Архитектура компьютера. Самостоятельная работа. Параллельные компьютеры мультипроцессоры и мультикомпьютеры с общей и выделенной памятью
 Скачать 248.96 Kb. Скачать 248.96 Kb.
|

 МИНИСТЕРСТВО ПО РАЗВИТИЮ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ И КОММУНИКАЦИЙ РЕСПУБЛИКИ УЗБЕКИСТАН ФЕРГАНСКИЙ ФИЛИАЛ ТАШКЕНТСКОГО УНИВЕРСИТЕТА ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ ИМЕНИ МУХАММАДА АЛ-ХОРЕЗМИЙ ФАКУЛЬТЕТ «Компьютерный инжиниринг» ПО ПРЕДМЕТУ «АХИТЕКТУРА КОМПЬТЕРА» САМОСТОЯТЕЛЬНАЯ РАБОТА На тему: Параллельные компьютеры: мультипроцессоры и мультикомпьютеры с общей и выделенной памятью. Выполнил: студент группы №717-20 Бакиев Р.С. Фергана 2023 г. План 1.Введение 2. Межпроцессорные системные соединения 3. Мультикомпьютеры 4. Механизмы передачи сообщений 5. Мотивы параллелизма 6. Архитектура однопроцессорной машины 7. Мультикомпьютеры с распределенной памятью 8. Мультипроцессор с разделяемой памятью 9. Режимы выполнения независимых частей программы 10. Уровни параллелизма в многоядерных архитектурах 11. Литература Введение Мультипроцессоры и мультикомпьютеры В любой параллельной компьютерной системе процессоры, выполняющие разные части единого задания, должны как-то взаимодействовать друг с другом, чтобы обмениваться информацией Для обмена информацией предложено и реализовано две стратегии: мультипроцессоры и мультикомпьютеры. Ключевое различие между стратегиями состоит в наличии или отсутствии общей памяти Это различие сказывается как на конструкции, устройстве и программировании таких систем, так и на их стоимости и размерах Мультипроцессоры Параллельный компьютер, в котором все процессоры совместно используют общую физическую память, называется мультипроцессором, или системой с об- общей памятью Два процесса имеют возможность легко обмениваться информацией — для этого один из них просто записывает данные в общую память, а другой их считывает Все процессоры в мультипроцессоре используют единое адресное пространство функционирует только одна копия операционной системы Организация, в основе которой лежит единая система, и отличает мультипроцессор от мультикомпьютера В одних мультипроцессорных системах только определенные процессоры получают доступ к устройствам ввода-вывода, в других - каждый процессор может получить доступ к любому устройству ввода-вывода Если все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода, и между процессорами возможна полная взаимозаменяемость, такой мультипроцессор называется симметричным (Symmetric Multiprocessor, SMP) Мультикомпьютеры Во втором варианте параллельной архитектуры каждый процессор имеет собственную память, доступную только этому процессору Такая схема называется мультикомпьютером, или системой с распределенной памятью Каждый процессор в мультикомпьютере имеет собственную локальную память, к которой этот процессор может обращаться, но никакой другой процессор не может получить доступ к локальной памяти данного процессора Мультипроцессоры имеют одно физическое адресное пространство, разделяемое всеми процессорами, а мультикомпьютеры содержат отдельные физические адресные пространства для каждого процессора 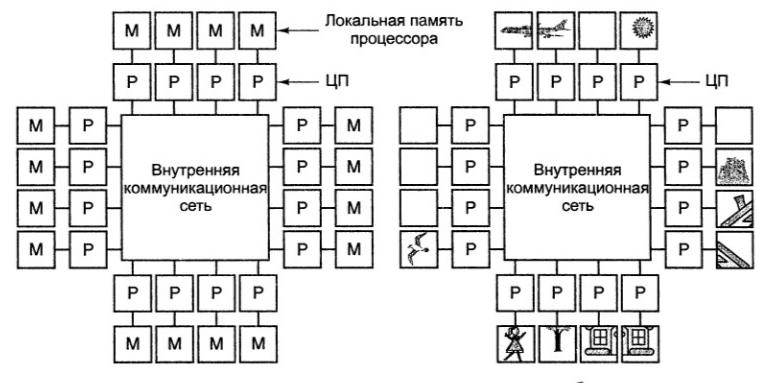 Поскольку процессоры в мульти компьютере не могут взаимодействовать друг с другом простыми обращениями к общей памяти, процессоры обмениваются сообщениями через связывающую их коммуникационную сеть Поскольку процессоры в мульти компьютере не могут взаимодействовать друг с другом простыми обращениями к общей памяти, процессоры обмениваются сообщениями через связывающую их коммуникационную сетьПримеры мульти компьютеров - IBM BlueGene/L, Red Storm, кластер Google Обмен данными При отсутствии общей памяти, реализованной аппаратно, предполагается определенная программная структура Пример: Сначала процессору 0 нужно как-то выяснить, какой процессор содержит необходимые ему данные, и послать этому процессору сообщение с запросом копии данных затем процессор 0 блокируется до получения ответа когда процессор 1 получает сообщение, оно программно анализируется, после чего затребованные данные передаются обратно когда процессор 0 получает ответное сообщение, блокировка программно снимается, и процессор продолжает работу В мультикомпьютере для взаимодействия между процессорами часто используются примитивы send и receive. ПО мультикомпьютера имеет более сложную структуру, чем ПО мультипроцессора Межпроцессорные системные соединения Параллельная обработка требует использования эффективных системных соединений для быстрой связи между входом / выходом и периферийными устройствами, мультипроцессорами и общей памятью. Иерархические шинные системы Иерархическая система шин состоит из иерархии шин, соединяющих различные системы и подсистемы / компоненты в компьютере. Каждая шина состоит из нескольких сигнальных, управляющих и силовых линий. Различные шины, такие как местные шины, шины объединительной платы и шины ввода / вывода, используются для выполнения различных функций соединения. Местные автобусы – это автобусы, установленные на печатных платах. Шина объединительной платы – это печатная плата, на которой используется множество разъемов для подключения функциональных плат. Шины, которые подключают устройства ввода-вывода к компьютерной системе, называются шинами ввода-вывода. Перекладина и много портовая память Коммутируемые сети обеспечивают динамическое соединение между входами и выходами. В системах малого или среднего размера чаще всего используются перекрестные сети. Многоступенчатые сети могут быть расширены до более крупных систем, если проблема увеличенной задержки может быть решена. Как кросс-коммутатор, так и много портовая организация памяти являются одноступенчатой сетью. Хотя создание одноступенчатой сети обходится дешевле, но для установления определенных соединений может потребоваться несколько проходов. Многоступенчатая сеть имеет более одной ступени распределительных коробок. Эти сети должны иметь возможность подключать любой вход к любому выходу. Многоступенчатые и объединяющие сети Многоступенчатые сети или многоступенчатые сети присоединения представляют собой класс высокоскоростных компьютерных сетей, который в основном состоит из элементов обработки на одном конце сети и элементов памяти на другом конце, соединенных коммутационными элементами. Эти сети применяются для создания больших многопроцессорных систем. Это включает в себя Omega Network, Butterfly Network и многое другое. Мультикомпьютеры Мультикомпьютеры – это MIMD-архитектуры с распределенной памятью. Следующая диаграмма показывает концептуальную модель мультикомпьютера – 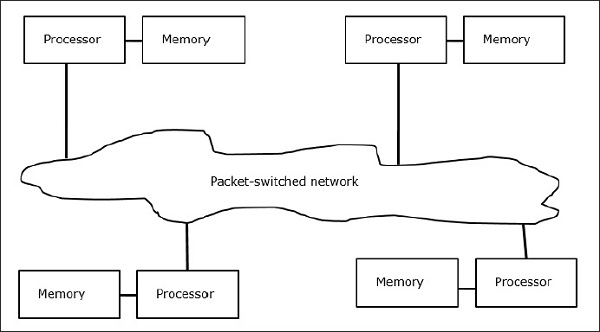 Мультикомпьютеры – это машины для передачи сообщений, которые применяют метод коммутации пакетов для обмена данными. Здесь каждый процессор имеет личную память, но нет глобального адресного пространства, поскольку процессор может обращаться только к своей локальной памяти. Таким образом, коммуникация не прозрачна: здесь программисты должны явно поместить коммуникационные примитивы в свой код. Отсутствие глобально доступной памяти является недостатком мультикомпьютеров. Это можно решить с помощью следующих двух схем – Виртуальная общая память (VSM) Общая виртуальная память (SVM) В этих схемах прикладной программист предполагает большую разделяемую память, которая адресуется глобально. При необходимости ссылки на память, создаваемые приложениями, преобразуются в парадигму передачи сообщений. Виртуальная общая память (VSM) VSM – это аппаратная реализация. Таким образом, система виртуальной памяти операционной системы прозрачно реализована поверх VSM. Таким образом, операционная система считает, что она работает на машине с общей памятью. Общая виртуальная память (SVM) SVM – это программная реализация на уровне операционной системы с аппаратной поддержкой модуля управления памятью (MMU) процессора. Здесь единица обмена – страницы памяти операционной системы. Если процессор обращается к определенной ячейке памяти, MMU определяет, находится ли страница памяти, связанная с доступом к памяти, в локальной памяти или нет. Если страница отсутствует в памяти, в обычной компьютерной системе она выгружается операционной системой с диска. Но в SVM операционная система выбирает страницу с удаленного узла, которому принадлежит эта конкретная страница. Три поколения мультикомпьютеров В этом разделе мы обсудим три поколения мультикомпьютеров. Выбор дизайна в прошлом. Выбирая технологию процессора, проектировщик мультикомпьютера выбирает недорогие средние процессоры зерна как строительные блоки. Большинство параллельных компьютеров построены со стандартными готовыми микропроцессорами. Распределенная память была выбрана для нескольких компьютеров, а не для использования общей памяти, что ограничивало бы масштабируемость. Каждый процессор имеет свой собственный локальный блок памяти. Для схемы межсоединений мультикомпьютеры имеют прямые сети передачи сообщений, а не сети с коммутацией адресов. Для стратегии управления разработчик нескольких компьютеров выбирает асинхронные операции MIMD, MPMD и SMPD. Космический куб Caltech (Seitz, 1983) – первый мультикомпьютер первого поколения. Настоящее и будущее развитие Компьютеры следующего поколения превратились из мультикомпьютеров среднего и мелкого размера в глобальную виртуальную память. Мультикомпьютеры второго поколения все еще используются в настоящее время. Но с использованием более качественных процессоров, таких как i386, i860 и т. Д., Компьютеры второго поколения получили большое развитие. Компьютеры третьего поколения – это компьютеры следующего поколения, где будут использоваться узлы, реализованные с помощью VLSI. Каждый узел может иметь процессор 14 MIPS, каналы маршрутизации 20 МБ / с и 16 КБ ОЗУ, интегрированные в один чип. Система IntelParagon Ранее для создания мультикомпьютеров гиперкубов использовались однородные узлы, поскольку все функции были переданы хосту. Таким образом, это ограничило пропускную способность ввода / вывода. Таким образом, для эффективного решения крупномасштабных задач или с высокой пропускной способностью эти компьютеры нельзя было использовать. Система Intel Paragon была разработана для преодоления этой трудности. Он превратил мультикомпьютер в сервер приложений с многопользовательским доступом в сетевой среде. Механизмы передачи сообщений Механизмы передачи сообщений в мультикомпьютерной сети нуждаются в специальной аппаратной и программной поддержке. В этом разделе мы обсудим некоторые схемы. Схемы маршрутизации сообщений В мультикомпьютере со схемой хранения и прямой маршрутизации пакеты являются наименьшей единицей передачи информации. В сетях, маршрутизируемых через червоточину, пакеты делятся на флиты. Длина пакета определяется схемой маршрутизации и реализацией сети, тогда как длина переброса зависит от размера сети. При хранении и прямой маршрутизации пакеты являются основной единицей передачи информации. В этом случае каждый узел использует буфер пакетов. Пакет передается от исходного узла к узлу назначения через последовательность промежуточных узлов. Задержка прямо пропорциональна расстоянию между источником и пунктом назначения. При маршрутизации по червоточине передача от исходного узла к узлу назначения осуществляется через последовательность маршрутизаторов. Все кадры одного и того же пакета передаются в неразделимой последовательности конвейерным способом. В этом случае только заголовок flit знает, куда идет пакет. Тупик и виртуальные каналы Виртуальный канал – это логическая связь между двумя узлами. Он образован буфером в исходном узле и узле приемника и физическим каналом между ними. Когда физический канал выделяется для пары, один исходный буфер соединяется с одним приемным буфером для формирования виртуального канала. Когда все каналы заняты сообщениями и ни один из каналов в цикле не освобожден, возникает ситуация взаимоблокировки. Чтобы избежать этого, необходимо следовать схеме предотвращения тупиковых ситуаций. Мотивы параллелизма Параллельность повышает производительность системы из-за более эффективного расходования системных ресурсов. Например, во время ожидания появления данных по сети, вычислительная система может использоваться для решения локальных задач. Параллельность повышает отзывчивость приложения. Если один поток занят расчетом или выполнением каких-то запросов, то другой поток может реагировать на действия пользователя. Параллельность облегчает реализацию многих приложений. Множество приложений типа "клиент-сервер", "производитель-потребитель" обладают внутренним параллелизмом. Последовательная реализация таких приложений более трудоемка, чем описание функциональности каждого участника по отдельности. Классификация вычислительных систем Одной из наиболее распространенных классификаций вычислительных систем является классификация Флинна. Четыре класса вычислительных систем выделяются в соответствие с двумя измерениями – характеристиками систем: поток команд, которые данная архитектура способна выполнить в единицу времени (одиночный или множественный) и поток данных, которые могут быть обработаны в единицу времени (одиночный или множественный). SISD (Single Instruction, Single Data) – системы, в которых существует одиночный поток команд и одиночный поток данных. В каждый момент времени процессор обрабатывает одиночный поток команд над одиночным потоком данных. К данному типу систем относятся последовательные персональные компьютеры с одноядерными процессорами. SIMD (Single Instruction, Multiple Data) – системы с одиночным потоком команд и с множественным потоком данных; подобный класс составляют многопроцессорные системы, в которых в каждый момент времени может выполняться одна и та же команда для обработки нескольких информационных элементов. Такая архитектура позволяет выполнять одну арифметическую операцию над элементами вектора. Современные компьютеры реализуют некоторые команды типа SIMD (векторные команды), позволяющие обрабатывать несколько элементов данных за один такт. MISD (Multiple Instructions, Single Data) – системы, в которых существует множественный поток команд и одиночный поток данных; к данному классу относят систолические вычислительные системы и конвейерные системы; MIMD (Multiple Instructions, Multiple Data) – системы с множественным потоком команд и множественных потоком данных; к данному классу относится большинство параллельных вычислительных систем. Классификация Флинна относит почти все параллельные вычислительные системы к одному классу – MIMD. Для выделения разных типов параллельных вычислительных систем применяется классификация Джонсона, в которой дальнейшее разделение многопроцессорных систем основывается на используемых способах организации оперативной памяти в этих системах. Данный подход позволяет различать два важных типа многопроцессорных систем: multiprocessors (мультипроцессорные или системы с общей разделяемой памятью) и multicomputers (мультикомпьютеры или системы с распределенной памятью). 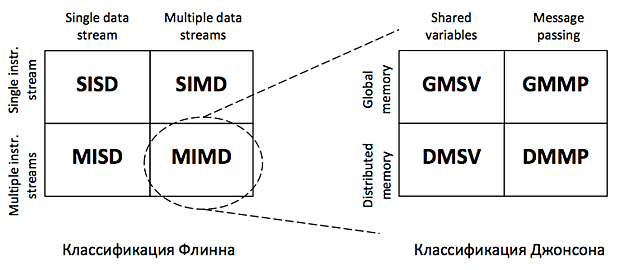 Классификация Джонсоном основана на структуре памяти (global - глобальная или distributed - распределенная) и механизме коммуникаций и синхронизации (shared variables - разделяемые переменные или message passing - передача сообщений). Системы GMSV (global-memory-shared-variables) часто называются также мультипроцессорами с разделяемой памятью (shared-memory multiprocessors). Системы DMMP (distributed-memory-message-passing) также называемые мультикомпьютерами с распределенной памятью (distributed-memory multicomputers). Архитектура однопроцессорной машины Современная однопроцессорная машина состоит из нескольких компонентов: центрального процессорного устройства (ЦПУ), первичной памяти, одного или нескольких уровней кэш-памяти (кэш), вторичной (дисковой) памяти и набора периферийных устройств (дисплей, клавиатура, мышь, модем, CD, принтер и т.д.). Основными компонентами для выполнения программ являются ЦПУ, кэш и память. 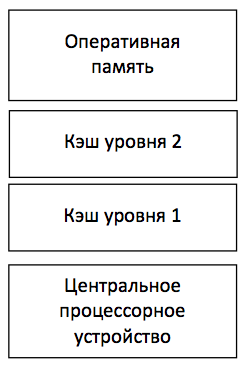 Процессор выбирает инструкции из памяти, декодирует их и выполняет. Он содержит управляющее устройство (УУ), арифметико-логическое устройство (АЛУ) и регистры. УУ вырабатывает сигналы, управляющие действиями АЛУ, системой памяти и внешними устройствами. АЛУ выполняет арифметические и логические инструкции, определяемые набором инструкций процессора. В регистрах хранятся инструкции, данные и состояние машины (включая счетчик команд). Мультикомпьютеры с распределенной памятью В мультикомпьютерах с распределенной памятью существуют соединительная сеть, но каждый процессор имеет собственную память. Соединительная сеть поддерживает передачу сообщений. Мультикомпьютеры (многопроцессорные системы с распределенной памятью) не обеспечивают общий доступ ко всей имеющейся в системах памяти. Каждый процессор системы может использовать только свою локальную память, в то время как для доступа к данным, располагаемых на других процессорах, необходимо использовать интерфейсы передачи сообщений (например, стандарт MPI). Данный подход используется при построении двух важных типов многопроцессорных вычислительных систем - массивно-параллельных систем (massively parallel processor or MPP) и кластеров (clusters). 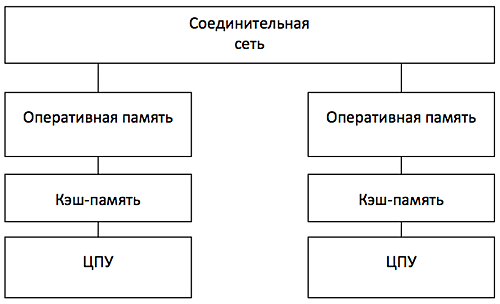 Мультикомпьютер (многомашинная система) – мультипроцессор с распределенной памятью, в котором процессоры и сеть расположены физически близко (в одном помещении). Также называют тесно связанной машинной. Она одновременно используется одним или небольшим числом приложений; каждое приложение задействует выделенный набор процессоров. Соединительная сеть с большой пропускной способностью предоставляет высокоскоростной путь связи между процессорами. Сетевая система – это многомашинная система с распределенной памятью, связаны с помощью локальной сети или глобальной сети Internet (слабо связанные мультикомпьютеры). Здесь процессоры взаимодействуют также с помощью передачи сообщений, но время их доставки больше, чем в многомашинных системах, и в сети больше конфликтов. С другой стороны, сетевая система строится на основе обычных рабочих станций и сетей, тогда как в многомашинной системе часто есть специализированные компоненты, особенно у связующей сети. Под кластером обычно понимается множество отдельных компьютеров, объединенных в сеть, для которых при помощи специальных аппаратно-программных средств обеспечивается возможность унифицированного управления, надежного функционирования и эффективного использования. Кластеры могут быть образованы на базе уже существующих у потребителей отдельных компьютеров, либо же сконструированы из типовых компьютерных элементов, что обычно не требует значительных финансовых затрат. Применение кластеров может также в некоторой степени снизить проблемы, связанные с разработкой параллельных алгоритмов и программ, поскольку повышение вычислительной мощности отдельных процессоров позволяет строить кластеры из сравнительно небольшого количества (несколько десятков) отдельных компьютеров (lowly parallel processing). Это приводит к тому, что для параллельного выполнения в алгоритмах решения вычислительных задач достаточно выделять только крупные независимые части расчетов (coarse granularity), что, в свою очередь, снижает сложность построения параллельных методов вычислений и уменьшает потоки передаваемых данных между компьютерами кластера. Вместе с этим следует отметить, что организация взаимодействия вычислительных узлов кластера при помощи передачи сообщений обычно приводит к значительным временным задержкам, что накладывает дополнительные ограничения на тип разрабатываемых параллельных алгоритмов и программ. Мультипроцессор с разделяемой памятью В мультипроцессоре и в многоядерной системе исполнительные устройства (процессоры и ядра процессоров) имеют доступ к разделяемой оперативной памяти. Процессоры совместно используют оперативную память. 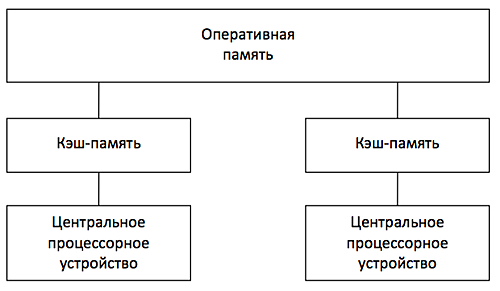 У каждого процессора есть собственный кэш. Если два процессора ссылаются на разные области памяти, их содержимое можно безопасно поместить в кэш каждого из них. Проблема возникает, когда два процессора обращаются к одной области памяти. Если оба процессора только считывают данные, в кэш каждого из них можно поместить копию данных. Но если один из процессоров записывает в память, возникает проблема согласованности кэша: в кэш-памяти другого процессора теперь содержатся неверные данные. Необходимо либо обновить кэш другого процессора, либо признать содержимое кэша недействительным. Обеспечение однозначности кэшей реализуется на аппаратном уровне – для этого после изменения значения общей переменной все копии этой переменной в кэшах отмечаются как недействительные и последующий доступ к переменной потребует обязательного обращения к основной памяти. Необходимость обеспечения когерентности приводит к некоторому снижению скорости вычислений и затрудняет создание систем с достаточно большим количеством процессоров. Наличие общих данных при выполнении параллельных вычислений приводит к необходимости синхронизации взаимодействия одновременно выполняемых потоков команд. Так, например, если изменение общих данных требует для своего выполнения некоторой последовательности действий, то необходимо обеспечить взаимоисключение с тем, чтобы эти изменения в любой момент времени мог выполнять только один командный поток. Задачи взаимоисключения и синхронизации относятся к числу классических проблем, и их рассмотрение при разработке параллельных программ является одним из основных вопросов параллельного программирования. Режимы выполнения независимых частей программы При рассмотрении проблемы организации параллельных вычислений следует различать следующие возможные режимы выполнения независимых частей программы: 1) Режим разделения времени (многозадачный режим) Режим разделения времени предполагает, что число подзадач (процессов или потоков одного процесса) больше, чем число исполнительных устройств. Данный режим является псевдопараллельным, когда активным (исполняемым) может быть одна единственная подзадача, а все остальные процессы (потоки) находятся в состоянии ожидания своей очереди на использование процессора; использование режима разделения времени может повысить эффективность организации вычислений (например, если один из процессов не может выполняться из-за ожидания вводимых данных, процессор может быть задействован для выполнения другого, готового к исполнению процесса), кроме того в данном режиме проявляются многие эффекты параллельных вычислений (необходимость взаимоисключения и синхронизации процессов и др.). Многопоточность приложений в операционных системах с разделением времени применяется даже в однопроцессорных системах. Например, в Windows-приложениях многопоточность повышает отзывчивость приложения – если основной поток занят выполнением каких-то расчетов или запросов, другой поток позволяет реагировать на действия пользователя. Многопоточность упрощает разработку приложения. Каждый поток может планироваться и выполняться независимо. Например, когда пользователь нажимает кнопку мышки персонального компьютера, посылается сигнал процессу, управляющему окном, в котором в данный момент находится курсор мыши. Этот процесс (поток) может выполняться и отвечать на щелчок мыши. Приложения в других окнах могут продолжать при этом свое выполнение в фоновом режиме. 2) Распределенные вычисления Компоненты выполняются на машинах, связанных локальной или глобальной сетью. По этой причине процессы взаимодействуют, обмениваясь сообщениями. Такие системы пишутся для распределения обработки (как в файловых серверах), обеспечения доступа к удаленным данным (как в базах данных и в Web), интеграции и управления данными, распределенными по своей сути (как в промышленных системах), или повышения надежности (как в отказоустойчивых системах). Многие распределенные системы организованы как системы типа клиент-сервер. Например, файловый сервер предоставляет файлы данных для процессов, выполняемых на клиентских машинах. Компоненты распределенных систем часто сами являются многопоточными. 3) Синхронные параллельные вычисления. Их цель – быстро решать данную задачу или за то же время решить большую задачу. Примеры синхронных вычислений: научные вычисления, которые моделируют и имитируют такие явления, как глобальный климат, эволюция солнечной системы или результат действия нового лекарства; графика и обработка изображений, включая создание спецэффектов в кино; крупные комбинаторные или оптимизационные задачи, например, планирование авиаперелетов или экономическое моделирование. Программы решения таких задач требуют эффективного использования доступных вычислительных ресурсов системы. Число подзадач должно быть оптимизировано с учетом числа исполнительных устройств в системе (процессоров, ядер процессоров). Уровни параллелизма в многоядерных архитектурах Параллелизм на уровне команд (InstructionLevelParallelism, ILP) позволяет процессору выполнять несколько команд за один такт. Зависимости между командами ограничивают количество доступных для выполнения команд, снижая объем параллельных вычислений. Технология ILP позволяет процессору переупорядочить команды оптимальным образом с целью исключить остановки вычислительного конвейера и увеличить количество команд, выполняемых процессором за один такт. Современные процессоры поддерживают определенный набор команд, которые могут выполняться параллельно. Параллелизм на уровне потоков процесса. Потоки позволяют выделить независимые потоки исполнения команд в рамках одного процесса. Потоки поддерживаются на уровне операционной системы. Операционная система распределяет потоки процессов по ядрам процессора с учетом приоритетов. С помощью потоков приложение может максимально задействовать свободные вычислительные ресурсы. Параллелизм на уровне приложений. одновременное выполнение нескольких программ осуществляется во всех операционных системах, поддерживающих режим разделения времени. Даже на однопроцессорной системе независимые программы выполняются одновременно. Параллельность достигается за счет выделение каждому приложению кванта процессорного времени. Литература Взято мною с разных интернет-источников: https://intuit.ru/studies/courses/5938/1074/lecture/16443 https://studfile.net/preview/3302751/ https://coderlessons.com/tutorials/akademicheskii/parallelnaia-kompiuternaia-arkhitektura/multiprotsessory-i-multikompiutery |