Лабораторная работа по Алгоритмам и структурам данных. Лабораторная работа №1. Отчет по лабораторной работе 1 по дисциплине Алгоритмы и структуры данных Тема Множества Студент гр. 9891 Преподаватель
 Скачать 130.71 Kb. Скачать 130.71 Kb.
|

1 2 МИНОБРНАУКИ РОССИИ Санкт-Петербургский государственный электротехнический университет «ЛЭТИ» им. В.И. Ульянова (Ленина) Кафедра вычислительной техники отчет по лабораторной работе №1 по дисциплине «Алгоритмы и структуры данных» Тема: Множества
Санкт-Петербург 2021 Цель работы: Сравнительное исследование четырёх основных способов хранения множеств в памяти ЭВМ. Необходимо разработать программу для обработки множеств четырьмя способами (Преставление в виде массива, списка, массива битов и машинного слова). И измерить время работы алгоритма для каждого из четырех способов представления. Содержание: Представление множества в виде массива 4 Представление множества в виде списка 4 Представление множества отображением на универсум 5 Представление множества в виде машинного слова 5 Алгоритм автоматической генерации 6 Примеры автоматической генерации 7 Вывод 7 Приложение А. Код программы 8 Представление множества в виде массива Словесное описание алгоритма Изначально путем ввода символов с клавиатуры задаются 4 множества (setA,…, setD) из которых в последствии будет формироваться множество setE. После того как были сформированы множества, начинается обработка множеств, то есть получение множества setE из введенных множеств по следующей формуле: 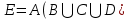 . Для этого сначала производим объединение множеств setB, setC, setD в одно (в программе оно названо setTemp). После этого производим посимвольное сравнение множества setA и объединение множеств setB, setC, setD. Для этого используем функцию strrchr (так как мы работает с си-строками). Если символ, который есть в множестве setА, но его нет в объединенном множестве setB, setC, setD, то функция strrchr возвращает NULL и мы в множество setE записываем символ из множества setA. Продолжаем этот цикл до тех пор пока не переберем все символы из множества A. . Для этого сначала производим объединение множеств setB, setC, setD в одно (в программе оно названо setTemp). После этого производим посимвольное сравнение множества setA и объединение множеств setB, setC, setD. Для этого используем функцию strrchr (так как мы работает с си-строками). Если символ, который есть в множестве setА, но его нет в объединенном множестве setB, setC, setD, то функция strrchr возвращает NULL и мы в множество setE записываем символ из множества setA. Продолжаем этот цикл до тех пор пока не переберем все символы из множества A.При автоматической генерации множеств изменяется только ввод элементов, вместо ручного ввода используется генерация с помощью функции rand. Подробнее о автоматической генерации в пункте 5. Временной результат работы алгоритма О 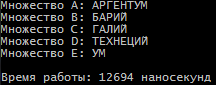 ценим время выполнения алгоритма для множеств мощностью в 8, 5, 5 и 8 элементов. Время работы алгоритма составило 12694 наносекунды или 0,000012694 секунды. ценим время выполнения алгоритма для множеств мощностью в 8, 5, 5 и 8 элементов. Время работы алгоритма составило 12694 наносекунды или 0,000012694 секунды.Представление множества в виде списка Словесное описание алгоритма Изначально путем ввода символов задаются 4 множества setA,…,setD в виде однонаправленного линейного списка (используется функция CreateSet). После того как были сформированы множества, начинается обработка множеств, то есть получение множества setE из введенных множеств по следующей формуле: . Для этого мы поочередно сравниваем элементы множества setA с множествами setB, setC, setD. В случае совпадения элементов в множестве setA и одном из множеств setB, setC или setD мы заменяем в множестве setA совпадающий элемент на цифру 8. После того как мы сравним множество setA со всеми множествами, мы формируем множество setE. Для этого будем записывать в множество setE все элементы множества A за исключением цифры 8.При автоматической генерации множеств изменяется только ввод элементов, вместо ручного ввода используется генерация с помощью функции rand. Подробнее о автоматической генерации в пункте 5. Временной результат работы алгоритма О 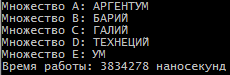 ценим время выполнения алгоритма для множеств мощностью в 8, 5, 5 и 8 элементов. Время работы алгоритма составило 3324608 наносекунды или 0,003324608 секунды. ценим время выполнения алгоритма для множеств мощностью в 8, 5, 5 и 8 элементов. Время работы алгоритма составило 3324608 наносекунды или 0,003324608 секунды.Представление множества отображением на юниверсум Словесное описание алгоритма Изначально создаем массивы битов для множеств A, B, C, D, E (setArrayBitA,…, setArrayBitE) и установим все значения в 0. Также для хранения введенных символов будут использоваться множества setA,…, setD. Также создадим множество setUniversum со значением от А до Я. Теперь после того как множества setA,…, setD заполнены символами, изменим биты в множествах setArrayBitA,…, setArrayBitE. Для этого будем сравнивать множества setA,…, setD с множеством setUniversum пока символ из множеств setA,…, setD не будет равен символу из множества setUniversum. Когда будет найден такой символ, то в множестве setArrayBitA,…, setArrayBitD инвертируем бит с номером, равным порядковому номеру найденного символа в множестве setUniversum. Повторяем эти действия пока все символы из множеств setA,…, setD не будут отражены в массивы битов. После этого будем обрабатывать множество в соответствии с заданной формулой: . Для этого сравним битовые массивы setArrayBitA,…, setArrayBitD с помощью логических операций и запишем результат в множество setArrayBitE. Это и будет искомое множество.При автоматической генерации множеств изменяется только ввод элементов, вместо ручного ввода используется генерация с помощью функции rand. Подробнее о автоматической генерации в пункте 5. Временной результат работы алгоритма О 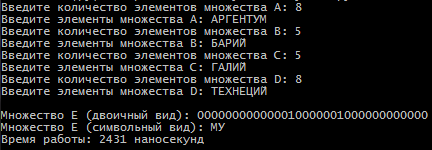 ценим время выполнения алгоритма для множеств мощностью в 8, 5, 5 и 8 элементов. Время работы алгоритма составило 2431 наносекунды или 0,000002431 секунды. ценим время выполнения алгоритма для множеств мощностью в 8, 5, 5 и 8 элементов. Время работы алгоритма составило 2431 наносекунды или 0,000002431 секунды.Представление множества в виде машинного слова Словесное описание алгоритма Для представления множеств в виде машинных слов создадим 4 переменных типа long mwordA,…,mwordD и присвоим им значение 0 (int нам не подходит, так как у нас множество заглавных русских букв требует 33 бита). Создаем множества setA,…,setD типа char, куда будут сохраняться вводимые множества, также создадим множество setUniversum (А,…, Я). После того как мы ввели все множества, преобразуем их в машинные слова. Для этого будем действовать следующим образом. Создадим временную переменную tempword. Далее будем сравнивать множество setA,…,setD с множеством setUniversum, пока не встретим одинаковые символы. Когда появляются равные символы, мы присваиваем биту с номером равным порядковому номеру символа в множестве setUniversum значение 1 в переменной tempword. После этого с помощью побитового ИЛИ присваиваем значение переменной tempword переменной mwordA,…, mwordD. Продолжаем эти действия пока все множества не будут переведены в машинные слова. После этого приступаем к обработке множеств по заданной формуле: . Для чего используем побитовое ИЛИ между множествами mwordB,…,mwordD и записываем результат в mwordEbinary. После этого делаем побитовое ОТРИЦАНИЕ получившегося множества. Далее делаем побитовое И между множествами mwordA и mwodrEbinary и записываем результат в mwodrEbinary, это и будет результирующее множество E.При автоматической генерации множеств изменяется только ввод элементов, вместо ручного ввода используется генерация с помощью функции rand. Подробнее о автоматической генерации в пункте 5. Временной результат работы алгоритма О 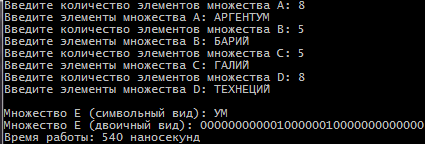 ценим время выполнения алгоритма для множеств мощностью в 8, 5, 5 и 8 элементов. Время работы алгоритма составило 540 наносекунды или 0,000000540 секунды. ценим время выполнения алгоритма для множеств мощностью в 8, 5, 5 и 8 элементов. Время работы алгоритма составило 540 наносекунды или 0,000000540 секунды.Алгоритм автоматической генерации Для автоматической генерации во всех случаях используется фунция rand и вспомогательное множество setUniversum(А,…, Я). С помощью функции rand выбирается произвольное число от 0 до 32 и ему сопоставляется буква из множества setUniversum, которая и присваивается в одно из множеств вместо ручного ввода. А) Автоматическая генерация. Массив. 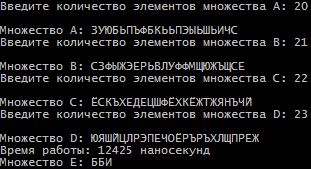 Б) Автоматическая генерация. Список. 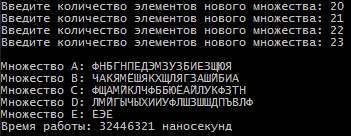 В) Автоматическая генерация. Универсум. 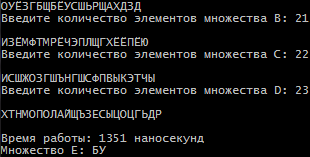 Г) Автоматическая генерация. Машинное слово.  Вывод Исходя из результатов работы программы мы видим, что самая быстрая скорость работы у машинного слова, а самая медленная у списка. Это было ожидаемо, так как побитовые операции значительно быстрее выполняются, чем итерация по списку. Отсюда можно сделать вывод, что если для решения задачи требуется высокая скорость обработки данных, то лучше всего использовать представление в виде машинного слова, хотя оно обладает некоторыми ограничениями, такими как ограниченный размер хранения данных, который ограничивается размером простого типа (int, long и т.д.). Для решения этого ограничения надо будет использовать двойные машинные слова. В случае списка таких проблем нет, мы ограничены только памятью ЭВМ. Приложение А. Код программы #include #include #include #include #include #include using namespace std; void inputLetter(int amount, char* setLetter); void concatenationLetter(char* setSum, char* setLetter_1, char* setLetter_2, char* setLetter_3); void compareAndcopyLetter(char* setLetterA, char* setLetterTemp, char* setLetterE); void compareString(char* setInput, int num); int numA, numB, numC, numD, numE; char temp_1, temp_2; char setElst[256], setAlst[256], setBlst[256]; struct SetNode { char element;}; struct ListSet { SetNode Set; ListSet* next;}; void CreateSet(ListSet** begin); void ShowSet(ListSet* begin); int main(){ setlocale(LC_ALL, "rus"); SetConsoleCP(1251); // Ввод с консоли в кодировке 1251 SetConsoleOutputCP(1251); // Вывод на консоль в кодировке 1251. Нужно только будет изменить шрифт консоли на Lucida Console или Consolas char setUniversum[33] = { 'А','Б','В','Г','Д','Е','Ё','Ж','З','И','Й','К','Л','М','Н','О','П','Р','С','Т','У','Ф','Х','Ц','Ч','Ш','Щ','Ъ','Ы','Ь','Э','Ю','Я' }; int choice = 0; cout << "Меню:" << endl; cout << "1. Массив." << endl; cout << "2. Список" << endl; cout << "3. Массив битов/универсум" << endl; cout << "4. Машинное слово" << endl; cout << "5. Массив. Генерация множества." << endl; cout << "6. Список. Генерация множества." << endl; cout << "7. Массив битов/универсум. Генерация множества." << endl; cout << "8. Машинное слово. Генерация множества." << endl; cout << "Введите цифру, которая соответствует вашему выбору: "; cin >> choice; if (choice == 1) { cout << "Введите количество элементов множества A: "; cin >> numA; cin.ignore(); char* setA = new char[numA + 1]; inputLetter(numA, setA); cout << "Введите количество элементов множества B: "; cin >> numB; cin.ignore(); char* setB = new char[numB + 1]; inputLetter(numB, setB); cout << "Введите количество элементов множества C: "; cin >> numC; cin.ignore(); char* setC = new char[numC + 1]; inputLetter(numC, setC); cout << "Введите количество элементов множества D: "; cin >> numD; cin.ignore(); char* setD = new char[numD + 1]; inputLetter(numD, setD); auto start = chrono::steady_clock::now(); char* setTemp = new char[numB + numC + numD + 1]; concatenationLetter(setTemp, setB, setC, setD); char* setE = new char[numA + 2]; compareAndcopyLetter(setA, setTemp, setE); auto stop = chrono::steady_clock::now(); auto second = chrono::duration_cast<chrono::nanoseconds>(stop - start); cout << "\nМножество A: ";cout << setA << endl; cout << "Множество B: ";cout << setB << endl; cout << "Множество C: ";cout << setC << endl; cout << "Множество D: ";cout << setD << endl; cout << "Множество Е: ";cout << setE << endl; cout << "\nВремя работы: " << second.count() << " наносекунд" << endl; delete[] setA;} if (choice == 2) { ListSet* beginA = NULL; ListSet* endA = NULL; ListSet* beginB = NULL; ListSet* endB = NULL; ListSet* beginC = NULL; ListSet* endC = NULL; ListSet* beginD = NULL; ListSet* endD = NULL; ListSet* beginE = NULL; ListSet* endE = NULL; CreateSet(&beginA); CreateSet(&beginB); CreateSet(&beginC); CreateSet(&beginD); ListSet* tempA = new ListSet; tempA = beginA; ListSet* tempB = new ListSet; tempB = beginB; ListSet* tempC = new ListSet; tempC = beginC; ListSet* tempD = new ListSet; tempD = beginD; cout << "\nМножество А: "; while (beginA != NULL) { cout << beginA->Set.element; beginA = beginA->next;} cout << "\nМножество B: "; while (beginB != NULL) { cout << beginB->Set.element; beginB = beginB->next;} cout << "\nМножество C: "; while (beginC != NULL) { cout << beginC->Set.element; beginC = beginC->next;} cout << "\nМножество D: "; while (beginD != NULL) { cout << beginD->Set.element; beginD = beginD->next;} auto start = chrono::steady_clock::now(); while (beginA != NULL) { while (beginB != NULL) { if (beginB->Set.element == beginA->Set.element) { beginA->Set.element = '8';} beginB = beginB->next;} beginA = beginA->next; beginB = tempB;} beginA = tempA; while (beginA != NULL) { while (beginC != NULL) { if (beginC->Set.element == beginA->Set.element) { beginA->Set.element = '8';} beginC = beginC->next;} beginA = beginA->next; beginC = tempC;} beginA = tempA; while (beginA != NULL) { while (beginD != NULL) { if (beginD->Set.element == beginA->Set.element) { beginA->Set.element = '8';} beginD = beginD->next;} beginA = beginA->next; beginD = tempD;} beginA = tempA; beginD = tempD; int count = 0; while (beginA != NULL) { if (beginA->Set.element != '8') { beginD->Set.element = beginA->Set.element; count++; beginD = beginD->next;} beginA = beginA->next;} beginD = tempD; beginA = tempA; beginB = tempB; beginC = tempC; cout << "\nМножество Е: "; while (count != 0) { cout << beginD->Set.element; beginD = beginD->next; count--;} auto stop = chrono::steady_clock::now(); auto second = chrono::duration_cast<chrono::nanoseconds>(stop - start); cout << "\nВремя работы: " << second.count() << " наносекунд" << endl; } if (choice == 3) { int setArrayBitA[33]; int setArrayBitB[33]; int setArrayBitC[33]; int setArrayBitD[33]; int setArrayBitE[33]; for (int i = 0; i < 33; i++) { setArrayBitA[i] = false; setArrayBitB[i] = false; setArrayBitC[i] = false; setArrayBitD[i] = false; setArrayBitE[i] = false;} char setE[33]; cout << "Введите количество элементов множества A: "; cin >> numA; cin.ignore(); char* setA = new char[numA + 1]; inputA: cout << "Введите элементы множества A: "; cin.getline(setA, numA + 1, '\n'); for (int i = 0; i < numA; i++) { if (!isupper((unsigned char)setA[i])) { cout << "Вы произвели неверный ввод символа. Повторите ввод!\n"; 1 2 |