ТОИ_КУРСОВАЯ. Методическое пособие для курсовой работы санктпетербург 2021 содержание введение 3 общие требования 3
 Скачать 3.05 Mb. Скачать 3.05 Mb.
|

|
Ф.В. Филиппов ТЕХНОЛОГИИ ОБРАБОТКИ ИНФОРМАЦИИ МЕТОДИЧЕСКОЕ ПОСОБИЕ ДЛЯ КУРСОВОЙ РАБОТЫ САНКТ-ПЕТЕРБУРГ 2021 СОДЕРЖАНИЕ ВВЕДЕНИЕ 3 ОБЩИЕ ТРЕБОВАНИЯ 3 1.Требования к оформление курсовой работы 3 2.Требования к содержанию курсовой работы 5 КРАТКИЕ СВЕДЕНИЯ 7 1.Метод PCA 7 2.Примеры использования метода PCA 9 3.Алгоритм t-SNE 13 4.Примеры использования алгоритма t-SNE 15 5.Алгоритм UMAP 19 6.Пример использования алгоритма UMAP 20 7.Графика в формате SVG 21 КОМПЛЕКТ ЗАДАНИЙ 22 Задание № 1: Понижение размерности данных 22 Задание № 2: Кластеризация данных 24 Задание № 3: Обработка графической информации 25 ПОЛЕЗНЫЕ РЕСУРСЫ 29 © Филиппов Ф.В., 2021 ВВЕДЕНИЕКурсовая работа выполняется в рамках образовательной программы «Информационные системы и технологии» («Интеллектуальные системы и технологии») и является неотъемлемой частью образовательного процесса. Выполнение курсовой работы представляет собой решение студентом, под руководством преподавателя, конкретных задач обработки информации. Цель курсовой работы – углубить знания и умения студентов, полученные в процессе теоретических и практических занятий, улучшить навыки самостоятельного поиска и изучения материала по теме курсовой работы, а также развить компетенции аналитической, исследовательской и проектной деятельности. В частности, компетенции: - ПК-1 - способность проводить исследования на всех этапах жизненного цикла программных средств; - ПК-18 - способность выполнять работы по созданию (модификации) и сопровождению ИС, автоматизирующих задачи организационного управления и бизнес-процессы; - ПК-19 - способность выполнять работы и управлять работами по созданию (модификации) и сопровождению ИС, автоматизирующих задачи организационного управления и бизнес-процессы. ОБЩИЕ ТРЕБОВАНИЯКурсовая работа должна быть выполнена на основе тщательно проработанных материалов научной и учебной литературы, собранных и обработанных эмпирических и теоретических сведений по изучаемой дисциплине. Курсовая работа должна отличаться критическим подходом к изучению литературных источников и демонстрировать умение использования студентом методов исследования в информационных технологиях, изученных в дисциплинах учебного плана соответствующего курса обучения. Материал, привлекаемый из литературных источников, должен быть переработан, органически увязан с решаемой студентом задачей. Изложение материала должно быть конкретным, насыщенным фактическими данными, анализом, расчетами, программными кодами, графиками и таблицами. Курсовая работа должна завершаться конкретными выводами и рекомендациями. Требования к оформление курсовой работыПояснительная записка курсовой работы должна содержать: - Титульный лист. - Содержание курсовой работы. - Введение. - Текстовое изложение курсовой работы (по разделам), а именно: 1. Постановка задачи. 1.1. Задание на курсовую работу. 1.2. Загрузка и подготовка исходных данных для анализа. В зависимости от типа исходных данных подготовка данных может включать удаление объектов с пропущенными значениями атрибутов, стандартизацию и нормирование, ограничение объема анализируемых векторов с помощью случайной выборки заданного количества, преобразование типов и тому подобное. 2. Основные сведения необходимые для выполнения курсовой работы. 2.1. Главные теоретические положения лежащие в основе решения поставленной задачи. 2.2. Описание используемых библиотечных функций с примерами. 3. Решение поставленной задачи. 3.1. Программный код с подробными комментариями. 3.2. Полученные результаты с выводами, пояснения полученных графических материалов. - Заключение. - Список использованных источников. Текстовое изложение разделов 1 – 3 выполняются для каждого задания курсовой работы. Введение, заключение и список используемых источников является общим для всей работы. Пояснительная записка курсовой работы выполняется на одной стороне листа формата А4, по обеим сторонам листа остаются поля размером 35 мм слева и 10 мм справа. Пояснительная записка должна быть написана 14 кеглем, используемый шрифт - Times New Roman, междустрочный интервал 1,5. Все листы пояснительной записки должны быть пронумерованы и сброшюрованы. Каждый раздел в тексте должен иметь заголовок в точном соответствии с названиями в содержании. Новый раздел можно начинать на той же странице, на которой кончился предыдущий, если на этой странице кроме заголовка поместится несколько строк текста. Таблицы, рисунки (графический и другой иллюстративный материал) необходимо размещать по ходу изложения, после соответствующей ссылки на них. Они должны иметь название и порядковый номер. Не рекомендуется переносить таблицы и рисунки с одной страницы на другую, недопустимо разрывать заголовок с таблицей и рисунком, помещая их на разных страницах. Номер формул проставляется в круглых скобках справа от формул. В пояснительной записке можно использовать только общепринятые сокращения и условные обозначения. Цитаты, цифровые и графические материалы, взятые из соответствующих источников, должны сопровождаться ссылками на них. Эти ссылки могут быть сделаны в виде сносок в нижней части страницы с указанием автора, названия работы, издательства, года издания и номера страницы, где находится данное высказывание, или с указанием в скобках сразу же после высказывания номера источника в списке литературы, если речь идет о содержании всего источника, например, [1]. Если же дается цитата, то источник приводится в скобках, как номер источника, так и номер страницы или страниц, например, [1, с.2]. Цитаты должны быть тщательно выверены и заключены в кавычки. Студент несет ответственность за точность данных, а также за объективность изложения мыслей других авторов. Общий объем курсового проекта – до 20-30 страниц машинописного текста. Курсовая работа должна быть подписана студентом. Требования к содержанию курсовой работыВо введении (1-2 страницы) обосновывается актуальность темы, определяются объект и предмет исследования, формируются цели, определяются задачи курсовой работы. Далее следует кратко раскрыть содержание отдельных разделов работы, отметить особенности применяемых методик и программных библиотек. Содержательная часть курсовой работы должна содержать постановку задачи для каждого задания, теоретический материал, программные коды с подробными комментариями и выводами по полученным результатам. Теоретическая часть является результатом работы студента над литературными источниками, отражающими отечественный и зарубежный опыт, отвечающий целям и задачам курсовой работы. Основные теоретические положения и выводы желательно иллюстрировать цифровыми данными и статистическими данными из статистических справочников, монографий, журнальных статей и других источников. В данной части работы студент должен показать умения критически подходить к рассмотрению проблемы, вытекающей из целей и задач курсовой работы, обобщать, анализировать и систематизировать собранный материал, раскрывать проблемы рассматриваемого вопроса. Следует обратить внимание на стилистику, язык изложения материалов и оформление пояснительной записки. Разделы работы должны быть взаимосвязаны. Поэтому особое внимание нужно обращать на логические переходы от одного раздела к другому. Каждый раздел должен заканчиваться выводами, позволяющими перейти к изложению материала следующего раздела. В заключении следует сделать общие выводы. После заключения необходимо привести список использованных источников (с соблюдением всех библиографических правил). КРАТКИЕ СВЕДЕНИЯВ курсовой работе необходимо выполнить три задания. Первое задание связано с изучением эффективных методов понижения размерности данных, второе – с исследованием алгоритмов визуальной классификации, а третье с освоением методики обработки графических данных в формате SVG. Настоящий раздел включает минимальный набор сведений необходимых для решения поставленных задач. Сведения касаются основных методов, которые могут быть использованы в ходе выполнения заданий курсовой работы. Метод PCAМетоды понижения размерности играют важную роль в задачах обработки данных. Они позволяют строить модели в пространствах меньшей размерности, чем исходное признаковое пространство, с минимальными потерями информации. В ряде случаев полезно понижать размерность до двух, то есть проецировать данные на плоскость. Таким образом можно изучить структуру данных, например, посмотреть, насколько разделимы классы в задачах классификации. Метод главных компонент PCA (PrincipalComponentAnalysis)— один из основных способов уменьшить размерность данных, с потерей наименьшего количества информации. В совокупности основная цель анализа главных компонентов заключается в следующем: выявить скрытый паттерн в наборе данных, уменьшить размерность данных за счет устранения шума и избыточности, определить коррелированные переменные. Метод главных компонент применяется к данным, записанным в виде матрицы X – прямоугольной таблицы чисел. Традиционно строки этой матрицы называются образцами, а столбцы – переменными (атрибутами). Цель – извлечение из этих данных нужной информации. Шум и избыточность в данных обязательно проявляют себя через корреляционные связи между переменными. Суть метода главных компонент – существенное понижение размерности данных. Исходная матрица X заменяется двумя новыми матрицами T и P (рис. 1): 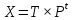 . .Матрица T называется матрицей счетов (scores) , а матрица P — матрицей нагрузок (loadings). При этом, размерность матрицы Т, число ее столбцов k, меньше, чем число переменных m (столбцов) у исходной матрицы X. 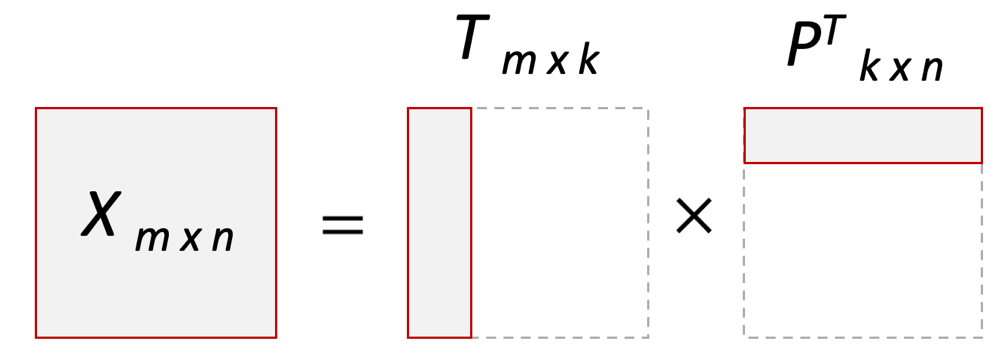 Рис. 1. Представление матрицы Х двумя матрицами Т и Р Вторая размерность – число образцов (строк) сохраняется. Если декомпозиция выполнена правильно – размерность k выбрана верно, то матрица T несет в себе практически столько же информации, сколько ее было в начале, в матрице X. При этом матрицы T и P в совокупности меньше, и, стало быть, проще, чем X. Метод главных компонент тесно связан с другим методом – разложением по сингулярным значениямSVD (Singular Value Decomposition). В этом случае исходная матрица X разлагается в произведение трех матриц (рис. 2): 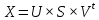 матрицы U и V – ортогональные, S - диагональная, значения на ее диагонали называются сингулярными значениями σ1 ≥ ... ≥ σR ≥ 0, которые равны квадратным корням из собственных значений λr: 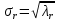 Такое разложение обладает замечательной особенностью: если в матрице S оставить только k наибольших сингулярных значений, а в матрицах U и V только соответствующие этим значениям столбцы, то произведение получившихся матриц будет наилучшим приближением исходной матрицы X к матрице меньшего ранга k. 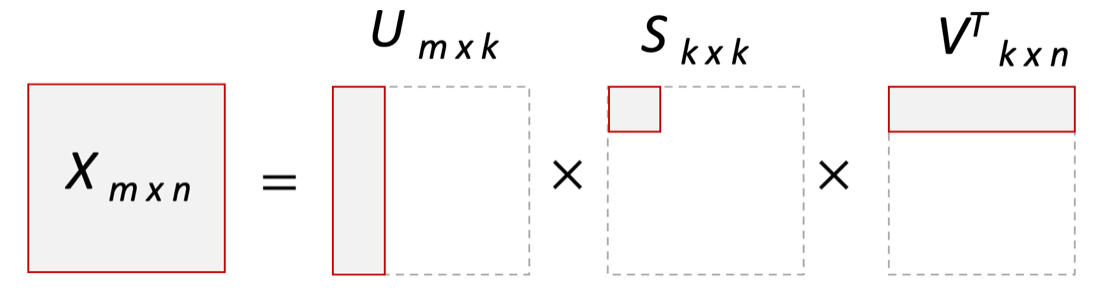 Рис. 2. Разложение матрицы Х по сингулярным значениям Связь между PCA и SVD определяется двумя простыми соотношениями: 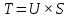 и и 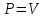 Таким образом, оба метода можно использовать для решения задач понижения размерности данных с минимальными потерями информации. При решении различных задач распознавания предполагается, что в наличии имеется некоторая выборка объектов, и для каждого объекта вычислен один и тот же набор признаков. На практике объекты могут быть представлены сложными многомерными данными, например, изображениями, набором кривых, текстом и так далее. Поэтому возникает задача извлечения из входных многомерных данных набора признаков, информативных с точки зрения дальнейшего решения задачи распознавания. Любые многомерные данные всегда можно представить в виде вектора чисел. В случае изображений достаточно развернуть матрицу пикселей в вектор. Для текстов можно вычислить количество раз, которое встречается каждое слово в тексте, и сформировать вектор чисел, длина которого определяется общим числом слов в словаре. Подобные векторы чисел имеют, как правило, большую длину, а содержащиеся в них признаки, как правило, малоинформативны. Именно поэтому рассматривается задача сокращения размерности описания данных с целью получения относительно компактного множества информативных признаков. Примеры использования метода PCAПример1. Рассмотрим пример использования метода главных компонент для понижения размерности изображения и оценим потери визуально. Возьмем небольшой jpg файл и посмотрим, какое число главных компонент будет достаточным для представления изображения в допустимом качестве. Будем вычислять главные компоненты используя сингулярное разложение матриц, которое выполняется с помощью функции svd, включенной в базовое программное обеспечение языка R. Эта функция вычисляет три матрицы S, U и Vсингулярного разложения. Их мы будем использовать как основу и выбирать из них разное число главных компонент k, формируя сжатые изображения. Качество получаемых изображений будем оценивать чисто визуально. Решение задачи выполним в среде RStudio (листинг 1). Для работы с jpg форматом воспользуемся библиотекой jpeg(строка2), позволяющей, в частности читать (функция readJPEG) и визуализировать (функция rasterImage) изображения. Для перевода цветного изображения в черно-белое используем библиотеку biOps(строка 3). В настоящее время эта библиотека исключена из репозитория CRAN и там дается только ссылка на архив, где она хранится. Прочитав архив по этой ссылке можно установить библиотеку с помощью следующей команды: install.packages(path_to_file, repos = NULL, type="source"), где path_to_file - путь к архивированному файлу. После чтения и перевода в черно-белое представление визуализируем оригинал изображения (строка 9, 10). Далее определяем размерность исходного изображения (dim(X) = 500 x 473) для дальнейшей оценки эффективности сжатия (строка 12). Наконец, находим сингулярное разложение X.svd(строка 14). Листинг 1. Использование метода главных компонент для понижения размерности  В нашем случае полученное сингулярное разложение X.svd представлено в виде списка (Largelist), состоящего из трех матриц, параметры которых можно посмотреть в закладе Environment правой верхней панелиRStudioи на рис. 4.  Рис. 4. Сингулярное разложение X.svd Как видно из рис. 4, диагональная матрица S имеет размер 473 х 473, матрица U размер 500 х 473 и матрица V размер 473 х 473. Матрицы S, U и V будем использовать как основу и выбирать из них разное число главных компонент k. Сформируем различные матрицы Xk, формирование проведем в цикле (строки 22-31 листинга 1) для числа компонент k = 5, 20, 50 и 250. Сначала сформируем усеченные матрицы Uk, Vk и Sk (строки 23-25). Затем в строке 26 выполним умножение сформированных матриц (см. рис. 2) для формирования сжатых изображений. Результатом работы этой программы будет четыре изображения, отличающихся по качеству (рис. 3):  Рис. 3. Изображения для k = 5, 20, 50, 250, соответственно Полагаем, что допустимым качеством обладает изображение для k = 50 сингулярных значений. Посмотрим, какой выигрыш мы можем получить используя его вместо оригинала. 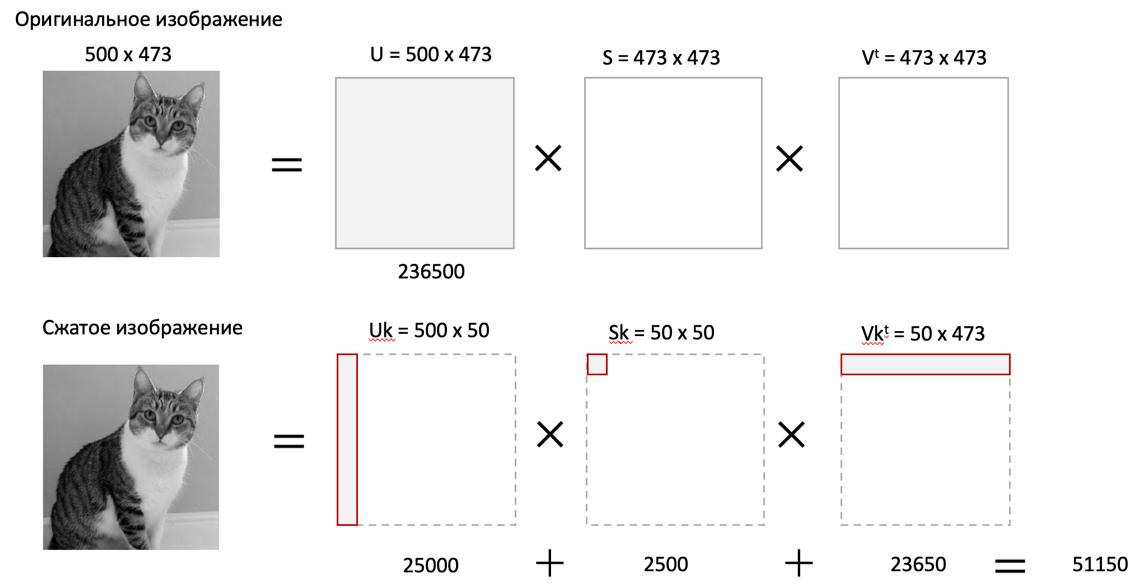 Рис. 4. Сравнение размерностей оригинального и сжатого изображения На рис. 4 приведено такое сравнение, где показано, что вместо 236500 пикселей нам потребуется всего 51150, то есть m 4,6 раза. Для оценки количества информации, которое мы потеряем, заменив оригинальное изображение на сжатое, можно поступить следующим образом. Если суммарное количество значений всех главных компонент принять за 100% информационного наполнения оригинала, то сумма значений k главных компонент сжатого изображения определит его информационное наполнение. Разность вычисленных таким образом величин и даст оценку «потерянной» Пример 2. Рассмотрим еще один пример использования метода PCA для анализа набора данных MNIST из [https://www.kaggle.com/oddrationale/mnist-in-csv]. Здесь имеется 60000 изображений рукописных цифр (mnist_train.csv) для обучения и 10000 изображений для тестирования (mnist_test.csv). Каждая цифра представлена вектором размерности 785, в котором изображение цифры занимает 28х28=784 компоненты и одна компонента label служит для идентификации изображенной цифры. Загрузим из ресурса файл mnist_test.csvв свой рабочий директорий. Возьмем из него 6000 случайно выбранных образцов и рассмотрим как будут классифицироваться эти образцы с использованием двух главных компонент (листинг 2). После чтения исследуемого набора в память (строка 4), определяем компоненту вектора label, как фактор (строка 5). Для воспроизводимости эксперимента устанавливаем фиксированную начальную фазу генератора случайных чисел set.seed(1), перед случайным выбором 6000 образцов (строка 6). Случайно выбранные образцы записываем в матрицу train (строка 8) и вычисляем две главные компоненты с помощью функции princomp. Важно отметить, что при вычислении главных компонент данной функцией первая компонента label из матрицы образцов должна быть исключена train[,-1]. Листинг 2. Проецирование MNIST на плоскость с использованием PCA  В результате мы получим следующую визуализацию (рис. 5), которая показывает потенциальные возможности классификации набора. 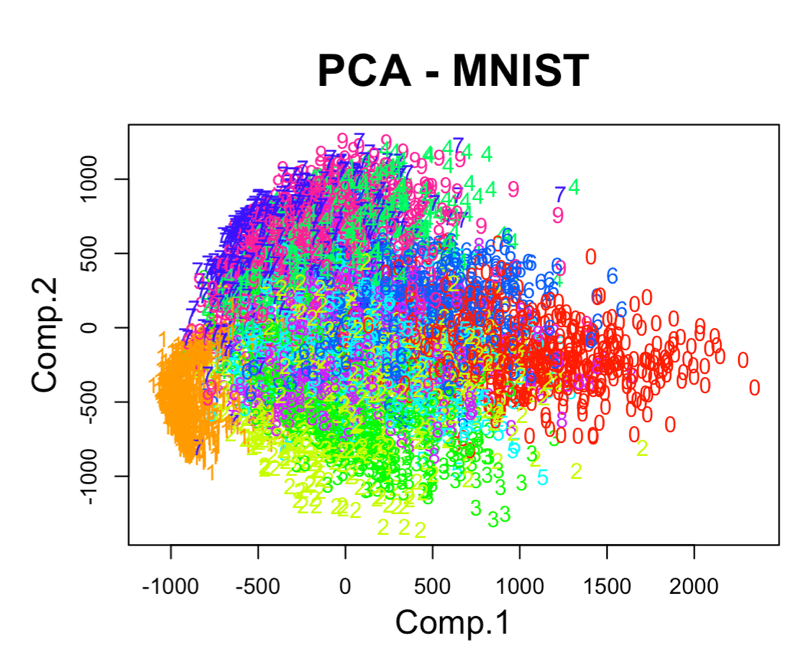 Рис. 5. Визуализация MNIST по двум главным компонентам PCA Анализ визуализации рис. 5 не позволяет нам сделать никаких однозначных выводов о достижимой точности классификации набора MNIST. Алгоритм t-SNEt-распределенное стохастическое соседнее вложение t-SNE (t-Distributed Stochastic Neighbor Embedding) - это алгоритм нелинейного уменьшения размерности, используемый для исследования данных большой размерности. Он отображает многомерные данные в двух или более измерениях, подходящих для наблюдения человеком. Алгоритм t-SNE (2008), в ряде случаев намного эффективнее PCA (1933). Важно подчеркнуть, что большинство нелинейных методов, кроме t-SNE, не способны одновременно сохранять локальную и глобальную структуру данных [L.J.P. van der Maaten and G.E. Hinton. Visualizing High-Dimensional Data Using t-SNE. Journal of Machine Learning Research 9(Nov):2579-2605, 2008]. SNE начинается с преобразования многомерной евклидовой дистанции между точками в условные вероятности, отражающие сходство точек. Математически это выглядит следующим образом: 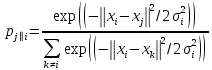 Формула показывает, насколько точка xj близка к точке xi при гауссовом распределении вокруг xiс заданным отклонением σ. Сигма будет различной для каждой точки. Она выбирается так, чтобы точки в областях с большей плотностью имели меньшую дисперсию. Для этого используется оценка перплексии (perplexity): 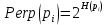 , ,где 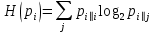 - энтропия Шеннона. Перплексия может быть интерпретирована как сглаженная оценка эффективного количества «соседей» для точки xi. Она задается в качестве параметра метода t-SNE и рекомендуется использовать ее значение в интервале от 5 до 50. Сигма определяется для каждой пары xi и xj при помощи алгоритма бинарного поиска. Таким образом, t-SNE алгоритм нелинейного уменьшения размерности, находит закономерности в данных, идентифицируя наблюдаемые кластеры на основе сходства точек данных с несколькими функциями. Но это не алгоритм кластеризации, а алгоритм уменьшения размерности, который просто отображает многомерные данные в более низкоразмерное пространство, а не идентифицирует входные объекты. Таким образом, вы не можете делать никаких выводов, основываясь только на t-SNE. По сути, это в основном техника исследования и визуализации данных. Но алгоритм t-SNE можно использовать в процессе классификации и кластеризации, используя его выходные данные в качестве входных характеристик для других алгоритмов классификации. Алгоритм t-SNE можно использовать практически для всех многомерных наборов данных. Он особенно широко применяется в обработке изображений, естественного языка и геномных данных. Ниже приведены распространенные ошибки, которых следует избегать при интерпретации результатов анализа с использованием алгоритма t-SNE: Чтобы алгоритм работал правильно перплексия должна находится в диапазоне от 5 до 50 и должна быть меньше количества переменных. Размеры кластеров на любом графике t-SNE не должны оцениваться на предмет стандартного отклонения, дисперсии или любых других аналогичных показателей. Это связано с тем, что t-SNE расширяет более плотные кластеры и сжимает более разреженные кластеры для выравнивания размеров кластеров. Это одна из причин получения четких и ясных графиков. Расстояния между кластерами могут измениться, потому что глобальная геометрия тесно связана с оптимальной сложностью. А в наборе данных с множеством кластеров с разным количеством элементов одна перплексия не может оптимизировать расстояния для всех кластеров. Шаблоны также могут быть обнаружены в случайном шуме, поэтому необходимо проверить несколько запусков алгоритма с разными наборами гиперпараметров, прежде чем решать, существует ли шаблон в данных. Различные формы кластеров могут наблюдаться на разных уровнях сложности. Топология не может быть проанализирована на основе одного графика t-SNE, перед проведением какой-либо оценки необходимо наблюдать несколько графиков. Примеры использования алгоритма t-SNEПример 1. Рассмотрим пример использования алгоритма t-SNE для анализа набора данных MNIST и сравним его возможности с результатом полученным ранее с использованием метода РСА (листинг 3): Листинг 3. Анализ MNIST методами PCA и t-SNE  По отношению к предыдущему листингу в листинг 3 добавлена функция Rtsne (строка 9) для реализации алгоритма t-SNE. Она имеет много входных параметров для настройки. Для наглядности в строке 15 параметр par(mflow= c(1,2)) определяет вывод двух графиков рядом в оной строке. В результате мы получим следующую визуализацию (рис. 6). 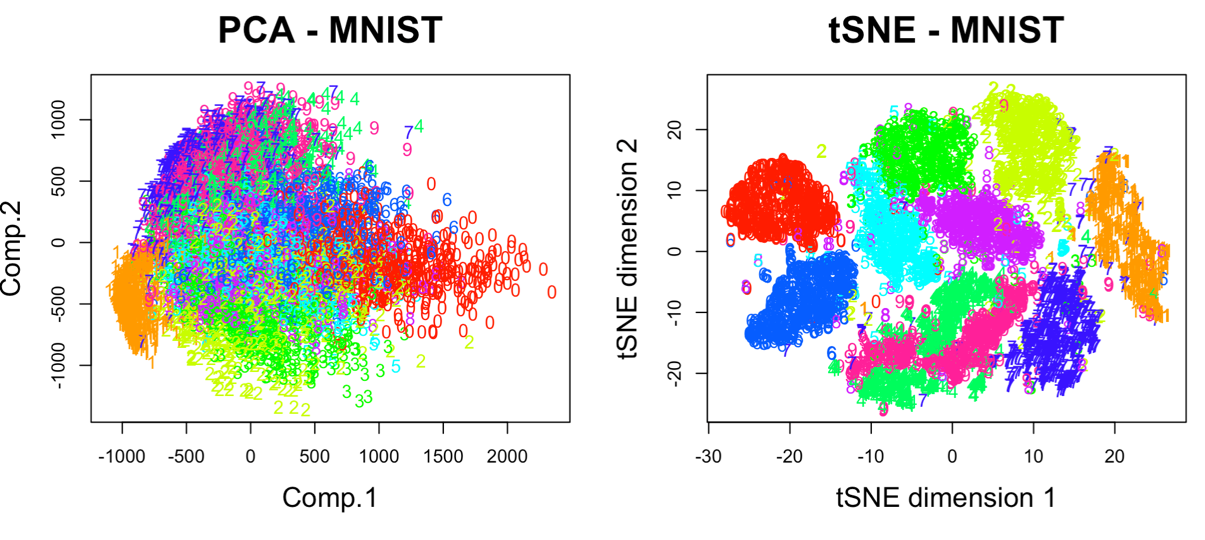 Рис. 6. Визуализация MNIST по двум компонентам с использованием PCA и tSNE Анализ визуализации рис. 6 справа позволяет сделать вывод о достижимой точности классификации набора MNIST гораздо более оптимистичным. Пример 2. Рассмотрим пример исследования данных по 250000 заемщиков, представленных в [https://www.kaggle.com/c/GiveMeSomeCredit/data] и оценим эффективность их использования для кредитного скоринга. Банки играют решающую роль в рыночной экономике. Они определяют, кто может получить финансирование и на каких условиях, а также могут принимать или отменять инвестиционные решения. Для функционирования рынков и общества отдельным лицам и компаниям необходим доступ к кредитам. Алгоритмы кредитного скоринга банки используют для определения того, следует ли предоставлять ссуду. По-сути, скоринг позволяет оценить вероятности дефолта для отдельных групп заемщиков. Посмотрим насколько алгоритм t-SNE подходит для решения подобной задачи. Загрузим файл cs-test.csv из [] в рабочий директорий RStudio. Ниже представлен листинг использования этого алгоритма для скоринга (листинг 4). Сначала загружаем необходимые библиотеки (строки 1-6) и читаем исследуемый файл из рабочего директория (строка 8). Затем подготавливаем загруженные данные для анализа: удаляем неинформативные столбцы (строка 10, 11); преобразуем данные в форму data.table (строка 13); удаляем строки с пропущенными значениями атрибутов (строка 15). В строке 18 уточняем размерность анализируемых данных после проведенных преобразований (осталось 81400 векторов для анализа). Для сокращения времени анализа возьмем только 500 случайных образцов (общая тенденция не изменится). Используем функцию Rtsne в цикле для различных значений перплексии и визуализируем результаты. Листинг 4. Использование алгоритма t-SNE для скоринга  Результатом визуализации будут графики представленные на рис. 7. Хорошо заметна тенденция упрощения представления исследуемых векторов при увеличении значения перплексии. 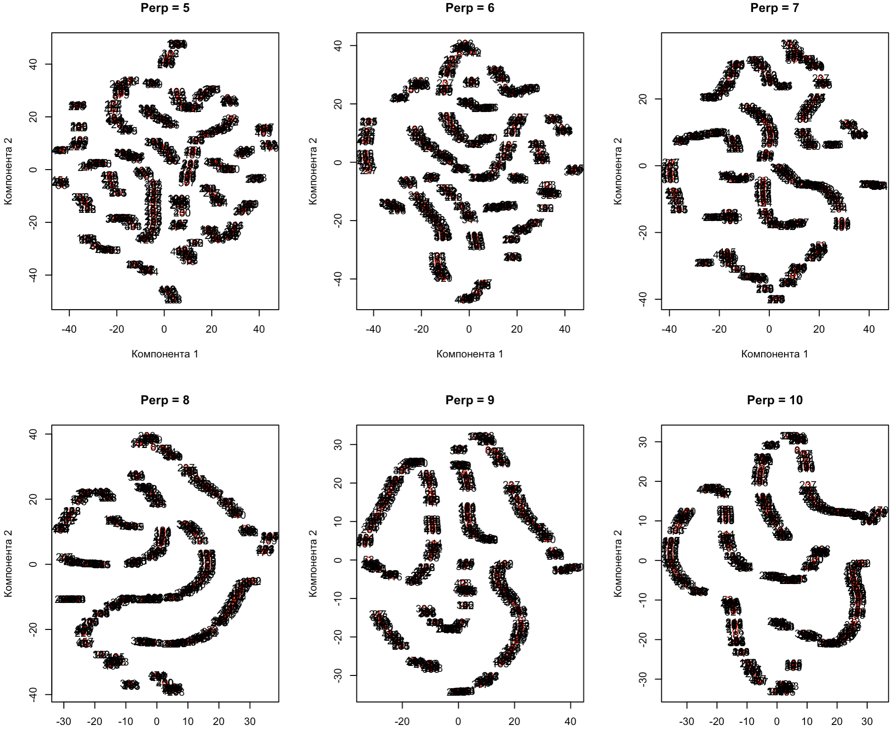 Рис. 7. Визуализация результатов скоринга Поскольку перплексия фактически задает число, которое устанавливает обоснованное предположение относительно количества близких соседей для каждой точки данных, то ее назначение состоит в том, чтобы сбалансировать локальные и глобальные аспекты ваших данных. t-SNE - инструмент для визуализации многомерных данных. Он преобразует аффинитеты точек данных в вероятности. Аффинитеты в исходном пространстве представлены гауссовыми совместными вероятностями, а аффинитеты во вложенном пространстве представлены t-распределениями Стьюдента. Это обеспечивает t-SNE особую чувствительность к локальной структуре и дает несколько других преимуществ над существующими методами [https://www.ibm.com/docs/ru/spss-modeler/SaaS?topic=nodes-t-sne-node ]. Алгоритм UMAPАппроксимация и проекция однородного многообразия UMAP (UniformManifoldApproximationandProjection) - это метод уменьшения размерности, который можно использовать для визуализации аналогично t-SNE, но также для общего нелинейного уменьшения размерности. Алгоритм основан на трех предположениях о данных: данные равномерно распределены на римановом многообразии; метрика Римана локально постоянна (или может быть аппроксимирована как таковая); многообразие локально связно. Исходя из этих предположений, можно смоделировать многообразие с нечеткой топологической структурой. Вложение находится путем поиска низкоразмерной проекции данных, которая имеет наиболее близкую возможную эквивалентную нечеткую топологическую структуру. Подробности лежащей в основе математики можно найти у авторов этого алгоритма в [https://arxiv.org/pdf/1802.03426.pdf ]. UMAP — это новый алгоритм уменьшения размерности, библиотека с реализацией которого вышла совсем недавно. Авторы алгоритма считают, что UMAP способен бросить вызов современным моделям снижения размерности, в частности, t-SNE, который на сегодняшний день является наиболее популярным. По результатам их исследований, у UMAP нет ограничений на размерность исходного пространства признаков, которое необходимо уменьшить, он намного быстрее и более вычислительно эффективен, чем t-SNE, а также лучше справляется с задачей переноса глобальной структуры данных в новое, уменьшенное пространство. Пример использования алгоритма UMAPРассмотрим пример использования алгоритма UMAP (листинг 5) для анализа набора данных MNIST и сравним его возможности с результатом полученным ранее с использованием методов РСА и t-SNE в листинге 3. Код листинга 5 максимально идентичен коду листингов 2 и 3, с той лишь разницей, что здесь используется функция umap(). Листинг 5. Анализ MNIST методом UMAP  В результате мы получим следующую визуализацию (рис. 8), которая показывает потенциальные возможности классификации набора. 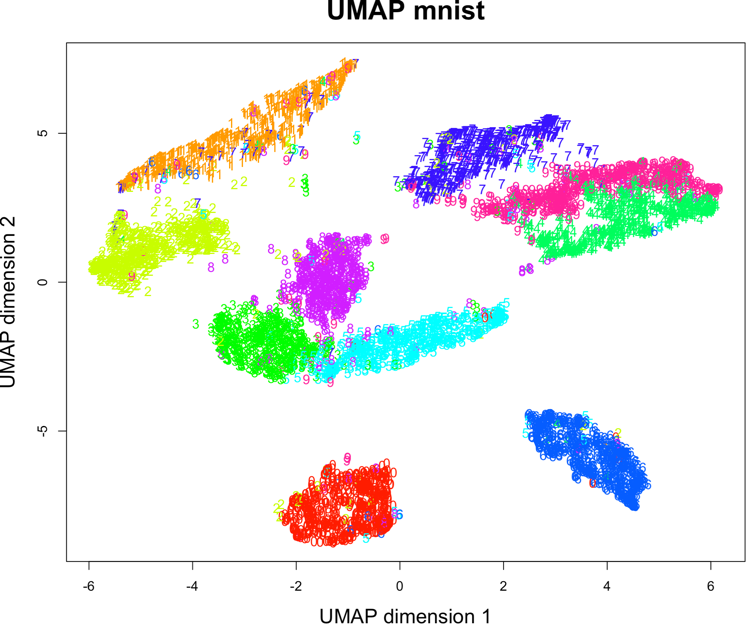 Рис. 8. Визуализация MNIST по двум компонентам с использованием UMAP Анализ визуализации рис. 8 позволяет сделать вывод о достижимой точности классификации набора MNIST еще более оптимистичным, чем визуализации рис. 6. Графика в формате SVGТехнология масштабируемой векторной графики SVG (Scalable Vector Graphics) позволяет объединить в одном формате текст, графику, анимацию и интерактивные компоненты и базируется на трех типах графических изображений: векторных формах, рисунках и тексте. Объекты, как это принято в векторной графике, представлены либо прямолинейными и криволинейными контурами, либо графическими примитивами (прямоугольниками, эллипсами и др.), а рисунки представляют собой импортированные растровые изображения. Помимо этого формат SVG поддерживает различные виды анимационных (напоминающих GIF и flash-анимацию) и интерактивных объектов, таких как гиперссылки, реакции на внешние события и прочие элементы навигации. Важно и то, что поскольку данный стандарт основан на языке XML, то SVG-файл наряду с элементами, предназначенными для визуального отображения, может содержать также различные метаданные. Указанные особенности выдвигают SVG-технологии на лидирующие места в области проектирования и разработки веб-ресурсов. Для знакомства с SVG-технологией полезно обратиться к одному из лучших веб-ресурсов, расположенного по адресу https://svg-art.ru/. Кроме того, вся информация, необходимая для выполнения третьего задания курсовой работы, приведена в [14-15]. КОМПЛЕКТ ЗАДАНИЙКурсовая работа предполагает выполнение трех заданий. Первое задание относится к изучению технологий понижения размерности анализируемых данных, позволяющих существенно снизить объем обрабатываемой информации. Для выполнения задания №1 следует изучить литературу, посвященную методу главных компонент, например [1-5] и ознакомиться с доступными библиотеками программ, реализующими данный метод. Второе задание связано с использованием технологий, позволяющих оценить возможности качественной кластеризации исследуемого набора данных. Современными эффективными алгоритмами, позволяющими решить подобную задачу, являются алгоритмы t-SNE и UMAP. Для выполнения задания №2 следует изучить особенности реализации данных алгоритмов, например, с использованием материалов ресурсов [6 – 10]. Третье задание позволить приобрести практические навыки в работе с графической информацией на базе перспективной технологии SVG. Данная технология тесно сопряжена с языком разметки HTML. Первое и второе задание может выполняться в любой программной среде, с использованием любых языков программирования и библиотек. Тем не менее, рекомендуется использовать среду RStudio и язык программирования R, широко используемых IT-специалистами. Задание № 1: Понижение размерности данныхИсследовать эффективность методов PCA и SVD для понижения размерности данных. В качестве исходных данных для анализа следует самостоятельно выбрать изображение в формате jpg. Размер изображения должен быть не менее 400 х 400 пикселей. В ходе исследования необходимо проделать следующее: выбрать и обосновать количество главных компонент, достаточное для качественной визуализации; оценить выигрыш сжатого изображения по объему, по сравнению с оригиналом; оценить количество «утраченной» информации; выяснить зависит ли достаточное число компонент для качественной визуализации от характера изображения (если да, то оценить эту зависимость). Контрольные вопросы Как вычислить матрицу счетов метода РСА исследуемой матрицы Х, используя сингулярное разложение Х? Опишите процесс выделения главных компонент в многомерном случае своими словами. Что такое собственные значения матрицы счетов метода РСА и что они характеризуют? Как связаны между собой сингулярные значения SVD разложения и собственные значения матрицы счетов метода РСА? Какие критерии выбора числа главных компонент используются на практике? Задание № 2: Кластеризация данныхИсследовать возможности классификации данных с использованием алгоритмов t-SNE и UMAP. Исходные данные для анализа загрузить из ресурса WineQuality (http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality /) репозитария [10]. Варианты заданий (номер варианта определяется последней цифрой номера зачетки) приведены в табл. 2. Таблица 2 Варианты задания
Анализируемые данные включают 11 объективных параметров различных сортов вина: фиксированная кислотность; летучая кислотность; лимонная кислота; остаточный сахар; хлориды; свободный диоксид серы; общий диоксид серы; плотность; pH; сульфаты; спирт. Последний, 12-ый параметр является субъективной оценкой качества, проставляемой экспертом и имеет несколько градаций. Основная задача исследования состоит в определении качества субъективной оценки экспертов и формированию обоснованной кластеризации вин. Исследование должно содержать: описание исследуемого набора данных, подготовку данных для анализа, план и решаемые задачи, выбор используемых функций и описание их параметров, результаты исследования, аргументированные выводы. Программный код должен быть снабжен подробным комментарием. Контрольные вопросы Как можно интерпретировать назначение и выбирать адекватное значение перплексии при использовании алгоритма t-SNE? Как решается проблема скученности точек в пространстве отображения в алгоритме t-SNE? Чем распределение Стьюдента отличается от нормального распределения? Что пытается сохранить алгоритм UMAP: глобальную структуру анализируемых данных или локальные расстояния между отдельными точками? Задание № 3: Обработка графической информацииВизуализировать отрывок сказки К.И.Чуковского «Муха-цокотуха» с использованием технологии SVG, соответствующий номеру фрагмента. Номер своего фрагмента определяется последней цифрой номера зачетной книжки: Муха, Муха-Цокотуха, Позолоченное брюхо! Муха по полю пошла, Муха денежку нашла. Пошла Муха на базар И купила самовар: "Приходите, тараканы, Я вас чаем угощу!" Тараканы прибегали, Все стаканы выпивали, А букашки - По три чашки С молоком И крендельком: Нынче Муха-Цокотуха Именинница! Приходили к Мухе блошки, Приносили ей сапожки, А сапожки не простые - В них застежки золотые. Приходила к Мухе Бабушка-пчела, Мухе-Цокотухе Меду принесла... "Бабочка-красавица. Кушайте варенье! Или вам не нравится Наше угощенье?" Вдруг какой-то старичок Паучок Нашу Муху в уголок Поволок - Хочет бедную убить, Цокотуху погубить! "Дорогие гости, помогите! Паука-злодея зарубите! И кормила я вас, И поила я вас, Не покиньте меня В мой последний час!" Но жуки-червяки Испугалися, По углам, по щелям Разбежалися: Тараканы Под диваны, А козявочки Под лавочки, А букашки под кровать - Не желают воевать! И никто даже с места Не сдвинется: Пропадай-погибай, Именинница! А кузнечик, а кузнечик, Ну, совсем как человечек, Скок, скок, скок, скок! За кусток, Под мосток И молчок! А злодей-то не шутит, Руки-ноги он Мухе верёвками крутит, Зубы острые в самое сердце вонзает И кровь у неё выпивает. Муха криком кричит, Надрывается, А злодей молчит, Ухмыляется. Вдруг откуда-то летит Маленький Комарик, И в руке его горит Маленький фонарик. "Где убийца, где злодей? Не боюсь его когтей!" Подлетает к Пауку, Саблю вынимает И ему на всём скаку Голову срубает! Муху за руку берёт И к окошечку ведёт: "Я злодея зарубил, Я тебя освободил И теперь, душа-девица, На тебе хочу жениться!" Тут букашки и козявки Выползают из-под лавки: "Слава, слава Комару - Победителю!" Прибегали светляки, Зажигали огоньки - То-то стало весело, То-то хорошо! Эй, сороконожки, Бегите по дорожке, Зовите музыкантов, Будем танцевать! Музыканты прибежали, В барабаны застучали. Бом! бом! бом! бом! Пляшет Муха с Комаром. А за нею Клоп, Клоп Сапогами топ, топ! Козявочки с червяками, Букашечки с мотыльками. А жуки рогатые, Мужики богатые, Шапочками машут, С бабочками пляшут. Тара-ра, тара-ра, Заплясала мошкара. Веселится народ - Муха замуж идёт За лихого, удалого, Молодого Комара! Муравей, Муравей! Не жалеет лаптей,- С Муравьихою попрыгивает И букашечкам подмигивает: "Вы букашечки, Вы милашечки, Тара-тара-тара-тара-таракашечки!" Сапоги скрипят, Каблуки стучат,- Будет, будет мошкара Веселиться до утра: Нынче Муха-Цокотуха Именинница! Как минимум, созданный фрагмент должен включать анимацию действия «героев» с использованием технологии SVG, а также звуковое сопровождение соответствующего фрагмента сказки (его можно вырезать, например из https://deti-online.com/audioskazki/skazki-chukovskogo-mp3/muha-cokotuha/). Звуковое сопровождение должно быть синхронизировано с визуальной анимацией. Сказка детская, поэтому постарайтесь, чтобы реализованный вами сценарий как можно точнее соответствовал текстовому фрагменту, был динамичен и красочен. Результирующий (исполнительный) файл должен иметь расширение svg. Не забудьте приложить все дополнительные файлы (аудио и, возможно jpg, png, gif и внешние svg и т.п.) и проверить работоспособность вашего продукта на разных браузерах. Контрольные вопросы Перечислите и назовите особенности использования всех тегов группировки объектов. С помощью какого механизма и какие динамические визуальные эффекты обеспечивает видовое окно viewBox? ПОЛЕЗНЫЕ РЕСУРСЫМетод главных компонент (примеры на R) http://math-info.hse.ru/f/2015-16/ling-mag-quant/lecture-pca.html Метод главных компонент https://rcs.chemometrics.ru/old/Tutorials/pca.htm Как работает метод главных компонент (примеры на Python) https://habr.com/ru/post/304214/ Метод главных компонент: введение (примеры на R) https://rpubs.com/AllaT/pca-intro Как уменьшить количество измерений и извлечь из этого пользу (SVD примеры на R) https://habr.com/ru/post/275273/ Препарируем t-SNE https://habr.com/ru/post/267041/ Comprehensive Guide on t-SNE algorithm with implementation in R & Python https://www.analyticsvidhya.com/blog/2017/01/t-sne-implementation-r-python/ Обзор нового алгоритма уменьшения размерности UMAP https://habr.com/ru/company/newprolab/blog/350584/ Uniform Manifold Approximation and Projection in R https://cran.r-project.org/web/packages/umap/vignettes/umap.html Machine Learning Repository [Электронный ресурс]. ‒ URL: http://archive.ics.uci.edu/ml/index.php (дата обращения 17.02.2021). Джентельменский набор пакетов R для автоматизации бизнес-задач https://habr.com/ru/post/309420/ Лучшие библиотеки языка R https://ai-news.ru/2020/08/luchshie_biblioteki_yazyka_r.html Научная библиотека избранных естественно-научных изданий https://scask.ru/index.php Филиппов Ф.В. Обработка графической информации в формате SVG : учебное пособие : часть 1 / Ф. В. Филиппов ; СПбГУТ. – СПб., 2017. – 84 с. Филиппов Ф.В. Обработка графической информации в формате SVG : учебное пособие : часть 2 / Ф. В. Филиппов ; СПбГУТ. – СПб., 2017. – 36 с. |