Вопросы с ответами(2008-2009).doc. Назовите цель разбиения исходных данных программ на классы эквивалентности. Приведите пример выделения классов эквивалентности для какойлибо задачи (в виде дерева разбиения)
 Скачать 456.5 Kb. Скачать 456.5 Kb.
|

|
32. Этапы жизненного цикла (ЖЦ) программных продуктов (ПП). Схема ЖЦ ПП.* Анализ Проектирование Программирование Тестирование и отладка Изготовление Эксплуатация и сопровождение  Эксплуатация и сопровождение Тестирование и отладка Программирование Проектирование Анализ 33. Поэтапная модель жизненного цикла программных продуктов.* 34. Основные положения ГОСТ 19-701-90.* В схемах проектов ПО согласно ГОСТ используются 4 вида символов: символы данных, символы процесса, символы линий и специальные символы. Символы данных: основные – данные, запоминаемые данные; специфические – оперативное запоминающее устройство, запоминающее устройство с последовательной выборкой (ЗУПВ), запоминающее устройство с прямым доступом (ЗУПД), документ, карта, бумажная лента, дисплей. Символы процесса: основные – процесс; специфические – предопределённый процесс, ручная операция, подготовка, решение, параллельные действия, граница цикла. Символы линий: основные - линия; специфические – передача управления, канал связи, пунктирная линия. Специальные символы: соединитель, терминатор, комментарий, пропуск. 35. Функциональное и структурное тестирование программ: цели, отличия стратегий, рекомендации по применению.* Структурное тестирование(белого ящика) применяют на ранних стадиях кодирования и тестирования для выявления и устранения в основном алгоритмических ошибок. Функциональное тестирование(черного ящика) применяют на более поздних стадиях тестирования для выявления и устранения ошибок интерфейса, а также некорректных и отсутствующих функций обработки данных. 36. Этапы тестирования программ. Стадии тестирования в процессе разработки программного обеспечения. Методы, используемые на каждой стадии.* В тестирование входят следующие этапы: а) постановка задачи для теста, б) проектирование теста, в) написание тестов, г) тестирование тестов, д) выполнение тестов, е) изучение результатов тестирования. Стадии: 1) автономное тестирование компонентов программного обеспечения (методы ручного контроля, покрытия операторов, покрытия решений, покрытия условий, комбинаторного покрытия). 2) комплексное тестирование разрабатываемых программ (восходящее и нисходящее тестирование). 3) системное или оценочное тестирование на соответствие основным критериям качества. 37. Ручной контроль как метод тестирования.* * Ручной контроль используют на ранних этапах разработки. Различают статический и динамический подходы к ручному контролю. При статическом подходе анализируют структуру, управляющие и информационные связи программы, ее входные и выходные данные. При динамическом подходе выполняют ручное тестирование, т.е. вручную моделируют процесс выполнения программы на заданных исходных данных. Исходными данными для таких проверок являются: тех. задание, спецификация, структурная и функциональная схемы программного продукта, схемы отдельных компонентов, а на более поздних этапах – алгоритмы и тексты программ, а также тестовые наборы данных. 38. Методы структурного тестирования. Общий недостаток методов.* //белый ящик 1 - метод покрытия решений (переходов), 2 - метод покрытия операторов, 3 - метод покрытия условий, 4 - метод комбинаторного покрытия условий. Применяются при тестировании логики программного модуля. Для применения этих методов на практике структура программы должна быть известной. 39. Методы функционального тестирования. Области применения.* //черный ящик эквивалентного разбиения анализа граничных значений таблиц решений функциональных диаграмм 40. Основные положения метода эквивалентного разбиения.* а) каждый тест должен включать столько различных входных условий, сколько это возможно, с тем чтобы минимизировать общее число тестов; б) необходимо пытаться разбить входную область программы на конечное число классов эквивалентности так, чтобы можно было предположить, что каждый тест, являющийся представителем некоторого класса, эквивалентен любому другому тесту этого класса. Другими словами, если один тест класса эквивалентности обнаруживает ошибку, то следует ожидать, что и все другие тесты этого класса эквивалентности будут обнаруживать эту ошибку. И наоборот, если тест не обнаруживает ошибки, то следует ожидать, что ни один тест этого класса эквивалентности не будет обнаруживать ошибки. 41. Основные положения метода граничных значений.* Определение: граничные условия это ситуации, возникающие непосредственно на, выше или ниже границ входных и выходных классов эквивалентности. Анализ граничных значений отличается от эквивалентного разбиения в двух отношениях: - выбор любого элемента в классе эквивалентности в качестве представительного при анализе граничных значений осуществляется таким образом, чтобы проверить тестом каждую границу этого класса. - при разработке тестов рассматривают не только входные условия (пространство входов), но и пространство результатов, то есть выходные классы эквивалентности. 42. Пошаговое тестирование модульных программ. Достоинства и недостатки подходов.* 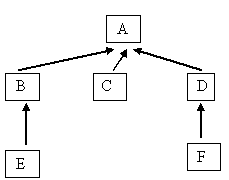 Методика восходящего тестирования включает следующие щаги: Сначала тестируются ‘листья’ дерева структуры программы, т.е. модули Е,C,F. Поскольку это вызываемые программы, то для их тестирования программируются драйверы. В его функции входит формирование тестовых данных для отлаживаемого модуля и передача ему управления (вызов модуля). Затем аналогично тестируются модули вышележащего уровня совместно с уже оттестированными модулями нижележащего уровня. Применительно к рассматриваемому нами примеру проектируются драйверы для тестирования пар B-E и D-F. Пошаговый процесс продолжается до тех пор, пока не будет включен в процесс тестирования последний модуль. Для нашего примера это будет модуль А. Для его тестирования совместно с вызываемыми программами нижележащего уровня драйвер разрабатывать не требуется. Альтернативное нисходящее тестирование состоит из следующих действий: Тестирование начинается с вызывающего модуля программы. Для модулей нижележащего уровня (вызываемых) программируются так называемые ‘заглушки’. После проверки ‘корня’ дерева структуры комплексной программы переходят к тестированию нижележащих модулей. Причем, формализованной процедуры подключения к вызывающему модулю нижележащих вызываемых модулей не существует. Единственное ограничение, которым руководствуются при выборе очередного претендента на тестирование, заключается в том, что этот модуль должен вызываться уже оттестированным модулем вышележащего уровня. Если очередной тестируемый модуль вызывает модули еще нижележащего уровня, то аналогично пункту а) для нижележащих модулей программируются ‘заглушки’ Процесс тестирования продолжается до тех пор, пока не будет оттестирован последний модуль из ‘листьев’ дерева структуры программы. 43. Классификация и проявление ошибок программирования.* 44. Методы отладки программ.* 1) метод индукции; 2) метод дедукции. Название методов напоминают о криминалистике и не напрасно, ибо есть аналогия между этими методами и расследованием преступления. Метод индукции включает: 1) определение данных тестирования, имеющих отношение к ошибке; 2) анализ от частного к общему позволит выявить закономерности в данных пункта 1); 3) в результате анализа (п.2) выдвигается гипотеза о причине ошибки; 4) для подтверждения гипотезы 3 разрабатывается один или больше тестов, которые должны либо подтвердить, либо опровергнуть гипотезу; если дополнительные тесты подтверждают гипотезу, можно приступать к исправлению ошибки, а вот если не подтверждают, то требуется в лучшем случае возврат к п.3, а в худшем - к п.2. Альтернативный метод дедукции заключается в: 1) перечисление возможных причин или гипотез: 2) использование данных тестирования для исключения некоторых возможных причин; 3) уточнение выбранной наиболее вероятной гипотезы, возможно с использованием дополнительных тестов: 4) доказательство выбранной гипотезы совпадает с п.4 и п.5 метода индукции. 45. Методы получения дополнительной информации об ошибках.* Наиболее распространенными и наименее эффективными для отладки являются так называемые методы ‘грубой силы’. К ним относят: 1) отладку с использованием дампа памяти; 2) отладку с использованием операторов печати по всей программе; 3) отладку с использованием автоматических средств. Дампы памяти практически невозможно использовать при программировании на языке высокого уровня, поэтому на этом способе отладки останавливаться не будем Расстановка печатей в программе бессистемно вряд ли может ускорить отладку. Для системной расстановки нужны четкие представления о структуре алгоритма (схема работы программы или блок-схема). Серьезным недостатком этого метода отладки является тот факт, что печати, вставляемые в программу, изменяют ее, вследствие чего могут послужить дополнительным источником ошибок. 46. Общая методика отладки программ.* 1й этап – изучение проявления ошибки. Результатом выполнения этапа должна быть локализация ошибки. При этом можно использовать методы индукции и дедукции и средства получения дополнительной информации об ошибке. 2й этап – выполняется, если произошло “зависание” или не удалось локализовать ошибку, используя методы 1го этапа 3й этап – определение причины ошибки. После локализации ошибки выдвигаются версии о ее природе. Эти версии необходимо проверить, используя отладочные средства для просмотра последовательности операторов и значений переменных 4й этап – исправление ошибки. Здесь нужно помнить 1 вещь – небрежное исправление может породить новые ошибки. 5й этап – повторное тестирование 47. Структуры данных: определение, механизмы агрегирования данных, общие свойства структур данных.* Структура данных – это совокупность элементов данных, между которыми существуют некоторые отношения, причем элементами данных могут быть простые данные и структуры данных. Структуру данных можно определить, как S = (D,R), где D- множество элементов данных, R-множество отношений (связей) между элементами данных. Структуру можно изображать в виде графа, при этом элементам данных соответствуют вершины, а связям или отношениям – ориентированные или неориентированные ребра. В зависимости от отсутствия или наличия явно заданных связей между элементами данных различают структуры несвязные (вектор, массив, строка, стек, очередь) и связные (списки). Важный признак структуры – ее изменчивость. Под изменчивостью будем понимать изменение числа элементов структуры и (или) связей между элементами структуры. По этому признаку различают структуры статические, полустатические и динамические. В зависимости от характера взаимного расположения элементов в памяти ЭВМ структуры делят на структуры данных с последовательным расположением элементов в памяти (вектор, массив, стек, очередь) и структуры с произвольным распределением – (односвязные, двусвязные, ассоциативные списки). 48. Статические структуры данных: вектор и массив. Функции линеаризации.* Вектор – конечное упорядоченное множество простых данных или скаляров одного и того же типа. Элементы вектора находятся между собой в отношении непосредственного следования. В памяти ЭВМ элементы вектора представляются последовательностью одинаковых по длине участков памяти, как правило, расположенных в порядке следования элементов в группе. Важнейшая операция над вектором – доступ к заданному элементу. Кроме того, над вектором можно выполнять операции определения верхней и нижней границ индекса. По сути эти операции дают описание вектора. Массивом называют такой вектор, каждый элемент которого вектор. В свою очередь элементы вектора “вектора массива” могут быть вектором (3-х и более мерные массивы). Процесс последовательного перехода к элементам вектора рано или поздно должен завершиться на скалярном элементе некоторого типа данных, причем этому типу должны соответствовать все скалярные элементы массива. Поэтому может быть более точным является скалярное определение массива: к-мерным массивом называется конечное упорядоченное множество (к-1) мерных массивов, все элементы которых принадлежат одному и тому же типу. При к=1 получаем вектор. 49. Статические структуры данных: запись и таблица. Физическая структура, доступ к элементам. * Запись - конечное упорядоченное множество элементов, характеризующихся в общем случае различным типом данных. Элементы записи называются полями. Другое определение записи – это обобщенный вектор, при котором не требуется однотипность или однородность элементов. Поскольку запись можно рассматривать как обобщение понятия вектор, то для записи характерной операцией является доступ к полям записи. Аналогично вектору поля записи в памяти ЭВМ располагаются последовательно. Как уже упоминалось выше, поля записи именуются и доступ к ним осуществляется путем указания имени записи и имени поля этой записи. Для организации доступа в ЭВМ, как правило, создается дескриптор записи, в котором указывается смещение начала поля записи относительно начала записи в целом. Например, запись: ЗАП личный N студента, целое 2-значное; ФИО – символьное 15 – значное; Аббревиатура факультета – символьное 4-значное, может иметь следующий дескриптор: ЗАП Личный номер студента 0 ФИО 2 (целое занимает 2 байта) Факультет 17 (1-символ – 1байт) Таблица - конечное упорядоченное множество записей, имеющих одну и ту же организацию. Наиболее распространена форма таблицы, в которой элемент представляет собой одноуровневую запись, состоящую из упорядоченной последовательности полей, имеющих в общем случае различный размер и соответствующих различным типам простых данных. Логическая структура представляется в виде последовательности расположенных друг под другом строчек одинаковой длины представляющих элементы таблицы и разделенных на графы. Обычно одно из полей всех элементов таблицы отводится для хранения ключа, являющегося уникальным для каждого записи таблицы. Иногда ключом записи таблицы является некоторая совокупность полей записи. Тогда говорят, что ключ записи – сцепленный. Иногда таблицы определяют в виде совокупности (k,v), где k-поле ключа (сцепленного или простого), v- набор остальных полей записи (неключевых). 50. Статическая структура данных: файл. Доступ к записям. Логическая структура магнитного диска.* Одной из важнейших структур данных является файл – конечное множество записей, расположенных на некотором устройстве внешней памяти. Элементы файла – записи. При последовательном доступе осуществляется автоматическое блокирование и деблокирование логических записей. Для этого в ОП создаются одна или несколько буферных областей , в которых и происходит блокирование и деблокирование записей. При прямом доступе обращение производится непосредственно к нужному блоку данных. Как правило, поиск осуществляется по значению ключа (на логическом уровне). Чтобы найти запись на физическом уровне, нужно по значению ключа определить физический адрес записи. Эту процедуру возлагают либо на функции ОС, либо программист реализует эту процедуру в своей программе обработки, что, несомненно, усложняет программу обработки. На каждом диске можно выделить две области - системную и данных. В системной области диска (начинается с 0 дорожки, 0 стороны, сектора 1) размещены 3 зоны, содержащие: главную загрузочную запись (MRB – Main Boot Record), в которой описывается конфигурация диска: какой раздел (логический диск) является системным, сколько разделов на этом диске и какого они объема; таблицу размещения файлов FAT (File Allocation Table) , в которой отмечаются кластеры, выделенные для файла. Кластеры, в которых размещены физически последовательные записи файла, имеют последовательные номера. Эта таблица является очень важной, при ее порче чтение записей файла становится невозможным, поэтому такая таблица для каждого файла в системной области внешней памяти дублируется; корневой каталог диска - список файлов и/или подкаталогов с их параметрами: расширением, размером в байтах,, датой и временем создания и номером начального кластера. В этом начальном и следующих кластерах в таблице FAT указываются номера следующих кластеров, занимаемых файлом. Последний кластер файла имеет номер-код FFFF. 51. Полустатические структуры данных.* Полустатические структуры данных- это последовательные линейные списки с переменной длиной, ограниченной фиксированной максимальной величиной и с ограниченным доступом. К таким структурам относятся стеки и очереди. 52. Динамические структуры данных: линейные списки.* Динамическая структура имеет следующие основные признаки: 1.Непостоянство и непредсказуемость размера (числа элементов) структуры в процессе ее обработки. Число элементов динамической структуры может изменяться от 0 до некоторого значения, определяемого спецификой задачи или доступным размером машинной памяти. 2. Отсутствие физической смежности элементов структуры в физической памяти. Логическая последовательность элементов задается в явном виде с помощью одного или нескольких указателей или связок, хранящихся в самих элементах. Следовательно, память, занимаемая динамической структурой не является непрерывной и может быть хаотически разработана в области памяти. Часто динамические структуры физически представляются в форме связных списков. Связный список – такая структура, элементами которой служат записи с одним и тем же форматом, связанные друг с другом с помощью указателей, хранящихся в самих элементах списка. |