Описательная статистика (ручной расчёт). Описательная статистика
 Скачать 366 Kb. Скачать 366 Kb.
|

|
ОПИСАТЕЛЬНАЯ СТАТИСТИКА. Цель занятия - максимально развить интуитивное и практическое представление об анализе данных, статистической обработке эксперимента, не предполагая наличия у них специальной подготовки. Познакомить с культурой анализа данных. Статистика позволяет компактно описать данные, понять их структуру, провести классификацию, увидеть закономерности в хаосе случайных явлений. Первый раздел математической статистики – описательная статистика – предназначен для представления данных в удобном виде и описания информации в терминах математической статистики и теории вероятностей. Медицинская статистика - это отраслевая статистика, комплекс методов прикладной статистики, которые применяются в научной, практической медицине и здравоохранении. Основные задачи медицинской статистики: - статистика рождаемости и смертности; - статистика заболеваемости; - статистика деятельности учреждений здравоохранения. Вместе описательная и аналитическая статистики решают следующую задачу: - сбор данных и описание их в удобном для статистической обработки виде; - обработка результатов методами теоретической (общей ) статистики; - анализ полученных результатов, прогнозирование, выработка оптимальных решений. Основной величиной в статистических измерениях является единица статистической совокупности. Единица статистической совокупности характеризуется набором признаков или параметров. Значения каждого параметра или признака могут быть различными и в целом образовывать ряд случайных значений x1, х2, …, хn. Переменная - это параметр измерения, который можно контролировать или которым можно манипулировать в исследовании. Так как значения переменных не постоянны, нужно научиться описывать их изменчивость. Для этой цели существует описательная или дескриптивная статистика. Идея описательной статистики очень проста: вместо того чтобы рассматривать все значения переменной, а их может быть очень много (тысячи и миллионы), вначале стоит просмотреть описательные статистики. Они дают общее представление о значениях, которые принимает переменная. Остановимся на основных понятиях описательной статистики. Минимум и максимум — это минимальное и максимальное значения переменной. Среднее ( 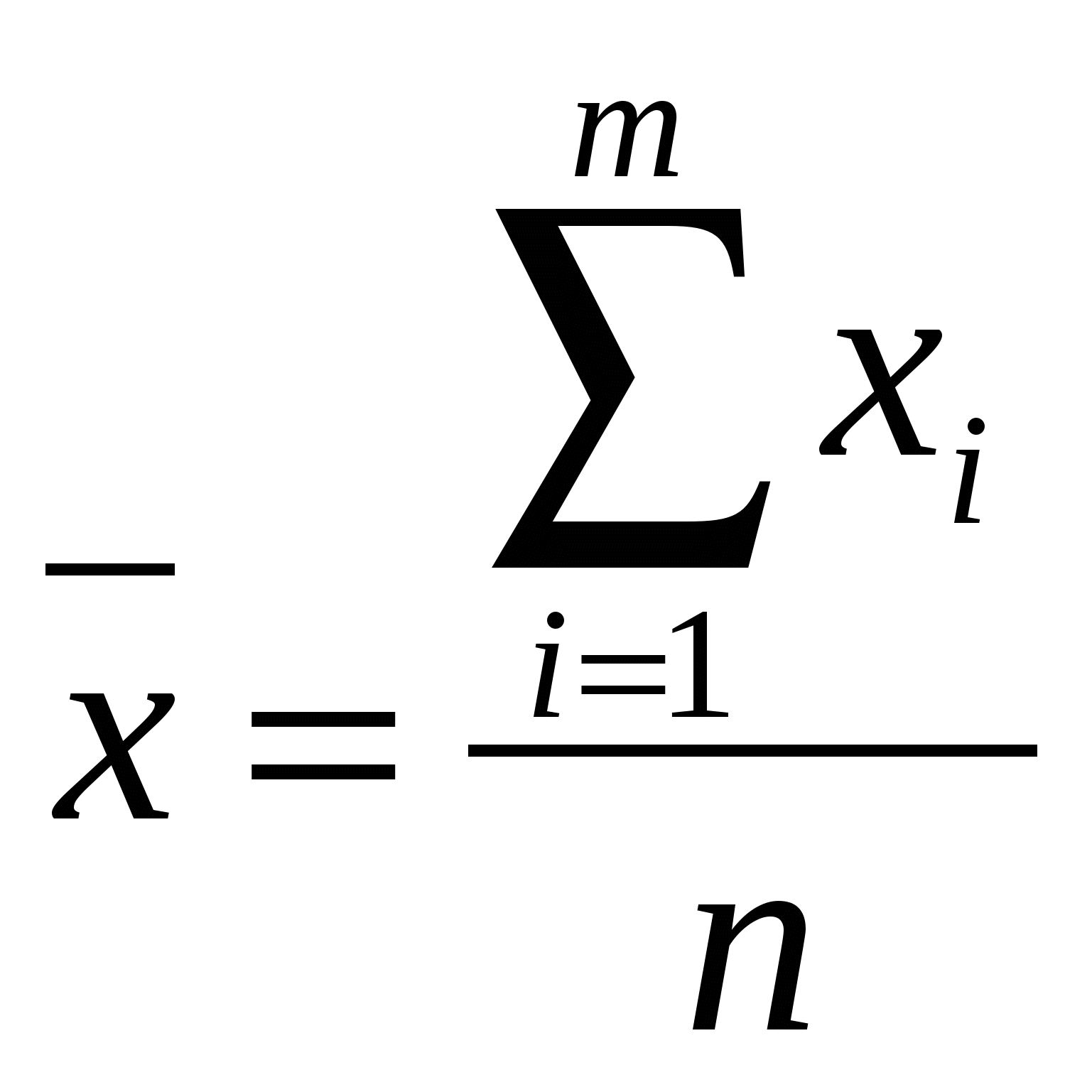 (1) (1)Среднее линейное отклонение ( 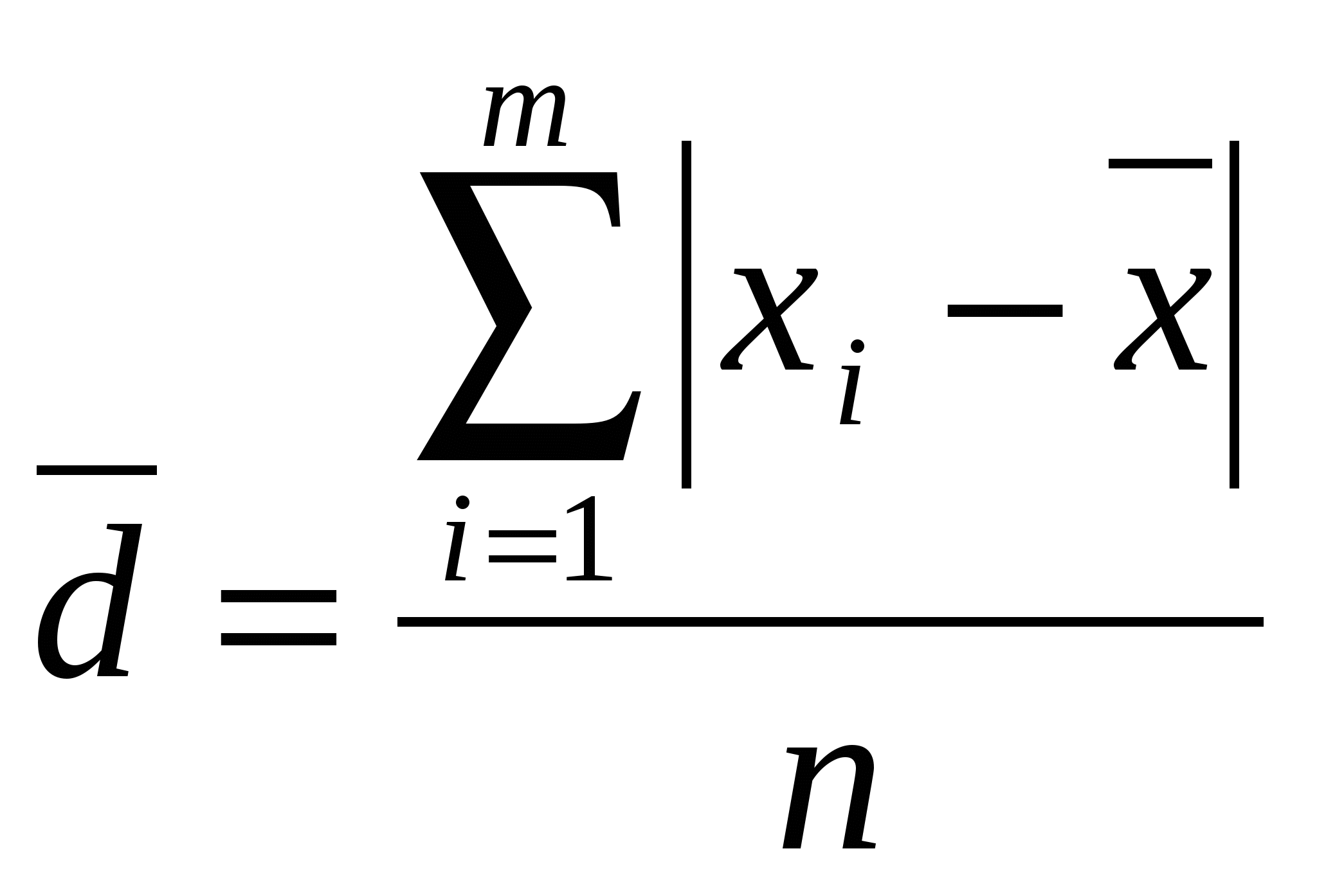 (2) (2)Дисперсия Дисперсия бывает двух видов: 1) простая дисперсия используется для несгруппированных данных и определяется по формуле: 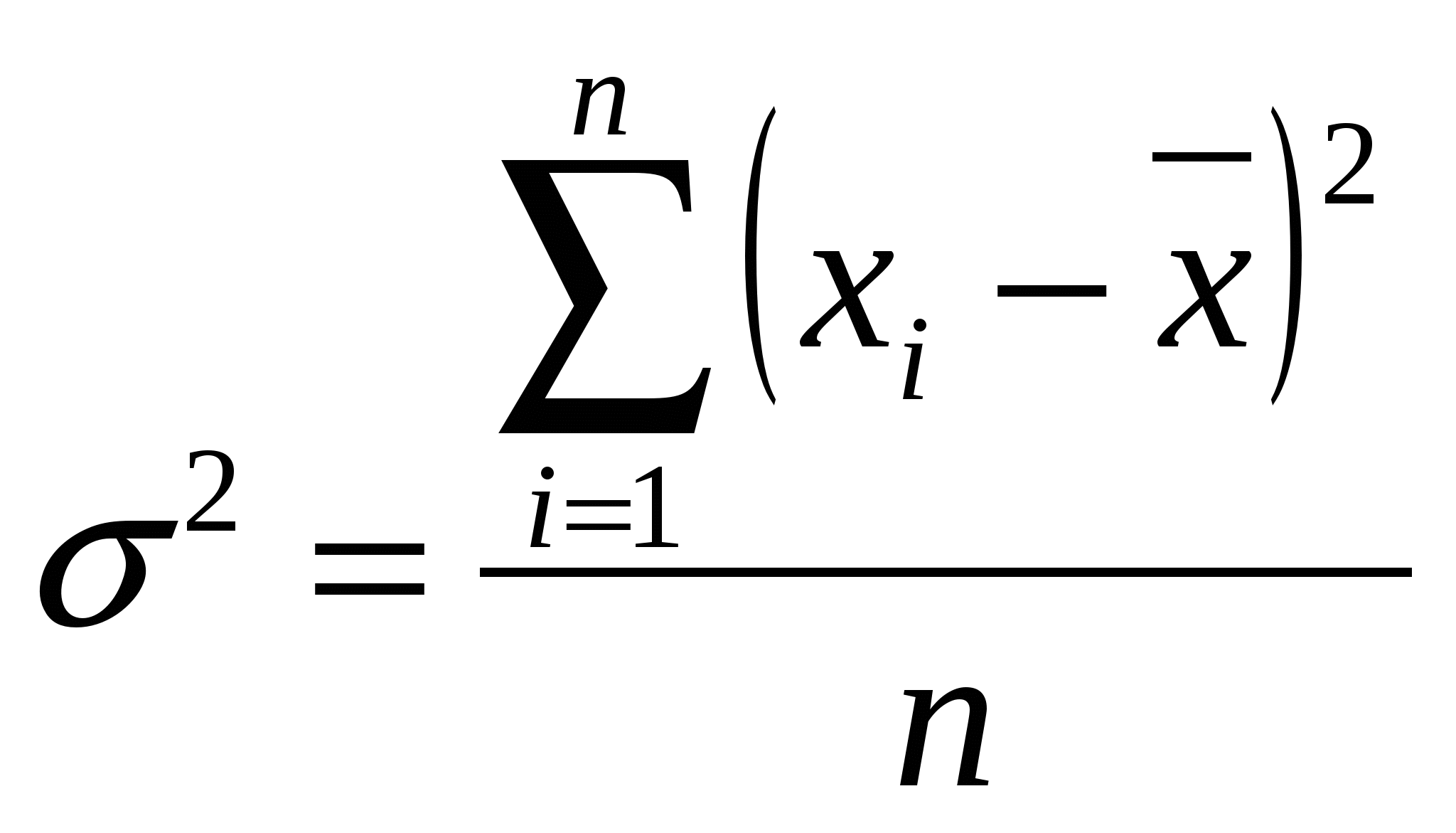 (3) (3)где Более удобно вычислять дисперсию по формуле: которая получается из основной путем несложных преобразований. В этом случае средний квадрат отклонений равен средней из квадратов значений признака минус квадрат средней. 2) взвешенная дисперсия применяется в случае вариационного ряда и вычисляется по формуле: 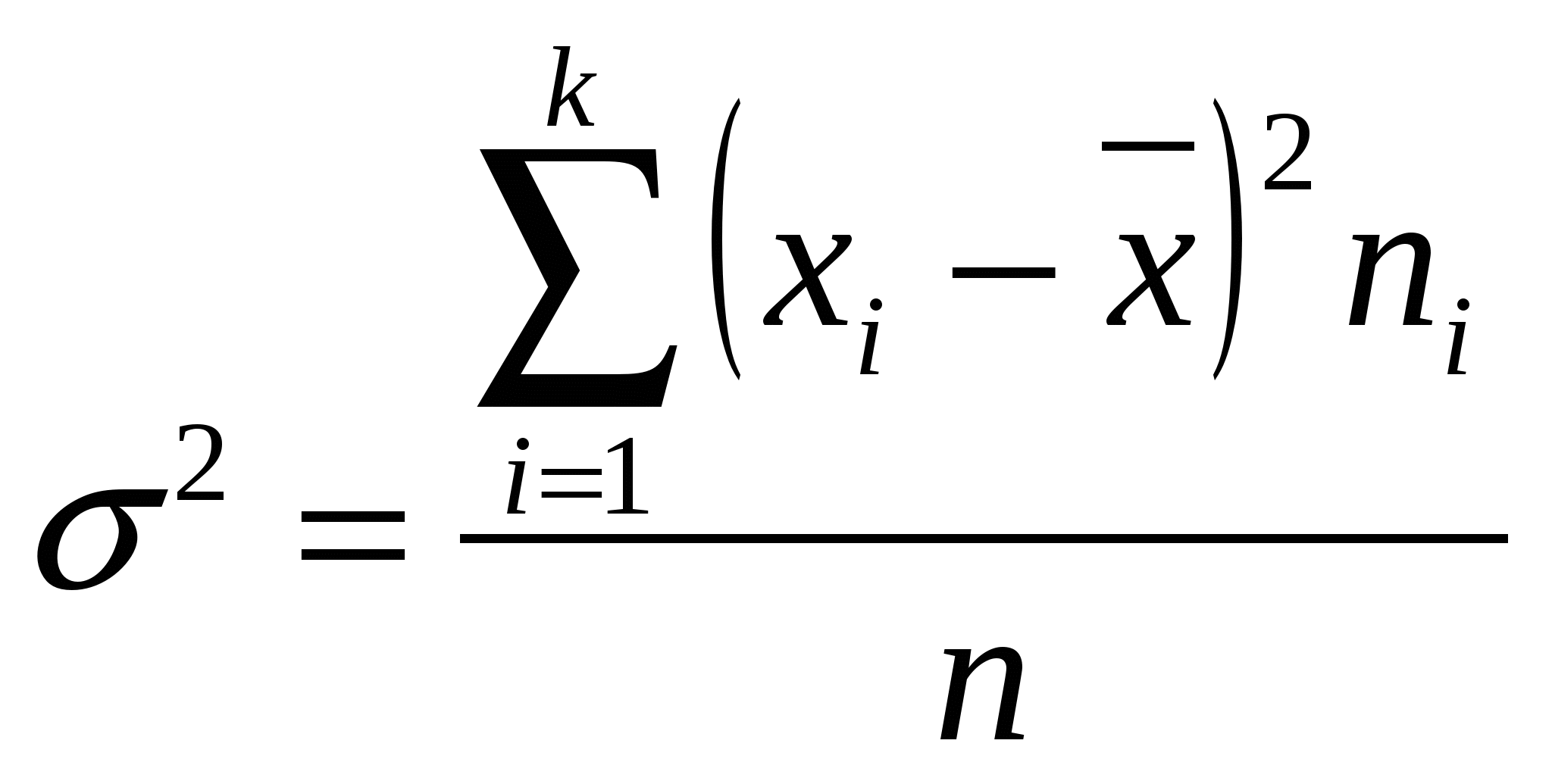 (5) (5)где Дисперсия меняется от нуля до бесконечности. Крайнее значение 0 означает отсутствие изменчивости, когда значения переменной постоянны. Чтобы использовать дисперсию дл анализа данных из нее извлекают квадратный корень. Получается так называемое среднеквадратическое отклонение. Чем выше дисперсия или стандартное отклонение, тем сильнее разбросаны значения переменной относительно среднего. Часто стандартное отклонение — более удобная характеристика, т.к измерена в тех же единицах, что исходная величина. Медиана разбивает выборку на две равные части. Половина значений переменной лежит ниже медианы, половина — выше. Медиана дает общее представление о том, где сосредоточены значения переменной, иными словами, где находится ее центр. Мода представляет собой максимально часто встречающееся значение переменной (иными словами, наиболее «модное» значение переменной), например, популярная передача на телевидении, модный цвет платья или марка автомобиля и т. д. Рассмотрим нахождение основных показателей описательной статистики на примере. Задача 1. Имеются данные по группе из 20 студентов. Рассчитать среднее значение, среднее линейное отклонение, построить интервальный ряд распределения, и изучить его дисперсию.
1. По формуле (1) вычисляем среднюю величину роста студентов: 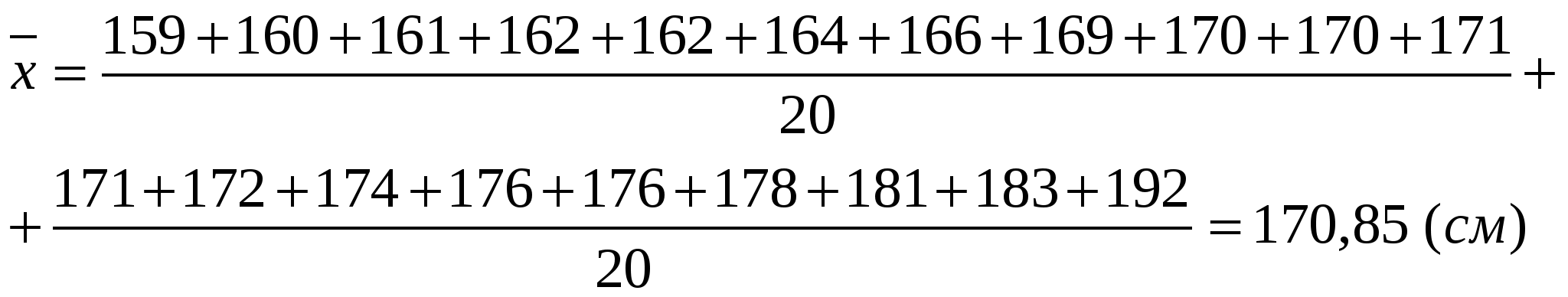 Вывод: средний рост студентов равен 170,85 см. 2. По формуле (2) вычисляем среднее линейное отклонение: 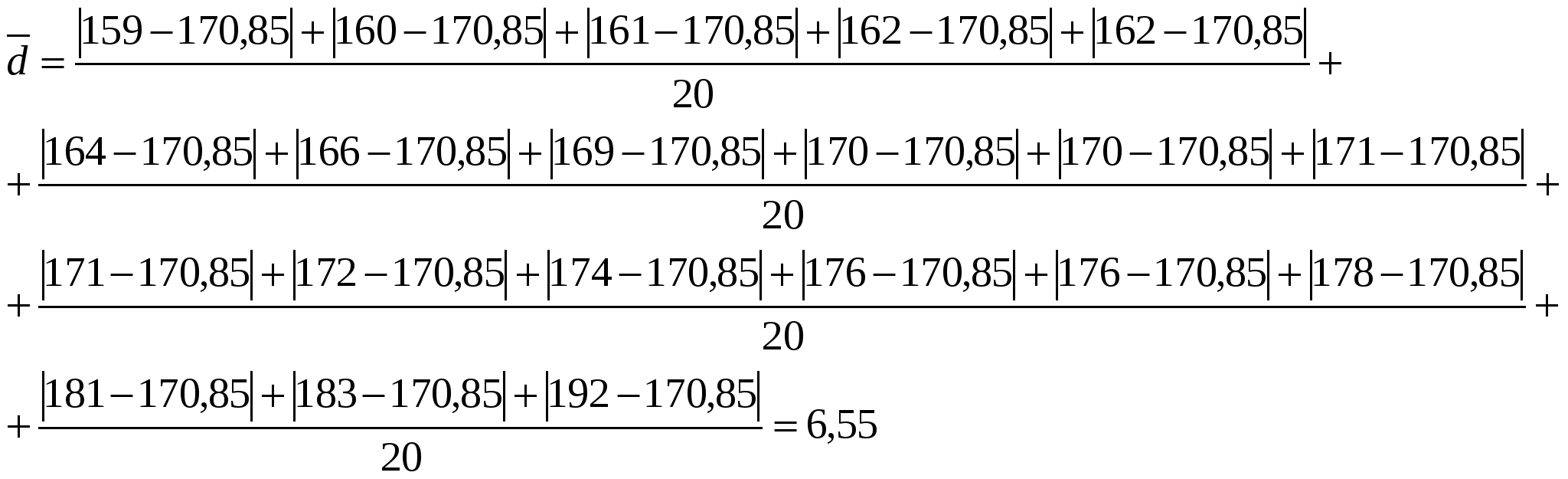 Вывод: разброс значений совокупности данных вокруг среднего значения, равен 6,55 см. 3. По формуле (3) найдём значение дисперсию.  4.Извлекая квадратный корень их дисперсии, находим среднеквадратическое отклонение. Вывод: сравнив полученное значение среднеквадратического отклонения со значением среднего линейного отклонения, рассчитанного в п.2, можно сделать вывод, что среднеквадратическое отклонение является более точным показателем меры рассеяния данных, чем среднее линейное отклонение. Построим интервальную группировку. 1. Определяем количество интервалов по формуле: В нашем случае 2. Определим шаг интервала по формуле: В нашем случае 3. 3. Составляем интервальную группировку в виде таблицы.
Для дальнейших расчётов строим вспомогательную таблицу.
Частота встречаемости ( абсолютная частота ) – число, показывающее, сколько раз объект с данным числовым значением признака встречается в совокупности или ее интервале. Абсолютною частоту обозначают символом ni ( µi ).  Задача №1 В таблице приведены результаты измерения частоты пульса у 41 некурящих студентов-медиков в возрасте 20 лет:
Пример. Исследуется случайная величина Х‒ число заболевших гриппом в течение одних суток в некотором городе N. Получены данные за первые 150 суток года Таблица 1
|