курсовая с. КУРСОВАЯ с++ ПЕРВАЯ ПРАВКА. Разработка программы, реализующей алгоритмы сортировки и поиска
 Скачать 0.55 Mb. Скачать 0.55 Mb.
|

|
Методы поиска Для работы со структурами данных, необходима реализация алгоритмов поиска, ведь в значительно крупных списках, поиск нужного элемента осложняется, поиск вручную может занять множество времени. Исследования по нахождению новых методов поиска продолжаются и по сей день. Каждый алгоритм имеет свои плюсы и минусы, рассмотрим поподробнее основные методы поиска: 1. Последовательный поиск. 2. Бинарный поиск. 3. Интерполяционный поиск. 1. Последовательный поиск называется также линейным, является самым простым методом поиска. Алгоритм его реализуется следующим образом – указатель наводится на начало списка, и идет последовательно по всему списку, пока не будет найден нужный элемент, затем указатель будет остановлен. Главным его недостатком является низкая скорость при больших размерах списка, время работы пропорционально количеству элементов в структурах данных. Данный метод используется только в списках небольшого размера [4]. 2. Бинарный поиск реализует алгоритм деления пополам, а затем сравнения среднего значения первого и второго частей списка с искомым значением, и при ближайшем совпадении, выбирается нужная часть списка, и поиск продолжается по такому же принципу. В конце концов, будет найден искомый элемент, либо же нет. Такой метод значительно быстрее работает при реализации поиска по спискам большого размера [5]. 3. Интерполяционный поиск реализует алгоритм интерполирования, который подобен бинарному, но вместо деления области поиска на две равные части, интерполяционный поиск работает в отсортированном массиве значений, и сравнивает искомое значение с средним значением в части массива, если искомое значение меньше или больше части массива, он его отсекает, и продолжает поиск с таким же принципом до тех пор, пока не будет найдено искомое значение. Особенностью такого поиска является отсекание значительно больших значений, чем искомое, или значительно меньших, что позволяет сэкономить время и ресурсы. Данный алгоритм поиска определяется формулой 1 [6]. 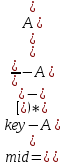 (1) (1)2. Список очередь Цель курсового проекта – реализация списка типа очереди, как типа данных, а также реализация функций работы с ним: добавление и удаление элементов, поиск, открытие из файла и сохранение в файл. Для определения структуры в программном коде C++, используется функция struct. Пример реализации односвязной структуры данных в виде списка изображен на рисунке 4. В данной структуре название списка: “node”. А int data и node*next – компоненты структуры. 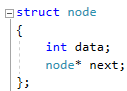 Рисунок 4 – Реализация структуры данных в виде списка Целью курсовой работы является работа со списком типа очередь. Данный тип структуры данных представлен на рисунке 5 и работает по принципу FIFO – первый пришел, первый ушел.  Рисунок 5 – Список типа очереди Добавление элементов в таких структурах данных происходит с конца списка, а удаление с начала. Очередь является динамической структурой, так как предполагает вставку и удаление элементов. Так как по заданию необходима реализация односвязного списка, то каждый элемент имеет только один указатель, на следующий элемент в списке, либо на конец. 2.1 Генерация очереди Для генерации очереди и его элементов, была реализована функция Insert(), вставленная в цикл, зависящий от переменной int n, которая определяет размер списка, пример реализации генерации очереди представлен на рисунке 6.  Рисунок 6 – Генерация списка типа очереди Переменная n задается пользователем, вводящим целочисленное значение с клавиатуры. В процессе генерации значений, используется функция rand(), которая производит случайную генерацию целочисленных значений, находящихся в промежутке от 0 до 99. Однако, эта же функция при повторных генерациях значений, берет те же самые значения из первой попытки генерации для правильной отладки разрабатываемой программы. Для полной рандомизации значений была использована функция srand(), которая при каждом запуске программы, генерирует совершенно новые случайные значения. Чтобы не менять каждый раз аргумент в функции srand(), используется функция time() в аргументах которой используется нулевой указатель - NULL, при выполнении time() с нулевым указателем, возвращается время системы, что обеспечивает полную рандомизацию значений при запуске программы. Реализация генерации случайных значений изображена на рисунке 7. Рисунок 7 – Генерация случайных значений 2.2 Вывод очереди Функция вывода очереди изображена на рисунке 8, реализуется с помощью перечисления элементов, при этом, перечисление начинается с первого значения списка с указателем на следующий элемент. Данная функция принимает указатель на начало очереди, и перечисляет все элементы списка до тех пор, пока не будет возвращено значение NULL, которое означает конец списка. Данная функция только выводит значения на экран консоли элементы списка типа очереди, не возвращает значения. 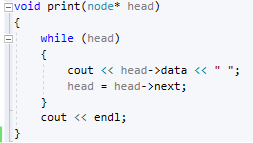 Рисунок 8 – Вывод списка 2.3 Добавление и удаление элементов Функция, реализующая добавление элементов, была показана на рисунке 6, однако сама функция является вызываемой подпрограммой. Более подробное содержание функции изображено на рисунке 9. 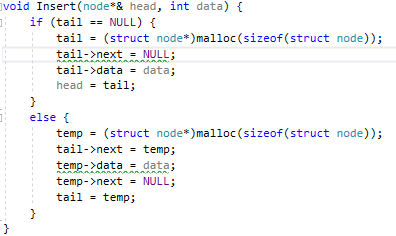 Рисунок 9 – Добавление элементов Данная функция проверяет конец списка, если конец списка равен значению NULL, выполняется выделение памяти для добавления значения. Затем, указателю на следующий элемент в конце списка присваивается значение NULL, означающее конец списка, а переменной tail(хвост), присваивается добавляемое значение, которое вводится пользователем на рисунке 2.11, выделение и подсчет памяти предназначен именно для этого, чтобы определить конец списка. Если же указатель на конец списка, tail, не является пустым, используется переменная temp для выделения памяти и добавления значений, затем указателю на следующий элемент присваивается переменная temp, и происходит добавление значений, после чего значение temp присваивается tail. Функция реализации удаления элементов была создана с проверкой на наличие элементов в списке и присвоение значений из головы(head) списка переменной temp. Если в списке отсутствуют элементы, возвращает сообщение. Иначе, выполняется цикл на неравенство, до тех пор, пока указатель next не будет равен значению NULL, что будет означать конец списка. В функции удаления элементов списка, используется free(), который возвращает память, указанную параметром head(голова). Данная функция изображена на рисунке 10. 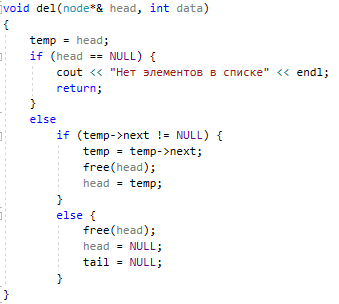 Рисунок 10 – Удаление элементов Таким образом, для удаления и добавления элементов в списке, были использованы основные свойства принципа FIFO(первым пришел, первым ушел), добавление элемента реализуется с конца списка, а удаление – с начала. 2.4 Сортировка очереди попарным слиянием Данный тип сортировки списка реализует принцип – “разделяй и властвуй”. Первым делом, происходит разделение списка на две части. Для этого была реализован метод продвижения указателей на определенное количество позиций. Быстрый указатель проходит два узла, а медленный – один. Таким образом, когда быстрый указатель достигнет конца списка, медленный укажет на середину списка, благодаря чему, список можно разделить на две, примерно равные, части. Затем, происходит рекурсивная сортировка двух отдельных списков, и после этого, происходит процесс объединения двух отсортированных списков в один. Данная функция также учитывает списки, с нулевым или единичным размером. Реализация сортировки очереди попарным слиянием изображена на рисунках 11-13. Недостатком данного метода сортировки является постоянное перевыделение памяти под подсписки, что создает дополнительный расход ресурсов компьютера при выполнении программы [7]. 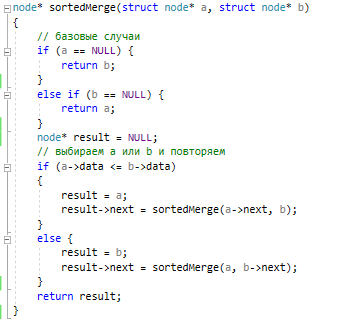 Рисунок 11 – Выбор подсписков для сортировки, рекурсивно 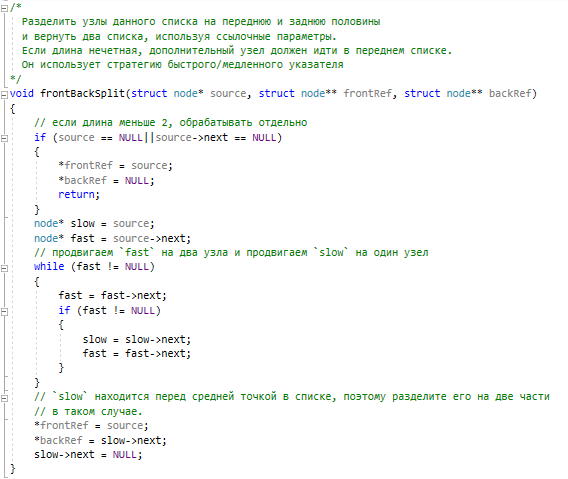 Рисунок 12 – Разделение на две части с быстрым/медленным указателем 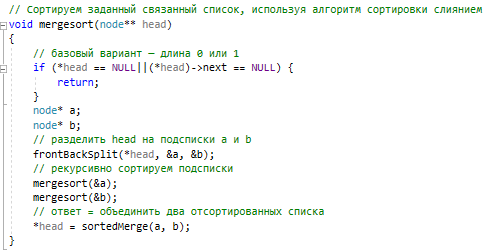 Рисунок 13 – Сортировка списка с слиянием подсписков в один 2.5 Поиск элемента в очереди Алгоритм поиска элемента в очереди изображен на рисунке 14. 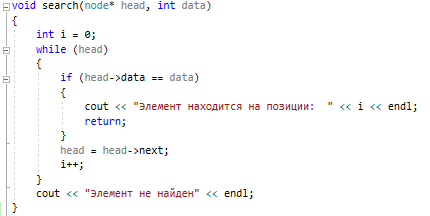 Рисунок 14 – Поиск заданного элемента Данная функция реализована с помощью перебора значений списка и сравнения с искомым значением. При успешном нахождении элемента, выводится индекс самого значения, то есть позиция. При достижении конца списка, и отсутствии искомого значения, выводится иное сообщение, о отсутствии данного значения в списке. Функция поиска является линейной, и самой простой для реализации [8]. 2.6 Сохранение очереди в файл. Считывание очереди из файла. Файл — это объект с именем, который может хранить любую информацию на каком-нибудь носителе данных, как пример USB-флешка, CD диск., жесткий диск компьютера. Каждый файл имеет свое уникальное имя, и в одной директории не могут находиться файлы с одним и тем же именем, причем, учитывается не только название, но и расширение. В С++ открытие файла связывается с потоком, для извлечения или редактирования данных, затем в конце каждой программы, должна быть операция закрытия файла для достоверного сохранения данных. В С++ существует два типа потока файлов, это текстовый и двоичный(бинарный). Текстовый поток содержит последовательность символов, и не возвращает при чтении знаки табуляции, формата текста, такие как “\n” – перенос строки. Двоичный поток содержит последовательность байтов, которые полностью соответствуют тому, что находится на носителе данных. Чтобы производить действия с файлами, необходимо объявить указатель файла. Указателем файла является указатель на структуру типа FILE, чтобы объявить переменную, необходимо передать указатель на переменную, в данном случае – переменная f. Объявление и открытие файла реализуется кодом на рисунке 15. 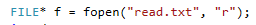 Рисунок 15 – объявление и открытие файла. Файл открывается с помощью функции fopen(), которая принимает в качестве параметров название файла, и режим открытия, в данном случае – r – read, чтение файла. Затем, происходит последовательное чтение данных из файла в список с помощью функции fscanf(), реализация приведена на рисунке 16, цикл идет до тех пор, пока не встретит конец файла – EOF(Ending Of File) Рисунок 16 – чтение данных из файла в список посредством цикла Закрытие файла реализуется функцией fclose(), функция принимает параметр в виде указателя на файл, который необходимо закрыть. В случае с функцией записи в файл, алгоритм другой, используется функция fprintf(), параметрами которой является указатель на файл и формат строки, записываемой в файл. Реализация функции записи списка в файл изображена на рисунке 17. 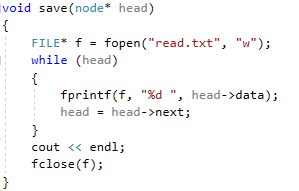 Рисунок 17 – функция записи списка в файл В данном случае, fprintf() в качестве параметров принимает указатель на файл, формат записываемых данных, и считывает данные из списка посредством указателя на начало списка. Также, следует отметить открытие файла с правами на запись – w- write. Код реализации функции чтения списка из файла изображен на рисунке 18. 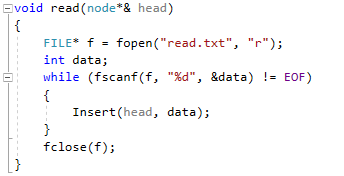 Рисунок 18 – Чтение списка из файла 3. Массив В данной курсовой работе реализована работа с массивом, а именно, поразрядная сортировка, вывод массива, бинарный и интерполяционный поиски, а массив будет заполнен беззнаковыми целыми числами. Массив является последовательной структурой данных, представленный в виде группы ячеек, которые объединены единым именем. В данной программе массив является динамическим, после компиляции задается нужный размер массива и происходит генерация элементов массива в виде чисел. Динамическим он является из-за того, что во время компиляции размер его неизвестен, но может быть задан пользователем или другой программой, то есть, происходит выделение памяти в процессе работы программы. 3.1 Генерация массива В данной программе, генерация массива происходит в отдельной подпрограмме для большего удобства, создание массива происходит в головной функции – int main(), само объявление массива имеет вид указателя на nullptr – отдельный тип данных, имеющий целочисленный тип данных. Данный тип данных используется для затирания адресов элементов при объявлении массива, для предупреждения возможных ошибок при присвоении массиву значения 0 или NULL. Все дело в контроле памяти, при повторных итерациях без присвоения nullptr, старая память не будет очищена без функции delete, что может привести к краху программы, из-за получения старых, неочищенных данных с прошлой итерации. Генерация массива происходит путем использования функций srand() и rand(), их действие описано в разделе 2.1. Реализация генерации массива изображена на рисунке 19 в виде функции random(), массив заполняется случайными целочисленными значениями в диапазоне от 0 до 99. В качестве параметров принимает указатель на массив и его размер.  Рисунок 19 – Генерация массива с случайными значениями 3.2 Сортировка массива Сортировка массива - перераспределение элементов массива по порядку. В данной курсовой работе используется поразрядная цифровая сортировка массива. Данный метод сортировки подразумевает под собой сортировку значений по разрядам, и для этого, нужно определить самое большое значение в массиве, что реализуется функцией getMax() на рисунке 20. 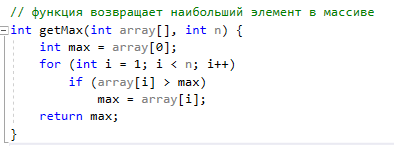 Рисунок 20 – Нахождение наибольшего значения в массиве Затем, используется сортировка подсчетом, где реализуется подсчет количества элементов, расчет совокупности значений элементов, и затем размещение элементов в отсортированном порядке. Массиву присваиваются выходные значения после всех данных операций, и за сортировкой подсчетом, следует сортировка поразрядная, где берется максимальный элемент в массиве, и применяется сортировка подсчетом для реализации алгоритма поразрядной сортировки. Примеры поразрядной сортировки приведены на рисунке 21, а функция сортировки на рисунках 22-23. 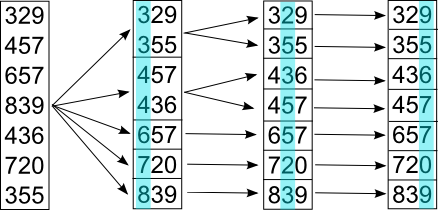 Рисунок 21 – Поразрядная сортировка наглядно  Рисунок 22 – Сортировка подсчетом 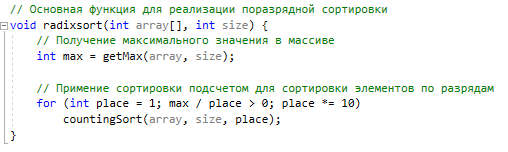 Рисунок 23 – Функция поразрядной сортировки Преимуществом поразрядной сортировки является скорость, и наилучшее время работы сортировки при большой выборке значений, однако и вместе с этим, имеются существенные недостатки, как пример – строгость задания типа данных для сортировки, различные вариации для сортировки беззнаковых и знаковых целых чисел, а реализация сортировки в отношении вещественных чисел крайне сложна[8]. 3.3 Интерполяционный поиск в массиве Данный метод поиска данных работает с отсортированными значениями, и является более быстрым чем бинарный, но стоит учесть, что при делении значений по формуле 1, указанной в разделе 1.3, отбрасываются дробные значения. Реализация данного алгоритма поиска приведена на рисунке 24[8]. 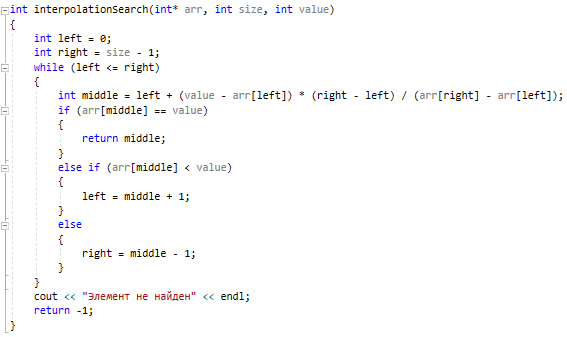 Рисунок 24 – Функция интерполяционного поиска 3.4 Бинарный поиск в массиве Алгоритм бинарного поиска реализуется в отсортированном массиве, принцип действия достаточно прост – массив делится на две примерно равные части, и поиск осуществляется в одной из этих частей, которая делится еще на две части, до тех пор, пока не будет найдено нужное значение. Для этого используется сравнение по значениям, заведомо большие значения сразу отбрасываются в виде частей. Именно поэтому, и нужен отсортированный массив, где значения упорядочены. В неотсортированном массиве поиск может застопориться, или даже не начаться толком. Реализация данного алгоритма поиска приведена на рисунке 25, производится операция сравнения значений с искомым, при нахождении искомого значения сразу же возвращает позицию элемента, который содержит нужное значение, иначе – продолжает поиск. В данном случае, поиск реализуется путем сравнения искомого значения с средним значением в одной из частей массива. При отсутствии искомого значения во всем массиве, выводится сообщение об этом факте[8]. 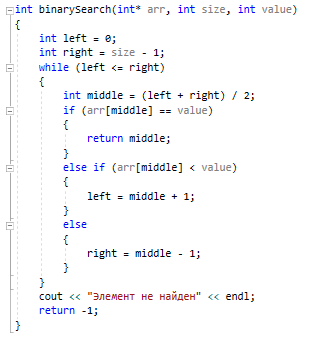 Рисунок 25 – Функция бинарного поиска |