Управление разработкой информационных систем. Проектирование информационной системы для маркировки обуви и одежды
 Скачать 1.01 Mb. Скачать 1.01 Mb.
|

2. ПРОЕКТИРОВАНИЕ ИНФОРМАЦИОННОЙ СИСТЕМЫ2.1 Технологии реализацииПроектирование информационных систем всегда начинается с определения цели проекта. Основная задача любого успешного проекта заключается в том, чтобы на момент запуска системы и в течение всего времени ее эксплуатации можно было обеспечить: требуемую функциональность системы и степень адаптации к изменяющимся условиям ее функционирования; требуемую пропускную способность системы; безотказную работу системы в требуемом режиме, иными словами - готовность и доступность системы для обработки запросов пользователей; простоту эксплуатации и поддержки системы; необходимую безопасность. Производительность является главным фактором, определяющим эффективность системы. Хорошее проектное решение служит основой высокопроизводительной системы. Проектирование информационных систем охватывает три основные области: проектирование объектов данных, которые будут реализованы в базе данных; проектирование программ, экранных форм, отчетов, которые будут обеспечивать выполнение запросов к данным; учет конкретной среды или технологии, а именно: топологии сети, конфигурации аппаратных средств, используемой архитектуры (файл-сервер или клиент-сервер), параллельной обработки, распределенной обработки данных и т.п. В реальных условиях проектирование — это поиск способа, который удовлетворяет требованиям функциональности системы средствами имеющихся технологий с учетом заданных ограничений. К любому проекту предъявляется ряд абсолютных требований, например, максимальное время разработки проекта, максимальные денежные вложения в проект и т.д. Одна из сложностей проектирования состоит в том, что оно не является такой структурированной задачей, как анализ требований к проекту или реализация того или иного проектного решения. Считается, что сложную систему невозможно описать в принципе. Это, в частности, касается систем управления предприятием. Одним из основных аргументов является изменение условий функционирования системы, например, директивное изменение тех или иных потоков информации новым руководством. Еще один аргумент - объемы технического задания, которые для крупного проекта могут составлять сотни страниц, в то время как технический проект может содержать ошибки. Возникает вопрос: а может, лучше вообще не проводить обследования и не делать никакого технического проекта, а писать систему «с чистого листа» в надежде на то, что произойдет некое чудесное совпадение желания заказчика с тем, что написали программисты, а также на то, что все это будет стабильно работать? Жизненный цикл программного обеспечения представляет собой модель его создания и использования. Модель отражает его различные состояния, начиная с момента возникновения необходимости в данном ПО и заканчивая моментом его полного выхода из употребления у всех пользователей. Известны следующие модели жизненного цикла: Каскадная модель. Переход на следующий этап означает полное завершение работ на предыдущем этапе. Поэтапная модель с промежуточным контролем. Разработка ПО ведется итерациями с циклами обратной связи между этапами. Межэтапные корректировки позволяют уменьшить трудоемкость процесса разработки по сравнению с каскадной моделью; время жизни каждого из этапов растягивается на весь период разработки. Спиральная модель. Особое внимание уделяется начальным этапам разработки - выработке стратегии, анализу и проектированию, где реализуемость тех или иных технических решений проверяется и обосновывается посредством создания прототипов (макетирования). Каждый виток спирали предполагает создание некой версии продукта или какого-либо его компонента, при этом уточняются характеристики и цели проекта, определяется его качество и планируются работы следующего витка спирали. В проектировании информационной системы «Маркировка», был применен спиральный подход (рисунок 2.1), то есть происходило поэтапное уточнение требований, частичная реализация в рабочих примерах, тестирование, а дальше цикл повторялся. 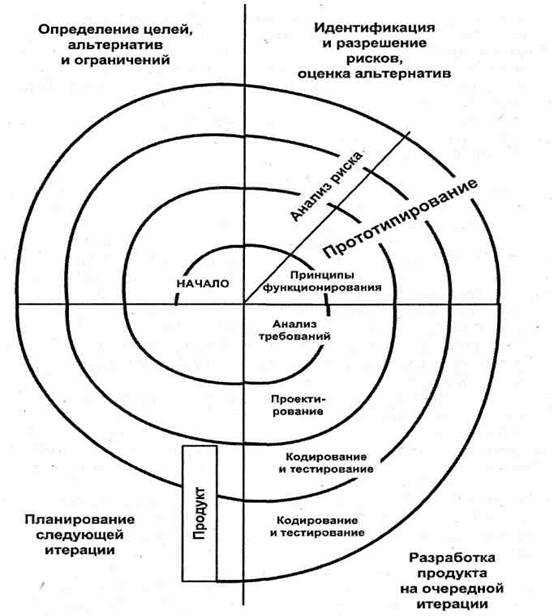 Рис. 2.1 Спиральная модель жизненного цикла программного обеспечения 2.2 Внутримашинное информационное обеспечение. Проектирование БДВ качестве технологий для разработки базы данных выступает Microsoft SQL SERVER 2019. Microsoft SQL Server – это разработанная компанией Microsoft система управления реляционными базами данных. Microsoft SQL Server 2019 – это новая и самая актуальная на текущий момент времени версия системы. Возможности SQL Server 2019: кластеры больших данных – они помогают в реализации среды для работы с большими наборами данных, в том числе с использованием машинного обучения и возможностей искусственного интеллекта; пакетный режим для данных rowstore – данный режим обеспечивает выполнение в пакетном режиме без необходимости использования индексов columnstore. В этом режиме более эффективно используются ресурсы процессора во время аналитических запросов, поэтому его лучше использовать тогда, когда значительная часть работы состоит из аналитических запросов, или если рабочая нагрузка сильно зависит от процессора. Раньше такая возможность использовалось, но только если запрос включал операции с индексами columnstore. Однако приложения могли использовать функции, которые не поддерживают индексы columnstore, и поэтому не могли работать в пакетном режиме. Начиная с этой версии пакетный режим доступен для запросов, которые включают операции как с индексами rowstore, так и с columnstore; встраивание скалярных пользовательских функций – данная возможность автоматически в SQL запросе преобразует определяемые пользователем скалярные функции в реляционные выражения, что значительно повышает производительность запросов, которые используют скалярные пользовательские функции; отложенная компиляция табличных переменных – возможность позволяет оптимизировать план и повысить производительность запросов, в которых используются табличные переменные. Это достигается за счет того, что во время оптимизации и первичной компиляции инструкций эта возможность распространяет оценки кратности, основанные на фактическом количестве строк табличной переменной; приблизительная обработка запросов с помощью функции APPROX_COUNT_DISTINCT – эта функция выполняет статистическое вычисление COUNT(DISTINCT()), однако она оптимизирована для крупных наборов данных, так она использует меньше ресурсов и обеспечивает лучший параллелизм. Ее можно использовать в случаях, если не требуется абсолютная точность, но есть строгие требования по времени выполнения; гибридный буферный пул – данная возможность обеспечивает (в случае необходимости) прямой доступ к страницам данных в файлах базы данных, хранящихся на устройствах с постоянной памятью (PMEM); оптимизированные для памяти метаданные TempDB – эта функция позволяет обеспечить новый уровень масштабируемости для рабочих нагрузок, которые активно используют TempDB. Таким образом, системные таблицы, связанные с управлением метаданными временных таблиц, теперь можно переместить в таблицы, оптимизированные для работы с памятью, без кратковременной блокировки; поддержка In-Memory OLTP для моментальных снимков базы данных – теперь SQL Server поддерживает создание моментальных снимков баз данных, которые включают оптимизированные для памяти файловые группы; параметр OPTIMIZE_FOR_SEQUENTIAL_KEY для индексов – он оптимизирует ядро для увеличения пропускной способности операций вставки в индекс с высокой степенью параллелизма. Этот параметр предназначен для индексов с последовательным ключом; сокращение повторных компиляций для инструкций с временными таблицами – начиная с этой версии SQL Server выполняет дополнительные проверки инструкций с временными таблицами, чтобы избежать ненужных перекомпиляций, что повышает производительность; одновременные обновления PFS – «Свободное место на странице» PFS – это специальные страницы в файле базы данных, с помощью которых SQL Server находит свободное место при выделении пространства для объекта. Это улучшение позволяет изменить способ управления параллелизмом с помощью обновлений PFS, чтобы можно было использовать общую кратковременную блокировку, а не монопольную блокировку. Это поведение включено по умолчанию во всех базах данных, включая TempDB, начиная с 2019 версии SQL Server; WAIT_ON_SYNC_STATISTICS_REFRESH – это новый тип ожидания в динамическом системном представлении sys.dm_os_wait_stats. Он отображает суммарное время на уровне экземпляра, затраченное на синхронные операции обновления статистики; параметр LIGHTWEIGHT_QUERY_PROFILING – это новый параметр области базы данных, который позволяет включать и отключать упрощенную инфраструктуру профилирования запросов. Упрощенная инфраструктура профилирования запросов (LWP) – предоставляет более эффективные данные производительности запросов по сравнению со стандартными механизмами профилирования. По умолчанию она включена; табличная функция sys.dm_exec_query_plan_stats – это новая функция динамического управления (DMF), она возвращает эквивалент последнего известного фактического плана выполнения для всех запросов. Управляется она, т.е. ее можно включить и отключить, с помощью параметра LAST_QUERY_PLAN_STAT уровня области базы данных; параметр SHORTEST_PATH – это новый параметр MATCH, который используется для поиска кратчайшего пути между любыми двумя узлами в графе или выполнения обходов произвольной длины; графовые таблицы теперь поддерживают секционирование таблиц и индексов; поддержка кодировки UTF-8 – для импорта и экспорта кодировки, а также как параметр сортировки на уровне столбцов и базы данных для строковых данных; SDK для языка Java – это интерфейс для расширения языка Java, который используется для обмена данными с SQL Server и выполнения кода Java из SQL Server. Ранее мы могли в базе данных SQL сервера выполнять код на языках R и Python, теперь стало возможно выполнять код и на языке Java; CREATE EXTERNAL LANGUAGE – это новая инструкция DDL, которая регистрирует внешние языки, такие как Java; улучшения в «Сообщениях об ошибках» – теперь сообщение об ошибке усечения данных по умолчанию включает имена таблицы и столбца, а также усеченное значение; управление сертификатами в диспетчере SQL Server – теперь стало возможно управлять сертификатами в диспетчере конфигурации SQL Server; пять синхронных реплик в Availability Groups – максимальное количество синхронных реплик увеличено до пяти (в 2017 версии 3), что дает возможность настроить группу из пяти реплик для автоматического перехода на другой ресурс в пределах группы; перенаправление подключения от вторичной реплики к первичной – данная возможность позволяет направлять подключения клиентских приложений к первичной реплике независимо от целевого сервера, указанного в строке подключения; ускоренное восстановление баз данных (ADR) – это улучшение сокращает время восстановления баз данных после перезапуска или длительного отката транзакций; новые возобновляемые операции – такие как: сборка и перестроение кластеризованных индексов columnstore в режиме «в сети», а также сборка индексов rowstore в режиме «в сети»; улучшенная поддержка Linux – теперь на Linux поддерживается: репликация, координатор распределенных транзакций (MSDTC), OpenLDAP для сторонних поставщиков Active Directory, службы машинного обучения, система отслеживания измененных данных (CDC) и PolyBase. Кроме этого, есть улучшения TempDB. новые параметры установки – в SQL Server 2019 добавились новые параметры настройки памяти Min Server Memory и Max Server Memory (в MB), а также новые параметры настройки параллелизма Max degree of parallelism (MaxDOP). Целью построения диаграммы базы данных является получение графического представления физической структуры исследуемой предметной области. Сущности описывают объекты, являющиеся предметом деятельности предметной области, и субъекты, осуществляющие деятельность в рамках предметной области. Свойства объектов и субъектов реального мира описываются с помощью атрибутов. Взаимоотношения между сущностями иллюстрируются с помощью связей. Правила и ограничения взаимоотношений описываются с помощью свойств связей. Обычно связи определяют либо зависимости между сущностями, либо влияние одной сущности на другую. В спроектированной базе данных, следующие таблицы таблицы: tblattr – системная таблица с контр эткетками; tblBoxAttach – таблица контроля SSCC кодов; tblboxes – таблица, хранящая SSCC коды; tbllabel – спецификации; tblsupply – коды грузов. Таблица 1 Описание таблиц БД
На рисунке 2.2 представлена диаграмма базы данных информационной системы «Маркировка». 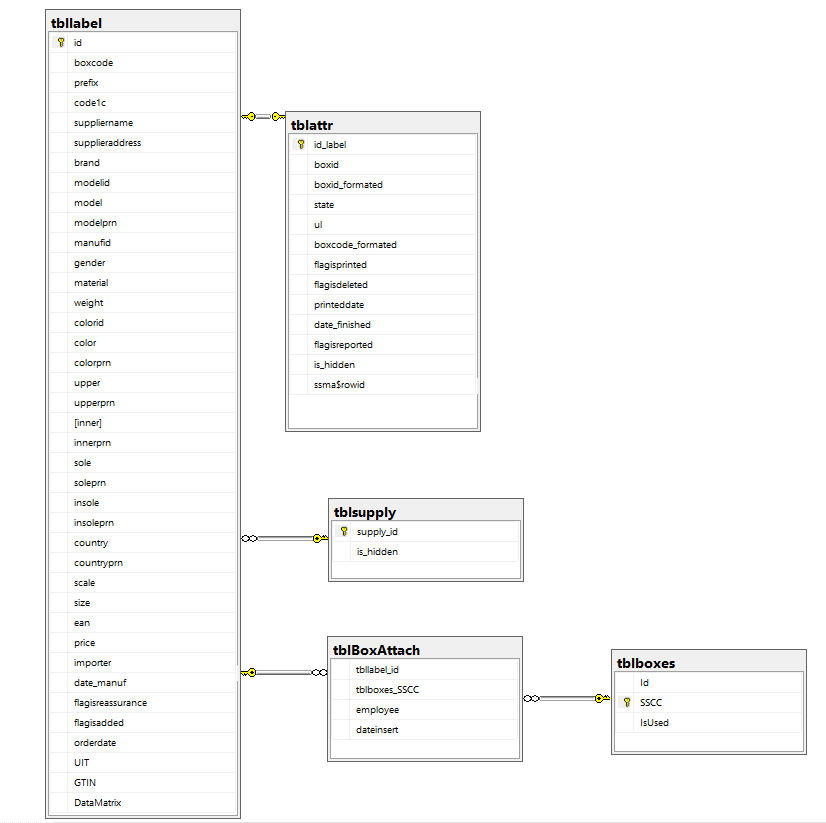 Рис. 2.2 Диаграмма базы данных информационной системы «Маркировка» Пример запроса загрузки данных в таблицу tbllabel: INSERT INTO tbllabel VALUES('X3P712 XM330','RU','356290','G.A.OPERATIONS SpA','Via Borgonuovo 11, 20121 Milano','EMPORIO ARMANI','X3P712 XM330','сабо',NULL,'','Жен',NULL,NULL,NULL,'бежевый, черный','бежевый, черный','100% полиэтилен; Второй материал: 100% кожа','100% полиэтилен; Второй материал: 100% кожа','100% кожа','100% кожа','100% кожа','100% кожа',NULL,NULL,'ИТАЛИЯ',NULL,NULL,'37','8058644786936',NULL,'','03.12.2019',0,0,'03.03.2020','010805864478693621GLYJh.Xjp?KOq','8058644786936','010805864478693621GLYJh.Xjp?KOq91002A92QhQd19/a0WdjOUNegJnFPF/BiNdUGJ0zyND/fZYp7bzLenrjzuCCRhL7Id/86vuReWE8FQ93nXX7eE6y5X+jMg==') INSERT INTO tbllabel VALUES('X3P712 XM330','RU','356290','G.A.OPERATIONS SpA','Via Borgonuovo 11, 20121 Milano','EMPORIO ARMANI','X3P712 XM330','сабо',NULL,'','Жен',NULL,NULL,NULL,'бежевый, черный','бежевый, черный','100% полиэтилен; Второй материал: 100% кожа','100% полиэтилен; Второй материал: 100% кожа','100% кожа','100% кожа','100% кожа','100% кожа',NULL,NULL,'ИТАЛИЯ',NULL,NULL,'38','8058644786950',NULL,'','03.12.2019',0,0,'03.03.2020','010805864478695021xtGMe_EV4b0DH','8058644786950','010805864478695021xtGMe_EV4b0DH91002A927dG5mjfyk7WvehvBVdWejD5qTo4ONGb9D0u734KYAtXjyOpG0fxP6D/zPdmK9kB8QBCqYEsBNOSGP/x9E3C7/g==') INSERT INTO tbllabel VALUES('X3P712 XM330','RU','356290','G.A.OPERATIONS SpA','Via Borgonuovo 11, 20121 Milano','EMPORIO ARMANI','X3P712 XM330','сабо',NULL,'','Жен',NULL,NULL,NULL,'бежевый, черный','бежевый, черный','100% полиэтилен; Второй материал: 100% кожа','100% полиэтилен; Второй материал: 100% кожа','100% кожа','100% кожа','100% кожа','100% кожа',NULL,NULL,'ИТАЛИЯ',NULL,NULL,'39','8058644786974',NULL,'','03.12.2019',0,0,'03.03.2020','010805864478697421nqoICW0PEZaq+','8058644786974','010805864478697421nqoICW0PEZaq+91002A92P9SlGs8AXxEAMl+jcocJjQnb3R8TM46iJrjFIf/FXG7yiNBm1YRkV3jeH4V65u6jARE7WIQrMm1pVkz48enk+w==') INSERT INTO tbllabel VALUES('X3P712 XM330','RU','356290','G.A.OPERATIONS SpA','Via Borgonuovo 11, 20121 Milano','EMPORIO ARMANI','X3P712 XM330','сабо',NULL,'','Жен',NULL,NULL,NULL,'бежевый, черный','бежевый, черный','100% полиэтилен; Второй материал: 100% кожа','100% полиэтилен; Второй материал: 100% кожа','100% кожа','100% кожа','100% кожа','100% кожа',NULL,NULL,'ИТАЛИЯ',NULL,NULL,'40','8058644786998',NULL,'','03.12.2019',0,0,'03.03.2020','010805864478699821DL_1LiuZfcaCJ','8058644786998','010805864478699821DL_1LiuZfcaCJ91802992ZelcMobMm0ruhXxAQTRPLVPoxECnJtOqjPjV6UlOWEBIoEv/LfmlS8pZ0h9hvXJrCBugZPW+kzhta/Z4Y+/mzw==') | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||