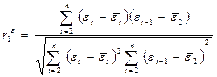АЛГОРИТМЫ ПОСТРОЯНИЕ ЛИНЕЙНЫХ ПО ПАРАМЕТРАМ МОДЕЛЕЙ. Реферат по дисциплине структура и алгоритмы обработки данных алгоритмы построяние линейных по параметрам моделей
 Скачать 136.84 Kb. Скачать 136.84 Kb.
|

|
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ УНИВЕРСИТЕТ «МОСКОВСКИЙ ЭНЕРГЕТИЧЕСКИЙ ИНСТИТУТ» Кафедра управления и информатики РЕФЕРАТ ПО ДИСЦИПЛИНЕ СТРУКТУРА И АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ «АЛГОРИТМЫ ПОСТРОЯНИЕ ЛИНЕЙНЫХ ПО ПАРАМЕТРАМ МОДЕЛЕЙ»
Москва, 2022 ОГЛАВЛЕНИЕВВЕДЕНИЕ 3 1.ПОСТАНОВКА ЗАДАЧИ, СОСТАВ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ И ОСНОВНЫЕ МЕТОДЫ, И АЛГОРИТМЫ ЧИСЛЕННОГО ЛИНЕЙНОГО РЕГРЕССИОННОГО АНАЛИЗА 4 2.ПОСЛЕДСТВИЯ НАРУШЕНИЯ ПРЕДПОСЫЛОК РЕГРЕССИОННОГО АНАЛИЗА 6 3.ШАГОВЫЕ АЛГОРИТМЫ ВЫБОРА «НАИЛУЧШЕЙ МОДЕЛИ» 8 4.АНАЛИЗ КАЧЕСТВА МОДЕЛИ: КОЛИЧЕСТВО ПОКАЗАТЕЛЕЙ КАЧЕСТВА ДИСПЕРСНОГО АНАЛИЗА, АНАЛИЗ ОСТАТКОВ 11 ЗАКЛЮЧЕНИЕ 13 СПИСОК ЛИТЕРАТУРЫ 14 ВВЕДЕНИЕЦель освоения и написания реферата являеля: привести алгоритмы построения линейных по параметрам моделей. Задачи: - провести постановку задач, состав экспериментальных данных и основные методы, и алгоритмы численного линейного регрессионного анализа; - выявить последствия нарушения предпосылок регрессионного анализа; - описать шаговые алгоритмы выбора «наилучшей модели»; - выполнить анализ качества модели: количественные показатели качества, элементы дисперсионного анализа, анализ остатков. ПОСТАНОВКА ЗАДАЧИ, СОСТАВ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ И ОСНОВНЫЕ МЕТОДЫ, И АЛГОРИТМЫ ЧИСЛЕННОГО ЛИНЕЙНОГО РЕГРЕССИОННОГО АНАЛИЗАЗадача рекуррентного, или итеративного, оценивания может быть представлена как задача улучшения старой оценки. Наличие такой оценки означает использование некоторой модели (например, в виде программы для ЦВМ), Входной одной сигнал одновременно подается на объект и модель с настраиваемыми параметрами. Настройка параметров производится с помощью настраивающего устройства, на вход которого поступают выходные сигналы объекта и модели[1]. Основные методы, применяемые для численного линейного регрессивного анализа. Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид: y=ax+b a, b – коэффициенты линейного уравнения регрессии; x – независимая переменная; y – зависимая переменная. Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов: 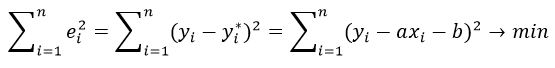 частные производные функции приравниваем к нулю 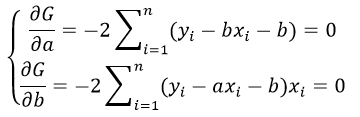 отсюда получаем систему линейных уравнений  Формулы определения коэффициента уравнения линейной регрессии: 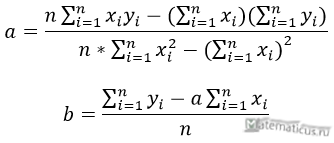 Метод максимального правдоподобия применяется для определения неизвестных коэффициентов модели регрессии и является альтернативой методу наименьших квадратов. Суть данного метода состоит в максимизации функции правдоподобия или её логарифма. Общий вид функции правдоподобия: где– это геометрическая сумма, означающая перемножение вероятностей по всем возможным случаям внутри скобок. Общий вид функции правдоподобия: 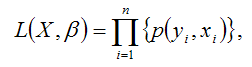 ПОСЛЕДСТВИЯ НАРУШЕНИЯ ПРЕДПОСЫЛОК РЕГРЕССИОННОГО АНАЛИЗАОптимизационный подход к проблемам управления и принятия решений. Исторически оптимизационные задачи возникли как способы описания и алгоритмизации проблемных ситуаций принятия решений. При этом из множества альтернатив выбора находится одна или несколько, при которых функционал задачи достигает своего максимума или минимума. Последствия нарушения предпосылок регрессии проявляются в: существенной смещенности оценок коэффициентов; бессмысленности коэффициента корреляции. Дисперсия уровней ряда остатков должна быть одинаковой для всех значений Воздействие гетероскедастичности на оценку интервала прогнозирования и проверку гипотезы заключается в том, что хотя коэффициенты и не смещены, дисперсии и, следовательно, стандартные ошибки этих коэффициентов будут смещенными. Если смещение отрицательно, то оценочные стандартные ошибки будут меньше, чем они должны быть, а критерий проверки — больше, чем в реальности. Таким образом, можно прийти к выводу, что коэффициент значим, когда он таковым не является. И наоборот, если смещение положительно, то оценочные ошибки будут больше, чем они должны быть, а критерии проверки — меньше. Значит, возможно ошибочное принятие нулевой гипотезы. Гетероскедастичность подлежит устранению, однако рассмотрение этого вопроса остается за пределами данного пособия. Для оценки гетероскедастичности при малом объеме выборки можно использовать метод Гольдфельда-Квандта, суть которого заключается в том, что необходимо: расположить значения переменной разделить совокупность упорядоченных наблюдений на 2 группы; по каждой группе наблюдений построить уравнения регрессии; определить остаточные суммы квадратов для первой и второй групп по формулам: рассчитать При выполнении гипотезы о гомоскедастичности критерий Fрасч будет удовлетворять F-критерию со степенями свободы Чем больше величина Fрасч превышает табличное значение F-критерия, тем больше нарушена предпосылка о равенстве дисперсий остаточных величин[2]. ШАГОВЫЕ АЛГОРИТМЫ ВЫБОРА «НАИЛУЧШЕЙ МОДЕЛИ»Частный
где Если числитель и знаменатель формулы умножить на Для остаточной суммы квадратов Аналогичную процедуру можно применять и для усложнения модели путем решения вопроса о включении в нее нового фактора. В пакетах прикладных программ, например в пакете STATISTICA, реализованы как процедура включения, так и процедура исключения фактора из модели. Критические значения критериев для включения и исключения факторов В методе исключения анализ начинается с включения в регрессионную модель всех переменных. Затем для каждой переменной вычисляют частную В методе включения начинают с построения модели, включающей лишь одну переменную, имеющую наибольший по абсолютной величине парный коэффициент корреляции с переменной выхода. Затем вычисляют частные Преимуществами шаговых методов являются простота алгоритмов, автоматизация выбора наилучшей модели, быстрота вычислений; недостатком - раздельный анализ переменных (по отдельности переменные могут не являться значимыми, но их совместное использование может улучшить показатели регрессионной модели). Более сложной процедурой является комбинация методов включения и исключения. Выбирают фиксированные пороговые уровни Другой способ пошагового отбора факторов состоит в использовании скорректированного коэффициента детерминации, определяемого по формуле
В отличие от обычного коэффициента детерминации АНАЛИЗ КАЧЕСТВА МОДЕЛИ: КОЛИЧЕСТВО ПОКАЗАТЕЛЕЙ КАЧЕСТВА ДИСПЕРСНОГО АНАЛИЗА, АНАЛИЗ ОСТАТКОВКачество модели оценивается по адекватности и точности на основе анализа остатков регрессии. Анализ остатков позволяет получить представление о том, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. Согласно общим предположениям регрессионного анализа, остатки должны «вести себя» как независимые (в действительности почти независимые), одинаково распределенные случайные величины. В классических методах регрессионного анализа предполагается нормальный закон распределения. Исследование остатков полезно начинать с их графика. Нередко встречаются ситуации, когда остатки содержат тенденцию или подвержены циклическим колебаниям. В этом случае говорят о наличии автокорреляции остатков. Иногда автокорреляция связана с исходными данными и вызвана наличием ошибок измерения результативного признака. В других случаях автокорреляция указывает на наличие какой-то достаточно сильной зависимости, неучтенной в модели. Например, при подборе простой линейной зависимости график остатков может показать необходимость перехода к нелинейной модели или включения в модель периодических компонент. Существуют два наиболее распространенных метода определения автокорреляции остатков: 1. построения графика зависимости остатков от времени и визуальное определение наличия или отсутствия автокорреляции; 2. использование критерия Дарбина–Уотсона и расчет величины 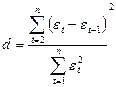 Таким образом, d это отношение суммы квадратов разностей последовательных значений остатков к остаточной сумме квадратов по модели регрессии. Коэффициент автокорреляции остатков определяется по
Если в остатках существует полная положительная автокорреляция и r1 ε = 1, то d = 0. если в остатках полная отрицательная автокорреляция и r1 ε = -1, то d = 4. Таким образом, величина d изменяется в переделах: 0£ d £ 4. Алгоритм выявления автокорреляции остатков на основе критерия Дарбина–Уотсона следующий: выдвигается гипотеза Но об отсутствии автокорреляции остатков; альтернативные гипотезы Н1 и Н1* состоят соответственно в наличии положительной или отрицательной автокорреляции в остатках. Далее по специальным таблицам определяются Критические значения критерия Дарбина-Уотсона dL и du для заданного числа наблюдений n, числа независимых переменных модели k и уровня значимости g. По этим значениям числовой промежуток [0;4] разбивают на пять отрезков. Если фактическое значение критерия Дарбина-Уотсона попадает в зону неопределенности, то нельзя сделать окончательный вывод по этому критерию. ЗАКЛЮЧЕНИЕВ реферате были рассмотрены методы и алгоритмы численного линейного регрессионного анализа, приведены примеры формул расчета методов. Метод наименьших квадратов дает наилучшие (в определенном смысле) оценки параметров регрессии. Выявлены последствия предпосылок регрессионного анализа такие как: Существенное смещение оценок коэффициентов; Бессмысленность коэффициента корреляции. Рассмотрены шаговые алгоритмы выбора «наилучшей модели», так же выделены преимущества и недостатки шаговых алгоритма выбора. Преимущества: Простота алгоритмов Автоматизация выбора наилучшей модели Быстрота вычислений Недостатки: Раздельный анализ переменных Сделаны выводы о выборе качества модели СПИСОК ЛИТЕРАТУРЫ1. Толчеев В.О. Современные методы обработки и анализа данных: Учебное пособие. М.: Издательский дом МЭИ, 2016. 2. Воскобойников Ю.Е. Регрессионный анализ в пакете MATHCAD+CD. − СПб.: Лань, 2021. 3. Теория информационных процессов и систем: учебник для вузов/ Б. Я. Советов и др. – М.: Академия, 2020. |