Deductor. Лабораторные работы_РИО2008. Разведка данных в среде deductor методические указания к выполнению лабораторных работ по курсу Информационные системы Иваново 2008
 Скачать 0.69 Mb. Скачать 0.69 Mb.
|

|
Федеральное агентство по образованию Государственное образовательное учреждение высшего профессионального образования «Ивановский государственный энергетический университет имени В.И.Ленина» Кафедра информационных технологий Разведка данных в среде DEDUCTOR Методические указания к выполнению лабораторных работ по курсу «Информационные системы» Иваново 2008
Приводятся рекомендации по выполнению лабораторных работ по курсу «Информационные системы» для студентов, обучающихся по специальности «Прикладная информатика (по областям применения)». Рассматриваются различные методы разведки данных (DataMining) и примеры решения конкретных задач с использованием программного пакета DEDUCTOR. Утверждены цикловой методической комиссией ИВТФ Рецензент кафедра информационных технологи ГОУВПО «Ивановский государственный энергетический университет имени В.И.Ленина» Разведка данных в среде DEDUCTOR Методические указания к выполнению лабораторных работ
Компьютерная верстка М.Е.Сиротовой Редактор Т.В.Соловьева Лицензия ИД № 05285 от 04.07.01г. Подписано в печать 10.04.2008г. Формат 60x84 1/16. Печать плоская. Усл.печ.л. 1,63. Тираж 50 экз. Заказ ГОУВПО «Ивановский государственный энергетический университет имени В.И. Ленина» 153003, г. Иваново, Рабфаковская, 34.
Методы Data Mining входят в платформе Deductor в состав методов извлечения знаний из баз данных (Knowledge Discovery in Databases). Процесс извлечения знаний выглядит следующим образом (рис.1). 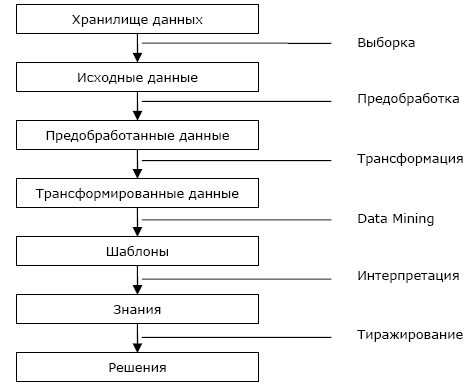 Рис.1 DM – Data Mining – «разведка» данных. Это метод обнаружения в «сырых» данных ранее неизвестных, нетривиальных, практически полезных и доступных для интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. DM обеспечивает решение пяти задач — классификация, кластеризация, регрессия, ассоциация, последовательность.
Иногда специально выделяют задачу анализа отклонений — выявление наиболее нехарактерных шаблонов. Для анализа отклонений необходимо сначала построить шаблон типичного поведения изучаемого объекта. Например, поведение человека при использовании кредитных карт. Тогда будет известно, что клиент (покупатель) использует карту регулярно два раза в месяц и приобретает товар в пределах определенной суммы. Отклонением будет, например, незапланированное приобретение товара по данной карте на большую сумму. Это может говорить о ее использовании другим лицом, то есть о факте мошенничества. Методика анализа с использованием механизмов Data Mining базируется на различных алгоритмах извлечения закономерностей из исходных данных, результатом работы которых являются модели. Таких алгоритмов довольно много, но, несмотря на их обилие, использование машинного обучения и т.п., они не способны гарантировать качественное решение. Никакой самый изощренный метод сам по себе не даст хороший результат, т.к. критически важным становится вопрос качества исходных данных. Чаще всего именно качество данных является причиной неудачи. Ниже описана методика, следуя которой, можно подготовить качественные данные в нужном объеме для анализа. В этой последовательности действий все достаточно просто и логично, но, несмотря на это, пользователи почти всегда допускают одни и те же тривиальные ошибки. Общая схема использования методов Data Mining состоит из следующих шагов (рис.2). 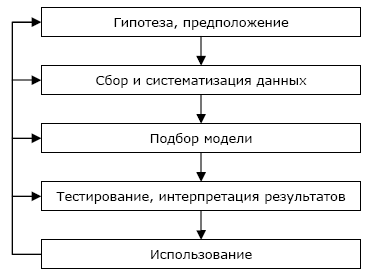 Рис.2 Эта последовательность действий не зависит от предметной области, поэтому ее можно использовать для любой сферы деятельности.
Введение В настоящее время в нашей стране сильно ощущается кризис неплатежей. Действующее налоговое законодательство закрепляет обязанность субъектов налогообложения вносить налоговые платежи в установленных размерах и в определенные сроки. Однако исполнение этого законодательства пока оставляет желать лучшего. Стало нормой уклонение от налоговой повинности легальными – когда удается полностью или частично избежать налогообложения, не нарушая при этом действующих правовых норм – и нелегальными, т. е. запрещенными законом способами. Исходя из этого у налоговых органов стоит серьезная проблема – контроль за правильностью, своевременностью и полнотой взимания налогов. Важнейшим фактором повышения эффективности контрольной работы налоговой инспекции является совершенствование действующих процедур контрольных проверок. Анализ показал, что необходимыми признаками любой действенной системы налогового контроля является наличие эффективной системы отбора налогоплательщиков для проведения документальных проверок, дающей возможность выбрать наиболее оптимальное направление использования ограниченных кадровых и материальных ресурсов налоговой инспекции, добиться максимальной результативности налоговых проверок при минимальных затратах усилий и средств, затрачиваемых на их проведение, за счет отбора для проверок таких налогоплательщиков, вероятность обнаружения налоговых нарушений у которых представляется наибольшей. Постановка задачи В соответствии с рассмотренной ранее методикой первым действием является выдвижение гипотез. Гипотезой в данном случае будем считать предположение о влиянии определенных факторов на исследуемую нами задачу. Форма этой зависимости в данном случае значения не имеет. Эту задачу должны решать эксперты – специалисты в предметной области. Полагаться можно и нужно на их опыт и здравый смысл. Нужно постараться максимально использовать их знание о предмете и собрать как можно больше гипотез/предположений. Обычно для этих целей хорошо работает тактика мозгового штурма. На первом шаге нужно собрать и систематизировать все идеи, их оценку будем производить позже. Результатом данного шага должен быть список с описанием всех факторов. В данном случае в качестве таких факторов, влияющих на величину уплаченного налога, выступают сведения об организации-налогоплательщике: стоимость основных средств, нематериальных активов, запасов, отложенных налоговых активов и сфера деятельности организации. Также влияние на выявление нарушений влияют величина когда-либо взимаемого максимального штрафа (за выявленные нарушения) и задекларированные расходы и доходы. Теперь определим состав необходимых для решения проблемы методов.
Извлечение из БД. Предварительная обработка Импорт данных Импорт данных является отправной точкой анализа данных. Импорт в Deductor может осуществляться из популярных форматов хранения данных, таких как Excel, Access, MS SQL, Oracle, Текстовый файл и прочих. Кроме того, имеется универсальный доступ к любому источнику данных посредством ADO или ODBC. В налоговой инспекции используются таблицы в формате Text (текстовый файл с разделителями), из которого и будет осуществляться импорт в Deductor (рис.3).  Рис.3 Импорт осуществляется путем вызова мастера импорта на панели «Сценарии» (рис.4).  Рис.4 После запуска мастера импорта укажем тип импорта “Text (Direct)” и перейдем к настройке импорта. Укажем имя файла, из которого необходимо получить данные: "Data.txt" (рис.5). 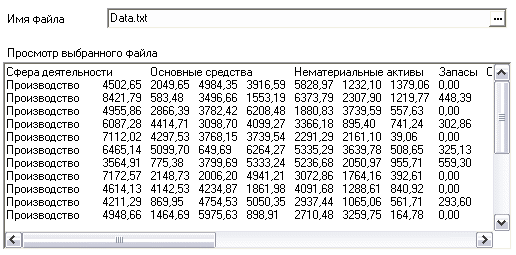 Рис.5 Далее предлагается настроить параметры импорта текстового файла, где указать символ-разделитель (символ табуляции) и обозначить то, что первая строка является заголовком (рис.6). 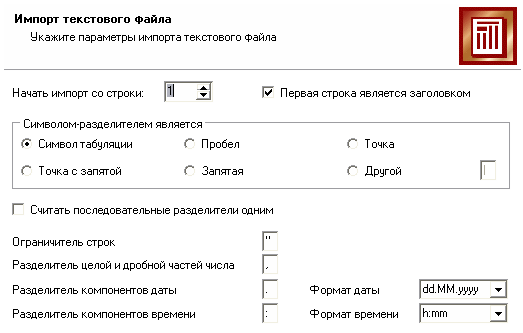 Рис.6 Далее перейдем к настройке свойств полей. На этом шаге мастера предоставляется возможность настроить имя, название (метку), размер, тип данных, вид данных и назначение. Некоторые свойства (например, тип данных) можно задавать для выделенного набора столбцов. Вид данных определяет – конечный это набор (дискретные) или бесконечный (непрерывные). Назначение столбцов определяет характер их использования в алгоритмах обработки (при импорте можно оставить значение по умолчанию) (рис.7).  Рис.7 Далее проводится процесс загрузки данных. После импорта данных на следующем шаге мастера необходимо выбрать способ отображения данных. В данном случае самым информативным является таблица, выберем ее (рис.8).  Рис.8 После всех действий сценарий будет иметь вид, представленный на рис.9. Рис.9 Предобработка данных Для эффективного применения методов Data Mining следует обратить серьезное внимание на вопросы предобработки данных. Данные могут содержать пропуски, шумы, аномальные значения и т.д. Кроме того, данные могут быть избыточны, недостаточны и т.д. В некоторых задачах требуется дополнить данные некоторой априорной информацией. Ошибочно предполагать, что если подать данные на вход системы в существующем виде, то на выходе будут получены полезные знания. Входные данные должны быть качественны и корректны. В данном случае актуальной будет проверка на наличие пропусков. Часто бывает так, что в столбце некоторые данные отсутствуют в силу каких либо причин (данные не известны либо их забыли внести и т.п.). Обычно из–за этого пришлось бы убрать из обработки все строки, которые содержат пропущенные данные. Для восстановления пропусков следует запустить мастер парциальной обработки (рис.10). 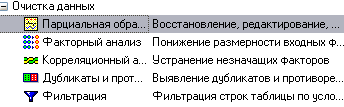 Рис.10 На следующем шаге необходимо выбрать тип обработки «Максимальное правдоподобие» для всех столбцов (рис.11).  Рис.11 Остальные параметры не меняются, т.е. не будем проводить редактирование аномальных значений и спектральную обработку. После выполнения процесса обработки пропуски в данных ликвидируются, что и было необходимо сделать. Сценарий после добавления к загруженным данным обработчика "Парциальная обработка" будет выглядеть следующим образом (рис.12)  Рис.12 Задание. Импортируйте текстовый файл с данными той же структуры "Task 1-2.txt" и выполните восстановление пропущенных значений. Укажите значения пропущенных ячеек в столбце «Основные средства» (записи номер 51 и 57), в столбце «Нематериальные активы» (запись номер 21), в столбце «Запасы» (записи номер 9 и 22). Сделайте выводы по работе алгоритма подстановки.
Корреляционный анализ Корреляционный анализ применяется для оценки зависимости выходных полей данных от входных факторов и устранения незначащих факторов. Принцип корреляционного анализа состоит в поиске таких значений, которые в наименьшей степени коррелированы (взаимосвязаны) с выходным результатом. Такие факторы могут быть исключены из результирующего набора данных практически без потери полезной информации. Критерием принятия решения об исключении является порог значимости. Если корреляция (степень взаимозависимости) между входным и выходным факторами меньше порога значимости, то соответствующий фактор отбрасывается как незначащий. Корреляция представляет собой меру зависимости переменных. Наиболее известна корреляция Пирсона. При вычислении корреляции Пирсона предполагается, что переменные измерены, как минимум, в интервальной шкале. Коэффициент корреляции Пирсона (r) представляет собой меру линейной зависимости двух переменных. Коэффициенты корреляции изменяются в пределах от –1,00 до +1,00. Значение –1,00 означает, что переменные имеют строгую отрицательную корреляцию (две переменные могут быть связаны таким образом, что при возрастании значений одной из них значения другой убывают). Значение +1,00 означает, что переменные имеют строгую положительную корреляцию (связь между двумя переменными может быть следующей – когда значения одной переменной возрастают, значения другой переменной также возрастают). Отметим, что значение 0,00 означает отсутствие корреляции. Для проведения корреляционного анализа используем данные, подготовленные в лабораторной работе №1. Добавляем к полученному сценарию новую ветку «Устранение незначащих факторов» после ветки «Восстановление пропущенных значений» (рис.13):  Рис.13 В мастере корреляционного анализа зададим все доходы, расходы и активы (основные средства, запасы и пр.) входными полями, а поле Возможный доход – выходным, поле Сфера деятельности будет непригодным, т.к. имеет строковый тип данных (рис.14).  Рис.14 Следующий шаг предлагает запустить процесс корреляционного анализа. После завершения процесса на следующем шаге предлагается выбрать, какие факторы оставить для дальнейшей работы. Это делается либо вручную, основываясь на значениях матрицы ковариации, либо путем указания порога значимости (по умолчанию порог значимости равен 0,05). Включать в дальнейшую обработку будем те факторы, которые преодолели порог значимости в 0,5 (рис.15). 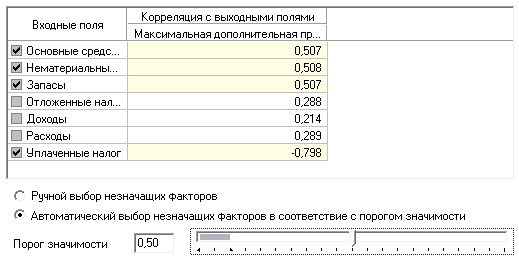 Рис.15 Таким образом, корреляционный анализ позволил проанализировать влияние входных факторов на результат и исключить незначащие факторы из дальнейшего анализа. Задание. Используя результаты обработки прошлого задания, проведите устранение незначащих факторов и укажите пороги значимости, а также включенные/исключенные из дальнейшей обработки факторы при пороге значимости 0,25.
Кластерный анализ Самоорганизующаяся карта Кохонена является разновидностью нейронной сети. Она применяется, когда необходимо решить задачу кластеризации, т.е. распределить данные по нескольким кластерам. Алгоритм определяет расположение кластеров в многомерном пространстве факторов. Исходные данные будут относиться к какому-либо кластеру в зависимости от расстояния до него. Многомерное пространство трудно для представления в графическом виде. Механизм же построения карты Кохонена позволяет отобразить многомерное пространство в двумерном, которое более удобно и для визуализации и для интерпретации результатов аналитиком. Применение алгоритма Так как алгоритм SOM сочетает в себе два основных направления — векторное квантование и проецирование, то можно найти и основные применения этого алгоритма. Данную методику можно использовать для поиска и анализа закономерностей в исходных данных. При этом после того, как нейроны размещены на карте, полученная карта может быть отображена. Рассмотрим различные способы отображения полученной карты. Раскраска, порожденная отдельными компонентами При данном методе отрисовки полученную карту можно представить в виде слоеного пирога, каждый слой которого представляет собой раскраску, порожденную одной из компонент исходных данных. Полученный набор раскрасок может использоваться для анализа закономерностей, имеющихся между компонентами набора данных. После формирования карты мы получаем набор узлов, который можно отобразить в виде двумерной картинки. При этом каждому узлу карты можно поставить в соответствие участок на рисунке, четырех– или шестиугольный, координаты которого определяются координатами соответствующего узла в решетке. Теперь для визуализации осталось только определить цвет ячеек этой картинки. Для этого и используются значения компонент. Самый простой вариант — использование градаций серого. В этом случае ячейки, соответствующие узлам карты, в которые попали элементы с минимальными значениями компонента или не попало вообще ни одной записи, будут изображены черным цветом, а ячейки, в которые попали записи с максимальными значениями такого компонента, будут соответствовать ячейки белого цвета. В принципе, можно использовать любую градиентную палитру для раскраски. Полученные раскраски в совокупности образуют атлас, отображающий расположение компонент, связи между ними, а также относительное расположение различных значений компонент. Отображение кластеров Кластером будет являться группа векторов, расстояние между которыми внутри этой группы меньше, чем расстояние до соседних групп. Структура кластеров при использовании алгоритма SOM может быть отображена путем визуализации расстояния между опорными векторами (весовыми коэффициентами нейронов). При использовании этого метода чаще всего используется унифицированная матрица расстояний (u-matrix), вычисляется расстояние между вектором весов нейрона в сетке и его ближайшими соседями. Затем эти значения используются для определения цвета, которым этот узел будет отрисован. Обычно используют градации серого, причем чем больше расстояние, тем темнее отрисовывается узел. При таком использовании узлам с наибольшим расстоянием между ними и соседями соответствует черный цвет, а близлежащим узлам — белый. Реализация Используются данные, подготовленные по результатам выполнения предыдущих лабораторных работ. Добавляем к полученному сценарию новую ветку «Кластеризация», после ветки «Устранение незначащих факторов» (рис.16).  Рис.16 Запустим мастер обработки и выберем из списка метод обработки «Карта Кохонена». На втором шаге мастера настроим назначения столбцов. Укажем все столбцы входными (этот обработчик позволяет задать все поля входными и не указывать выходные), кроме поля «Максимальная дополнительная прибыль», которое зададим выходным. Т.е. предположим, что на основании значений поля «Максимальная дополнительная прибыль» организации могут быть отнесены к тому или иному классу. На третьем шаге мастера необходимо настроить способ разделения исходного множества данных на тестовое и обучающее, а также количество примеров в том и другом множестве. Укажем, что данные обоих множеств берутся случайным образом, зададим размер тестового множества равным десяти примерам путем изменения значения столбца «Размер в строках» строки «Тестовое множество». Следующий шаг предлагает настроить параметры карты (количество ячеек по Х и по Y, их форму) и параметры обучения (способ начальной инициализации, тип функции соседства, необходимость перемешивания строк обучающего множества и количество эпох, через которые необходимо перемешивание). Значения по умолчанию вполне подходят (рис.17).  Рис.17 На пятом шаге мастера необходимо настроить параметры остановки обучения. Обучение будем останавливать при значении максимальной ошибки обучающего множества меньше 0,05 (рис.18).  Рис.18 На шестом шаге настраиваются остальные параметры обучения – способ начальной инициализации, тип функции соседства и также параметры кластеризации – автоматическое определение числа кластеров с соответствующим уровнем значимости либо фиксированное количество кластеров. Предоставляется возможность настроить интервалы обучения. Каждый интервал задается количеством эпох, радиусом обучения и скоростью обучения. Укажем фиксированное количество кластеров, равное трем (рис.19).  Рис.19 На седьмом шаге предлагается запустить сам процесс обучения. Во время обучения можно посмотреть количество распознанных примеров и текущие значения ошибок. Здесь необходимо нажать на кнопку пуск и дождаться завершения процесса обработки (рис.20). 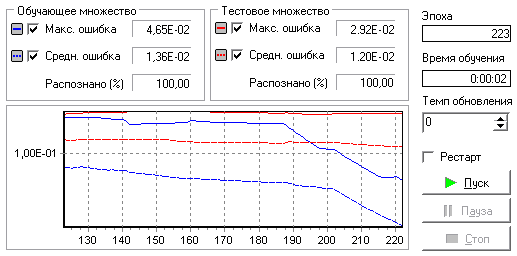 Рис.20 После этого необходимо в списке визуализаторов выбрать появившуюся теперь «Карту Кохонена» для просмотра результатов кластеризации, а также визуализатор «Что-если» для прогнозирования класса организации (проводить проверку или нет) (рис.21).  Рис.21 Далее в мастере настройки отображения карты Кохонена необходимо указать, чтобы отображались все поля, также следует поставить флажок «Границы кластеров» (рис.22).  Рис.22 После этого можно увидеть полученные результаты обучения (рис.23). 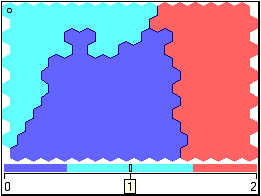 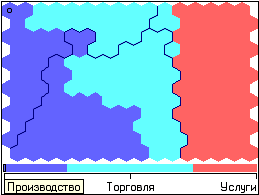 Рис.23 Как видно, все предприятия, работающие в сфере оказания услуг, относятся ко второму кластеру. Кроме того, обработчик добавил новые поля, значения которых могут оказаться весьма полезными для эксперта, в дальнейшем использующего результаты кластеризации.
Полученные результаты кластеризации экспортируются во внешний текстовый файл. Далее эксперт проанализирует эти данные, добавит новый столбец «Проверка», где проставит вид проводимой проверки («Полная», «Не полная» или «Не проводить»). Задание. Классифицируйте организации со следующими параметрами.
Классификация с помощью деревьев решений Деревья решений (decision trees) являются одним из наиболее популярных подходов к решению задач добычи данных. Они создают иерархическую структуру классифицирующих правил типа «ЕСЛИ…ТО…» (if-then), имеющую вид дерева. Чтобы принять решение, к какому классу следует отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид «значение параметра А больше В?». Если ответ положительный, осуществляется переход к правому узлу следующего уровня. Затем снова следует вопрос, связанный с соответствующим узлом и т. д. В каждом узле бинарных деревьев ветвление производится по двум направлениям (т. е. на вопрос, заданный в узле, имеется только два варианта ответов, например, Да или Нет). Однако в общем случае ответов, а следовательно, и ветвей, выходящих из узла, может быть больше. Дерево решений состоит из узлов – где производится проверка условия, и листьев – конечных узлов дерева, указывающих на класс (узлов решения). Также после построения присутствует информация о достоверности того или иного правила, его значимость. С помощью данного инструмента можно узнать ранг значимости каждого фактора (наиболее значимые факторы находятся на верхних уровнях дерева). Полученную обучающую выборку (сформированную экспертом) загружают в систему (текстовый файл " training_sample.txt"). Эксперт формирует таблицу из результатов кластеризации путём оставления столбцов Основные средства, Нематериальные активы, Запасы, Уплаченный налог и сфера деятельности, и добавления к ним столбца Проверка, в который он заносит свои оценки назначаемой проверки. Добавляем к корню дерева сценария новую ветку «Загрузка экспертных данных» и после неё ветку «Построение решений» (рис.24):  Рис.24 Выберем в качестве обработки дерево решений. В мастере построения дерева решения на втором шаге настроим «Название организации» как информационный, «Проверка» – как выходной, остальные поля – входные. Далее предлагается настроить способ разбиения исходного множества данных на обучающее и тестовое. Зададим способ разбиения по порядку, когда данные для тестового и обучающего множества берутся из исходного набора подряд, т.е. для обучающего множества будут использоваться проанализированные экспертом данные. На следующем шаге мастера предлагается настроить параметры процесса обучения, а именно минимальное количество примеров, при котором будет создан новый узел (пусть узел создается, если в него попали два и более примеров), а также предлагается возможность строить дерево с более достоверными правилами и отсекать узлы дерева. Включим данные опции (рис.25).  Рис.25 На следующем шаге мастера запускается сам процесс построения дерева. Также можно увидеть информацию о количестве распознанных примеров (рис.26). 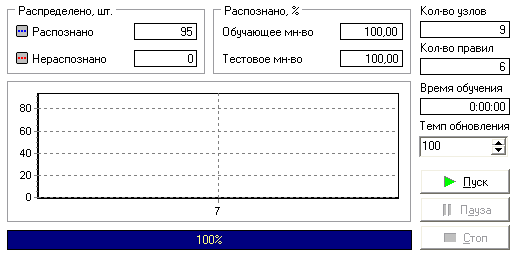 Рис.26 Получили следующее дерево решений и правила в соответствии с ним (рис.27).  Рис.27 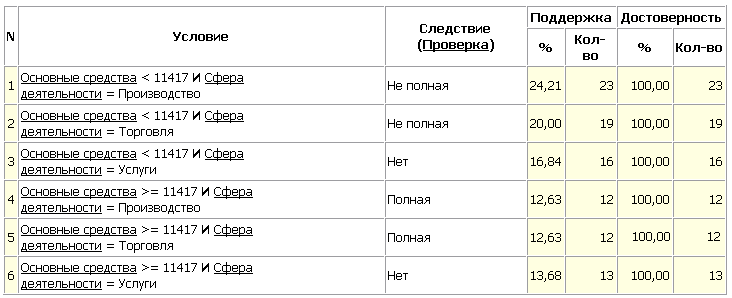 Рис.28 С помощью визуализатора "Что-если" можно протестировать модель на других данных, подставляя соответствующие значения (рис.29).  Рис.29 Задание. Определите вид проверки для следующих организаций.
OLAP (On-Line Analytical Processing) является ключевым компонентом организации хранилищ данных. Эта технология основана на построении и визуализации многомерных кубов данных с возможностью произвольного манипулирования информацией, содержащейся в кубе. Это позволяет представить информацию для анализа в любом разрезе. Для решения задачи многомерного представления данных также весьма полезны сведения по объемам сбора того или иного вида налога за некоторый период, к примеру, за только что завершившийся отчетный период. Организации-налогоплательщики работают не в одной сфере деятельности, а в различных (производство, оказание услуг и т.д.). Первые два простейших вопроса, на которые нам сразу же хотелось бы иметь ответы, – это объемы сбора налогов (конкретных видов) по отдельным сферам деятельности за отчетный период. Очевидно, что «ответ» на каждый из этих вопросов будет оформлен в виде двумерной таблицы. В первом случае строками и столбцами этой таблицы соответственно будут названия налога, период и суммы, а во втором – названия сферы деятельности и суммы. Однако анализировать информацию в таком виде неудобно. Возникает потребность «соединить» данные нескольких таблиц (представим их в виде трехмерного куба). В итоге в таком отчете будет фигурировать три равноправных аналитических измерения (город, товар и месяц), и вместо двумерных (рис.30).  Рис.30. Данные для обработки находятся в файле "OLAPData.txt". Импортируем данные и в визуализаторах выбираем "OLAP анализ"/"Куб". При многомерном представлении данных вся информация представляется структурой типа «звезда», где в центре расположены таблицы фактов, а «лучами» являются измерения. Измерения могут быть как простыми списками, например, дата (Период), так и содержать дополнительные столбцы, называемые свойствами (рис.31). 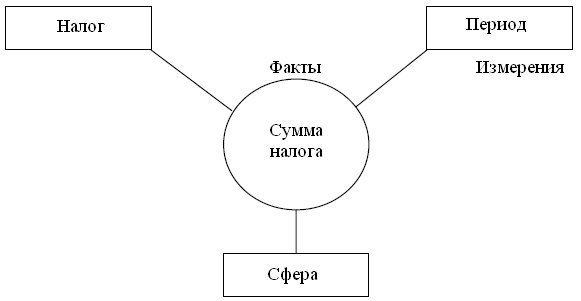 Рис.31 В соответствии с этим назначаем поля Период, Вид налога, Сфера деятельности измерениями, а поле Уплаченные налог – фактом.  Рис.32 Измерения могут быть размещены в строках и столбцах кросс-таблицы. В мастере настройки отображения изначально весь список выбранных измерений отображается в окне «Доступные измерения». Нажимая кнопки «>« и «>>« справа и снизу от этого окна, можно размещать выбранные измерения в строках и столбцах таблицы. Один из способов размещения приведен на рис.33. 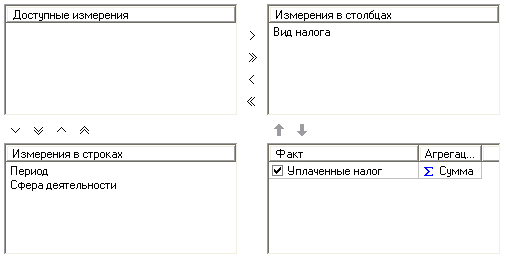 Рис.33 Здесь можно также выбрать, какие факты отображать в кросс-таблице на пересечении измерений и какую функцию применять при их агрегации (объединении). В данном примере факт «Уплаченный налог» будет суммироваться. В результате получим кросс-таблицу, по которой удобно анализировать информацию, например, наибольшая сумма Налога 1 была собрана в 2002 г., причём наибольший вклад в эту сумму был с предприятий, работающих в сфере торговли (рис.34). 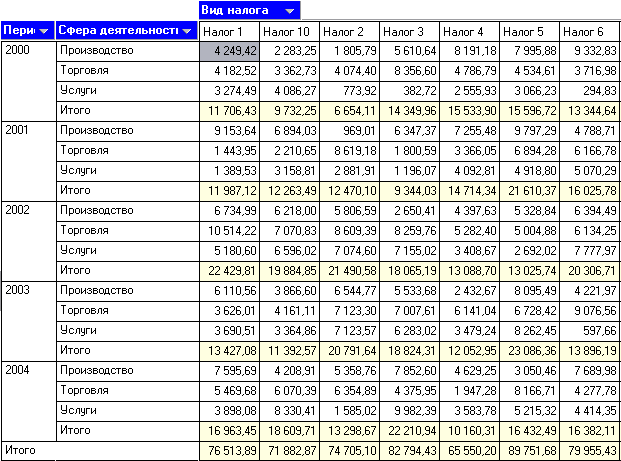 Рис.34 Задание. Измените куб и интерпретируйте полученные результаты.
Прогнозирование Прогнозирование позволяет получать предсказание значений временного ряда на число отсчетов, соответствующее заданному горизонту прогнозирования. Алгоритм прогнозирования работает следующим образом. Пусть в результате преобразования методом скользящего окна была получена последовательность временных отсчетов: X(-n), ..., X(-2), X(-1), X, где X – текущее значение. Прогноз на X(+1) строится на основании построенной модели. Чтобы построить прогноз для значения X(+2), нужно сдвинуть всю последовательность на один отсчет влево, чтобы ранее сделанный прогноз X(+1) тоже вошел в число исходных значений. Затем снова будет запущен алгоритм расчета прогнозируемого значения – X(+2) будет рассчитан с учетом X(+1) и так далее в соответствии с заданным горизонтом прогноза. Для настройки алгоритма прогнозирования необходимо задать горизонт прогноза, а также поля таблицы, которые необходимо подавать на вход модели для построения прогноза (для вычисления выходного поля модели). Проведем прогнозирование количества должников по месяцам с помощью нейросети. Данные для прогнозирования находятся в файле "Prognoz.txt" и содержат статистику количества должников по месяцам за предыдущие годы. Импортируем их (рис.35). 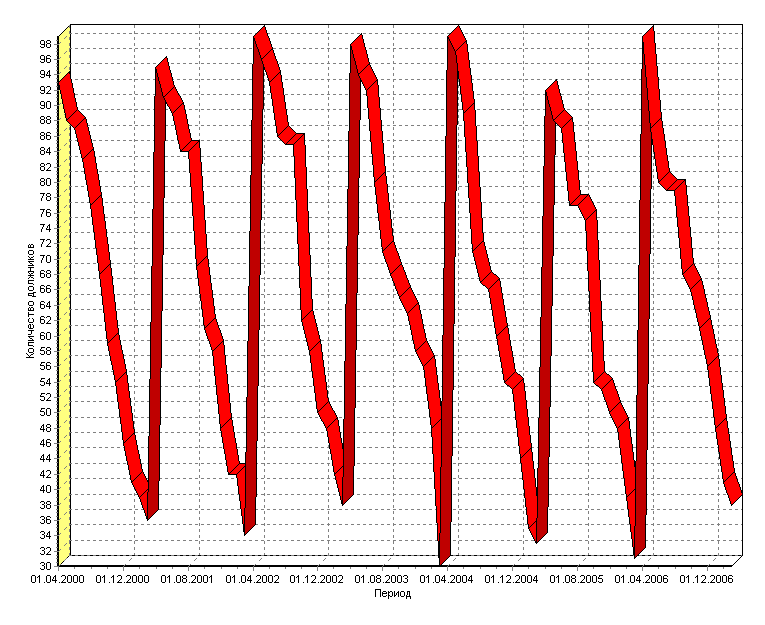 Рис.35 Для дальнейшего прогнозирования необходимо соответствующим образом подготовить данные. При прогнозировании временных рядов при помощи нейросети требуется подавать на вход анализатора значения нескольких, смежных, отсчетов из исходного набора данных. Такой метод отбора данных называется скользящим окном (окно – поскольку выделяется только некоторый непрерывный участок данных, скользящее – поскольку это окно «перемещается» по всему набору). При этом эффективность реализации заметно повышается, если не выбирать данные каждый раз из нескольких последовательных записей, а последовательно расположить данные, относящиеся к конкретной позиции окна, в одной записи. Значения в одном из полей записи будут относиться к текущему отсчету, а в других – смещены от текущего отсчета «в будущее» или «в прошлое». Таким образом, преобразование скользящего окна имеет два параметра: «глубина погружения» – количество «прошлых» отсчетов, попадающих в окно, и «горизонт прогнозирования» – количество «будущих» отсчетов. Следует отметить, что для граничных (относительно начала и конца всей выборки) положений окна будут формироваться неполные записи, т.е. записи, содержащие пустые значения для отсутствующих прошлых или будущих отсчетов. Алгоритм преобразования позволяет исключить такие записи из выборки (тогда для нескольких граничных отсчетов записи формироваться не будут) либо включить их (тогда формируются записи для всех имеющихся отсчетов, но некоторые из них будут неполными). Отметим, что для правильного формирования скользящего окна данные должны быть соответствующим образом упорядочены. В нашем случае имеются данные по количествам должников по месяцам за 7 лет, значит, выбираем поле "Количество должников" как используемое и выбираем глубину погружения 12, т.к. в году 12 месяцев (рис.36). 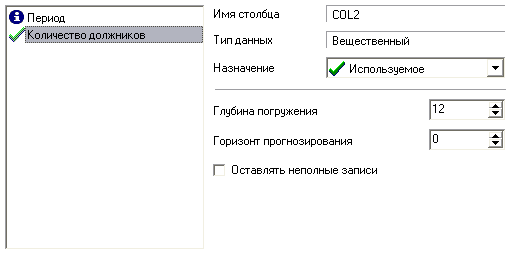 Рис.36 Далее предстоит построить модель, для чего в качестве обработчика выбираем "Нейросеть". Поле "Период" делаем информационным, все поля, сформированные скользящим окном (Количество должников-1 – Количество должников-12), – входными, а поле "Количество должников" – выходным (рис.37). 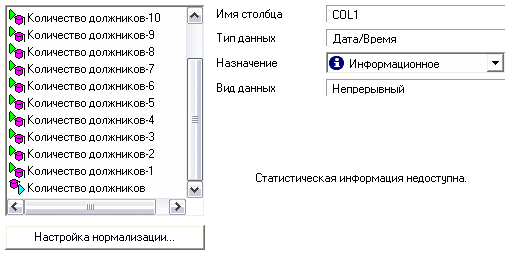 Рис.37 Далее назначаем количество элементов в тестовом и обучающем множестве и выбираем структуру нейронной сети. Оставим параметры по умолчанию (рис.38). 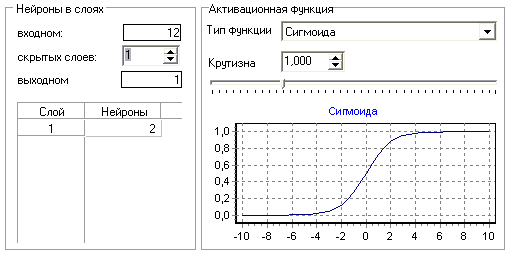 Рис.38 Далее можно выбрать алгоритм и параметры обучения, оставляем и их по умолчанию (рис.39).  Рис.39 На следующем шаге нужно настроить параметры остановки обучения, где выберем остановку обучения, если максимальная ошибка обучающего множества меньше 0,05, т.е. при данной ошибке качество обучения будет достаточно приемлемым (рис.40).  Рис.40 Запускаем обучение нейронной сети (рис.41). 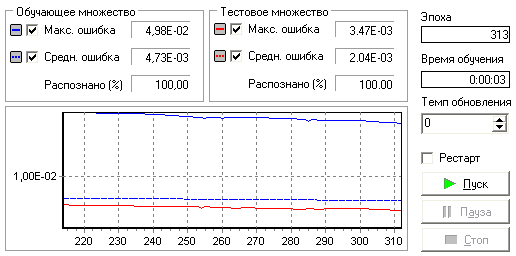 Рис.41 Обучение остановлено на 313 эпохе, т.е. максимальная ошибка стала меньше 0,05. Как видно из результатов обучения, были распознаны все элементы обучающего и тестового множеств, значит изменение параметров нейросети не требуется. Далее к этой ветке сценария добавляем обработчик "Прогнозирование", где задаем горизонт прогноза, равный 4, т.е. строим прогноз на 4 последующих месяца (рис.42).  Рис.42 Получился сценарий (рис.43).  Рис.43 Выбираем визуализатор "Таблица" и оставляем в ней только поля "Количество должников" и "Шаг прогноза".
Таким образом нам удалось построить прогноз количества должников на апрель, май, июнь и июль 2007 года. Задание. Постройте прогноз на год, используя данные за 3 года, приведенные в файле "Task 6.txt", расположенного в папке примеров Deductor. |