Методическое пособие по выполнению практических работ по предмет. Методическое пособие по выполнению практических работ по дисциплине Теория вероятностей и математическая статистика
 Скачать 1.23 Mb. Скачать 1.23 Mb.
|

Практическая работа №8 «Вычисление функции и плотности распределения непрерывных случайных величин».Случайная величина – величина, численное значение которой может меняться в зависимости от результата стохастического эксперимента. Непрерывной назовём случайную величину, которая может принять любое значение из некоторого промежутка. Распределение вероятностей непрерывной случайной величины х можно задавать либо функцией распределения F(x)=p(ξ Зная F(x), можно найти плотность вероятности по формуле: f(x)=F'(x), а зная f(x), найдём функцию распределения: Для непрерывной случайной величины х вероятность попадания её в промежуток с концами a и b равна: Причём Пример. Задана следующая функция распределения:  Найти плотность распределения. Решение. Зная F(x), можно найти плотность вероятности по формуле: f(x)=F'(x)=  Равномерное распределение. Случайная величина х называется равномерно распределённой на [a, b], если её плотность распределения f(x) на [a, b] постоянна, а вне [a, b] равна 0:  , , Пример 1. Время ожидания автобуса (х) измеряется в минутах и распределено равномерно на отрезке [0, 30]. Определить, что ждать придётся не более 10 минут. Решение. 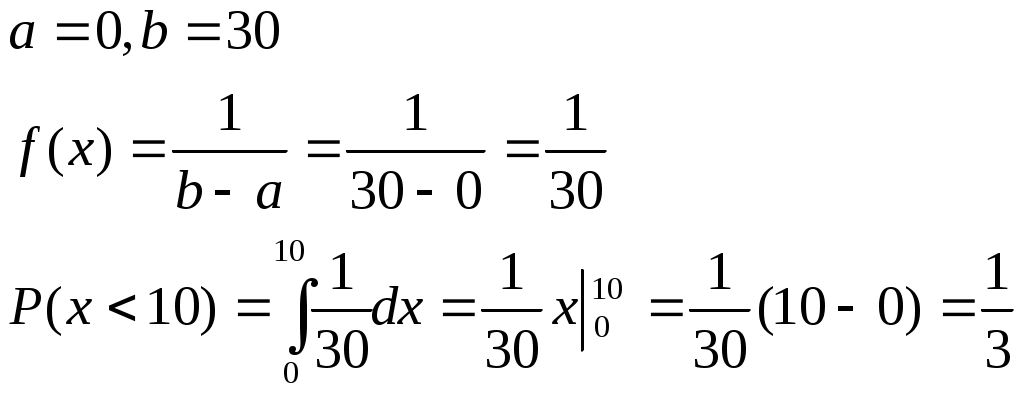 Пример 2. Задана плотность распределения:  Найти h. Решение. 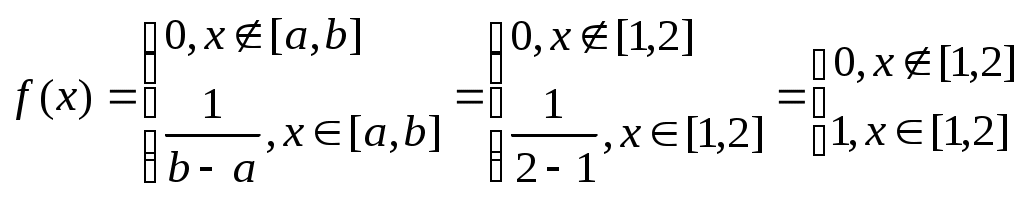 h-2=1 h=3 Нормальное распределение. Случайная величина х называется нормально распределённой, если её плотность распределения f(x) имеет вид:  , , где а и σ – параметры нормального распределения, σ >0. В этом случае говорят, что х распределено нормально согласно закону N(a, σ). Если а=0 и σ=1, то Значения Ф(х) затабулированы, Пример. Рост мужчины в Москве имеет нормальное распределение. Средний рост мужчины в Москве а=175 см, σ=10 см. Какова вероятность, что рост первого встречного мужчины будет в пределах 160-190 см? Решение.  Правило трёх сигм. Случайная величина х распределена нормально N(a, σ).  Пример. Рост мужчины в Москве имеет нормальное распределение. Средний рост мужчины в Москве а=175 см, σ=10 см. Какова вероятность, что рост первого встречного мужчины будет в пределах 145-205 см? Решение. Правило двух сигм. Случайная величина х распределена нормально N(a, σ).  Правило одной сигмы. Случайная величина х распределена нормально N(a, σ).  Практическая работа №9 «Вычисление числовых характеристик важнейших непрерывных распределений».Математическое ожидание непрерывной случайной величины определяется по формуле: Дисперсия непрерывной случайной величины определяется по формуле: Свойства математического ожидания и дисперсии дискретных случайных величин справедливы и для непрерывных случайных величин. Равномерное распределение.  Пример. Время ожидания автобуса (х) измеряется в минутах и распределено равномерно на отрезке [0, 30]. Определить среднее время ожидания автобуса и дисперсию. Решение.  Практическая работа №10 «Вычисление плотности распределения одного случайного аргумента».Функцией распределения двумерной случайной величины (X, Y) называют вероятность совместного выполнения двух неравенств: F(x, y) = P{X<x, Y<y}. Плотность распределения двумерной случайной величины вычисляется как вторая смешанная частная производная функции распределения: f(x,y) = Fxy(x,y). Выражение функции распределения через плотность: Свойства плотности распределения. Плотность распределения двумерного случайного вектора есть функция неотрицательная: f(x,y) 0. Двойной интеграл в бесконечных пределах от плотности распределения двумерного случайного вектора равен единице: Плотности распределения компонент случайного вектора могут быть получены по формулам: Закон распределения дискретного случайного вектора (X, Y) – это совокупность всех возможных значений случайного вектора (X, Y) и их вероятностей: pij=P{X=xi, Y=yj}, где i=1, 2, …, n, j=1, 2, …, m. n, m – число возможных значений случайных величин X и Y. Так же, как и в непрерывном случае: Пример 1. Качество продукции характеризуется двумя случайными величинами: X и Y. Закон распределения случайного вектора (X,Y) представлен в таблице:
На пересечении i-той строки и j-того столбца таблицы находятся вероятности pij=P{X=xi, Y=yj}. Найти закон распределения координат X и Y случайного вектора. Решение. Вероятность события {X=xi}=pi, есть сумма вероятностей, находящихся в i-той строке. Вероятности pi находятся в последнем столбце таблицы. Ряд распределения случайной величины X имеет вид:
Ряд распределения Y находим, вычисляя суммы элементов столбцов таблицы. Эти вероятности pj находятся в последней строке таблицы. Ряд распределения случайной величины Y имеет вид:
Условное распределение компонент дискретного случайного вектора (X, Y) – это ряд распределения одной случайной величины, вычисленной при условии, что другая случайная величина приняла определённое значение, а именно: 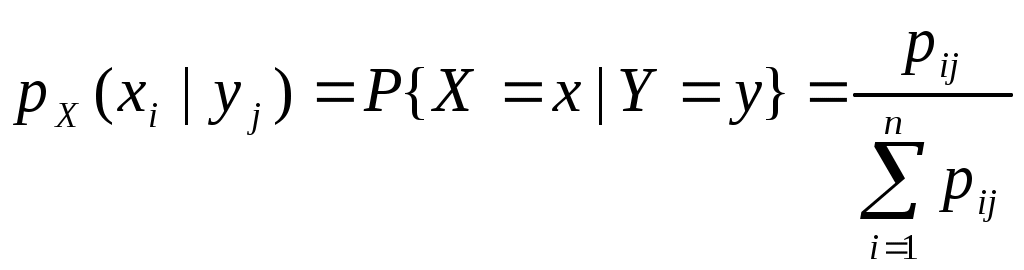 ; ;  Пример 2. В условиях закон распределения дискретного случайного вектора (X,Y) из примера 1, найти условное распределение случайной величины X при условии, что случайная величина Y приняла значение y2=0,1. Решение. Выбрав значения pi2 из столбца таблицы, соответствующего значению y2=0,1, и разделив их на 0,25, получаем следующее условное распределение X при условии, что Y=0,1:
Практическая работа №11 «Построение графических изображений выборок и эмпирических функций распределения».Для наглядного представления статистического распределения пользуются графическим изображением вариационных рядов (полигоном, гистограммой и куммулятой). В случае дискретного распределения на оси абсцисс откладывают отдельные значения признака. Из принимаемых значений xi проводят перпендикуляры, длины которых пропорциональны частотам mi, затем концы соседних перпендикуляров соединяют отрезками прямых. Это полигон для дискретных вариационных рядов. Пример. На телефонной станции проводились наблюдения над числом Х неправильных соединений в минуту. Наблюдения в течение часа дали следующие результаты:
 Гистограмма строится только для интервального вариационного ряда (группированной выборки). На каждом из интервалов значений как на основании, строят прямоугольник с высотой, пропорциональной mi. Если середины верхних сторон прямоугольников соединить отрезками прямых, а концы этой ломаной ещё соединить с серединами соседних интервалов, частоты которых равны 0, а длина равна длине соседнего интервала, то получим полигон интервального ряда. Пример.
 Кумулята – график накопленных частот, сглаженное графическое изображение эмпирической функции распределения. При построении кумуляты в точке, соответствующей принимаемому значению, для дискретного ряда и в правом конце интервала для интервального ряда строится перпендикуляр, высота которого пропорциональна накопленной частоте, затем верхние концы перпендикуляров соединяются между собой с помощью прямолинейных отрезков. «Накопленные частоты» - это и есть значения эмпирической функции распределения, а кумулята – её сглаженное графическое изображение.  Практическая работа №12 «Вычисление выборочных средней и дисперсии».Пусть x1, x2, …, xn – данные наблюдений над случайной величиной X. Средним арифметическим наблюдаемых значений случайной величины X называется частное от деления суммы всех этих значений на их число:  (1). (1).Если данные наблюдений представлены в виде дискретного ряда, где x1, x2, …, xn – наблюдаемые варианты, а m1, m2, …, mn – соответствующие им частоты, причём  (2). (2).Вычисленное по данной формуле среднее арифметическое называется взвешенным, так как частоты mi называются весами, а операция умножения xi на mi – взвешиванием. Для интервального вариационного ряда за xi принимают середину i-го интервала, а за mi - соответствующую интервальную частоту:  (3). (3).Основные свойства среднего арифметического: Среднее арифметическое алгебраической суммы соответствующих друг другу значений равна алгебраической сумме средних арифметических: Если ряд наблюдений состоит из двух непересекающихся групп наблюдений, то среднее арифметическое всего ряда наблюдений равно взвешенному среднему арифметическому групповых средних, причём весами являются объёмы соответствующих групп: Среднее арифметическое постоянной равно самой постоянной: Постоянную можно выносить за знак среднего арифметического: Сумма отклонений результатов наблюдений от их среднего арифметического равна нулю: Если все результаты наблюдений увеличить (уменьшить) на одно и то же число, то среднее арифметическое увеличится (уменьшится) на то же число: Если все частоты вариантов умножить на одно и то же число, то среднее арифметическое не изменится. Выборочной дисперсией значений случайной величины X называется средне арифметическое квадратов отклонений наблюдаемых значений этой величины от их среднего арифметического:  (4). (4).Если данные наблюдений представлены в виде дискретного ряда, где x1, x2, …, xn – наблюдаемые варианты, а m1, m2, …, mn – соответствующие им частоты, причём 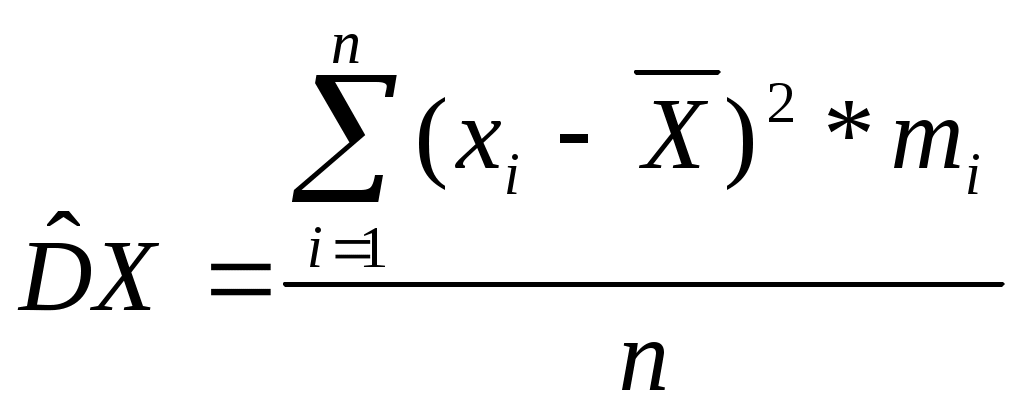 (5). (5).Используя равенство Дисперсия, вычисленная по формулам 5 и 6, называется взвешенной выборочной дисперсией. Основные свойства выборочной дисперсии: Дисперсия постоянной равна нулю: Если все результаты наблюдений увеличить (уменьшить) на одно и то же число С, то дисперсия не изменится: Если все результаты наблюдений умножить на одно и то же число С, то имеет место равенство: Если все частоты вариантов умножить на одно и то же число, то выборочная дисперсия не изменится. Выборочная дисперсия равна разности между средним арифметическим квадратов наблюдений над случайной величиной X и квадратом её среднего арифметического: Пример 1. По данным, приведённым в таблице, вычислить среднее арифметическое и дисперсию числа неправильных соединений в минуту.
Решение. Среднее арифметическое вычислим по формуле 2: Дисперсию вычисляем по формуле 5:  Пример 2. По данным, приведённым в таблице, вычислить среднее арифметическое и дисперсию диаметра валика. 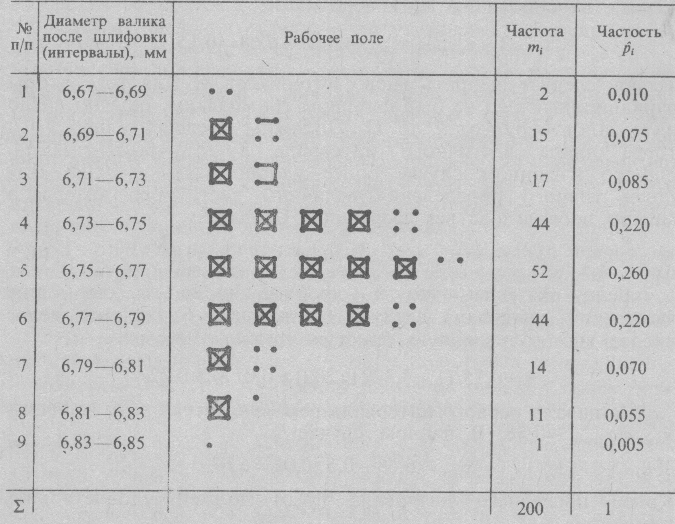 Решение. Среднее арифметическое вычислим по формуле 3:  Дисперсию вычисляем по формуле 6:  Практическая работа №13 «Решение задач на доверительный интервал».Если в процессе эксперимента для статистики получено некоторое значение, то значит оно принадлежит области I, вероятность которой близка к 1. Эту вероятность называют доверительной вероятностью. Её обозначают . По ней строят интервал, накрывающий значение оцениваемого параметра с вероятностью . Его и называют доверительным интервалом с уровнем доверия . Область I и доверительный интервал по ней строятся в соответствии с распределением вероятностей используемой статистики. Величина уровня доверия влияет на величину интервала: чем больше уровень доверия, тем шире интервал. Уровень доверия выбирается из соображений допустимого риска. Формула для доверительного интервала для математического ожидания нормального распределения с уровнем доверия для случая, когда известно среднеквадратическое отклонение распределения : Формула для доверительного интервала для математического ожидания нормального распределения с уровнем доверия для случая, когда среднеквадратическое отклонение распределения неизвестно: Пример. Для проверки фасовочной установки были отобраны и взвешены 20 упаковок. Получены следующие результаты (в граммах):
Найти доверительный интервал для математического ожидания с надёжностью 0,95, предполагая, что измеряемая величина распределена нормально. Решение. Находим точечные оценки a и :  Определяем по таблице распределения Стьюдента для доверительной вероятности =0,95 и числу степеней свободы (n-1)=19 соответствующее значение t=2,093 и по формуле находим искомый интервал: или 251,27 а 254,69. Практическая работа №14 «Расчёт сводных характеристик выборки методом произведений».Признак – это основная отличительная черта, особенность изучаемого явления или процесса. Количественное представление признака называется показателем. Результативный признак – исследуемый показатель процесса, характеризующий эффективность процесса. Факторный признак – показатель, влияющий на значение результативного показателя. Целью регрессионного анализа является оценка функциональной зависимости условного среднего значения результативного признака (Y) от факторных (x1, x2, …, xn), выражаемой в виде уравнения регрессии: Y = f(x1, x2, …, xn). Для характеристики связей между признаками используют следующие типы функций: - линейную - гиперболическую - показательную - параболическую - степенную Линейная функция используется в случае, если результативный и факторный признаки возрастают одинаково, примерно в арифметической прогрессии, гиперболическая – если связь между Y и x, наоборот, обратная. Параболическая или степенная функция применяются, если факторный признак увеличивается в арифметической прогрессии, а результативный значительно быстрее. Линейная однофакторная регрессия:  , где n – объём исследуемой совокупности. , где n – объём исследуемой совокупности.В уравнении регрессии свободный член регрессии коэффициент a0 показывает совокупное влияние на результативный признак неучтённых (не выделенных для исследования) факторов; его вклад в значение результирующего показателя не зависит от изменения факторов; параметр а1 – коэффициент регрессии – показывает, на сколько изменяется в среднем значение результативного признака при увеличении факторного на единицу собственного измерения. Пример. По следующим данным, полагая, что зависимость между x и Y линейная, определить значения коэффициентов a0 и а1:
Решение. Для определения величин a0 и а1 необходимо вычислить следующие значения: х, Y, xY, х2. Расчёты рекомендуется проводить в Exсel и оформлять в виде таблицы:
Система нормальных уравнений имеет вид:  Решив данную систему методом Гаусса, получаем значения: a0=0,876, а1=1,284. Следовательно,  Практическая работа №15 «Расчёт сводных характеристик выборки методом сумм».Однофакторная параболическая модель второй степени - параболическая регрессия применяется, если факторный признак увеличивается в арифметической прогрессии, а результативный значительно быстрее. В этом случае уравнение регрессии будет иметь вид: В данном случае задача сводится к определению неизвестных параметров: а0, а1,. Величину параметров a0, а1 и а2 находим как решение системы нормальных уравнений:  , ,Пример. По следующим данным, полагая, что зависимость между x и Y параболическая, определить значения коэффициентов a0, а1 и а2:
Решение. Для определения величин a0, а1 и а2 необходимо вычислить следующие значения: х, Y, xY, х2, х3, x4, х2Y. Расчёты рекомендуется проводить в Exсel и оформлять в виде таблицы:
Система нормальных уравнений имеет вид:  Решив данную систему методом Гаусса, получаем значения: a0=0,734, а1=1,352, а2=0,0126. Следовательно, уравнение регрессии имеет вид: Оценка обратной зависимости между Y и x, может быть дана на основе уравнения гиперболы: Величину параметров a0 и а1 находим как решение системы нормальных уравнений:  , ,Пример. По следующим данным, полагая, что зависимость между x и Y выражается уравнением гиперболы, определить значения коэффициентов a0 и а1:
Решение. Для определения величин a0 и а1 расчёты рекомендуется проводить в Exсel и оформлять в виде таблицы:
Система нормальных уравнений имеет вид:  Решив данную систему методом Гаусса, получаем значения: a0=9,02, а1=0,71. Следовательно, уравнение регрессии имеет вид: |