МДК 03.01. Лекция Введение
 Скачать 1.66 Mb. Скачать 1.66 Mb.
|

Сохранение работоспособности в аварийных условияхВ понедельник в два часа ночи вам звонят и сообщают о том, что в результате разрыва водопроводной трубы прямо над вашим офисом серверы и маршрутизаторы, а также большинство рабочих станций стоят в воде. Офис открывается в 8 часов утра.Бен Смит В понедельник в два часа ночи вам звонят и сообщают о том, что в результате разрыва водопроводной трубы прямо над вашим офисом серверы и маршрутизаторы, а также большинство рабочих станций стоят в воде. Офис открывается в 8 часов утра. Что делать? В подобных ситуациях становится очевидным отличие ИТ-отделов, предусматривающих планирование действий в чрезвычайных ситуациях, от ИТ-отделов, в которых аварийные мероприятия не планируются. Для второй группы описанная выше ситуация - не просто авария, а настоящая катастрофа. Возможность полной потери данных при отсутствии программы послеаварийного восстановления ставит под угрозу деятельность организаций, особенно представителей малого и среднего бизнеса, часто не располагающих средствами для восстановления работоспособности после катастрофических событий. Во многих компаниях планирование чрезвычайных мероприятий фокусируется уже в первую очередь на ИТ. Программа сохранения непрерывности бизнес-операций и послеаварийного восстановления может стать одним из наиболее ценных вкладов отдела ИТ в успешную деятельность организации. Шесть этапов планированияВ терминологии планирования действий в аварийных ситуациях фигурируют два общих понятия: планирование сохранения непрерывности бизнеса (Business Continuity Planning, BCP) и планирование послеаварийного восстановления (Disaster Recovery Planning, DRP). Эти понятия, часто используемые как равноценные, представляют различные концепции. ВСР традиционно предусматривает планирование мероприятий, обеспечивающих сохранение деловой активности организации в чрезвычайных ситуациях. Сфера ответственности DRP, по сути, представляет подмножество ВСР и касается восстановления информации и работоспособности систем в случае аварии. Например, выход из строя жесткого диска на сервере базы данных потенциально угрожает целостности бизнеса, но не является результатом катастрофических событий. Разрыв же водопроводной трубы с затоплением серверного помещения и погружением сервера базы данных в воду представляет угрозу целостности бизнеса, рассматриваемую в рамках плана послеаварийного восстановления (DRP). Планирование мероприятий ВСР и DRP - дело непростое, и в крупных организациях этим часто занимаются специальные группы. Однако даже без детального анализа степеней риска и решения прочих сложных вопросов в рамках ВСР и DRP в крупных компаниях можно создать программу сохранения целостности бизнеса и послеаварийного восстановления, если двигаться по шести перечисленным ниже этапам. Этап 1. Определение критически важных деловых операцийПервый шаг планирования в рамках ВСР и DRP - определение критически важных деловых операций, т.е. действий, которые должны выполняться в повседневном режиме для сохранения работоспособности организации. Например, центр приема заявок клиентов на выполнение технического обслуживания должен сохранять способность принимать и фиксировать заявки. Юридическая фирма должна иметь доступ к информации о клиентах, отправлять и принимать электронную почту, пользоваться интерактивными справочниками по праву, а также отвечать на телефонные звонки. На данном этапе планирования необходимо сотрудничать с главными ответственными лицами организации в определении видов деятельности, важных для сохранения ее работоспособности. В центре планирования мероприятий в рамках ВСР находится сохранение деловой активности организации за счет восстановления этих видов деятельности. Этап 2. Составление схемы инфраструктуры информационных систем, обеспечивающих выполнение критически важных деловых операцийОт определения критически важных деловых операций переходим к определению информационных систем, обеспечивающих их выполнение. В частности, в центре приема заявок клиентов на проведение технического обслуживания возможность просмотра зарегистрированных и фиксации новых заявок зависит от работоспособности серверов базы данных, где хранятся эти записи, и приложений, обеспечивающих доступ к этим серверам. Кроме того, должна также функционировать определенная часть центральной сетевой инфраструктуры, чтобы эти критически важные деловые операции могли выполняться. Перечисленные выше информационные системы необходимо поддерживать в работоспособном состоянии за счет оперативного послеаварийного восстановления. Этап 3. Модели угроз в виде предсказуемых и вероятных событийПрактически все катастрофы и аварии, угрожающие целостности бизнеса, являются предсказуемыми с определенной степенью вероятности. Катастрофические события могут быть природными (землетрясение, наводнение) либо механическими (неисправность жесткого диска, разрыв водопроводной трубы и т. д.). Например, если служба приема заявок клиентов на техническое обслуживание расположена в Ваките (шт. Оклахома), весьма вероятно, что информационные системы центра рано или поздно окажутся на пути торнадо. Точно так же, в любой компании, использующей результаты технического прогресса, всегда вероятен отказ аппаратных средств. Определив критически важные системы, можно приступать к моделированию угроз со стороны предсказуемых и вероятных событий. Моделирование позволяет реализовать структурный подход к определению потенциальных угроз, несущих в себе максимальную опасность для целостности бизнеса, и ослаблению их негативных последствий. Составьте список возможных сценариев нарушения работоспособности критически важных информационных систем, а также событий, предшествующих реализации каждой из угроз. Например, работоспособность центра приема заявок клиентов может быть нарушена из-за недоступности базы регистрируемых заявок. Предшествующим событием может стать отказ аппаратных средств, перебой в питании либо нечто более серьезное, например разрушение информационного центра из-за торнадо. Этап 4. Разработка планов и процедур сохранения целостности бизнесаПосле составления списка критически важных деловых операций, перечисления информационных систем, обеспечивающих их выполнение, и определения возможных и вероятных событий, способных нарушить работоспособность указанных информационных систем, можно приступить к выработке превентивных мер, имеющих целью сохранение целостности бизнеса, с использованием моделей угроз. В рамках ВСР существуют четыре категории превентивных мер: отказоустойчивость и восстановление после сбоя, резервное копирование, «холодное» запасное оборудование и помещения и «горячее» запасное оборудование и помещения. Отказоустойчивость и восстановление после сбоя. Эта категория превентивных мер предполагает использование резервируемых аппаратных средств, сохраняющих работоспособность при отказе отдельных элементов. В ИТ для обеспечения отказоустойчивости наиболее широко используются массивы жестких дисков, технологии кластеризации, аккумуляторные и генераторные источники питания. Резервное копирование. Резервное копирование с использованием внутрисистемных и внесистемных средств занимает центральное место среди превентивных мер в рамках DRP. В случае утраты данных резервное копирование обеспечивает возможность восстановления и реконструкции информации по последним данным, соответствующим работоспособному состоянию систем. «Холодное» запасное оборудование и помещения. «Холодное» запасное оборудование — это автономные устройства, которые можно быстро подготовить к выполнению рабочих функций. Например, можно держать набор серверов без подключения к сети, на которых установлены операционные системы с настройками, принятыми в компании. В случае аварии можно завершить настройку конфигурации и восстановить либо скопировать данные, необходимые для возобновления работы. «Холодное» помещение вмещает автономное оборудование, которое можно использовать для возобновления работы в случае аварии на главном оборудовании. Часто «холодное» помещение представляет собой просто зал, способный вместить рабочие столы и стулья. Для большинства организаций малого и среднего бизнеса (SMB) содержание «холодных» помещений не является экономически выгодным. «Горячее» запасное оборудование и помещения. «Горячее» запасное оборудование - это устройства, готовые к немедленной работе в чрезвычайной ситуации. Например, можно непрерывно дублировать критически важную информацию с занесением в удаленную базу данных и обеспечить возможность перенаправления клиентских приложений к этим копиям данных в случае необходимости. «Горячее» оборудование позволяет очень быстро возобновлять выполнение операций. Скорость приведения «горячего» оборудования в работоспособное состояние обычно определяется временем, необходимым сотрудникам для прибытия к месту хранения запасного оборудования. «Горячее» оборудование располагает точными копиями данных в реальном времени (или почти в реальном времени) и всегда работоспособно. Содержание «горячего» запасного оборудования и помещений обходится дорого, так что этот вариант используется только в организациях, которые должны сохранять работоспособность в чрезвычайных ситуациях, например в ведомствах государственной безопасности. Этап 5. Разработка планов и процедур послеаварийного восстановленияНе все события являются предсказуемыми и вероятными. Трудно найти более удачный пример непредсказуемой катастрофы, чем атака на всемирный торговый центр 11 сентября 2001 г. Для чрезвычайных обстоятельств такого рода, а также для других серьезных катастроф, в которых возможна полная потеря данных и работоспособности главных систем, необходима разработка планов и процедур восстановления. Поскольку послеаварийное восстановление относится к стрессовым ситуациям, очень важно иметь под рукой хорошо документированные, проверенные и испытанные на практике процедуры. Убедиться в работоспособности данных, хранящихся на резервных носителях, можно в режиме имитации работы процедур восстановления. Необходимо позаботиться о средствах внесистемного хранения копий процедур, выполняемых в рамках DRP, вместе с проверенными работоспособными резервными копиями. Для большинства организаций наиболее эффективным, доступным и безопасным вариантом внесистемного хранения проверенных резервных копий и планов DRP являются депозитарные ячейки и банковские сейфы. РЕКЛАМА Этап 6. Проверка работоспособности планов сохранения целостности бизнеса и испытание на практике средств послеаварийного восстановленияСам характер обстоятельств, вынуждающих составлять планы ВСР и DRP, предполагает необходимость гарантии работоспособности планов, процедур и технологий, используемых для сохранения целостности бизнеса. Проведите планируемые и спонтанные учения для проверки состоятельности стратегий ВСР и DRP. Можно раз в месяц имитировать отказ кластерных узлов, периодически выполнять восстановление «холодных» запасных серверов либо проводить полномасштабные имитации катастрофических ситуаций с проверкой работоспособности «холодных» и «горячих» средств восстановления. Как минимум, следует выполнить восстановление критически важных данных по резервным копиям с хранящихся вне офиса носителей. Хранящиеся вне офиса носители резервных копий - последняя линия защиты от полной утраты данных. Шесть этапов защиты от катастрофыВыполняя перечисленные этапы, можно помочь предприятию создать программу BCP и DRP, которая обеспечит защиту от последствий природных, механических и обусловленных человеческим фактором катастроф. Когда сотовый телефон звонит в два часа ночи, меньше всего хочется лихорадочно изобретать пути восстановления данных, находящихся на сервере и лентах и пробывших под водой в течение 30 часов, или, что еще хуже, после физического разрушения информационного центра в результате катастрофы. Бен Смит - Специалист по безопасности в компании Microsoft. Раздел 5. Замена расходных материалов и мелкий ремонт периферийного оборудования, определение устаревшего оборудования и программных средств сетевой инфраструктуры. Лекция 27. Принципы локализации неисправностей. Локализация неисправностей - это возможность быстро изолировать сбой. Найти неисправность при поиске сбоев в сетях, - это значит сделать половину дела по ее устранению. Программа сбора статистики может сообщить, что число пакетов в сегменте вдруг многократно увеличилось, но она далеко не всегда "знает", откуда эти пакеты появляются. Поэтому некоторые пользователи, например, Натан Цурхер, специалист по локальным сетям компании MagneTek предпочитают такие продукты как LANalyzer компании Novell. Другие пользователи, среди которых Ричард Манникс, управляющий сетевыми службами компании Fuller предпочитают программу Sniffer, разработанную компанией Network General. По мере усложнения сетей все большую актуальность приобретает задача локализации неисправностей. С другой стороны, отмечает Хантингтон-Ли, такие продукты как LANalyzer приемлемы лишь в том случае, если вы располагаете достаточным временем. Вместе с тем она считает, что программы NetView и Spectrum предлагают наилучшие средства локализации неисправностей. Инструментарий сетевого управления OpenView, пожалуй, наиболее перспективен в этой области, поскольку такие производители как Maxm Systems и Boole & Babbage обеспечили совместимость своих систем с NetView, которая является компонентом программы OpenView, разработанной компанией Hewlett-Packard. Томайно считает, что эта весьма важная характеристика во всех программных продуктах представлена примерно одинаково. "Я думаю, что все программы неплохо справляются с этой задачей. Если компания не может обеспечить локализацию неисправностей в своих продуктах, она просто не выдержит конкуренции". Алгоритм поиска неисправности сети. В наше с Вами время зависимость от сетевых ресурсов (интернета, локальной сети организации) многократно возросла. В современном мире работа многих компаний частично или полностью зависит от доступности сети. Начиная от сетевого сообщения внутри компании между сотрудниками, обмена информацией и документами между фирмами и заканчивая компаниями, работа которых целиком и полностью зависит от работоспособности и качества сети (например, трейдерские компании, теряющие огромные средства от несостоявшихся online-сделок). Внутрисетевые ресурсы компаний растут и усложняются, в их построение вовлекается все больше оборудования, сервисов, связей между сетями интернет-провайдера и частными сетями, а конвергенция голосового и видеопотоков в сети передачи данных добавляет ко всему прочему еще больше сложности и, как следствие, важности вопросов стабильности, надежности и безопасности. Усложняющаяся структура сетей означает рост вероятности возникновения проблем, источник которых часто локализировать становится очень сложно. В итоге неполадки, отказы и перебои функционирования сети становятся все более крупной проблемой, которую необходимо предупреждать. Поэтому, поиск и устранение неисправностей в сети стали неотъемлемой частью гарантии успеха функционирования предприятий. Отказы в сети характеризуются определенными признаками. Это могут быть как общие проблемы (клиенты не могут получить доступ к определенным ресурсам), так и более конкретные (нарушения в таблице маршрутизации). Неисправность любого вида может быть локализована до одной или нескольких конкретных причин при использовании определенных алгоритмов и методов поиска неисправностей. Будучи идентифицированной, к каждой проблеме может быть применен ряд действий, осуществляющий решение данной неисправности. То есть, работать по принципу «от общего к частному», устраняя каждую наиболее вероятную причину неисправности от более вероятной к маловероятной, тем самым систематизировав процесс восстановления работоспособности сети и уменьшив временные затраты. Шаг 1. Анализ проблемы. Детектирование проблемы, учитывая текущие признаки и потенциальные причины, а так же, какие из причин могли повлечь за собой возникновение неисправности. Например, некоторые узлы сети не отвечают на запросы или отдельные их интерфейсы, недоступность линии связи между двумя узлами, в то время, как физически соединение присутствует, возможные неполадки в маршрутизации или функционировании отдельных устройств и т.д. Шаг 2. Сбор статистики. Опрос узлов сети на предмет получения log-файлов, диагностические команды узла сети, нарушающего общее функционирование (при условии его доступности) Шаг 3. Локализация причины Базируясь на полученных сведениях, отброс некоторых потенциальных проблем. В зависимости от полученных данных, стоит определить характер проблемы – аппаратная ли она или программная. Шаг 4. Устранение проблемы. Представляя вероятные причины неисправности, пошагово осуществлять ряд операций, ведущий к ее устранению, параллельно проверяя результат своих действий. Нужно четко понимать, какое конкретное действие приводит к правильному пути для устранения неисправности, чтобы, во-первых, всегда была возможность вернуться на шаг назад, а во-вторых, иметь представление о том, как решить подобную проблему в будущем используя уже выверенный план действий. Шаг 5. Анализ результатов. Если проблема решена, значит примененный инструментарий для ее решения был верен. Процесс завершен. Если разработанный алгоритм не принес успеха, необходимо вернуться на Шаг 3 и пересмотреть ход действий, осуществив процесс устранения заново. 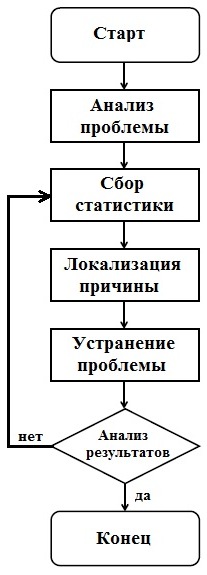 Рис 1. Алгоритм поиска и устранения неисправностей Рассмотрим подробнее основные блоки схемы, представляющие собой более разветвленные структуры. 1. Анализ проблемы. Заключает в себе несколько первичных действий, необходимых для грубого установления местоположения неисправности. Как правило, сначала определяется проблемный узел (или навскидку, если нет в распоряжении точной топологии и логического устройства сети, из которых можно быстро и четко понять, какой узел за что отвечает, является ли он простым связующим звеном или это пограничный маршрутизатор, являющий точкой соединения с интернет-провайдером или выходом на резервную линию). После того, как возможно неисправный узел сети детектирован, необходимо проверить его доступность и доступность его интерфейсов. Удаленно произведя такого рода действия, можно определенно выяснить, вышел из строя сам узел или проблема только в соединении между узлами. 2. Сбор статистики. Подразумевает собой опрос проблемного маршрутизатора (если он доступен) или соседних узлов сети на предмет получения статистики, а именно файлов журнала, фиксирующего разного рода ошибки на интерфейсах, протоколах и т.д. Оперируя такими данными, можно с большой точностью узнать время, причины и предпосылки возникновения неисправности узла сети либо напрямую из его системных журналов, либо косвенно, запрашивая информацию о состоянии соседних устройств на время нарушения функционирования сети. 3.Локализация причины Оперируя собранными данными, без труда можно отбросить некоторые варианты возникновения поломки, а вместе с ними и неверные действия на пути решения проблемы. То есть, конкретно определив, что неисправность узла аппаратная (отсутствие питания, физический выход из строя оборудования), не придется удаленно пытаться анализировать составляющие протоколы или найти проблему маршрутизации. И наоборот, заведомо установив, что устройство функционирует нормально в штатном режиме, нужно искать проблему только в настройках и программном обеспечении. Таким образом, заведомо корректная локализация причины неисправности, сокращает количество лишних манипуляций и затрачиваемое на устранение проблемы время. 4. Устранение проблемы. Установив с большой долей вероятности неисправный сетевой узел, зная характер проблемы (аппаратный или программный), а так же, располагая сведениями статистики на время нарушения функционирования сети от проблемного узла или от соседних устройств, можно разработать последовательность действий, необходимых для устранения неисправности. Далее, необходимо выбрать некую конечную задачу, на решение которой будут направлены все последующие действия. Каждый шаг предпринимаемых действий должен сопровождаться мониторингом изменений в работе налаживаемого устройства. Если преследуемые цели и фактические показатели функционирования сети не совпадают, а очередной шаг процедуры устранения неисправности ухудшил ситуацию (например, появились сбои в работе уже соседних устройств или целой ветви сети), следует пересмотреть выбор инструментария для разрешения неполадки. 5. Анализ результатов. Выполнив процедуру наладки неисправного узла, необходимо убедиться, решена ли проблема. Если функционирование сети восстановлено, значит постановка задачи и предпринятые действия были верны. Если неисправность по-прежнему не устранена, необходимо вернуться к пункту 3 и пересмотреть в корне корректность локализации причины неисправности. Процесс поиска и устранения неисправности всегда проще облегчить, имея в своем распоряжении: - наличие полной актуальной топологии сети; - логическую карту адресов устройств, подсетей и соединений; - список протоколов, запущенных внутри сети; - правильно сконфигурированные маршрутизаторы; - информация о внешних точках соединения сети с ISP; - своевременное профилактика и диагностика; Располагая таким инструментарием, неполадки будет устранить гораздо легче. А так же, документируя каждый процесс устранения неисправностей, можно облегчить последующие экстренные работы и профилактические мероприятия, зная слабые места сети. Лекция 28. Контрольно-измерительная аппаратура. (см. презентацию 79). Каждая аппаратная подсистема ПК содержит важную для управляющих приложений информацию. Очевидно, любая ошибка в обработке или хранении данных чревата серьезными последствиями даже несмотря на то, что некоторые ошибки можно исправить. Данные об общих и доступных ресурсах системы, в том числе массовой и оперативной памяти, слотах шины, каналах DMA и других элементах, должны быть известны любому работоспособному управляющему приложению. В том, что касается компьютера, контрольно-измерительная аппаратура не имеет ничего общего с видеокамерами или датчиками давления; различные процессоры и низкоуровневые программные процессы предоставляют, как правило, необходимые управляющему приложению данные, без помощи каких-либо специальных аппаратных датчиков. Большинство системных плат с Pentium Pro имеет специальные управляющие контроллеры и шину для проведения инвентаризации, обработки событий, защиты и других видов контроля. Единственное, что требуется, - это стандартизованный доступ к имеющимся данным. Производители, поддерживающие Wired for Management Baseline компании Intel, должны внедрить Systems Standard Groups Definition, определенный инженерной группой по управлению настольными системами (Desktop Management Task Force, DMTF). В состав DMTF Standard Group входят рабочие группы по дискам, клавиатуре, манипуляторам, операционным системам, физическим корпусам, процессорам, системной BIOS, системному кэшу и видео (Disks, Keyboard, Pointing Device, Operating System, Physical Container, Processor, System BIOS, System Cache и Video). Кроме того, помимо структур данных в формате Management Information Format (MIF) производи- тели должны предоставить программное обеспечение Desktop Management Interface (DMI) 2.0 Service Provider и обеспечить поддержку одного из стандартных механизмов доступа к DMI, что позволит управляющим приложениям, обменивающимся информацией по сети, собирать данные об оборудовании. В состав DMTF входят не только партнеры Intel, но и все крупнейшие производители систем - AMD, National Semiconductor, Sun Microsystems и IBM. А раз так, то проблема стандартизации оборудования, по всей вероятности, вскоре будет решена, хотя многие системы, созданные более двух лет назад, а также любые новые системы, не поддерживающие стандарт, останутся по-прежнему неуправляемыми. Для замеров уровней напряжений, токов, сопротивлений, наблюдения осциллограмм сигналов в контрольных точках, измерений параметров электрических сигналов, можно использовать обычную, стандартную КИА, с характеристиками, соответствующими измеряемым сигналам и их параметрам. Ее краткий перечень и назначения: 1) низковольтный тестер (с напряжением питания не более 1,5 В, но лучше – цифровой мультиметр). Им можно: - измерять потенциалы на выводах ИМС, определяя уровни логических 0 и 1, или высокоимпедансное состояние (“воздух”); - проверять целостность линий связи в печатных платах, без риска повреждения ИМС; - определять, часто без выпаивания, целостность p-n-переходов в полупроводниковых диодах и транзисторах; - грубо проверять исправность резисторов и конденсаторов; - измерять величины питающих напряжений и токи потребления от каналов БП; 2) обычный осциллограф (синхроскоп), к сожалению, не всегда помогает при анализе дефектов в РС, так как на SВ РС очень мало синхронно повторяющихся процессов. Осциллограф применим только для просмотра синхросигналов, сигналов интервального таймера, циклов шины, да и то только в том случае, если удается зациклить процесс обращения к порту или ОЗУ по одному и тому же адресу. Осциллограф, однако, поможет разобраться в работе схемы, имеющей дефекты типа замыкания, приводящие к монтажному ИЛИ (когда выходы двух или более ИМС объединяются замыканием в монтаже). В этом случае, если и не удается просмотреть осциллографом развертку всей последовательности импульсов, можно заметить наличие импульсов неправильной, урезанной амплитуды, но для этого все-таки нужно уметь зациклить нужный кусок программы или микропрограмму; 3) телевизионный осциллограф просто незаменим при анализе работы видеомонитора. TV-осциллограф позволяет выделить одну строку изображения, засинхронизировать ее, и увидеть на экране синхросигналы строчной развертки, бланкирующие импульсы, уравнивающие сигналы и аналоговый видеосигнал с его уровнями яркости и цветности. Это удобно в том случае, когда используются видеокарты, формирующие полный телевизионный сигнал для модуляции кинескопа и управления развертками. 4) частотомер в диагностике РС применяется редко, и только для точного определения частот задающего генератора синхросигналов и таймеров. Частотомеры обычно имеют довольно низкое входное сопротивление и сильно нагружают исследуемую схему, поэтому к ним дополнительно нужны бестоковые входные адаптеры на полевых транзисторах, или, если хватает чувствительности частотомера, использовать индуктивную петлю связи. 5) двухканальный (многоканальный) осциллограф используются для измерений фазовых характеристик сигналов, например так, как проиллюстрировано на рисунке 2.1. 6) запоминающий осциллограф содержит специальную оперативную память и позволяет зарегистрировать однократный или переходной процесс, в том числе, обнаружить помеху в зарегистрированной последовательности сигналов. Прибор очень дорог и имеет малое быстродействие, часто недостаточное для анализа быстрых процессов в РС. Емкости памяти запоминающего осциллографа часто недостаточно для регистрации длинных последовательностей. Возникают и проблемы с поиском сигнала для синхронизации (запуска регистрации) осциллографа. Но важно то, что такой осциллограф позволяет зафиксировать форму однократного исследуемого сигнала и в этой роли ему нет равных; Лекция 29. Сервисные платы и комплексы. Для облегчения диагностики неисправностей РС, промышленностью выпускаются несколько типов сервисных плат. Наиболее популярны сервисные платы: - RACER, - ROM&DIAG, - HD-tester, - AnalBus (Анализатор шины). Главное их достоинство состоит в том, что платы RACERи ROM&DIAG, имея встроенные ПЗУ с тестовыми программами, перехватывают на себя управление по прерыванию 19h и вместо загрузки MBR с диска, запускают свою собственную программу тестирования компонент РС. Анализатор шины не имеет собственного ПЗУ с программой, а использует тест-программу, запускаемую стандартным образом. В качестве тест-программы для анализатора шины можно использовать и обязательно имеющуюся в ROM BIOS РС POST-программу, которая, как известно, выполняется при каждом старте РС, или любую другую стимулирующую (тестирующую) программу. Таким образом, с помощью этих сервисных плат можно, в первом приближении, протестировать РС, который даже не выполняет загрузки ОС и, следовательно, недоступен для тестирования внешней тестирующей программой типа CheckIt, NDiags и т. п. Такое, даже предварительное, тестирование трудно переоценить. Так, если при включении, компьютер ничего не выполняет, ничего не сообщает, экран дисплея пуст, и неизвестно с чего начинать, можно, вставив сервисную плату в свободный слот расширения и включив питание компьютера, получить первичные сообщения программы сервисной платы о том, какая из подсистем или компонент РС неисправна и принять меры к "оживлению" компьютера настолько, чтобы получить возможности более углубленного его тестирования. Из отладочных комплексов наибольшее распространение имеют установки для тестового контроля (УТК) комбинационных и последовательностных схем цифровой логики, использующиеся в основном для проверки ТЭЗ ЭВМ Для профессиональной диагностики АПС типа РС и Main Frame используются отладочные комплексы типа PC-tester. Для диагностики неисправностей современных персональных компьютеров типа Pentium существуют сервисные платы, подобные RACER, HD-tester, AnalBus. Они имеют разъемы для подключения к компьютеру через шину PCI и тестируют РС современной архитектуры. Если компьютер исправен настолько, что может выполнять загрузку с дисковода CD-ROM, можно использовать специальные диагностические CD-диски с набором разных тест-программ. Некоторые из этих дисков работают под управлением MS DOS, имеют загрузочный модуль этой операционной системы и позволяют выполнять некоторые тест-программы из набора Norton Utilities. Другие диски могут иметь свою собственную операционную систему упрощенного типа для выполнения своих тест-программ. Лекция 30. Программные средства диагностики. В Интернет имеется немало общедоступных специализированных диагностических программных продуктов: Etherfind, Tcpdump (lss:os2warez@merlin.itep.ru ftp.ee.lbl.gov/tcpdump.tar.Z, для SUN или BSD 4.4; ftp.ee.lbl.gov.libpcap.tar.Z), netwatch(windom.ucar.edu), snmpman (http://www.smart.is/pub/mirror-indstate/snmp), netguard (oslo-nntp.eunet.no/pub/msdos/winsock/apps), ws_watch (bwl.bwl.th-harmstadt.de /windows/util). Программа tcpdump создана в университете Калифорнии и доступна по адресу ftp.ee.lbl.gov. Эта программа переводит интерфейс ЭВМ в режим приема всех пакетов, пересылаемых по данному сетевому сегменту. Такой режим доступен и для многих интерфейсов IBM/PC (например, популярный NE2000 Eagle, mode=6), но tcpdump на этих машинах не работает. Tcpdump написана на СИ, она отбирает и отображает на экране пакеты, посылаемые и получаемые данным интерфейсом. Критерии отбора могут варьироваться, что позволяет проанализировать выполнение различных сетевых процедур. В качестве параметров при обращении к программе могут использоваться наименования протоколов, номера портов и т.д., например, tcpdump TCP port 25. Существует довольно большое число модификаторов программы (опций). К сожалению для рядовых пользователей программа не доступна - требуются системные привилегии. Описание применения программы можно найти по указанному выше адресу, а также в [10]. Другой полезной служебной программой является sock (socket или sockio). Эта программа способна посылать TCP и UDP пакеты, она может работать в четырех режимах. Программа устанавливает канал клиент-сервер и переадресует стандартный ввод серверу, а все полученные пакеты от сервера переправляет на стандартный вывод. Пользователь должен специфицировать имя сервера или его адрес и наименование операции или номер порта, ей соответствующий. Работа в режиме диалогового сервера (опция -s). В этом режиме параметром операции является ее имя или номер порта (или комбинация IP-адреса и номера порта), например: sock -s 100. После установления связи с клиентом программа переадресовывает весь стандартный ввод клиенту, а все что посылается клиентом, отправляет на стандартный вывод. Режим клиента-отправителя (опция -i). Программа выдает в сеть заданное число раз (по умолчанию 1024) содержимое буфера с объемом в 1024 байта. Опции -n и -w позволяют изменить число и размер посылок. Режим приема и игнорирования данных из сети (опция -i и -s). |