Язык SQL. Поддержка языков бд
 Скачать 120.5 Kb. Скачать 120.5 Kb.
|

|
Основные функции СУБД:
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД выделялись два языка –
В современных СУБД обычно поддерживается единый интегрированный язык SQL (Structured Query Language), содержащий все необходимые средства для работы с БД. Язык SQL декларативен. (Существуют процедурные и декларативные языки обработки данных: Большинство систем БД до начала использования SQL-технологии основывались на процедурных языках обработки данных. Они характеризуются зависимостью между прикладной программой и физической структурой данных – основной их недостаток. Декларативные языки обработки данных только специфицируют, какие данные необходимы прикладной программе, оставляя СУБД определение, как осуществлять навигацию по физической структуре данных для доступа к требуемым данным. Достоинства декларативных языков: - изменение в структурах данных незначительно влияет на существующие прикладные программы, - уменьшается сложность прикладной программы и снижается число ошибок в прикладных программах. ) Типовая организация современной СУБДЛогически в современной реляционной СУБД можно выделить (В некоторых системах эти части выделяются явно, в других - нет, но логически такое разделение можно провести во всех СУБД):
Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую выполняемую программу. Результатом компиляции является выполняемая программа, представляемая в некоторых СУБД в машинных кодах или в выполняемом внутреннем машинно-независимом коде. Производительность работы с БД определяется как среднее время реакции системы на выполнение операции поиска и предоставления требуемой операции. Это время зависит от многих факторов как технических (мощность компьютеров пользователей и серверов, пропускная способность сети), так и от логической структуры БД, а также и от языковых средств доступа к данным. Проблемы оптимизации в компиляторе языка SQLНачнем с формулировки проблемы оптимизации SQL-запросов. В формулировках SQL-запросов указывается, какими свойствами должны обладать данные, которые хочет получить пользователь, но не говориться, как система должна реально выполнить запрос. Проблема состоит в том, что бы по декларативной формулировке вопроса построить программу (эту программу принято называть планом выполнения запроса), которая выполнялась бы максимально эффективно и выдавала бы результаты, соответствующие запросу.Основные трудности:
Обе эти задачи не являются полностью формализуемыми и потому сложно решаемы.Оптимизация запросов (query optimization) в реляционных СУБД – это способ обработки запросов, когда по начальному представлению запроса вырабатывается наиболее оптимальный план его выполнения путем его преобразований. Соответствующие преобразования начального представления запроса выполняются специальным компонентом СУБД - оптимизатором запросов (query optimizer), и оптимальность производимого им плана выполнения запроса зависит от критериев, которые в него заложены. Во время процесса оптимизации запросов обрабатываются все типы команд SQL, однако команда SQL SELECT представляет наибольшую сложность в процессе, поэтому все примеры для команды SELECT . Термин оптимизация запросов является не совсем точным в том смысле, что нет гарантии, что в процессе оптимизации запроса будет действительно получен оптимальный план выполнения запроса. Более подходящим термином мог бы быть термин "улучшение запроса" (query improvement). Ранние версии реляционных СУБД обрабатывали запросы простым и непосредственным способом без какой-либо попытки оптимизировать как запрос сам по себе. Это имело результатом неудовлетворительно большое время обработки запроса и приводило к убеждению среди некоторых прикладных программистов, что реляционные СУБД являются непрактичными и мало пригодными для широкого круга практических применений. Для того чтобы увеличить скорость обработки запросов, были выполнены обширные исследования и тестирование для поиска способов повышения эффективности обработки запросов.
Несмотря на то, что оптимизаторы запросов современных реляционных СУБД различаются по сложности и принципам создания, все они следуют одним и тем основным этапам в выполнении оптимизации запроса. 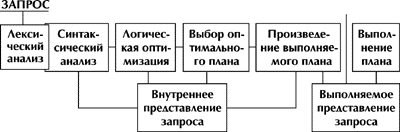 На первой фазе запрос, заданный на языке SQL:
На второй фазе запрос во внутреннем представлении подвергается логической оптимизации. Оптимизатор применяет правила преобразования запроса для преобразования его в формат, оптимальный с точки зрения синтаксиса.
После выполнения второй фазы обработки запроса его внутреннее представление все еще остается непроцедурным, хотя и является в некотором смысле более эффективным, чем начальное. Третий этап обработки запроса состоит в:
На четвертом этапе по выбранному оптимальному плану выполнения запроса формируется выполняемое представление плана. Выполняемое представление плана может быть программой в машинных кодах, если система ориентирована на компиляцию запросов в машинные коды, или быть машинно-независимым, но более удобным для интерпретации, если система ориентирована на интерпретацию запросов. В нашем случае это непринципиально, поскольку четвертая фаза обработки запроса уже не связана с оптимизацией. Наконец, на пятом этапе обработки запроса происходит его реальное выполнение. Реляционные операцииОперации, определенные в реляционной алгебре, используются для формирования внутреннего представления SQL запроса, т.е. представляют те логические операторы, которые должны быть обработаны оптимизатором. Эти логические операторы являются неявными для синтаксиса команд SQL, но именно они и обрабатываются СУБД. Операции реляционной алгебры имеют на входе одно или более отношений на входе и одно отношение на выходе. Эти операторы разделяются на два класса: теоретико-множественные операции (traditional set operations) и специальные реляционные операторы (special relational operators). Использование теоретико-множественных операций обычно достаточно для обработки большинства реляционных запросов, специальные операторы определяют желаемый результат более эффективно. Теоретико-множественные операцииГлавное отличие теоретико-множественных операций (за исключением декартова произведения) от всех других, выполняемых СУБД, состоит в том, что каждая таблица должна иметь одинаковое число колонок и каждая пара колонок для любой позиции таблицы должна быть определена с одинаковым типом и масштабом.
Специальные реляционные операторыSQL использует этот класс операций гораздо чаще, чем теоретико-множественные операции. К классу специальных реляционных операций обычно относят следующие:
(SELECT name, phone from customer)
(SELECT * FROM CUSTOMER WHERE NAME = 'JONES';) Каждое сравнение, содержащееся в предложении WHERE, называется предикатом (predicate).
Соединение. Соединение создает результирующее множество из двух или более таблиц таким же образом, что и ранее рассмотренное декартово произведение. Оно осуществляет конкатенацию строк для каждой строки одной таблицы с каждой строкой другой таблицы. Отличие между декартовым произведением и соединением состоит в том, что в эту операцию вовлекаются только те строки, которые удовлетворяют условию соединения. Это является логическим эквивалентом декартова произведения, для которого была выполнена операция селекции по условию. Однако операция соединения реализуется более эффективно большинством оптимизаторов запросов, так как оценивание строк выполняется до первоначального формирования декартова произведения как промежуточного результата. SELECT P.NAME, O.ORDER_NUM, C.NAME FROM CUSTOMER C, ORDER O, PRODUCT P WHERE (C.CUST_NO = O. CUST_NO ) AND (P.CUST_NO = O. CUST_NO); Две важнейших характеристики операции соединения состоят в том, что она является коммутативной и ассоциативной: A JOIN B = B JOIN A; (коммутативность) A JOIN (B JOIN C) = (A JOIN B) JOIN C; (ассоциативность) (A JOIN B) JOIN C = B JOIN (A JOIN C). Действие этих свойств состоит в том, что когда оптимизатор обрабатывает соединение более чем двух таблиц, то он может выбрать любую последовательность соединений двух таблиц для завершения операции. Это дает возможность оптимизатору готовить выполнение соединения любого числа таблиц как серию соединений двух таблиц, которое позволяет избегать выполнения специфических физических операций при соединении произвольного числа таблиц. Виды соединения:
SELECT P.PROD_NO, P.PROD_DESC FROM PRODUCT P, ORDER O WHERE (O.PROD_NO = P.PROD_NO) AND (O.ORD_DATE BETWEEN JAN-1-1995 AND JAN-31-1995);
SELECT P.NAME, COUNT(*) Kol FROM PRODUCT P, ORDER O WHERE P.PROD_NO = O.PROD_NO(+);
SELECET E.NAME Подчиненный, M.NAME Руководитель FROM EMPLOYEE E, EMPLOYEE M WHERE E.MNGR_NO = M. EMPLOYEE_NO;
Пример скалярной агрегации (просто возвращает единственное значение как вывод), который не имеет какого-либо предложения GROUP BY: SELECT SUM(SALARY) FROM EMPLOYEE; SELECT COUNT(*) FROM EMPLOYEE WHERE NAME = 'DAVE'; Синтаксис SQL для выполнения функции агрегации всегда включает предложение GROUP BY. В результате некоторая новая таблица: SELECT DEPT, AVG(SALARY) FROM EMPLOYEE GROUP BY DEPT; 2. Оптимизация запросов (2 этап выполнения оптимизации запроса)При классическом подходе к организации оптимизаторов запросов на этапе логической оптимизации производятся эквивалентные преобразования внутреннего представления запроса, которые "улучшают" начальное внутреннее представление в соответствии со стратегиями оптимизатора. Трудно привести полную характеристику и классификацию методов логической оптимизации. Ограничимся несколькими примерами:2.1 Синтаксическая оптимизацияПервый успех в оптимизации запросов состоял в нахождении способа переформулирования запроса таким образом, чтобы новое представление запроса обеспечивало тот же результат, но было более эффективно для обработки СУБД. Пример. Рассмотрим следующий запрос, который делает выборку данных из таблиц PRODUCT (ПРОДУКЦИЯ) и VENDOR (ПРОИЗВОДИТЕЛЬ): SELECT VENDOR_CODE, PRODUCT_CODE, PRODUCT_DESC FROM VENDOR, PRODUCT WHERE VENDOR.VENDOR_CODE = PRODUCT.VENDOR_CODE AND VENDOR.VENDOR_CODE = "100"; Наиболее очевидный путь обработки этого запроса состоит в следующем:
Оценим стоимость процесса обработки этого запроса в терминах операций ввода/вывода. Пусть для определенности таблица VENDOR содержит 50 строк, а таблица PRODUCT - 1000 строк. Тогда формирование декартова произведения потребует 50000 операций чтения и операций записи (в результирующую таблицу). Для ограничения результирующей таблицы потребуется более 50000 операций чтения и, если 20 строк удовлетворяют условиям поиска, то 20 операций записи. Выполнения операции проекции вызовет еще 20 операций чтения и 20 операций записи. Таким образом, обработка этого запроса обойдется системе в 100080 операций чтения и записи. Основная идея синтаксической оптимизации лежит в использовании эквивалентных алгебраических преобразований. Для данного примера запроса можно использовать следующую эквивалентность: (A JOIN B) WHERE restriction on A v (A WHERE restriction on A) JOIN B. Это означает, что ограничение по условию поиска может быть выполнено как можно раньше для того, чтобы ограничить число строк, которые могут быть обработаны позже. Применяя это правило к запросу, приведенному выше, получаем следующий процесс обработки запроса:
Обработка запроса в этом случае потребует 110 операций чтения и записи для получения того же самого результата, что и в первом случае. Преобразование, описанное в данном примере, называется синтаксической оптимизацией (syntax optimization). Существует много формул для выполнения таких преобразований, и все современные оптимизаторы запросов используют правила преобразований для представления запроса в более эффективной форме для обработки. С точки зрения реализации является очень важным, что эти автоматические преобразования освобождают программиста от поиска эквивалентной формы запроса, чтобы получить самую лучшую реализацию, поскольку оптимизатор обычно дает такую же окончательную форму, какую программист может получить вручную. Структура плана запросаОптимизатор определяет множество физических операций, необходимых для выполнения SQL команды, полученное множество операций и порядок их следования называется планом запроса (query plan). Аналогия с задачей программирования делает роль плана запроса проще для понимания. Программист кодирует инструкции на языке высокого уровня, которые затем компилируются для получения выполняемого программного кода. Аналогично, программист кодирует утверждения SQL, которые затем обрабатываются оптимизатором для производства выполняемой формы этого кода. Эта выполняемая форма кода есть план запроса. Дерево запросаОдним из способов представления запроса, которое обеспечивает понимание механизма его выполнения, является дерево запроса (query tree). Дерево запроса представляет собой древовидную структуру:
Следующий пример показывает дерево запроса для утверждения SQL, которое получает имена авторов книг, опубликованных в 1993 году: SELECT A.NAME FROM AUTHORS A, BOOCKS B WHERE (B.DATE_PUBLISHED ='1993') AND (A.NAME = B.NAME); 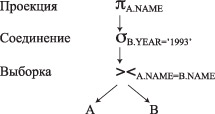 Дерево запроса Дерево запроса (в рисунке ошибка, надо поменять местами Соединение и Выборка) Пример построения дерева запросаОдин из наиболее используемых и важнейших методов состоит в использовании правила, что выполнение операций проекции и выбора надоосуществлять как можно раньше. Потому что эти операции могут ограничить размер результирующего множества. На оптимизатор улучшает дерево запросов, применяя выборку сначала для ограничения числа строк, которые являются входом операции эквисоединения. SELECT A.NAME FROM AUTHORS A, BOOCKS B WHERE (B.DATE_PUBLISHED ='1993') AND (A.NAME = B.NAME); 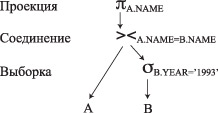 2.2 Оптимизация, основанная на правилахКогда был достигнут некоторый прогресс в улучшении обработки запросов, были предприняты усилия для улучшения методов доступа к таблицам. Это касается разработки методов доступа на основе использования индексов. Однако использование техники индексирования увеличивает сложность обработки запроса. Например, если таблица имеет индексы по трем различным колонкам, то любой из них может быть использован для доступа к таблице (помимо последовательного доступа к таблице в физическом порядке расположения строк). Также появилось много новых алгоритмов для выполнения соединения таблиц. Двумя наиболее основными алгоритмами выполнения соединения являются:
Операции соединения подчиняются как коммутативному, так и ассоциативному закону. Следовательно, теоретически возможно выполнять соединение в любом порядке. Например, все следующие предложения являются эквивалентными: (A JOIN B) JOIN C A JOIN (B JOIN C) (A JOIN C) JOIN B Различные пути доступа, различные алгоритмы соединений и порядок выполнения соединений могут приводить и к различной производительности. Следовательно, когда выполняется соединение нескольких таблиц, то существует несколько сотен различных комбинаций для выбора пути доступа к таблицам, порядка выполнения соединений и алгоритмов соединений. Каждая из этих комбинаций производит один и тот же результат, но имеет различные характеристики производительности. Установление эвристических правил для выбора между порядком доступа,порядком и методами соединений называется оптимизацией, основанной на правилах (rule-based optimization). В этом подходе предпочтения назначаются альтернативным решениям, которые являются общепризнанными. Используя эти предпочтения, оптимизатор запросов производит возможные планы выполнения до тех пор, пока не будет достигнут лучший план выполнения, удовлетворяющий этим правилам. Оптимизация, основанная на правилах, обеспечивает удовлетворительную производительность системы в тех ситуациях, когда эвристики являются точными. Однако часто общепризнанные правила не являются точными. Для обнаружения таких ситуаций оптимизатор запросов должен рассматривать характеристики данных, такие как:
Эти характеристики данных могут сильно влиять на эффективность обработки запроса. Использование таких характеристик приводит к следующему типу оптимизации. 2.3 Оптимизация, основанная на вычислении стоимостиОптимизация, основанная на вычислении стоимости запроса (cost-based optimization), аналогична оптимизации, основанной на правилах, за исключением того, что оптимизатор на основе вычисления стоимости использует статистическую информацию для выбора наиболее эффективного плана выполнения запроса. Стоимость каждого альтернативного плана выполнения запроса оценивается с помощью статистики, например, такой как число строк в таблице и распределения значений колонки таблицы. Такая статистика хранится в системном каталоге и поддерживается СУБД. Для понимания того, как статистика может быть использована для выбора плана выполнения запроса, рассмотрим следующий запрос к таблице CUSTOMER (ПОКУПАТЕЛЬ): SELECT CUST_N, CUST_NAME FROM CUSTOMER WHERE STATE = "RUS"; Если существует индекс на колонку STATE, оптимизатор, основанный на правилах, использовал бы его для обработки запроса. Однако если девяносто процентов строк в таблице CUSTOMER имеют RUS в колонке STATE, то использование индекса будет в действительность приводить к более медленному выполнению запроса, чем простая последовательная обработка таблицы. Оптимизатор, основанный на вычислении стоимости, с другой стороны, обнаружил бы, что использование индекса в этом случае не дает никаких преимуществ перед последовательным просмотром таблицы. Подход к оптимизации, основанный на вычислении стоимости, сегодня представляет определенное искусство в технике оптимизации запросов. Большинство реляционных СУБД применяют оптимизаторы, основанные на вычислении стоимости. ЗаключениеОптимизаторы реляционных СУБД представляют собой наиболее сложные компоненты систем. Эффективность системы в целом во многом определяется тем, насколько мощной является оптимизация. Как мы старались показать, во всех существующих направлениях, связанных с оптимизацией, наряду с определенным продвижением остается множество нерешенных проблем. |