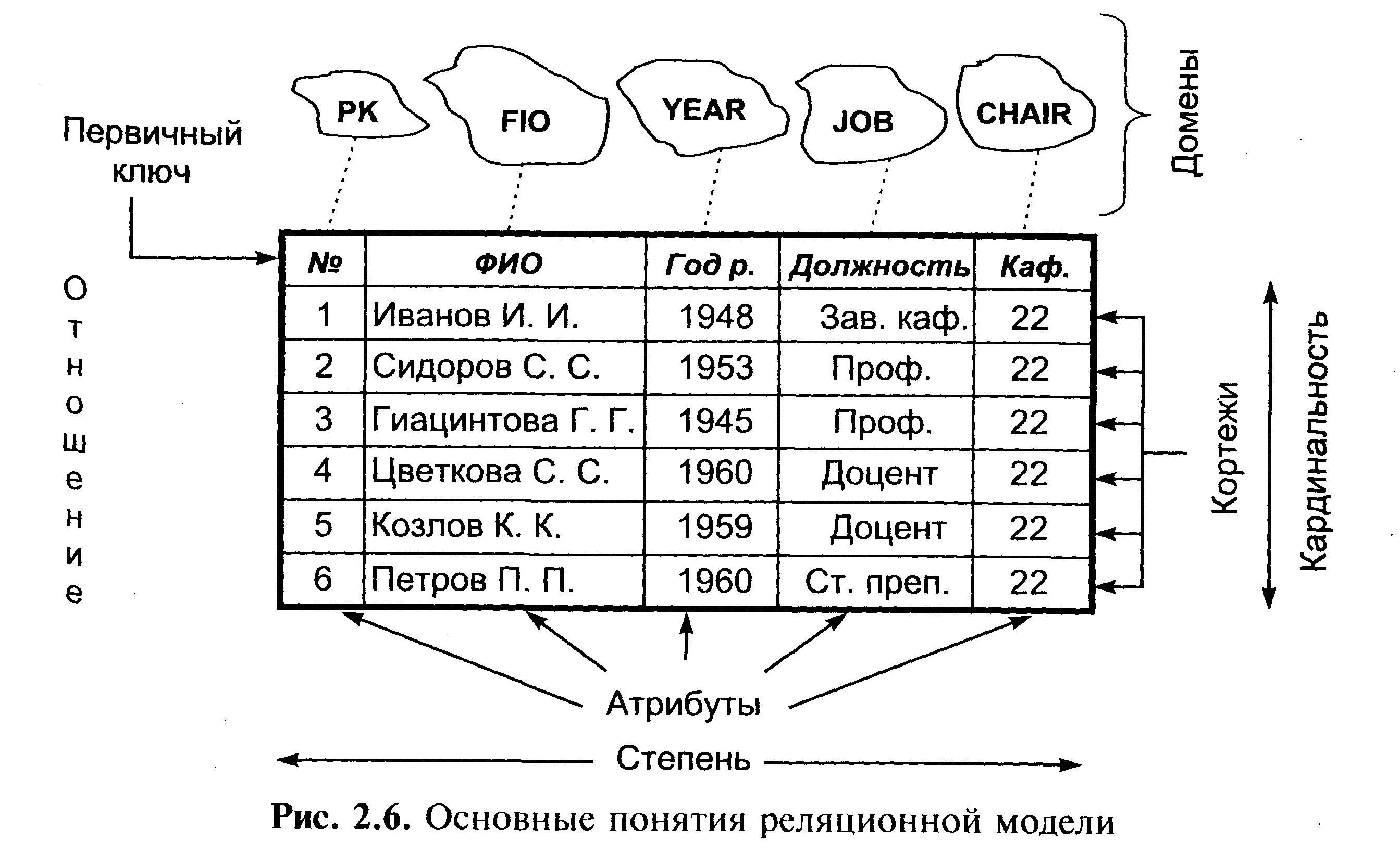 4.2. Концепция реляционной модели. Правила Кодда.В целом концепция реляционной модели определяется следующими двенадцатью правилами Кодда : /. Правило информации. Вся информация в базе данных должна быть представлена исключительно на логическом уровне и только одним способом — в виде значений, содержащихся в таблицах. 2. Правило гарантированного доступа. Логический доступ ко всем и каждому элементу данных (атомарному значению) в реляционной базе данных должен обеспечиваться путем использования комбинации имени таблицы, первичного ключа и имени столбца. Правило 2 указывает на роль первичных ключей при поиске информации в базе данных. Имя таблицы позволяет найти требуемую таблицу, имя столбца — требуемый столбец, а первичный ключ — строку, содержащую искомый элемент данных. 3. Правило поддержки недействительных значений. В реляционной базе данных должна быть реализована поддержка недействительных значений, которые отличаются от строки символов нулевой длины, строки пробельных символов, от нуля или любого другого числа и используются для представления отсутствующих данных независимо от типа этих данных. Правило 3 требует, чтобы отсутствующие данные можно было представить с помощью недействительных (пустых) значений (NULL). 4. Правило динамического каталога, основанного на реляционной модели. Описание базы данных на логическом уровне должно быть представлено в том же виде, что и основные данные, чтобы пользователи, обладающие соответствующими правами, могли работать с ним с помощью того же реляционного языка, который они применяют для работы с основными данными. Правило 4 гласит, что реляционная база данных должна сама себя описывать. Другими словами, база данных должна содержать набор системных таблиц, описывающих структуру самой базы данных. 5. Правило исчерпывающего подъязыка данных. Реляционная система может поддерживать различные языки и режимы взаимодействия с пользователем (например, режим вопросов и ответов). Однако должен существовать по крайней мере один язык, операторы которого можно представить в виде строк символов в соответствии с некоторым четко определенным синтаксисом и который в полной мере поддерживает определение данных; определение представлений; обработку данных (интерактивную и программную); условия целостности; идентификацию прав доступа; границы транзакций (начало, завершение и отмена). Правило 5 требует, чтобы СУБД использовала язык реляционной базы данных, например SQL. Такой язык должен поддерживать все основные функции СУБД: создание базы данных, чтение и ввод данных, реализацию защиты базы данных и т. д. 6. Правило обновления представлении. Все представления, которые теоретически можно обновить, должны быть доступны для обновления. Правило 6 касается представлений, которые являются виртуальными таблицами, позволяющими показывать различным пользователям различные фрагменты структуры базы данных. Это одно из правил, которое сложнее всего реализовать на практике. 7. Правило добавления, обновления и удаления. Возможность работать с отношением как с одним операндом должна существовать не только при чтении данных, но и при добавлении, обновлении и удалении данных. Правило 7 акцентирует внимание на том, что базы данных по своей природе ориентированы на множества. Оно требует, чтобы операции добавления, удаления и обновления можно было выполнять над множествами строк. Это правило предназначено для того, чтобы запретить реализации, в которых поддерживаются только операции над одной строкой. 8. Правило независимости физических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при любых изменениях способов хранения данных или методов доступа к ним. 9. Правило независимости логических данных. Прикладные программы и утилиты для работы с данными должны на логичсском уровне оставаться нетронутыми при внесении в базовые таблицы любых изменений, которые теоретически позволяют сохранить нетронутыми содержащиеся в этих таблицах данные Правила 8 и 9 означают отделение пользователя и прикладной программы от низкоуровневой реализации базы данных. Они утверждают, что конкретные способы реализации хранения или доступа, используемые в СУБД, и даже изменения структуры таблиц базы данных не должны влиять на возможность пользователя работать с данными. 10. Правило независимости условий целостности. Должна существовать возможность определять условия целостности, специфические для конкретной реляционной базы данных, в подъязыке реляционной базы данных и хранить их в каталоге, а не в прикладной программе. Правило 10 гласит, что язык базы данных должен поддерживать ограничительные условия, налагаемые на вводимые данные и действия, которые могут быть выполнены над данными. //. Правило независимости распространения. Реляционная СУБД не должна зависеть от потребностей конкретного клиента. Правило 11 гласит, что язык базы данных должен обеспечивать возможность работы с распределенными данными, расположенными на других компьютерных системах. 12. Правило единственности. Если в реляционной системе есть низкоуровневый язык (обрабатывающий одну запись один раз), то должна отсутствовать возможность использования : его для того, чтобы обойти правила и условия целостности, выраженные на реляционном языке высокого уровня (обрабатывающем несколько записей за один раз). Правило 12 предотвращает использование других возможностей для работы с базой данных помимо языка базы данных, поскольку это может нарушить ее целостность. 4.3. Составные части реляционной модели.Согласно трактовки Кристофера Дейта в реляционной модели выделяются следующие составные части: структурная ; целостностная; манипуляционная. В структурной части модели определяется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение. В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. правила целостности сущностей (отношений); правила ссылочной целостности. В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД - реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств, а второй - на классическом логическом аппарате исчисления предикатов первого порядка. 4.3.1.Структура данных реляционной моделиСтруктура данных предполагает представление предметной области рассматриваемой задачи в виде набора взаимосвязанных отношений. При создании информационной системы совокупность отношений позволяет хранить данные об объектах предметной области и моделировать связи между ними. В каждой связи одно отношение может выступать как основное (базовое), а другое отношение выступает в роли подчиненного (производного). Таким образом, один кортеж основного отношения может быть связан с несколькими кортежами подчиненного отношения. Для поддержки этих связей оба отношения должны содержать наборы атрибутов, по которым они связаны. В основном отношении это первичный ключ отношения, который однозначно определяет кортеж основного отношения. В подчиненном отношении для моделирования связи должен присутствовать набор атрибутов, соответствующий первичному ключу основного отношения. Однако здесь этот набор атрибутов уже является вторичным ключом или внешним ключом, т. е. он определяет множество кортежей отношения, которые связаны с единственным кортежем основного отношения. Множество взаимосвязанных друг с другом таблиц образуют схему базы данных. Отношение Rпредставляет собой двумерную таблицу, содержащую некоторые данные. Математически N-арное отношение D — это множество декартова произведения где Домен подмножество значений некоторого типа данных, имеющих определенный смысл. Домен характеризуется следующими свойствами: имеет уникальное имя (в пределах базы данных); определен на некотором простом типе данных или на другом домене; может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для этого домена; Пример: вес, количество и т.п. Основное значение доменов состоит в том, что они ограничивают сравнения: нельзя сравнивать значения из различных доменов, даже если они имеют одинаковый тип данных. Атрибут отношения представляет собой пару вида <Имя_атрибута : Имя_домена> (либо Отношение R, определенное на множестве доменов, содержит две части: заголовок и тело. Заголовок отношения— это фиксированное количество атрибутов отношения, описывающее декартово произведение доменов, на котором задано отношение: (< A1 :D1>,< A2 : D2>, ... ,< An : Dn> ) Заголовок статичен: он не меняется во время работы с базой данных. Если в отношении изменены, добавлены или удалены атрибуты, то в результате получается уже другое отношение (даже если его имя осталось прежним). Тело отношения содержит множество кортежей отношения. Каждый кортеж отношения представляет собой множество Пар вида <Имя_атрибута : Значение_атрибута> R(< А1 : Val1>,< А2: Val2 >,...,< An : Vаln>) таких, что значение Vаliатрибута Ai, принадлежит домену Di. Тело отношения представляет собой набор кортежей, т. е. подмножество декартового произведения доменов. Таким образом, тело отношения собственно и является отношением в математическом смысле слова. Тело отношения может изменяться во время работы с базой данных, т. к. кортежи с течением времени могут изменяться, добавляться и удаляться. Отношение обычно записывается в виде: R(< A1 :D1>,< A2 : D2>, ... ,< An : Dn> ), либо в сокращенных вариантах: R(А1,А2, •••, Аn)или R. Число атрибутов в отношении называется степенью (либо арностью] отношения, а множество кортежей отношения — мощностью отношения. Экземпляр отношения — это множество кортежей для данного отношения. Экземпляр может изменяться с течением времени. Обычная база данных в текущий момент времени работает только с одной версией отношения. Такой экземпляр отношения называется текущим. Схема отношения представляет собой набор заголовков отношения, входящих в базу данных, т. е. перечень имен атрибутов данного отношения с указанием домена, к которому они относятся: SR=(А1,А2, •••, Аn), Если атрибуты принимают значения из одного и того же домена, то они называются сравнимыми, где — множество допустимых операций сравнений, заданных для данного домена. Например, если домен содержит числовые данные, то для него допустимы все операции сравнения: = {=,<>,>=,<=,<,>}. Однако и для доменов, содержащих символьные данные, могут быть заданы не только операции сравнения по равенству и неравенству значений. Если для данного домена задано лексикографическое упорядочение, то он также имеет полное множество операций сравнения. Схемы двух отношений называются эквивалентными, если они имеют одинаковую степень, и возможно такое упорядочение имен атрибутов в схемах, что на одинаковых местах будут находиться сравнимые атрибуты, т. е. атрибуты, принимающие значения из одного домена: Для эквивалентных соотношений выполняются следующие условия. наличие одинакового количества атрибутов; наличие атрибутов с одинаковыми наименованиями; содержание данных из одних и тех же доменов для атрибутов с одинаковыми наименованиями; наличие в отношениях одинаковых строк с учетом того, что порядок атрибутов может различаться; отношения такого рода есть различные изображения одного и того же отношения. Свойства отношений непосредственно следуют из приведенного ранее определения отношения. В этих свойствах в основном и состоят различия между отношениями реляционной модели данных и простыми таблицами. Уникальность имени отношения. Имя одного отношения должно отличаться от имен других отношений. Уникальность кортежей. В отношении нет одинаковых кортежей. Действительно, тело отношения есть множество кортежей и, как всякое множество, не может содержать неразличимые элементы. Таблицы в отличие от отношений могут содержать одинаковые строки. Каждая ячейка отношения содержит только атомарное (неделимое) значение. Неупорядоченность кортежей. Кортежи не упорядочены (сверху вниз), т. к. тело отношения есть множество, а множество не упорядочено (для сравнения — строки в таблицах упорядочены). Одно и то же отношение может быть изображено разными таблицами, в которых строки идут в различном порядке. Неупорядоченность атрибутов. Атрибуты не упорядочены (слева направо). Уникальность имени атрибута в пределах отношения. Каждый атрибут имеет уникальное имя в пределах отношения, значит, порядок атрибутов не имеет значения (для сравнения — столбцы в таблице упорядочены). Это свойство несколько отличает отношение от математического определения отношения. Одно и то же отношение может быть изображено разными таблицами, в которых столбцы идут в различном порядке. Атомарность значений атрибутов. Все значения атрибутов атомарны. Это следует из того, что лежащие в их основе атрибуты имеют атомарные значения, т. е. с каждым атрибутом связана какая-то область значений (отдельный элементарный тип), значения атрибутов берутся из одного и того же домена. Схема и кортежи отношения— множества, а не списки, поэтому порядок их представления не имеет значения. Для сравнения-- в ячейки таблицы можно поместить различную информацию: массивы, структуры, другие таблицы и т. д. Следует отметить, что реляционная модель представляет собой базу данных в виде множества взаимосвязанных отношений, которые называются схемой реляционной базы данных. Связи, которые можно выделить между отношениями в базе данных, классифицируются по следующим типам. "Один-к-одному" - - один экземпляр первого отношения связан только с одним экземпляром второго отношения. Как правило, существование такого типа связи свидетельствует о том, что отношения в пределах схемы базы данных заданы некорректно. "Один-ко-многим"-- один экземпляр первого (базового) отношения связан со многими экземплярами второго (подчиненного) отношения. Данная связь является основой зависимостей между отношениями в реляционной модели Данных. "Многие-ко-многим" - многие экземпляры первого отношения связаны со многими экземплярами второго отношения. Связь такого вида практически не реализуется в реляционной среде. В силу этого она легко разрешается введением дополнительного (производного) отношения, которое является промежуточным между исходными от ношениями и соединено с ними двумя связями "один-ко-многим". 4.3.2.Реляционная целостность данныхРеляционная целостность данных рассматривается в двух аспектах ключи отношения и реляционные ограничения целостности. Первичным ключом (ключом отношения, ключевым атрибутом) называется атрибут отношения, однозначно идентифицирующий каждый из его кортежей. Ключ может быть составным (сложным), т. е. состоять из нескольких атрибутов. Каждое отношение обязательно имеет комбинацию атрибутов, которая может служить ключом. Таким образом, ее существование гарантирует то, что отношение — это множество, которое не содержит одинаковых кортежей. Во многих СУБД можно создавать отношения, не определяя ключи. Иногда отношение имеет несколько комбинаций атрибутов, каждая из которых однозначно определяет все кортежи от-ношения. Такие комбинации атрибутов — это возможные ключи отношения и любой из них можно выбрать в качестве первичного. Если выбранный первичный ключ состоит из минимально необходимого набора атрибутов, то он является не избыточным. Обычно ключи используют для: исключения дублирования значений в ключевых атрибутах (другие атрибуты в расчет не принимаются); упорядочения кортежей. Возможно упорядочение по возрастанию или убыванию значений всех ключевых атрибутов, а также смешанное упорядочение (по одним атрибутам возрастание, по другим — убывание); ускорения работы с кортежами отношения; организации связывания таблиц. Если в отношении R1 имеется не ключевой атрибут A, значения которого являются значениями ключевого атрибута B другого отношения R2 . то атрибут A отношения R1является внешним ключом. С помощью внешних ключей устанавливаются связи между отношениями. Реляционная модель накладывает на внешние ключи ограничение для обеспечения целостности данных ограничение ссылочной целостности, т. е. каждому значению внешнего ключа должны соответствовать строки в связывае-мых отношениях. Так каждый атрибут связан с некоторым доменом, для множества допустимых значений каждого атрибута отношения определяют так называемые ограничения домена. Кроме этого, для БД задаются два правила целостности, которые называются реляционными ограничениями целостности — ограничениями для всех допустимых состояний БД: правила целостности сущностей (отношений); правила ссылочной целостности. Определитель NULL указывает на то, что значение атрибута в данный момент неизвестно или неприемлемо для данного кортежа, NULL не входит в область определения некоторого кортежа либо никакое значение еще не задано. Ключевое слово NULL представляет собой способ обработки неполных или необычных данных, NULL ни в коем случае нельзя отождествлять как нулевое численное значение или заполненную пробелами текстовую строку (нули и пробелы — это некоторые значения; NULL — это отсутствие значения). Целостность отношений — в базовом (основном) отношении ни один атрибут первичного ключа не может содержать отсутствующих значений, т. е. NULL значений. Ссылочная целостность — значение внешнего ключа отношения должно либо соответствовать значению первичного ключа базового отношения, либо задаваться определителем NULL. Корпоративные ограничения целостности — дополнительные правила поддержки целостности данных, определяемые пользователями или администраторами БД. 4.3.3.ИндексированиеИндекс представляет собой средство ускорения поиска записей в таблице, а также других операций, использующих поиск: извлечение, модификацию, сортировку и т. д. Таблицу, для которой используют индекс, называют индексированной. Индекс содержит отсортированную по колонке или нескольким колонкам информацию и указывает на строки, в которых хранится конкретное значение колонки. Индекс выполняет роль оглавления таблиц, просмотр которого предшествует обращению к записям таблицы. В некоторых системах индексы хранятся в индексных файлах отдельно от табличных. Решение проблемы организации физического доступа к информации зависит в основном от следующих факторов: вида содержимого в поле ключа записей индексного файла; типа используемых ссылок (указателей) на запись основной таблицы; метода поиска нужных записей. Индексный файл— это хранимый файл особого типа, в котором каждая запись состоит из двух значений: данное и RID-указатель. На практике чаще всего используются два метода поиска: последовательный и бинарный (основан на делении интервала поиска пополам). Поиск необходимых записей при индексации может происходить по одноуровневой либо двухуровневой схеме индексации. При одноуровневой схеме в индексном файле хранятся короткие записи, имеющие два поля: поле содержимого старшего ключа (хеш-кода ключа) адресуемого блока и поле адреса начала этого блока (рис. 2.2.). 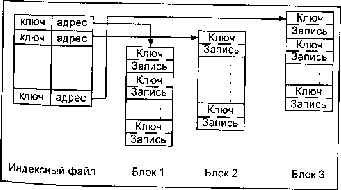 Рис. 4.2. Одноуровневая схема индексации В каждом блоке записи располагаются в порядке возрастания значения ключа (или свертки). Старшим ключом каждого блока является ключ его последней записи. Если в индексном файле хранятся хеш-коды ключевых полей индексированной таблицы, то алгоритм поиска нужной записи включает три этапа. 1 Образование свертки значения ключевого поля искомой записи. 2 Поиск в индексном файле записи о блоке, значение первого поля которого больше полученной свертки (это гарантирует нахождение искомой свертки в данном блоке). 3 Последовательный просмотр записей блока до совпадении сверток искомой записи и записи блока файла. В случае коллизий сверток(нескольким разным ключам может соответствовать одно значение хеш-функции, т. е. один адрес) ищется запись, значение ключа которой совпадает со значением ключа искомой записи. Недостаток одноуровневой схемы — ключи (свертки) записей хранятся вместе с записями, что приводит к увеличению времени поиска записей из-за большой длины просмотра (значения данных в записях приходится пропускать). В двухуровневой схеме ключи (свертки) записей отделены от содержимого записей (рис. 2.3). В данном случае индекс основной таблицы распределен по совокупности файлов: одному файлу главного индекса и множеству файлов с блоками ключей. На практике при создании индекса для некоторой таблицы базы данных указывают поле таблицы, которое требует индексации. Ключевые поля таблицы во многих СУБД индексируются автоматически. Индексные файлы, создаваемые по ключевым полям таблицы, называются файламипервичных индексов. Индексы, создаваемые не для ключевых полей, называются вторичными (пользовательскими) индексами. Введение этих индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. Индексные файлы, создаваемые для поддержания вторичных индексов таблицы, называются файламивторичных индексов. Блок ключей-1 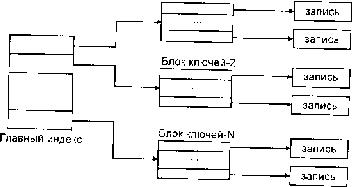 Рис. 4.3. Двухуровневая схема индексации Некоторые СУБД поддерживают кластеризованные и кластеризованные хешированные индексы. Кластеризация— помещение в один блок записей таблиц, которые с большой вероятностью будут часто подвергаться соединению. Кластеризованныйиндекс- специальная техника индексирования, при которой данные в таблице физически располагаются в индексированном порядке. Использование кластеризованного индекса значительно ускоряет выполнение запросов по индексированной колонке. Для каждой табли-цы может существовать только один кластеризованный индекс. При создании кластеризованного индекса не по первичному ключу автоматически снимается кластеризация по первичному ключу. Хеширование-— альтернативный способ хранения данных в заранее заданном порядке с целью ускорения поиска (прямой доступ). Хеширование избавляет от необходимости поддерживать и просматривать индексы. Кластеризованный хешироваииый индекс значительно ускоряет операции поиска и сортировки, но добавление и удаление строк замедляется из-за необходимости реорганизации данных для соответствия индексу. Хеширование применяется в том случае, когда необходим прямой доступ (без индексов), например при бронировании авиабилетов, мест в гостиницах, прокате машин, а также электронных денежных переводах. Однако недостатком хеширования являются необходимость нахождения соответствующей хеш-функции, необходимость выполнения операции свертки (требует определенного времени), возможные коллизии (свертка различных значений может дать одинаковый хеш-код) и промежутки между записями неопределенной про тяженности. При хешировании RID-указатель вычисляется с помощью некоторой хеш-функции и называется хеш-кодом В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (хеш-код). Длина хеш-кода всегда постоянна и имеет достаточно малую величину (например, 4 байта), а это существенно снижает время поисковых операций. Общим недостатком индексных схем является необходимость хранения индексов, к которым требуется обращаться для обнаружения записей. | ||||||||||||||||||||||||||||||||||||||||||||||||