ПОВТ-1-17 Хатанзейская Н.А. лаб1. Распознавание цифр из графических с помощью нейросети на языке Python по дисциплине Технологии искусственного интеллекта в автоматизированных системах управления
 Скачать 374.69 Kb. Скачать 374.69 Kb.
|

ОТЧЁТ ПО ЛАБОРАТОРНОЙ РАБОТЕ №1 на тему «Распознавание цифр из графических с помощью нейросети на языке Python» по дисциплине «Технологии искусственного интеллекта в автоматизированных системах управления»
Казань -2021 Цель работы Написать программу для распознания цифр из графический файлов. Теоретическая часть Набор данных MNIST Один из самых популярных наборов данных для работы с машинным обучением. Он содержит 60 000 тренировочных изображений написанных от руки цифр от 0 до 9, а также 10 000 картинок для тестирования. В наборе есть 10 разных классов. Изображения с цифрами представлены в виде матриц 28 х 28, где каждая ячейка содержит определенный оттенок серого. Сверточная нейронная сеть Свёрточные нейронные сети нужны для того, чтобы находить и распознавать какие-то признаки (это может быть цифра или собака, например), которые будут обобщаться вне зависимости от положения изображения на картинке (по середине или где-то сбоку). Свёрточные нейронные сети используют принцип свертки, по которому так называемое ядро (kernel) перемещается вдоль изображения и выделяет ключевые эффекты на картинке, если они есть. Затем полученный результат сообщается «обычной» нейронной сети, которая и выдает готовый результат. Свёртка решает ещё и задачу учёта дополнительной информации о структуре данных, то есть она учитывает, какие пиксели находятся рядом с какими. В свёрточной нейронной сети в операции свёртки используется лишь ограниченная матрица весов небольшого размера, которую «двигают» по всему обрабатываемому слою (в самом начале — непосредственно по входному изображению), формируя после каждого сдвига сигнал активации для нейрона следующего слоя с аналогичной позицией. То есть для различных нейронов выходного слоя используются одна и та же матрица весов, которую также называют ядром свёртки. Её интерпретируют как графическое кодирование какого-либо признака, например, наличие наклонной линии под определённым углом. Тогда следующий слой, получившийся в результате операции свёртки такой матрицей весов, показывает наличие данного признака в обрабатываемом слое и её координаты, формируя так называемую карту признаков. Естественно, в свёрточной нейронной сети набор весов не один, а целая гамма, кодирующая элементы изображения (например линии и дуги под разными углами). При этом такие ядра свёртки не закладываются исследователем заранее, а формируются самостоятельно путём обучения сети классическим методом обратного распространения ошибки. Слой свертки Слой свёртки (convolutionallayer) — это основной блок свёрточной нейронной сети. Слой свёртки включает в себя для каждого канала свой фильтр, ядро свёртки которого обрабатывает предыдущий слой по фрагментам (суммируя результаты поэлементного произведения для каждого фрагмента). Весовые коэффициенты ядра свёртки (небольшой матрицы) неизвестны и устанавливаются в процессе обучения. Особенностью свёрточного слоя является сравнительно небольшое количество параметров, устанавливаемое при обучении. Так например, если исходное изображение имеет размерность 100×100 пикселей по трём каналам (это значит 30000 входных нейронов), а свёрточный слой использует фильтры c ядром 3x3 пикселя с выходом на 6 каналов, тогда в процессе обучения определяется только 9 весов ядра, однако по всем сочетаниям каналов, то есть 9×3×6 =162, в таком случае данный слой требует нахождения только 162 параметров, что существенно меньше количества искомых параметров полносвязной нейронной сети. Фильтр представляет собой небольшую сетку вдоль ширины и высоты, но простирающуюся по всей глубине входного представления Пулинг Слой пулинга (иначе подвыборки, субдискретизации) представляет собой нелинейное уплотнение карты признаков, при этом группа пикселей (обычно размера 2×2) уплотняется до одного пикселя, проходя нелинейное преобразование. Преобразования затрагивают непересекающиеся прямоугольники или квадраты, каждый из которых ужимается в один пиксель, при этом выбирается пиксель, имеющий максимальное значение. Операция пулинга позволяет существенно уменьшить пространственный объём изображения. Пулинг интерпретируется так: если на предыдущей операции свёртки уже были выявлены некоторые признаки, то для дальнейшей обработки настолько подробное изображение уже не нужно, и оно уплотняется до менее подробного. Слой пулинга, как правило, вставляется после слоя свёртки перед слоем следующей свёртки. Полносвязная нейронная сетьПосле нескольких прохождений свёртки изображения и уплотнения с помощью пулинга система перестраивается от конкретной сетки пикселей с высоким разрешением к более абстрактным картам признаков, как правило на каждом следующем слое увеличивается число каналов и уменьшается размерность изображения в каждом канале. В конце концов остаётся большой набор каналов, хранящих небольшое число данных (даже один параметр), которые интерпретируются как самые абстрактные понятия, выявленные из исходного изображения. Эти данные объединяются и передаются на обычную полносвязную нейронную сеть, которая тоже может состоять из нескольких слоёв. При этом полносвязные слои уже утрачивают пространственную структуру пикселей и обладают сравнительно небольшой размерностью (по отношению к количеству пикселей исходного изображения). LeNet LeNet- это архитектура, которая была предложена Яном ЛеКуном для того, чтобы распознавать рукописные цифры. LeNet принимает картинки размером 32 на 32, пропускает через два набора свёрток, затем распрямляет вектор, и затем применяет полносвязанные слои. И в результате у нас получается 10 результатов, каждый из этих результатов описывает вероятность каждого класса для данной картинки. Когда нейронная сеть создана, ее надо обучить. Для начала необходимо загрузить входные данные MNIST и преобразовать их в нужный формат. У нас есть два блока данных: train и test — один служит для обучения, второй для верификации результатов. Это общепринятая практика, обучать и тестировать нейронную сеть желательно на разных наборах данных. Библиотека Keras уже включает некоторые из них. В их числе и MNIST. Таким образом можно запросто импортировать набор и начать работать с ним. Структура сети: три сверточных слоя и два полносвязных слоя. 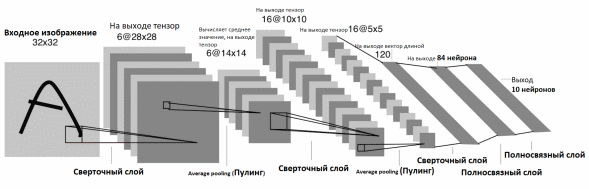 Рис 1 – Архитектура нейронной сети Алгоритм На вход подаётся изображение размером 32 на 32. Это изображение прогоняется через свёртку 5 на 5, с шестью выходными каналами, значит - у нас свёртка 5 на 5 проходит по всему изображению. Она не выходит за границы изображения, и по этой причине она обрезает два пикселя с каждой стороны изображения, и выходное изображение 32 на 32 преобразуется к изображению 28 на 28. Но теперь это уже не изображение а тензор глубиной 6, потому что свёртка - с шестью выходными каналами. После этого вот этот тензор (28 на 28 на 6) передается в пулинг, который вычисляет среднее значение по квадрату 2 на 2. Он по всему изображению проходит, берёт непересекающиеся участки 2 на 2, и вычисляет среднее значение пикселей или чисел, которые оказываются в этом тензоре. И на выходе у него один пиксель, соответственно, всё изображение ужимается в два раза: было 28 на 28 на 6, стало 14 на 14 на 6. Далее повторяется точно такая же свёртка, как в первый раз, только теперь у неё количество входных каналов - 6, а выходных каналов - 16. При этом, из 14 на 14, изображение получается 10 на 10, потому что у нас по два пикселя съелось с каждой стороны, потому что мы применяли свёртки без паддингов - без выхода за границы изображения. Далее снова точно такой же, 2 на 2 average pooling. Затем берется свёртка 5 на 5, (потому что у нас получается тензор 5 на 5 на 16), вот этот тензор 5 на 5 на 16 мы растянем в один вектор длиной. И у нас есть готовый вектор, к которому можно применить полносвязанный слой, который на выходе будет иметь 120 нейронов. Полносвязанному слою придётся выучить 400 весов для каждого из 120 нейронов. После того, как мы получили вот этот вектор длиной 120, мы применяем к нему два полносвязанных слоя. Первый полносвязанный из 120 нейронов получает 84 нейрона, а второй полносвязанный слой - он уже нам отдает ответ, то есть он отдает нам 10 нейронов, которые потом преобразуются в одну из цифр. Нейронные сети занимаются тем, что сжимают, постепенно, информацию. С каждой итерацией пулингов информации становится всё меньше, потому что в тензорах меньше данных, но эта информация становится всё ближе к итоговым результатам. Перед работой импортируем библиотекиpytorch, numpy,PIL импортируем библиотеку для загрузки датасетовkeras. ПолучаемX_train, Y_train, X_test, Y_test. Мы будем в сеть передавать картинку как трёхмерный тензор. Первый канал - это глубина картинки, в черно-белой картинке это 1 канал с яркостью серого пикселя. А в RGB картинке будут RGB каналы. Соответственно, мы должны нашу картинку, которая на вход пришла (она просто "28 на 28"), разжать до "1 на 28 на 28". Для этого делаем X_train.unsqueeze, а здесь ставим индекс: " в каком измерении мы хотим разжать". То есть X_train у нас - тензор из 60 000 картинок 28 на 28, а мы хотим чтобы было 60 000 на 1 на 28 на 28, и то же самое мы делаем с тестомX_test. Инициализируем функцию loss –функцию ошибки. У нас есть градиентный ADAM, которому на вход передаются все параметры сети, и у него шаг градиентного спуска - 1/1000. И далее нам нужно написать процесс обучения. Процесс обучения будет идти по батчам, батч будет размера 100, каждую эпоху мы будем печатать accuracy (точность) и накапливать loss (вероятность ошибки) на данной эпохе, А внутри каждого батча мы будем сначала обнулять градиенты, после этого вычислять - какие же картинки пойдут в текущий батч. После этого прогонять батч через сеть с помощью функции forward, , после этого считать loss. Далее мы будем считать градиенты и делать шаг градиентного спуска. Вот, батч закончен, мы можем посчитать качество на отложенной выборке, на X_test. Здесь мы снова делаем обсчёт качества на X_test целиком. Тестирование работы нейросети Тестовые данные (из выборки базы MNIST) Картинка из тестового датасета 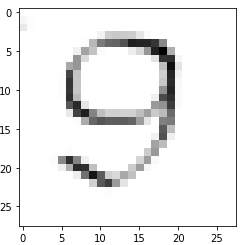 Ответ нейросети: 9  Вывод: Нейросеть предсказала правильный ответ Созданный уникальный набор картинок 28*28 пикселей, нарисованных в Paint. 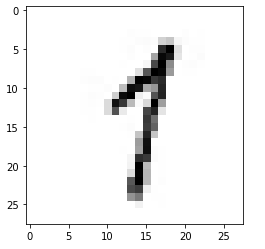 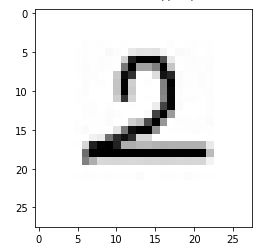 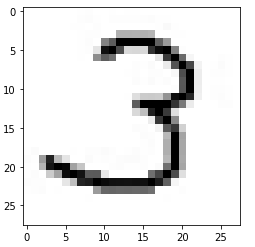 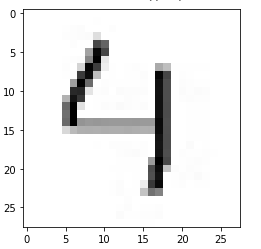 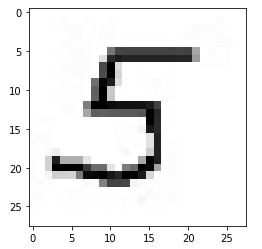    Рисунок 1 Входные данные Вывод Набор картинок с цифрами нейросеть предсказала с такими значениями:
В результате лабораторной работы мы создали рабочую нейросеть, которая определяет нарисованную цифры на входных картинках. Листинг программы 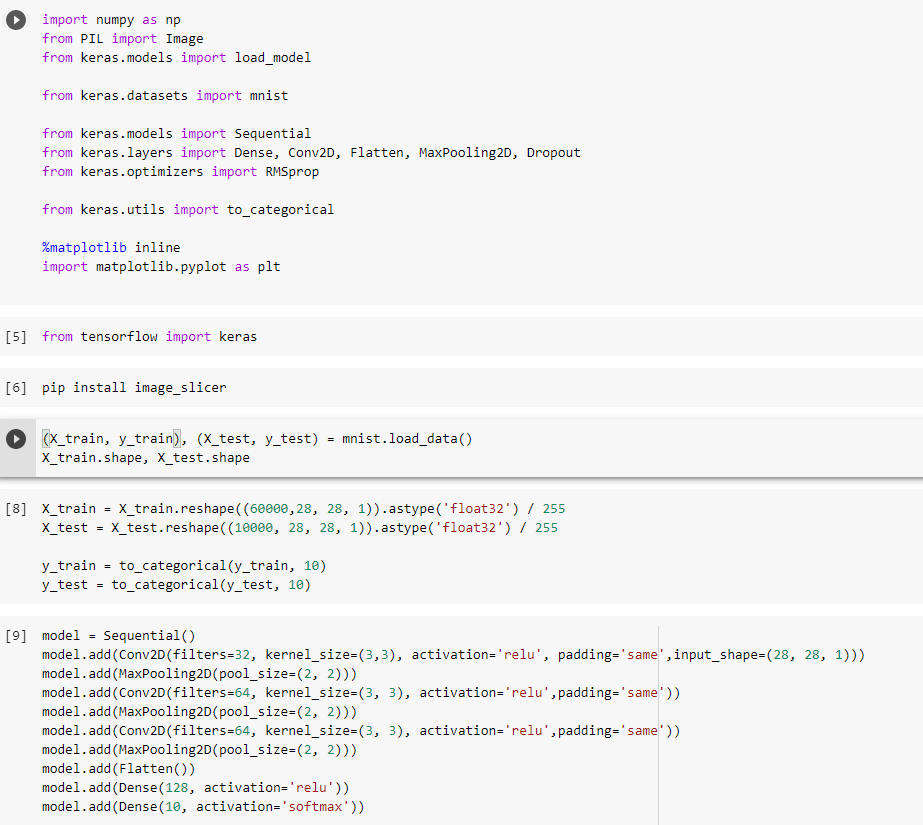  |