Работа с Weka. Отчёт по лабораторной работе 2
 Скачать 125.1 Kb. Скачать 125.1 Kb.
|

|
Отчёт по лабораторной работе №2 Для представления текстовой информации в Weka используется строковый атрибут типа STRING. Такой атрибут может содержать огромное число значений и поэтому напрямую классификаторы с ним не работают. В исходных данных всего два атрибута: атрибут класса и строковый атрибут. Мы преобразуем значения STRING в множество атрибутов, представляющих частоту встречаемости слов в строке. Такое преобразование можно реализовать с помощью фильтра StringToWordVector (рис. 1).  Рис 1 – Преобразование в множество атрибутов После преобразования можно начать обучение и сравнение классификаторов. В этой лабораторной работе мы будем использовать четыре классификатора: - алгоритм ближайшего соседа Nearest Neighbor (IBk), - байесовский Naïve Bayes (NB), - алгоритм на основе деревьев решений J48, - алгоритм на основе решающих правил JRip. Вавилонская башня Дано: коллекция из 189 предложений об интеллектуальном анализе данных из Wikipedia (не перевод!) на английском, французском, испанском и немецком языках. Найти: классификаторы, которые распознают язык текста. Перейдем в раздел Classify и обучим классификаторы. Сравним классификаторы между собой в режиме 10-перекрестной проверки:
Какой алгоритм лучший? По результатам видно, что лучший алгоритм это Naïve Bayes, так как у него самая высокая точность.
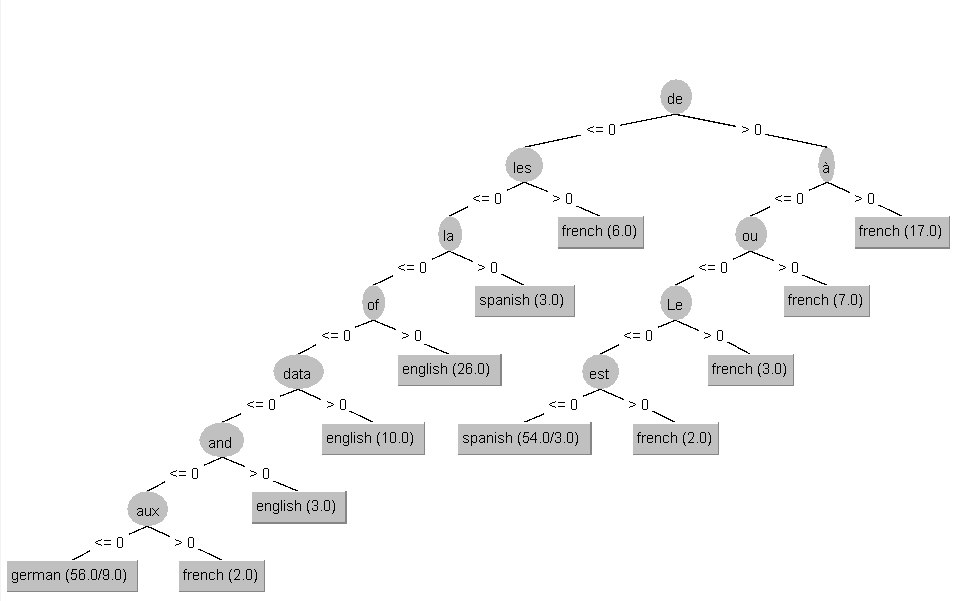 Рис 4 – Дерево J48 Являются ли языки, представленные в тексте, родственными? Как вы можете это подтвердить? Если проанализировать дерево решений алгоритма J48, то становится понятно, что язык можно распознать с помощью определенных артиклей, союзов и предлогов, которые используются в данном языке, а также с помощью характерных слов, которые встречаются только в определенной лингвистической группе. Некоторые слова имеют схожее происхождение и встречаются во всех четырех представленных языках. Именно поэтому алгоритм ошибается, что наглядно видно на матрице несоответствия Jrip и J48. Следовательно, можно сделать вывод, что эти четыре языка являются родственными. Классификатор IBk показывает невысокую точность для маленьких значений параметра k. Когда вы изменяете значение (например, увеличиваете значение k до 59), точность существенно растет. Как вы это объясните? Параметр k определяет количество соседей, которые алгоритм будет анализировать и классифицировать. Если посмотреть на исходные данные, то они записаны поочередно по языкам, что свидетельствует о том, что этот классификатор определяет по большинству предложений, написанных на одном языке, взятых в анализ. Сделаем выборку и определим важные атрибуты. Значения после выборки атрибутов:
Как вы видите, кроме сокращения времени работы, классификатор IBk повысил свою точность при малых значениях k. Как вы это объясните? Мы выбрали самые важные атрибуты, которые встречаются чаще других, а алгоритм IBk повысил свою точность, потому что классифицировал их по одному «соседу» то есть по одному релевантному атрибуту. Музыканты шутят Используя визуализацию деревьев решений J48 и JRip, можете ли вы предположить, что делает шутку смешной? 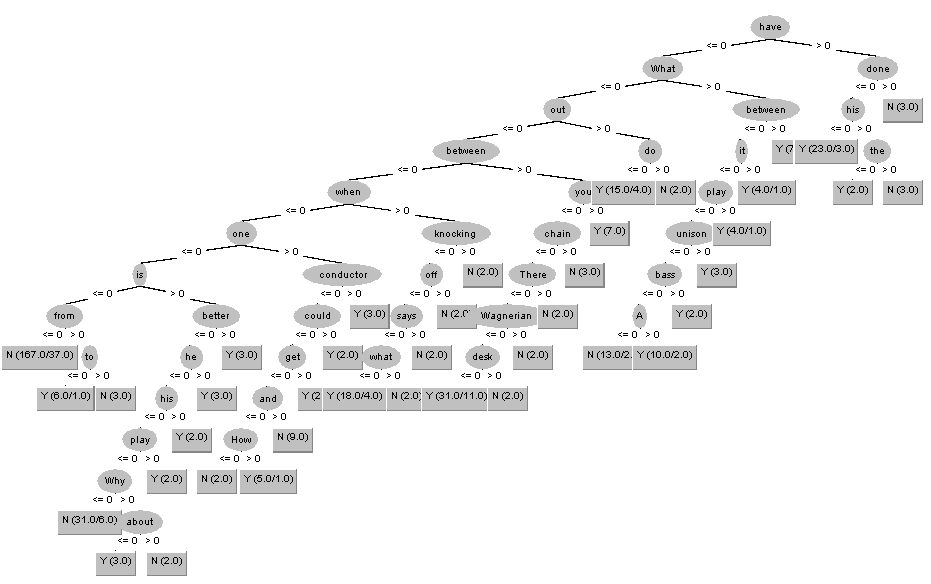 Рис 5 – Дерево «Музыканты шутят» Рискну предположить, что смешной шутку делают интересные сравнения музыкантов и музыкальных инструментов с чем-либо. Шутка типа «Что общего между…» чаще всего дает положительный результат, как видно по построению дерева. Какой алгоритм лучший? Результаты до выборки:
Результаты после выборки:
До выборки самый лучший алгоритм Jrip, после – Naïve Bayes. Американский и китайский английский Точность классификаторов не превышает 50%. Можно ли, используя классификаторы с невысокой точностью, получить приемлемые результаты классификации? Каким классификатором пользоваться? Нельзя пользоваться алгоритмом, точность которого близка к 50% на каком-то наборе данных. После обучения всех классификаторов получаем такие результаты:
В нашем случае такими алгоритмами являются J48 и Jrip. Алгоритмы NB и IBk показывают низкие точности. Следовательно, обратные им алгоритмы дадут точность в размере 78.7879 % и 92.0455 % соответственно. В данном случае лучшим алгоритмом будет являться обратный алгоритм классификации IBk с параметром KNN=1. |

