отчёт. Веревкин. Народ, жамкайте кнопку чата чтоли для авторизации
 Скачать 81.53 Kb. Скачать 81.53 Kb.
|

Лицензирование ПО: способы защиты ПОДля защиты используют следующие технологии: 1. Физическое обладание аппаратного ключа. 2. Защита, основанная на знании (серийные номера, код активации). 3. Защита с использованием сервера активации. 4. Защита с привязкой к рабочему месту – двухфазный процесс. 5. Организационная защита. Управление изменениями кода: MS Team Foundation ServerTeam Foundation Server (сокр. TFS) — продукт корпорации Microsoft, представляющий собой комплексное решение, объединяющее в себе систему управления версиями, сбор данных, построение отчетов, отслеживание статусов и изменений по проекту и предназначенное для совместной работы над проектами по разработке программного обеспечения. Данный продукт доступен как в виде отдельного приложения, так и в виде серверной платформы для Visual Studio Team System (VSTS) Архитектура. клиентский уровень, прикладной уровень иуровень данных Клиентский уровень используется для создания и управления проектами, а также для доступа к хранимым и управляемым элементам проекта. На этом уровне TFS не содержит никаких пользовательских интерфейсов, но предоставляет веб-сервисы, которые могут быть использованы клиентскими приложениями для самостоятельной интеграции в функциональность TFS. Эти веб-сервисы используются такими приложениями, какVisual Studio Team System для применения TFS в качестве серверной инфраструктуры хранилища информации или выделенного TFS управления приложениями, наподобие включенного приложения Team Foundation Client. Сами веб-сервисы находятся на прикладном уровне. Прикладной уровень также включает в себя веб-портал и репозиторий (хранилище) документации, поддерживаемые Windows SharePoint Services. Веб-портал, называемый Team Project Portal (портал командного проекта), выступает в роли центра взаимодействия для проектов, управляемых TFS. Репозиторий документов используется как для элементов проекта, так и для отслеживания ревизий (документирование изменений), а также для накопления и обработки данных и генерации отчетов. Уровень данных, основывающийся в первую очередь на установленном SQL Server 20хх Standard Edition, обеспечивает сервисы постоянного хранения данных для репозитория документов. Уровень данных и уровень приложений могут существовать на различных физических или виртуальных серверах при использовании Windows Server 2003 или более специализированных версий. Уровень данных не взаимодействует с клиентским уровнем напрямую, только через прикладной уровень. 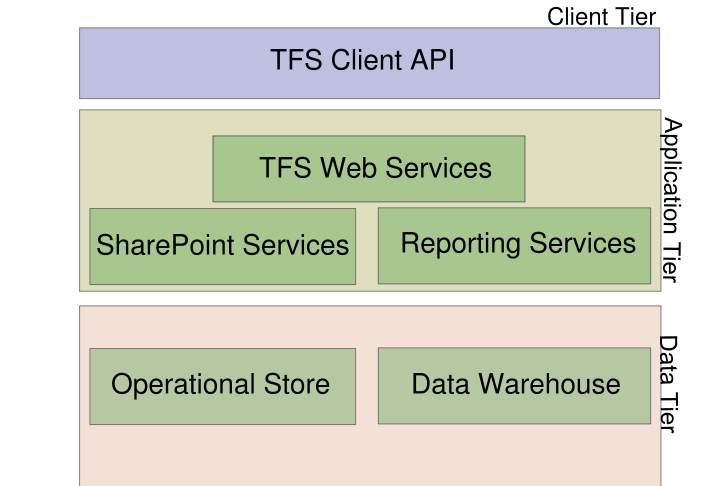 Любой Team Foundation Server содержит один или более Совместный проект, состоящий из решений на базе Visual Studio, конфигурационных файлов для Team Build и Team Load Test Agents, и единый репозиторий на базе SharePoint, содержащий связанную с проектом документацию. Совместный проект включает в себя пользовательские рабочие элементы, версии (ветки) исходного кода, отчеты, управляемые TFS. TFS обеспечивает возможности для управления этими проектами. Контроль исходного кодаПроект хранится ровно так же, как и записи обо всех изменениях кода в БД под управлением SQL Server. Поддерживаются такие особенности: одновременная множественная блокировка кода для изменения (один и тот же файл одновременно могут редактировать несколько человек) решение конфликтов откладывание внесений изменений (изменил файл, отложил. эти изменения могут видеть другие пользователи, но доступа к ним не получат) ветвление и слияние уровни доступа на любом уровне дерева исходного кода. Поддерживаются ветвления на всех уровнях исходного кода, даже файла и каталога. Обьединять ветки можно с указанием алгоритма решения конфликтов. Отчетность - еще один основной компонент Team Foundation Server. При помощи него можно создавать множество отчетов на основе объединения информации о рабочих элементах, наборах изменений, информации, поставляемой Team Build, и результатов тестирования от Test Agents. Например, уровень изменений кода за определенный временной промежуток, списки ошибок, не имеющих тестовых наборов, повторения ранее пройденных тестов и т. д. Существует портал проекта. Управление изменениями кода: SVNSubversion (SVN) — централизованная система (в отличии от распределенных систем, типа Git или Mercurial), т.е. данные хранятся в едином хранилище. Хранилище может располагаться на локальном диске или на сетевом сервере. Работа в Subversion мало отличается от работы в других централизованных системах управления версиями. Клиенты копируют файлы из хранилища, создавая локальные рабочие копии, затем вносят изменения в рабочие копии и фиксируют эти изменения в хранилище. Несколько клиентов могут одновременно обращаться к хранилищу. Для совместной работы над файлами в Subversion преимущественно используется модель копирование — изменение — слияние. Кроме того, для файлов, не допускающих слияние (различные бинарные форматы файлов), можно использовать модельблокирование — изменение — разблокирование. При сохранении новых версий используется дельта-компрессия: система находит отличия новой версии от предыдущей и записывает только их, избегая дублирования данных. При использовании доступа с помощью WebDAV также поддерживается прозрачное управление версиями — если любой клиент WebDAV открывает для записи и затем сохраняет файл, хранящийся на сетевом ресурсе, то автоматически создаётся новая версия. Типы репозиториев: Первый тип используют для хранения БД на основе Berkeley DB Второй тип - обычные файлы специального формата (доступ к ним организуется с помощью собственных библиотек, без использования сторонних БД) Оба типа репозиториев обеспечивают достаточную надёжность при правильной организации. Доступ к репозиторию: Прямой доступ к репозиторию на диске Удаленный доступ по протоколу WebDAV с использованием модуля mod_dav_svn (для Apache 2) Удаленный доступ с иcпользованием собственного протокола SVN на выделенном сетевом соединении (по умолчанию tcp-порт 3690) через стандартный ввод-вывод (SSH,CLI) Все эти способы могут быть использованы для работы с репозиториями обоих типов (FSFS и Berkeley DB). Для доступа к одному и тому же репозиторию могут одновременно использоваться разные способы. Подробнее Управление изменениями кода: MercurialMercurial кроссплатформенная распределенная система управления версиями, разработанная для эффективной работы с очень большими репозиториями кода. В первую очередь она является консольной программой. Mercurial является распределенной (децентрализованной) системой контроля версий. Рабочий процесс выглядит следующим образом: На личном компьютере создается новый репозиторий (путем клонирования существующего репозитория, создания нового и т. п.); В рабочей директории данного репозитория изменяются/добавляются/удаляются файлы; Выполняется фиксация (commit) изменений в данный репозиторий (то есть в локальный репозиторий на личном компьютере); Шаги 2 и 3 повторяются столько раз, сколько необходимо; При необходимости производится синхронизация изменений с другими репозиториями: забираются (pull) чужие наборы изменений и/или отдаются (push) собственные. То есть вся повседневная работа происходит в локальном репозитории, а когда возникает необходимость, производится отправка результатов своей работы в один или несколько других репозиториев. Количество шагов при работе с отдаленными репозиториями можно сократить, если настроить Mercurial на автоматическую отправку изменений в другие репозитории при выполнении фиксации. Управление изменениями кода: GitРаспределенная система контроля версий файлов. Система спроектирована как набор программ, специально разработанных с учётом их использования в скриптах. Это позволяет удобно создавать специализированные системы контроля версий на базе Git или пользовательские интерфейсы. Например,Cogito является именно таким примером оболочки к репозиториям Git, а StGit использует Git для управления коллекцией исправлений (патчей). Git поддерживает быстрое разделение и слияние версий, включает инструменты для визуализации и навигации по нелинейной истории разработки. Как иDarcs, BitKeeper, Mercurial, Bazaar и Monotone, Git предоставляет каждому разработчику локальную копию всей истории разработки, изменения копируются из одного репозитория в другой. Удалённый доступ к репозиториям Git обеспечивается git-daemon, SSH- или HTTP-сервером. TCP-сервис git-daemon входит в дистрибутив Git и является наряду с SSH наиболее распространённым и надёжным методом доступа. Метод доступа по HTTP, несмотря на ряд ограничений, очень популярен в контролируемых сетях, потому что позволяет использовать существующие конфигурации сетевых фильтров. Интеграция программных компонентов в рамках систем: способы и механизмы интеграцииВ правильности материала не уверен Интеграция слияниемИнтеграция слиянием включает разрешение параллельных изменений, выполненных разными членами команды в общих файлах и компонентах. В этом случае множество людей параллельно модифицируют один и тот же набор рабочих продуктов системы. Таким образом, возникает необходимость в комбинации, или, в терминологии ClearCase, слиянии этих изменений. В некоторых случаях этот процесс может быть автоматизирован применением инструментов, понимающих структуру файлов. В других случаях слияние должно выполняться вручную (наа пример, если есть конфликтующие изменения). Должно быть ясно, что интеграа ция слиянием требует определенных знаний об изменениях, внесенных в проо граммную систему. Вдобавок в программу могут быть внесены дополнительные изменения в процессе интеграции слиянием (например, изменения, необходимые для разрешения конфликтов слияния). Интеграция сборкойИнтеграция сборкой включает комбинирование базовых линий программных компонентов в более крупные части общей системы. Унифицированный процесс Rational определяет интеграцию как «деятельность по разработке программного обеспечения, в котором отдельные компоненты комбинируются в исполняемое целое. В отличие от интеграции слиянием интеграция сборкой не приводит к модификации исходного кода; она просто собирает вместе кусочки мозаики частей программной системы (в надежде, что они подойдут друг к другу). Интеграция сборкой может происходить во время построения, выполнения либо того и другого. При сборке времени построения (builddtime assembly) собираются вместе два набора исходных компонентов, компилируются, а затем компонуются для формирования тестируемой выполняемой программы. При сборке времени выполнения (runtime assembly) вы копируете набор предварительно собранных объектов в среду времени выполнения, которая затем может быть исполнена. Набор динамических библиотек (DLL) двух различных программных компонентов может служить хорошим примером интеграции времени выполнения. Тип интеграции и количество ее уровней в основном определяются масштабом программной системы и численностью команды разработчиков. Решения интеграции зависят от того, организована ли команда вокруг архитектуры или вокруг функций (см. раздел «Организация масштабной многопроектной разработки» в главе 7). На определенном уровне система, имеющая четко определенную программную архитектуру, обязательно требует интеграции сборкой. Монолитные системы с большей вероятностью требуют интеграции слиянием на всех уровнях, вплоть до наивысшего. Интеграция программных компонентов в рамках систем: синхронное и асинхронное взаимодействие (прямое обращение против очереди)При описании взаимодействия между элементами программных систем инициатор взаимодействия, т.е. компонент, посылающий запрос на обработку, обычно называется клиентом, а отвечающий компонент, тот, что обрабатывает запрос — сервером. "Клиент" и "сервер" в этом контексте обозначают роли в рамках данного взаимодействия. В большинстве случаев один и тот же компонент может выступать в разных ролях — то клиента, то сервера — в различных взаимодействиях. Синхронным (synchronous) называется такое взаимодействие между компонентами, при котором клиент, отослав запрос, блокируется и может продолжать работу только после получения ответа от сервера. По этой причине такой вид взаимодействия называют иногда блокирующим (blocking). Обычное обращение к функции или методу объекта с помощью передачи управления по стеку вызовов является примером синхронного взаимодействия Синхронное взаимодействие достаточно просто организовать, и оно гораздо проще для понимания. Код программы клиентского компонента, описывающей синхронное взаимодействие, устроен проще — его часть, отвечающая за обработку ответа сервера, находится непосредственно после части, в которой формируется запрос. В силу своей простоты синхронные взаимодействия в большинстве систем используются гораздо чаще асинхронных. Вместе с тем, синхронное взаимодействие ведет к значительным затратам времени на ожидание ответа. Это время часто можно использовать более полезным образом: ожидая ответа на один запрос, клиент мог бы заняться другой работой, выполнить другие запросы, которые не зависят от еще не пришедшего результата. Поскольку все распределенные системы состоят из достаточно большого числа уровней, через которые проходят практически все взаимодействия, суммарное падение производительности, связанное с синхронностью взаимодействий, оказывается очень большим. Наиболее распространенным и исторически первым достаточно универсальным способом реализации синхронного взаимодействия в распределенных системах является удаленный вызов процедур (Remote Procedure Call, RPC). Его модификация для объектно-ориентированной среды называется удаленным вызовом методов (Remote Method Invocation, RMI). Удаленный вызов процедур определяет как способ организации взаимодействия между компонентами, так и методику разработки этих компонентов. В рамках асинхронного (asynchronous) или неблокирующего (non blocking) взаимодействия клиент после отправки запроса серверу может продолжать работу, даже если ответ на запрос еще не пришел. Примером асинхронного взаимодействия является электронная почта. Другой пример — распространение сообщений о новостях различных видов в соответствии с имеющимся на текущий момент реестром подписчиков, где каждый подписчик определяет темы, которые его интересуют. Асинхронное взаимодействие позволяет получить более высокую производительность системы за счет использования времени между отправкой запроса и получением ответа на него для выполнения других задач. Другое важное преимущество асинхронного взаимодействия — меньшая зависимость клиента от сервера, возможность продолжать работу, даже если машина, на которой находится сервер, стала недоступной. Это свойство используется для организации надежной связи между компонентами, работающей, даже если и клиент, и сервер не все время находятся в рабочем состоянии. Чаще всего асинхронное взаимодействие реализуется при помощи очередей сообщений. При отправке сообщения клиент помещает его во входную очередь сервера, а сам продолжает работу. После того, как сервер обработает все предшествующие сообщения в очереди, он выбирает это сообщение для обработки, удаляя его из очереди. После обработки, если необходим ответ, сервер создает сообщение, содержащее результаты обработки, и кладет его во входную очередь клиента или в свою выходную. |